ロジスティック回帰分析を調べていると、説明変数が連続ではない場合(カテゴリカルデータ)について知りたくなった。
試しに擬似データで、一通り分析をしてみる。
性別と年齢層が説明変数、クリックしたかどうかが目的変数のデータを用意した。ディスプレイ広告を想定している。
https://drive.google.com/file/d/1yqUND_5lih4cHqAr3QFjsjaJc7IFoLz4/view
全体のコード
必要なライブラリ
カテゴリカルデータを可視化するパッケージ vcd が必要となる。
install.packages('vcd')
データ生成の方法
整数の一様乱数
floor(runif(n = 10, min = 0, max = 2)) とすることで、0か1の数値を10個生成することができる1
データの偏らせ方
性別が男性(male)であること、年代が30代(30s)であることのいずれかのとき、クリックをしやすいように調整した。
具体的には、rbinomで試行を1回(size=1)、観測回数を1(n=1)を指定して確率だけ変更した。例えば、maleであるときに成功確率を0.7としている。
clickするかどうかは、click_rateが0.5を超えるかどうかで0,1を分けている。
コード
samplesize <- 1000
sex <- factor(floor(runif(n = samplesize, min = 0, max = 3)), labels = c("male", "female", "other"))
agegroup <- factor(floor(runif(n = samplesize, min = 0, max = 5)), labels = c("10s", "20s", "30s", "40s", "50s"))
a <- sapply(sex, function (x) {
b <- 0
if(x == 'male') b <- rbinom(n=1,size=1,prob = 0.7)
else if (x == 'female') b <- rbinom(n=1,size=1,prob = 0.5)
else b <- rbinom(n=1,size=1,prob = 0.1)
return(b)
})
b <- sapply(agegroup, function (x) {
c <- 0
if (x == '30s') c <- rbinom(n=1,size=1,prob = 0.7)
else c <- rbinom(n=1,size=1,prob = 0.5)
return (c)
})
click_rate <- scale(x = (a+b), center=min(a+b), scale = (max(a+b) - min(a+b)))
