はじめに
この記事は、2021MLOpsアドベントカレンダーの記事です。
初記事なのでお手柔らかにお願いします。。。
最近では、ML開発環境はオンプレで持つよりもクラウド活用の方が多いのではないでしょうか?
しかしながら、様々な理由でクラウドが使えない人もいるはずです。
私が所属している研究室でも、クラウドが使えず自前構築となっています。
しかしながら、なかなかオンプレで構築する記事がなかったのでMLOpsとは少し違うかもしれませんが運用体制を書いていこうと思います。
前提条件
我々の研究室では以下の要件を満たす必要がありました。
- あまりお金がないので民間グレードのサーバで構築すること
- 一年に多くのサーバを購入することができないのでクラスタにサーバを順次追加して行けること。
- 複数の人間が研究目的で使うため、認証システムが使えること。
- Pytorchを使う人やTensorflowを使う人、そしてChainerなど使う人がいるので柔軟性があること。
でした。
また、構築の際に有利になることは、 - 情報学部の研究室であるためにある程度の知識をユーザーに要求できる。
- 企業に比べれば、少ないがさすがに家庭に比べれば予算が多い。
- 大学が一年に一度停電をするため、大規模メンテナンスを行うことができる。
です。
研究室のクラスタのサーバ一覧は以下のような形です。
- GPU:RTX 3090 + TITAN X CPU:Thredripper 3960X
- GPU:RTX 3090 CPU:Ryzen9 5950X
- GPU:RTX 3090 CPU:Xeon E5 2630
