はじめに
こんにちは!今回はLinuxのsedコマンドについてです!
sedを調べたときに一度は目にするであろう後方参照について、なるべくわかりやすく解説できればと思います!
なお今回の記事は**「catコマンドを使ったことがある」**ことを前提としていますので、あらかじめご了承ください。
(後半の章ではgrepや「正規表現」を使うので、これらを知っていればなお良いです。一応簡単な解説は載せています)
本稿の内容は大きく分けて、
・sedの基本的な機能
・後方参照の書き方
・\1とか\2の違い
・「後方参照」という言葉の意味
・具体的な使用例
となっています。
それでは本題に入ります!
(※「¥」マークと「\」マークは、同じ記号と考えて頂いてOKです。)
sedの基本的な使い方
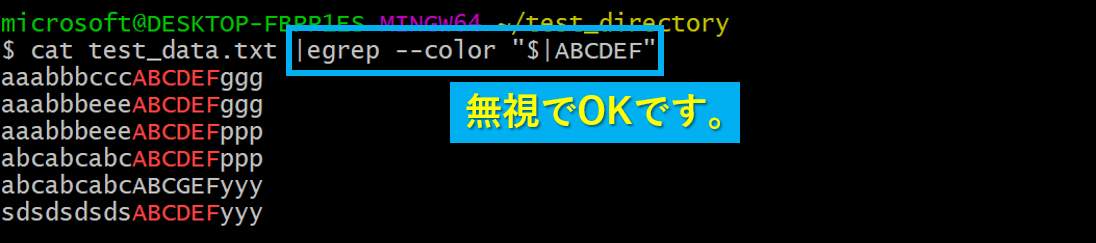
今回は下図のtest_data.txtを使って説明していきたいと思います。
「ABCDEF」の部分に着目しながら読み進めていって下さい!
catより右側の部分は「ABCDEFに色を付けるためのただのおまじない」なので、気にしなくて大丈夫です。もう二度と出てきません!
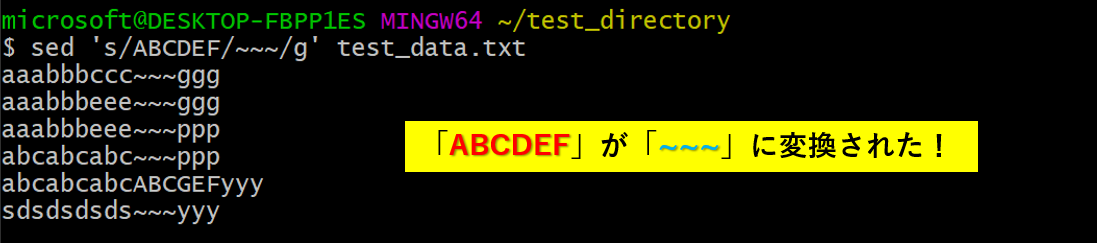
sedコマンドを使うときは、sed 's/〇〇〇/△△△/g' いじくりたいファイル名の形が基本となります。
これによって、ファイル内の**全ての行で、「〇〇〇」が「△△△」に変換**されます。
このように**sed**というコマンドは
「左で書いた文字列を右で書いた文字列に変換する」
という機能をもつという事を頭の隅に入れておいてください!
・ちなみに
sed 's/〇〇〇/△△△/g' いじくりたいファイル名は、
cat いじくりたいファイル名 | sed 's/〇〇〇/△△△/g'
と書いても同じです。
・より詳しいsedの使い方はこちらをご参照ください。sedコマンドの備忘録
後方参照の書き方
後方参照という言葉の意味は、sedにおける**\1や\2**の意味を理解してからの方がイメージしやすいかと思うので、いったん置いておいてください!
