はじめに
kindleは大型セールが頻繁にあるのでどうしてもたくさん買ってしまいがちですが、kindleアプリは使い勝手がゴミあまりよくないため書籍が増えてくると管理がしづらいと思います。
特に検索機能が問題で、前方一致でしか検索が行えないためタイトル名を完璧に覚えていない場合に目当ての書籍を探し出すのは困難を極めます。
そこで、自分の所持しているkindleの書籍データからタイトル名や著者名から検索できる機能や分析できる機能をPowerBIを用いて実装してみました。
書籍データの取得
xmlファイルの入手
kindleのデスクトップアプリを入れると、以下のファイルパスにxml形式のファイルが自動保存されます。
C:\Users\user_name\AppData\Local\Amazon\Kindle\Cache\KindleSyncMetadataCache.xml
$HOME/Library/Containers/com.amazon.Kindle/Data/Library/Application\ Support/Kindle/Cache/
中身をのぞいてみると以下のような内容になっています。
<response>
<sync_time>2023-12-15T15:42:26+0000;softwareVersion:70673;SE:F;SC:F;CS:S;CT:F;ST:KS-15000000000023,Periodical-1702654946091,KB-15000000001458,</sync_time>
<cache_metadata>
<version>1</version>
</cache_metadata>
<add_update_list>
<meta_data>
<ASIN>B0BSPC58ZH</ASIN>
<title pronunciation="オカルトケンハソンザイシナイ003">オカルト研は存在しない!! 3 (ヤングアニマルコミックス)</title>
<authors>
<author pronunciation="カワライユウキ">河原井優貴</author>
</authors>
<publishers>
<publisher>白泉社</publisher>
</publishers>
<publication_date>2023-01-27T00:00:00+0000</publication_date>
<purchase_date>2023-12-10T10:33:28+0000</purchase_date>