- GPU:RTX 2080TI CPU:Corei9 9900K
- GPU:TITAN X CPU:Xeon E5 1680
- GPU:RTX 2070 CPU:Xeon E5 1680
OSはすべてUbuntu 20.04LTSです。
システム概要
当研究室では、
認証系をLDAP、ストレージシステムをGlusterFSで構築しています。
イメージとしては下のような形です。
各サーバには2つの分散ストレージプールが存在していて合計12個のストレージプールでGLusterFSを構築しています。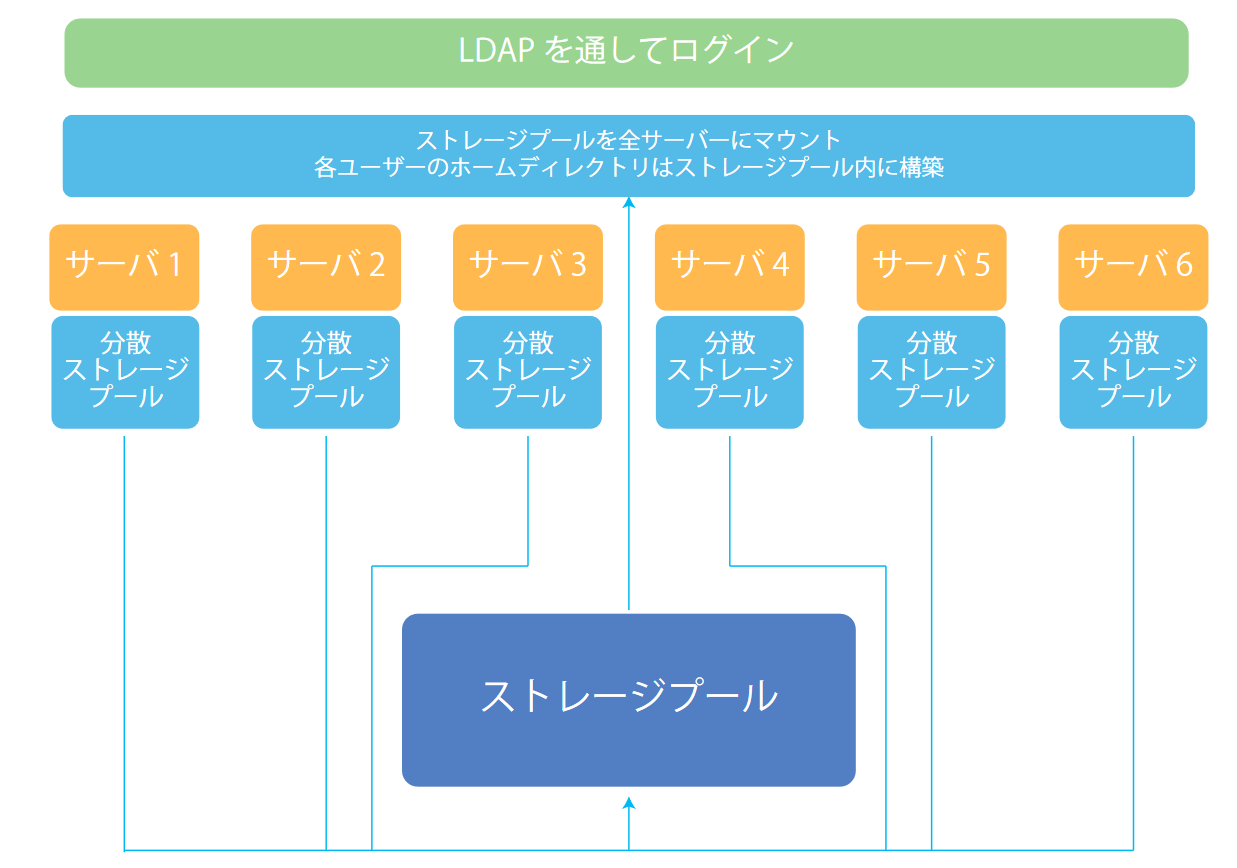
この際、本研究室で使用しているSSDはあまり高性能ではないためバックアップのために3重レプリケーションになるようにしています。
これにより2台のストレージが破損してもデータを保つことができます。
(ちなみに実際に破損しました)
当研究室でGlsuterFSを採用している理由は、追加するストレージの容量さえそろっていれば、どのようなOSでもどのようなシステム構成でも柔軟に追加できること。
そして、ストレージを搭載しないサーバを追加する際はストレージプールをマウントしてLDAP認証を追加するだけであっさりとクラスタに参加させることができます。
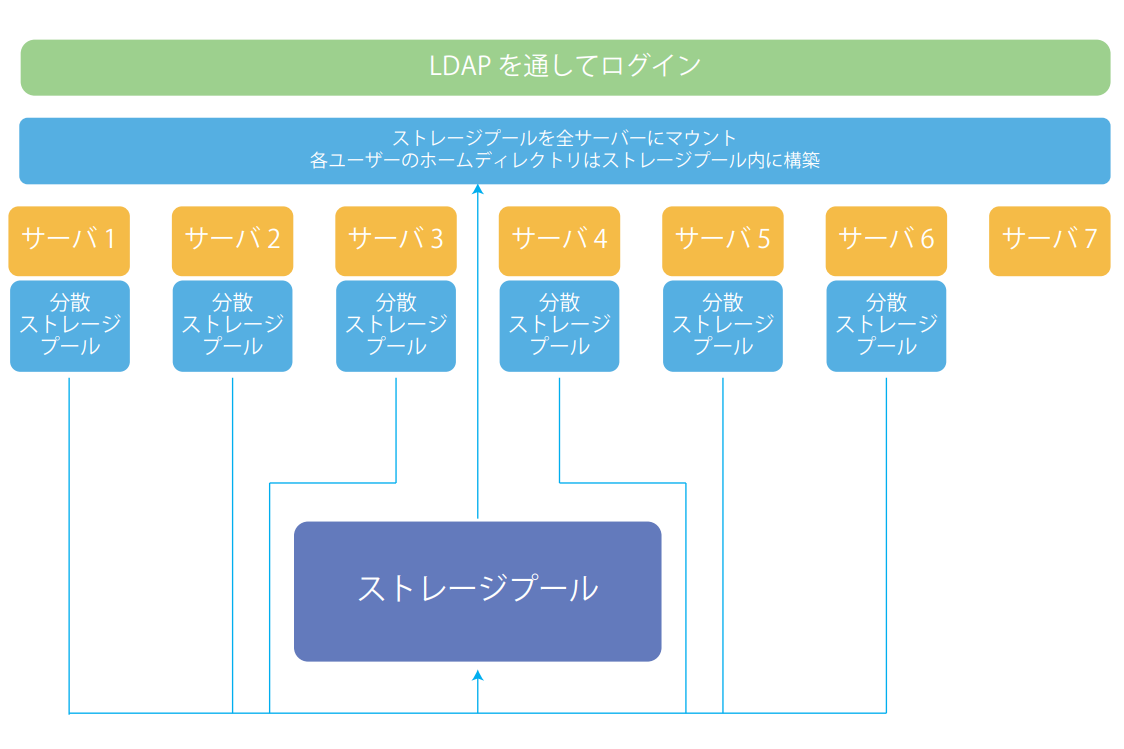
こんな感じです。
テスト環境などを構築する際に、ストレージなしのGPUサーバを参加させて活用したりしています。
また、各分散ストレージプール間の同期を早めるためサーバは、10GBit Ethernetで接続しています。