「後方参照」の使いどころは様々ですが、今回は
「指定した位置に、自分が入れたい文字列を挿入する」
場合をご説明します。
(文字列を「置換」するのではなく「挿入」する。)
この場合の「後方参照」の書き方ですが、基本的には冒頭で述べた
sed 's/〇〇〇/△△△/g' いじくりたいファイル名
の形がベースとなります。
違いは次の3点です。
1. △△△の前に「\1」をつける。
2. 〇〇〇を**(と)で囲む。(もしくは\(と\)**で囲む)
3. **sedの後ろに-r**をつける。(2を後者にした場合はいらないです)
以上3点を踏まえた書き方が以下の通りです。
sed -r 's/(〇〇〇)/\1△△△/g' いじくりたいファイル名
または
sed 's/\(〇〇〇\)/\1△△△/g' いじくりたいファイル名
これによって、
「〇〇〇を△△△に変換する」
という機能から、
「〇〇〇の後ろに△△△を挿入する」
という機能に切り替わります。

ここまでの内容で「やりたいことができそうだ」という方は、具体的な使い方も参考にしながら自分のデータに**sed**を利用して頂ければと思います!
\1と\2の違い
sedの後方参照について調べた方の中には、もしかしたら\1とか\2といった数字を見かけた方もいるかもしれません。
つぎはこの\1や\2の意味についてご説明したいと思います。
◆\1について
まず\1にだけ着目して話を進めます。
この\1の意味を理解するためには、次のような実験をするとわかりやすいです。
$ sed -r 's/(ABCDEF)/\1~~~/g' test_data.txt
aaabbbcccABCDEF~~~ggg
aaabbbeeeABCDEF~~~ggg
aaabbbeeeABCDEF~~~ppp
abcabcabcABCDEF~~~ppp
abcabcabcABCGEFyyy
sdsdsdsdsABCDEF~~~yyy
$ sed -r 's/(ABCDEF)/ \1 ~~~/g' test_data.txt ##右側の\1の両側に半角スペースを入れた
aaabbbccc ABCDEF ~~~ggg
aaabbbeee ABCDEF ~~~ggg
aaabbbeee ABCDEF ~~~ppp
abcabcabc ABCDEF ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds ABCDEF ~~~yyy
この結果をみて勘づいた方もいらっしゃるかと思いますが、この結果はつまり
「右側の\1の部分に、左側のABCDEFが代入されている」
ことを表しています!
つまりこの後方参照というのは
「ABCDEFをABCDEF ~~~に変換する」
ということを行う事で、
結果的に**「ABCDEFの後ろに ~~~が挿入されているように見えていた」**だけ
なのです。
以上が\1の意味です。つまり\1は、
「左側の( )に入っている文字列を、代入するための箱」
だということがわかりました。
◆\2について
まず前提として、\2を使うためには左側の( )を2つ設ける必要があります。
下に具体的な出力結果の例を示します。
おそらく実際に結果を見て頂いた方が理解しやすいかと思うので、コードが少し長くなりますが何卒お付き合いください。
$ sed -r 's/(ABC)(DEF)/ \1 \2 ~~~/g' test_data.txt
aaabbbccc ABC DEF ~~~ggg
aaabbbeee ABC DEF ~~~ggg
aaabbbeee ABC DEF ~~~ppp
abcabcabc ABC DEF ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds ABC DEF ~~~yyy
$ sed -r 's/(ABC)(DEF)/ \1 ~~~/g' test_data.txt
aaabbbccc ABC ~~~ggg
aaabbbeee ABC ~~~ggg
aaabbbeee ABC ~~~ppp
abcabcabc ABC ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds ABC ~~~yyy
$ sed -r 's/(ABC)(DEF)/ \2 ~~~/g' test_data.txt
aaabbbccc DEF ~~~ggg
aaabbbeee DEF ~~~ggg
aaabbbeee DEF ~~~ppp