<textbook_type/>
<cde_contenttype>EBOK</cde_contenttype>
<content_type>application/x-mobipocket-ebook</content_type>
<origins>
<origin>
<type>Purchase</type>
</origin>
</origins>
</meta_data>
...
取得できる中で使えそうなデータは以下の通りです。
- タイトル
- 作者
- 出版社
- 購入日
- 出版日
データの詳細についてですがタイトルにレーベル名や巻数が含まれていたり、シリーズ名を保持していない、などなかなかに使いづらそうなデータとなっています。
xmlファイルをdictに変換
import xmltodict
# xmlファイルのパスを指定
xml_file = "(ファイルパス)/KindleSyncMetadataCache.xml"
# XMLファイルの処理
with open(xml_file, encoding='utf-8') as fp:
# xml読み込み
xml_data = fp.read()
# xml → dict
dict_data = xmltodict.parse(xml_data)
# 各書籍のデータを格納
books = dict_data["response"]["add_update_list"]["meta_data"]
xmlファイルをそのまま扱うのは面倒だったので、xmltodictを用いてxmlファイルをdictに変換することで中のデータを取得しやすくしました。
csvファイルの出力
import csv
# CSVファイルの出力先を指定
csv_file = "output.csv"
with open(csv_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
# ヘッダー行を書き込む
writer.writerow(["タイトル(読み)", "タイトル", "作者(読み)", "作者", "出版社", "購入日", "出版日"])
# 各書籍のデータを書き込む
for book in books:
title_pronunciation = book["title"]["@pronunciation"]
title_text = book["title"]["#text"]
# 作者が複数人の場合
if isinstance(book["authors"]["author"], list):