そのおかげかはわかりませんが、データの同期でストレスを感じることはありません。
実際の運用・活用
実際のクラスタの活用については利用者は、以下の流れで利用することになります
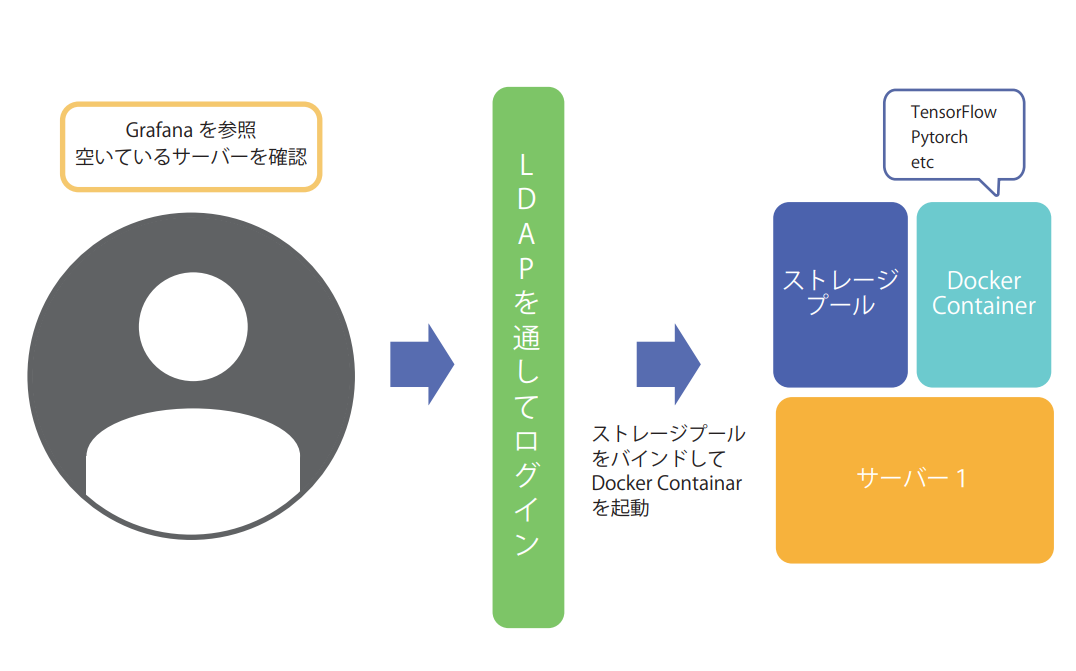
ユーザーは、
1.空いているサーバーを確認
2.空いているサーバーに対してLDAPを通じてログイン
3.ストレージプールをバインドして,必要なコンテナを起動。
4. 使い終わったらコンテナを削除する
の順番で活用します。
ストレージプールは全サーバで共有されているのでデータはすべてのサーバーで同じものが使えます。
これにより計算が必要な時だけ必要なコンテナを立ち上げることができます。
問題点
現状のシステムにはいくつか問題点があります。
1.コンテナを消し忘れるとTensorflowの場合GPUメモリを抱えたままとなります。この場合実験が終わっているのかそれとも消し忘れているのかが判断しずらく可用性低下の原因となっています。
2.今のシステムは研究室のメンバーが先着順にサーバを占有していきます。当研究室のサーバは性能にかなりばらつきがあるので、あるサーバで動いてもあるサーバでは動かないということが発生します。そのため軽いプログラムが性能が高いサーバで動いて思いプログラムが低性能なサーバで動いているという状況が発生します。
結論
多少問題はあるものの構成が柔軟で大学の研究室のニーズは十分に満たしていると思います。
今後はKubeflowなどの導入の検討しつつ改善しています。
意見がありましたらコメントお願いします。