abcabcabc DEF ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds DEF ~~~yyy
$ sed -r 's/(ABC)(DEF)/ \1 \2 \1 ~~~/g' test_data.txt
aaabbbccc ABC DEF ABC ~~~ggg
aaabbbeee ABC DEF ABC ~~~ggg
aaabbbeee ABC DEF ABC ~~~ppp
abcabcabc ABC DEF ABC ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds ABC DEF ABC ~~~yyy
$ sed -r 's/(ABC) (DEF)/ \1 \2 \1 ~~~/g' test_data.txt ##左側でスペースを入れると何も変化しなくなる
aaabbbcccABCDEFggg
aaabbbeeeABCDEFggg
aaabbbeeeABCDEFppp
abcabcabcABCDEFppp
abcabcabcABCGEFyyy
sdsdsdsdsABCDEFyyy
$ sed -r 's/(AB)CD(EF)/ \1 \2 \1 ~~~/g' test_data.txt
aaabbbccc AB EF AB ~~~ggg
aaabbbeee AB EF AB ~~~ggg
aaabbbeee AB EF AB ~~~ppp
abcabcabc AB EF AB ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds AB EF AB ~~~yyy
\3も使って書いてみます。
$ sed -r 's/(AB)(CD)(EF)/ \1 \2 \3 ~~~/g' test_data.txt
aaabbbccc AB CD EF ~~~ggg
aaabbbeee AB CD EF ~~~ggg
aaabbbeee AB CD EF ~~~ppp
abcabcabc AB CD EF ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds AB CD EF ~~~yyy
$ sed -r 's/(AB)(CD)(EF)/ \1 \3 \2 ~~~/g' test_data.txt
aaabbbccc AB EF CD ~~~ggg
aaabbbeee AB EF CD ~~~ggg
aaabbbeee AB EF CD ~~~ppp
abcabcabc AB EF CD ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds AB EF CD ~~~yyy
$ sed -r 's/(AB(C(DEF)))/ \1 \2 \3 ~~~/g' test_data.txt
aaabbbccc ABCDEF CDEF DEF ~~~ggg
aaabbbeee ABCDEF CDEF DEF ~~~ggg
aaabbbeee ABCDEF CDEF DEF ~~~ppp
abcabcabc ABCDEF CDEF DEF ~~~ppp
abcabcabcABCGEFyyy
sdsdsdsds ABCDEF CDEF DEF ~~~yyy
いかがでしょうか。ここまでの結果を踏まえて、ご説明させて頂きます。
**sedが「左で書いた文字列を右で書いた文字列に変換する」**コマンドだったことを、いま一度思い出しながら読んでいただければと思います。
まず、これらの結果は基本的には左側のABCDEFをどういう風に変換するか(置換するか)が違うだけです。
途中何も変化しない例があったのは、ABC DEFという文字列がファイル内のどこにも存在していなかったからというわけです。
また、\1 \2 \3にはそれぞれ、左側の1番目 2番目 3番目の( )の中身が代入されています。
なので例えば一番最後から2番目、8番目の例では\1に**AB、\2にCD、\3にEFが代入されているので、ABCDEFが AB EF CD ~~~に変換されていますし、
6番目の例では、\1にAB、\2にEFが代入されているので、ABCDEFがAB EF AB ~~~**に変換されています。
また、最後の例では\1に**ABCDEF、\2にCDEF、\3にDEF**が代入されていることから、左側の( )は入れ子にできることがわかります。
つまり話をまとめると、`\1` `\2` `\3` ... `\N`は、 **「左側の(`(`で見て)N番目の`(` `)`の中身を、代入するための箱」** だということです!