author_pronunciation = ""
author_text = ""
for author in book["authors"]["author"]:
author_pronunciation += author["@pronunciation"]
author_text += author["#text"]
else:
author_pronunciation = book["authors"]["author"]["@pronunciation"]
author_text = book["authors"]["author"]["#text"]
# 出版社の書き込み
if book["publishers"]is not None:
publisher = book["publishers"]["publisher"]
# 購入日の書き込み
purchase_date = book["purchase_date"]
# 発行日の書き込み
publication_date = book["publication_date"]
# データ行を書き込む
writer.writerow([title_pronunciation, title_text, author_pronunciation, author_text, publisher, purchase_date, publication_date])
dictに変換した各項目をcsvファイルに出力します。
これで自分の持っているkindle本の状態をデータとして取得することが出来ました。
PowerBIで可視化
書籍検索
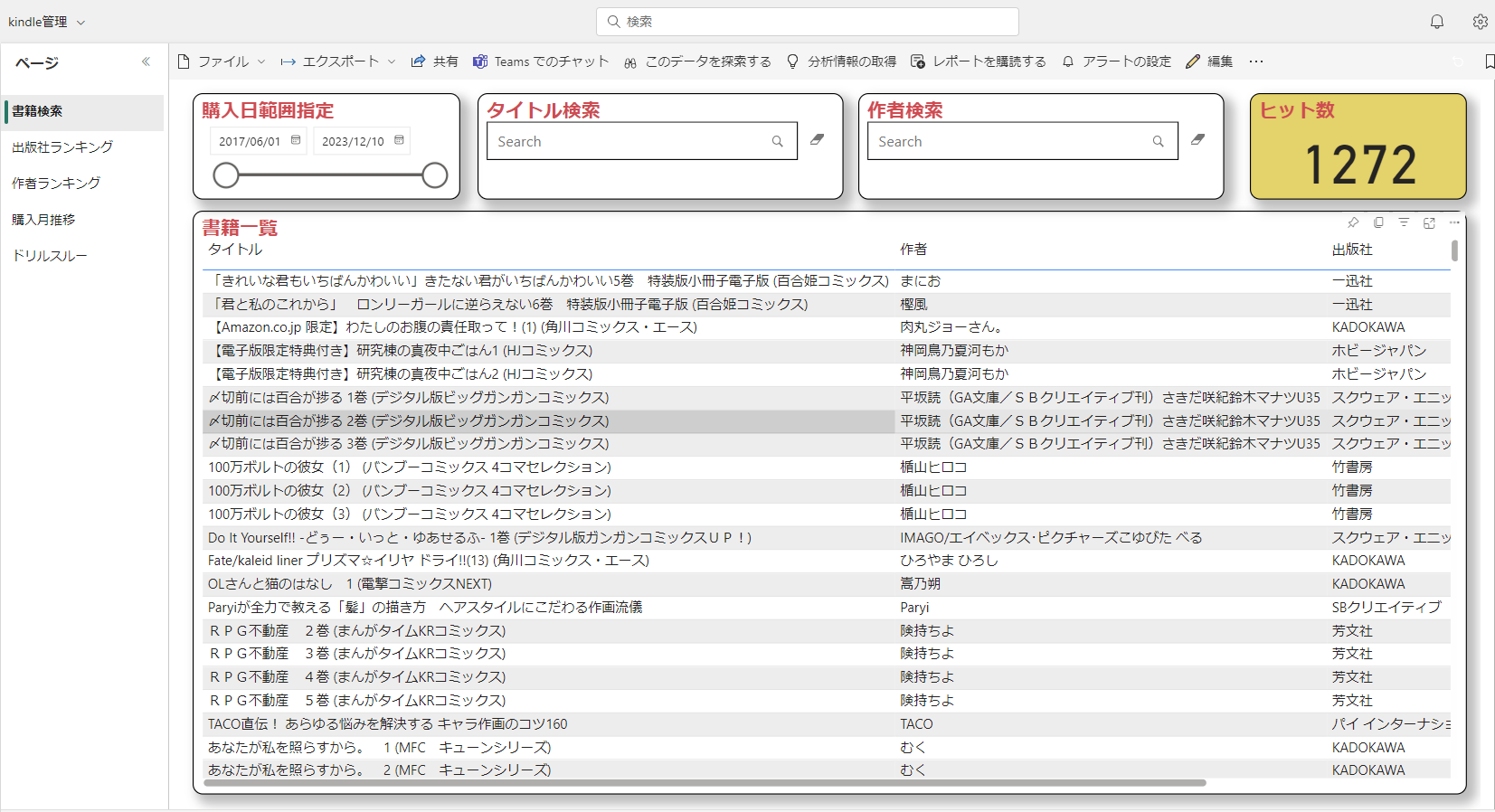
kindleアプリで一番不満だった「検索が前方一致でしか行えない問題」を解決するためのページです。
PowerBIの基本機能に検索ウィンドウはありませんが、Text Filterと呼ばれる公式の追加DLCのようなものを用いて実現させました。
また、ある地点で買った本なども検索できるように購入日での範囲指定フィルタも追加してみました。
出版社ランキング
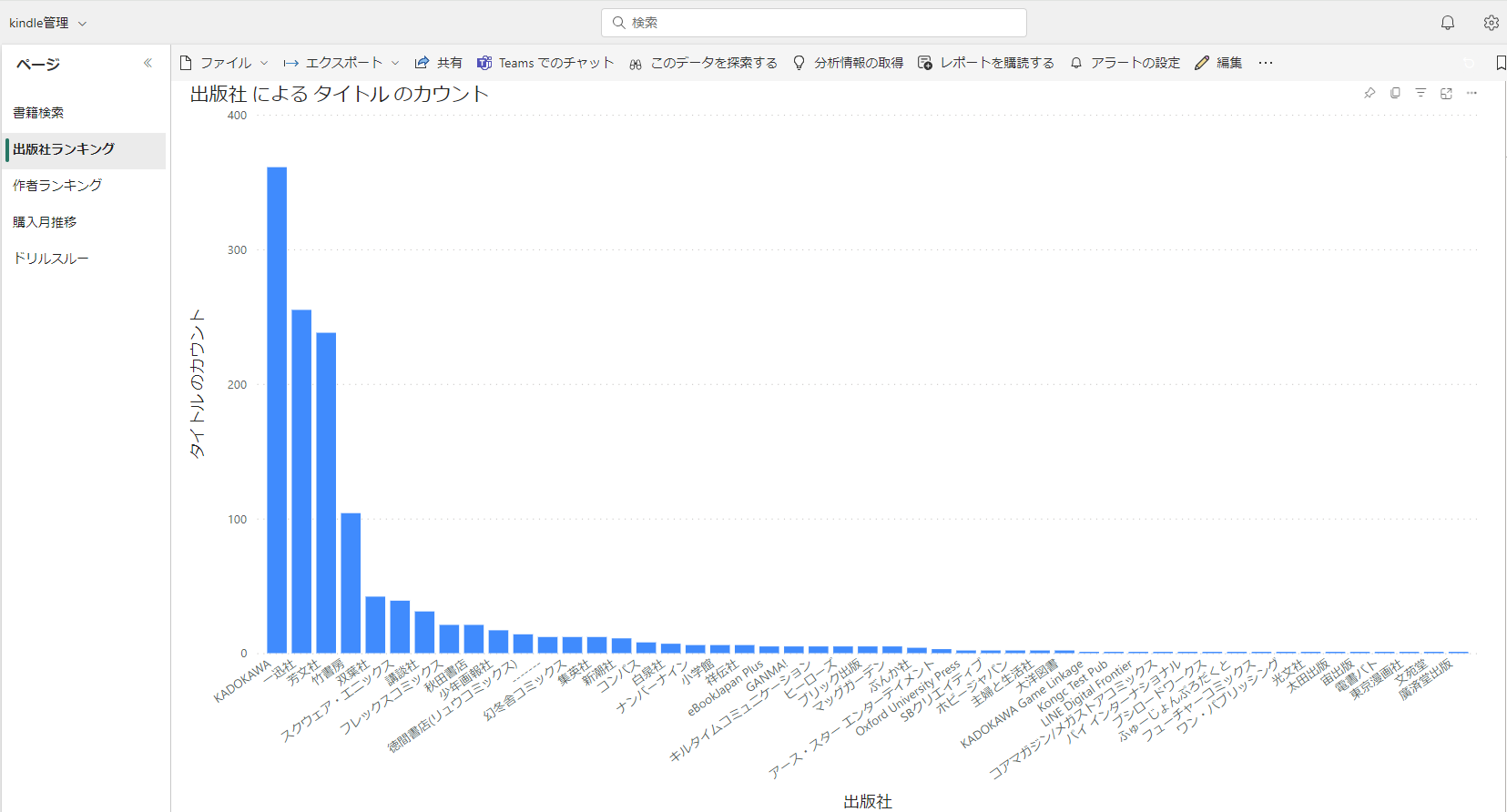
所持している書籍の出版社を多い順にグラフで表示するページです。
自分好みの書籍がどこの出版社から出ているかが一目でわかります。
補足
ドリルスルー機能を使うことで、内訳もチェックできるようにしました。
右クリックで「ドリルスルー」を選択すると...