click <- factor(ifelse(click_rate > 0.5, 1, 0), labels = c("n", "y"))
ad_click <- data.frame(click=click, sex=sex, agegroup)
記述統計量
生成された、ad_clickについてどのようになっているか観察する。clickは大きく偏っているが、sexやagegroupには一様に分布しているようだ。
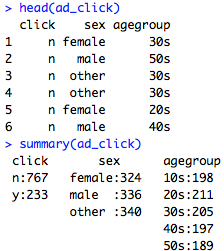
集計表を用いたカテゴリカルデータの分布
集計表を作り、どこに偏りがあるか確認する。
# visualization
crosstab <- xtabs(~ click + agegroup + sex, data=ad_click)
pairs(crosstab, lower_panel = pairs_assoc, shade=TRUE) # https://www.slideshare.net/KumarP34/using-r-for-customer-segmentation
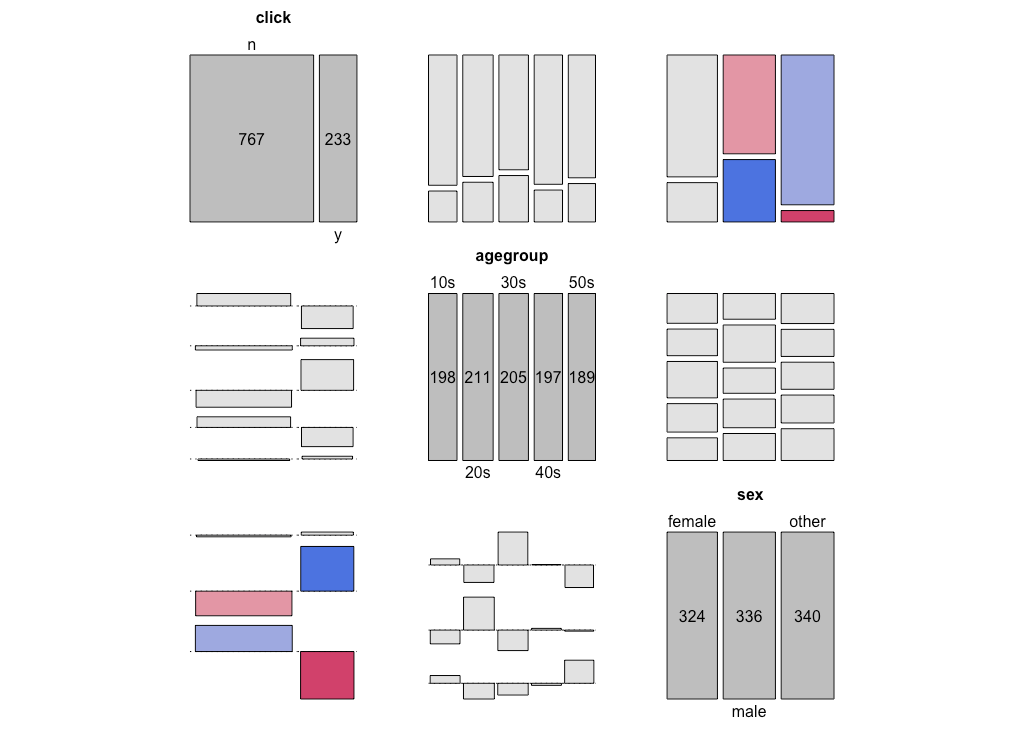
左下三角成分は、各変数間のアソシエーショングラフである。lower_panel = pairs_assocを指定することで、左下三角成分をアソシエーショングラフ(assocで生成されるグラフ)に変更できる。
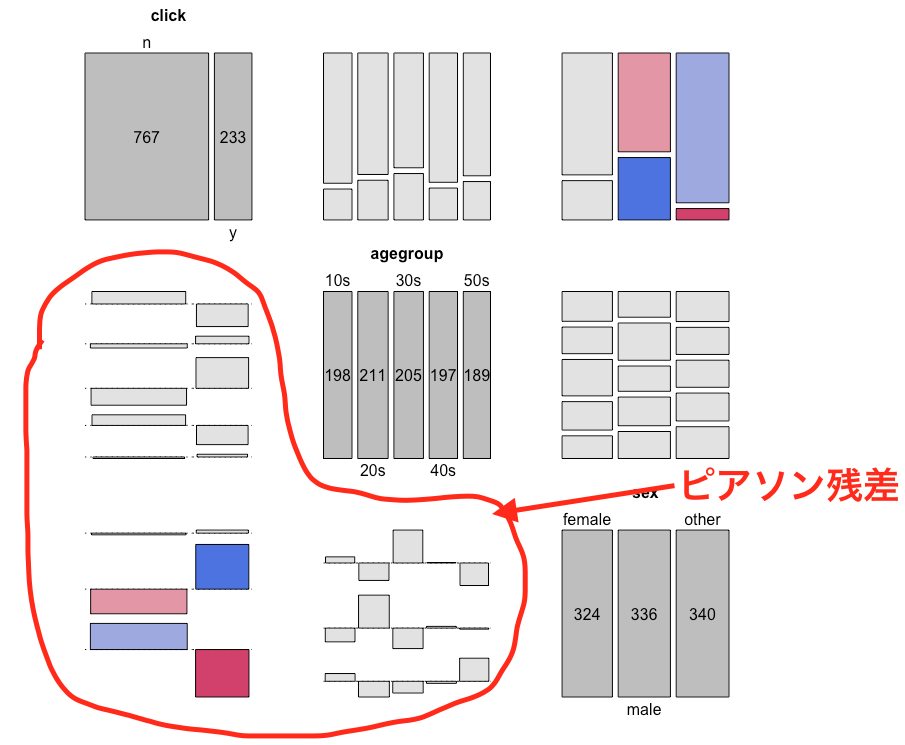
アソシエーショングラフ
clickとsexについてassoc を使ってグラフを描いた。上の図の3行1列のグラフに相当。
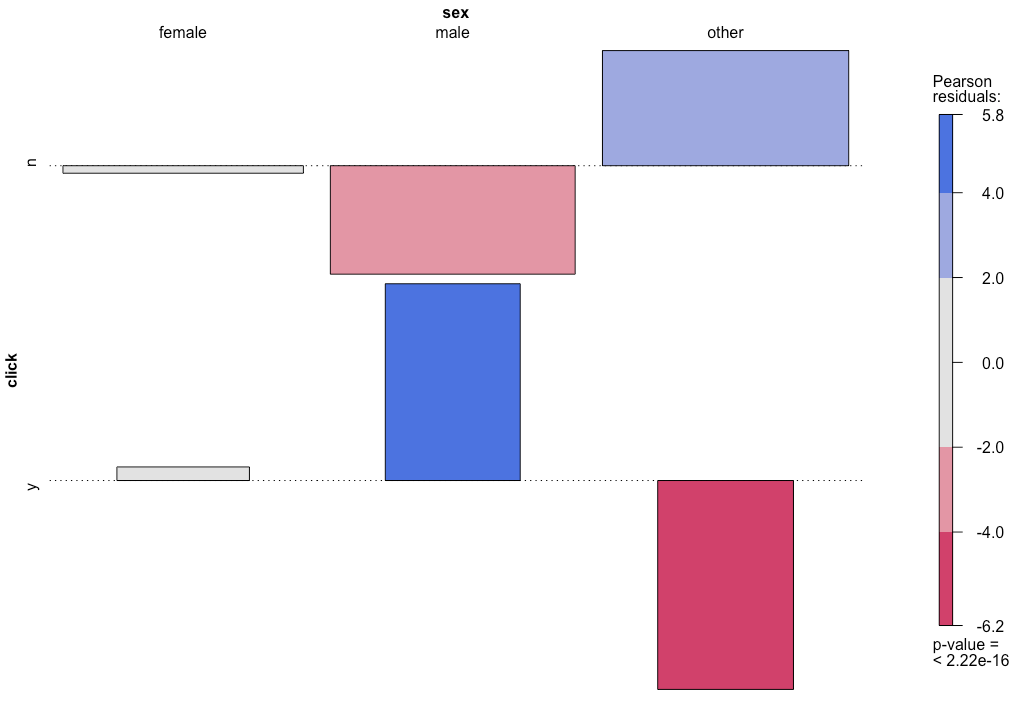
Rによるカテゴリカルデータの視覚化 によれば、グラフは以下を示しているらしい。
長方形の高さは残差、幅は期待度数の平方根、面積は観測度数と期待度数の差に比例する。各長方形はゼロをベースラインとし、残差が正の場合は場合はベースラインの上方、その逆であればベースラインの下方に配置する。
公式のDocmentも見ておいたほうがよさそうである(assoc function)。
このアソシエーショングラフからわかるのは、以下の2点である
- clickしたmaleの数が期待値よりも大きいこと
- clickしなかったotherの数が期待値よりも小さいこと
ロジスティック回帰
Rでは以下のコマンドを使う。
ad_click.glm <- glm(formula = click ~ sex + agegroup, data = ad_click, family="binomial")
summary(ad_click.glm)
Call:
glm(formula = click ~ sex + agegroup, family = "binomial", data = ad_click)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.1280 -0.8558 -0.4470 -0.3402 2.3993
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.36684 0.21408 -6.385 1.72e-10 ***
sexmale 0.69872 0.17350 4.027 5.65e-05 ***
sexother -1.43706 0.24924 -5.766 8.13e-09 ***
agegroup20s 0.19564 0.25298 0.773 0.4393
agegroup30s 0.55084 0.24969 2.206 0.0274 *
agegroup40s -0.01657 0.26547 -0.062 0.9502
agegroup50s 0.31678 0.26197 1.209 0.2266
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1085.75 on 999 degrees of freedom
Residual deviance: 974.58 on 993 degrees of freedom
AIC: 988.58
Number of Fisher Scoring iterations: 5
sexmaleの項、sexotherの項、そしてagegroup30sの項がかなり強い影響を及ぼしていることがPr(>|z|)の列から見てとれる
Coefficientsの列が、推定された係数である。この係数をexp関数にかけるとオッズ比が求まる。
オッズ比
クリック確率をpとしたとき、クリックしない確率 1 - p の比をオッズ比という。
説明変数それぞれのオッズ比は、ロジスティック回帰によって推定された係数から導ける。
exp(ad_click.glm$coefficients)
(Intercept) sexmale sexother agegroup20s agegroup30s agegroup40s agegroup50s
0.2549121 2.0111755 0.2376243 1.2160923 1.7347097 0.9835625 1.3726984
得られた数値は、各変数が1増加したときのオッズ比である。すなわち、sexmaleがTrueになるとオッズ比が2倍になる。
分析
よりビジネスに近い形で説明する。
- 男性(male)は、ほかの性別よりもクリック率が2.01倍になる
- 男女以外(other)は、ほかの性別よりも、クリック率が0.23倍になる
- 30代(30s)は、ほかの年代よりも、クリック率が1.73倍になる
以上のことから、 30代男性 に広告を多く配信するとクリック率向上が見込める。