「後方参照」という言葉の意味
**\1や\2**の意味はイメージできましたでしょうか。
前置きが長くなりましたが、ここでようやく「後方参照」という言葉の意味に触れたいと思います。
後方参照とはざっくりいうと、
**「( )で囲んだ部分を、後ろの方で参照して使う」**機能のことを言います。
( )で囲んだ部分を参照する場合は上の章で出てきた\1や\2を使います。
(ちなみにややこしい話なのですが、ここでいう「後方」とは( )の中のこと(=文頭方向の文字列)を言います。( )の中身を参照するので、「後方参照」といいます)
例えば、下のsedの例でいえば、
( )で囲んだ**ABCDEFを、後ろの\1**で参照しています。
$ sed -r 's/(ABCDEF)/\1~~~/g' test_data.txt
aaabbbcccABCDEF~~~ggg
aaabbbeeeABCDEF~~~ggg
aaabbbeeeABCDEF~~~ppp
abcabcabcABCDEF~~~ppp
abcabcabcABCGEFyyy
sdsdsdsdsABCDEF~~~yyy
## 左側でも使用可能。
$ sed -r 's/((a)\2\2)/\1---/g' test_data.txt
aaa---bbbcccABCDEFggg
aaa---bbbeeeABCDEFggg
aaa---bbbeeeABCDEFppp
abcabcabcABCDEFppp
abcabcabcABCGEFyyy
sdsdsdsdsABCDEFyyy
またこの後方参照は、Linux以外の言語や、Linuxのsed以外のコマンドでも利用することができます。
例えばgrepコマンドを使った下の例でいうと、(grepは " 指定した文字列 " を含んでいる行を出力するコマンドです(=文字列検索))
$ cat test_data2.txt
1cccABCDEFgggABCDEFyyy
2eeeABCDEFgggAB--EFggg
3eeeABCDEFpppABCDEFppp
4abcABCDEFppp------yyy
5abc------yyyABCDEFyyy
$ grep -E "(ABCDEF)...\1" test_data2.txt ## 「.」は「任意の1文字」を表す
1cccABCDEFgggABCDEFyyy
3eeeABCDEFpppABCDEFppp
のように、( )で囲んだ**ABCDEFを、\1**で参照することができます。(もちろん\2や\3も、grepで利用可能です)
これが後方参照のざっくりとした内容です。
注意点として、例えば( )の中身に複数候補が該当できる場合でも、( )で指定した中身と\1の中身は同一のものになります。(( )の中身と\1の中身が違う文字列を表すということはない)
$ cat test_data3.txt
1xxxABCyyyABCzzz
2xxxABCyyyABD
3xxxABCyyyABDzzzABD
4xxxABCyyyABDzzzABC
5xxxABDyyyABC
6xxxABDyyyABDzzz
$ grep -E '(AB[CD]).*\1' test_data3.txt ## AB[CD] と \1 は同一の文字列を表す
1xxxABCyyyABCzzz
3xxxABCyyyABDzzzABD
4xxxABCyyyABDzzzABC
6xxxABDyyyABDzzz
$ grep -E '(AB[CD])(y|z).*\2\1' test_data3.txt ## \2 も同様
1xxxABCyyyABCzzz
3xxxABCyyyABDzzzABD
6xxxABDyyyABDzzz
ここでの後方参照に関する説明は、以上となります。
お疲れ様でした!