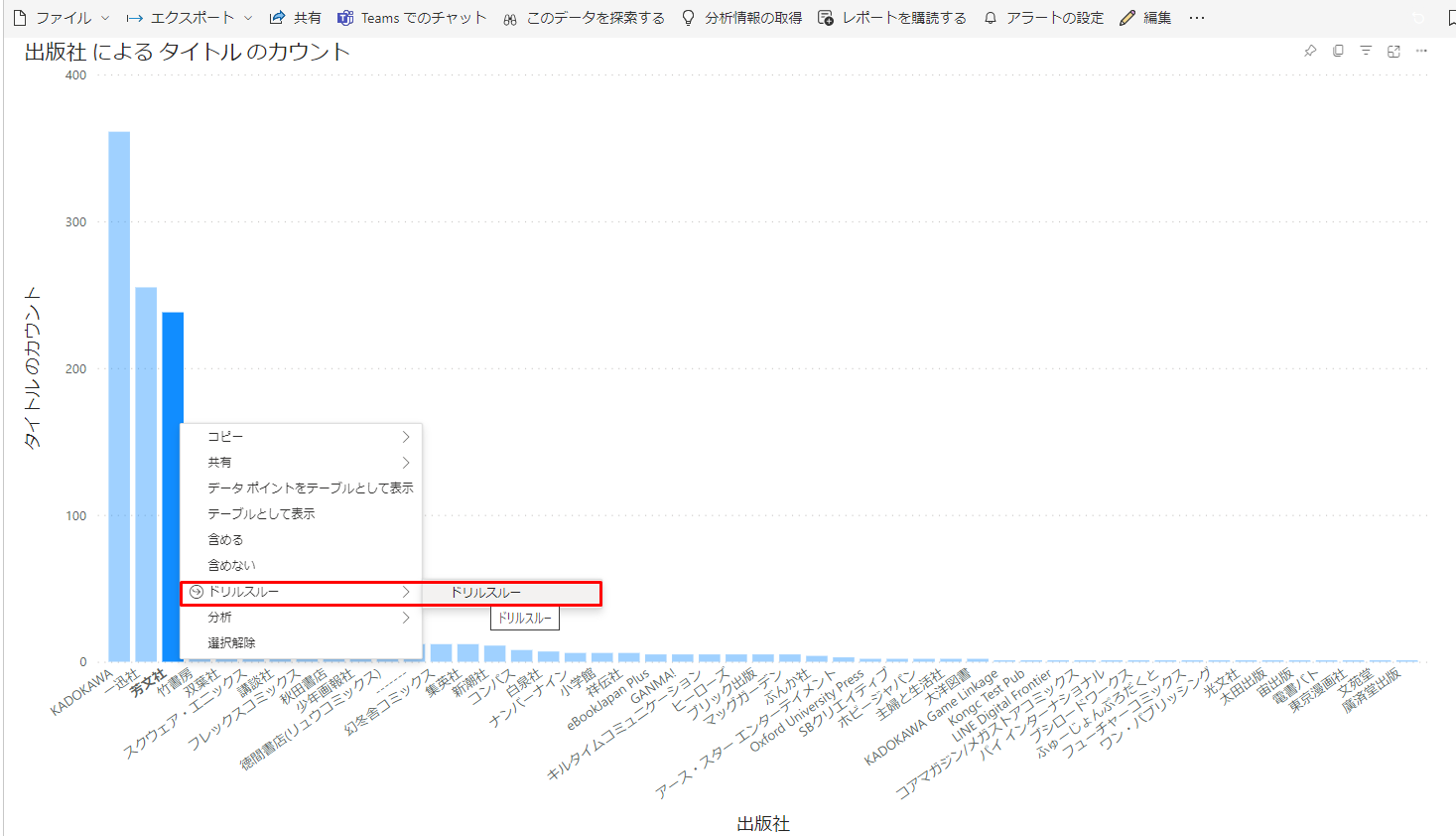
別ページに飛ばされて、選択したグラフの内訳が表示されます。
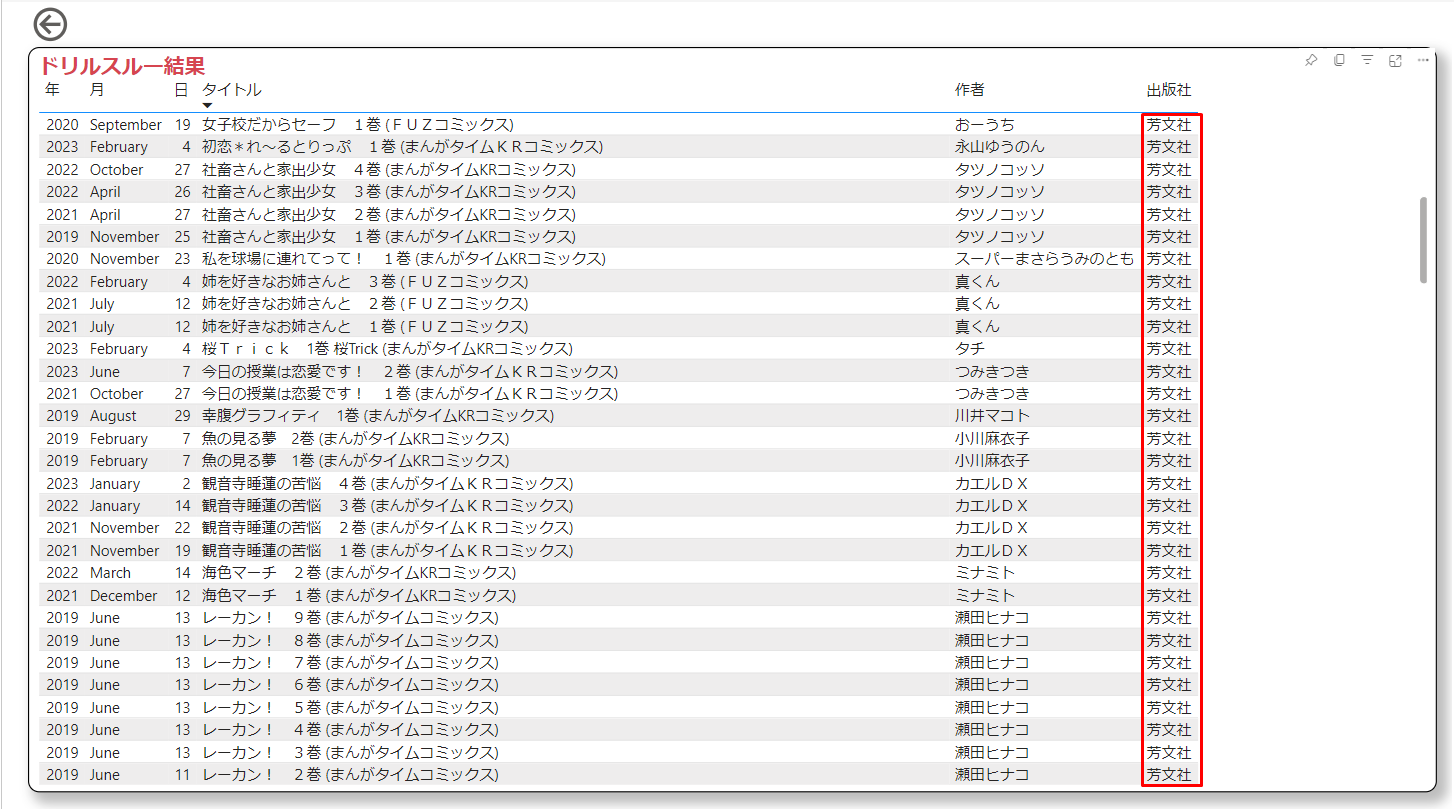
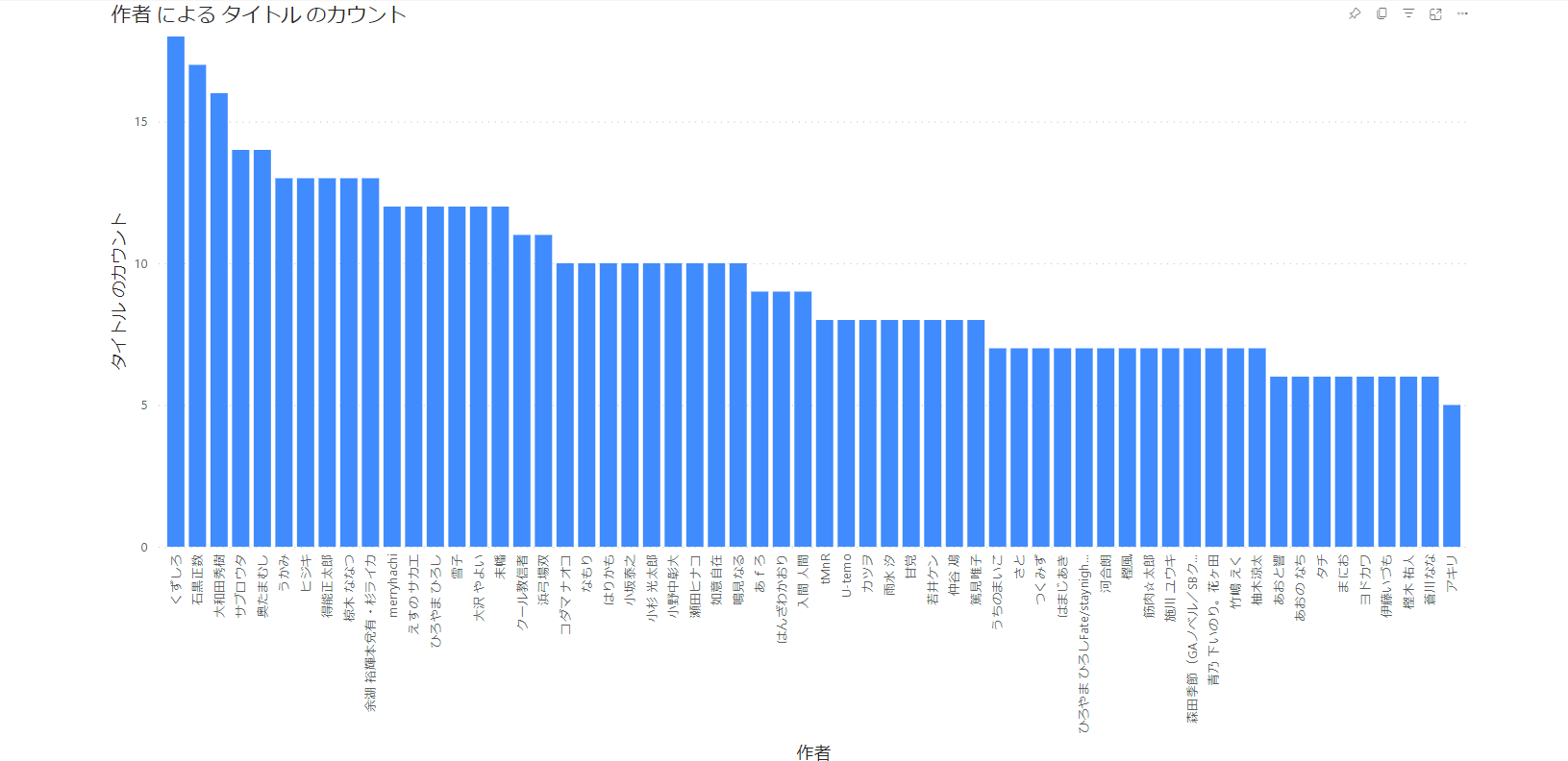