・この章を書く上で以下のサイトにお世話になりました。
「正規表現と後方参照」~マンガでプログラミング用語解説
(閲覧するには無料会員登録が必要です。)
具体的な使い方
最後にいくつかの使用例を挙げて本稿を締めさせて頂きたいと思います。
これらの具体的な書き方を参考にしつつ、ご自身のシチュエーションに合った使い方をしていただければと思います。
ご精読ありがとうございました!🙇♂️
通常のsedを用いた例
・特定の文字列に "" をつける
$ sed 's/ABCDEF/"ABCDEF"/g' test_data.txt
aaabbbccc"ABCDEF"ggg
aaabbbeee"ABCDEF"ggg
aaabbbeee"ABCDEF"ppp
abcabcabc"ABCDEF"ppp
abcabcabcABCGEFyyy
sdsdsdsds"ABCDEF"yyy
・特定の文字列を消す(右側に何も書かない)
$ sed 's/ABCDEF//g' test_data.txt
aaabbbcccggg
aaabbbeeeggg
aaabbbeeeppp
abcabcabcppp
abcabcabcABCGEFyyy
sdsdsdsdsyyy
\1を使った例
・先頭から5文字目の後ろに - を挿入(正規表現を使用)
-rを使わない場合は、( )を\( \)、{ }を\{ \}にする。
$ sed -r 's/(^.{5})/\1-/g' test_data.txt
aaabb-bcccABCDEFggg
aaabb-beeeABCDEFggg
aaabb-beeeABCDEFppp
abcab-cabcABCDEFppp
abcab-cabcABCGEFyyy
sdsds-dsdsABCDEFyyy
$ sed 's/\(^.\{5\}\)/\1-/g' test_data.txt ## -r をつけない場合
aaabb-bcccABCDEFggg
aaabb-beeeABCDEFggg
aaabb-beeeABCDEFppp
abcab-cabcABCDEFppp
abcab-cabcABCGEFyyy
sdsds-dsdsABCDEFyyy
(補足)
正規表現とは特殊な意味を持つ文字(メタ文字という)を使ってコマンドを書くこと。(Aとかbとかはただの文字ですが、^とか.は特別な意味を持つ文字です)
^:「先頭の」、.:「任意の文字」、{n}:「連続するn文字」
という意味なので、これらを組み合わせた**^.{5}**は「先頭の任意の5文字」を表します。(詳しくはまた別の機会に。)
・特定の文字列に "" をつける(\1を使えばコンパクトに書けます)
$ sed -r 's/(ABCDEF)/"\1"/g' test_data.txt
aaabbbccc"ABCDEF"ggg
aaabbbeee"ABCDEF"ggg
aaabbbeee"ABCDEF"ppp
abcabcabc"ABCDEF"ppp
abcabcabcABCGEFyyy
sdsdsdsds"ABCDEF"yyy
・**sed**を複数回使う
$ cat test_data.txt | sed -re 's/(^.{5})/\1-/g' | sed -re 's/(ABCDEF)/"\1"/g'
aaabb-bccc"ABCDEF"ggg
aaabb-beee"ABCDEF"ggg
aaabb-beee"ABCDEF"ppp
abcab-cabc"ABCDEF"ppp
abcab-cabcABCGEFyyy
sdsds-dsds"ABCDEF"yyy
(補足)
・複数個の処理を連動させたい場合は、|(「Shift」+「¥」)を使います。|は左で行った処理を、右に持ち越す機能があります。
今回はこれによって最終的に「-」と「" "」を両方挿入した結果が出力されます。
・sedの結果を|の向こうに持ち越すためには-eを付ける必要があります。今回は-rと-eを使っているので、あわせて-reとしています。ちなみに-erではうまくいきません。
\2を使った例
・文字列の位置を入れ替える(連続した文字列)
ABC(\1) DEF(\2)を、DEF(\2) ABC(\1)に置換しています。
$ sed -r 's/(ABC)(DEF)/\2\1/g' test_data.txt
aaabbbcccDEFABCggg
aaabbbeeeDEFABCggg
aaabbbeeeDEFABCppp
abcabcabcDEFABCppp
abcabcabcABCGEFyyy
sdsdsdsdsDEFABCyyy
・内側の文字列を置換する(「aaa … ppp」の文字列のみ)
$ sed -r 's/^(aaa).*(ppp)$/\1---\2/g' test_data.txt
aaabbbcccABCDEFggg
aaabbbeeeABCDEFggg
aaa---ppp
abcabcabcABCDEFppp
abcabcabcABCGEFyyy
sdsdsdsdsABCDEFyyy
(補足)
***もメタ文字の一種で、「0文字以上連続している」ことを表します。
つまり.*は(何もないのも含め)「あらゆる文字列」を表します。(※出力結果は最長のモノが選ばれます)
また、^は「先頭の」、$**は「末尾の」という意味のメタ文字なので、これによって、「aaaで始まり、pppで終わる行」だけが選択されます。