作者ランキング
出版社ランキングの作者版です。
自分の好きな作者が一目で分かりますが、シリーズ物も1冊ごとに集計しているため長編漫画の作者が上位にランクインしやすいという欠点があります。
ただ、取得したデータの中にシリーズの情報は無いためシリーズ物をひとまとめにするには一工夫必要そうです。
購入月推移
購入日の推移を可視化したビューです。
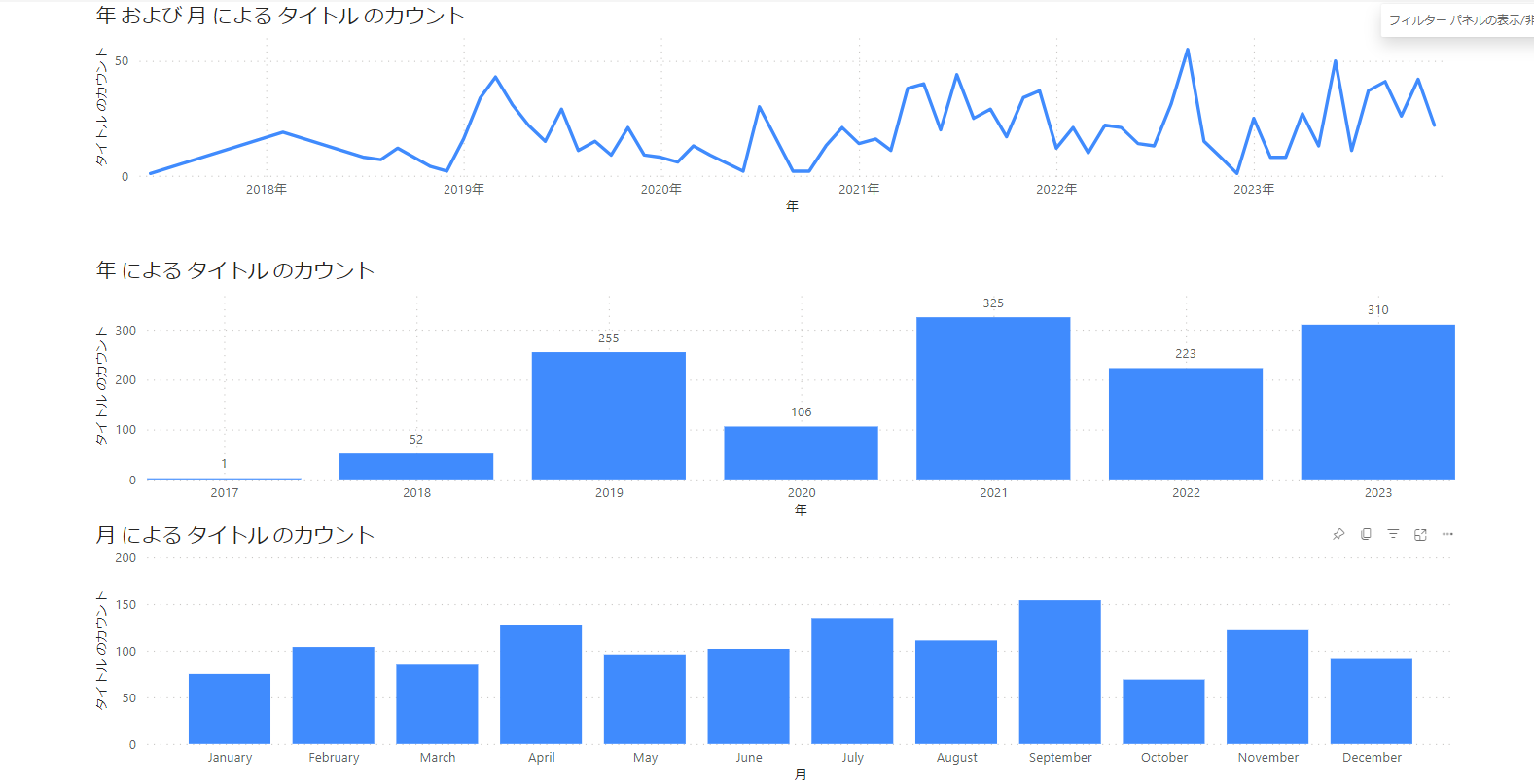
上は月ごとに、真ん中は年ごとの推移を表示しています。
また、下のグラフは通年の月ごとの推移を表しているので、どの時期に自分が書籍を多く買う傾向にあるかというのが分かります。
終わりに
xmlファイルから取得できるデータの種類が少ないためあまり分析案を出すことができませんでしたが、本来の目的であった部分一致の検索機能が実装できたため満足しました。
書籍データをcsvファイルに吐き出せればPowerBIで見せる以外にも色んな使い方ができると思うので、みなさんも良い読書ライフを!
参考サイト