【目次】
1. はじめに
2. 実行環境
3. pythonの実行環境の準備
4. データセットの基礎調査
5. データセットのクレンジング
6. 可視化
7. 優良顧客の特徴分析
8. おわりに
1. はじめに
Aidemyのデータ分析講座の締めくくりの成果物を作るために、Kaggleのデータセットを眺めていところ、顧客の購買行動のデータセット"Customer Analysis"を見つけました。
どこかのお店(多分スーパー)の売上やキャンペーンに対する反応が、顧客ごとに集計されたデータです。
以前、BtoCの小売企業で顧客分析をしていたことがあるので、当時の経験とAidemyで学んだことを組合わせて、基礎的な分析をしてみようと思います。
2. 実行環境
- PC:Widow surface 7 pro
- 言語:python3.12.1
- 使用サービス:Google Colaboratory
3. pythonの実行環境の準備
まず、必要なライブラリをインポートします。
# 基本操作
import pandas as pd
import numpy as np
from google.colab import drive
import os
import shutil
# 可視化
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
# ロジスティック回帰
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# その他
import re
import datetime
import warnings
import random
4. データセットの基礎調査
まずデータセットの構造を把握するために、基礎調査を行います。
- step1: データセットの読込み
- step2: データセットの基礎調査
- 何行何列で構成されているのか?
- データ型は?
- 欠損値はあるか?
- 格納されているのはどんな値か?
このプロセスで「何を表しているデータなのか」がわかり、「どんな分析ができそうか」「どのようにクレンジングするか」といった方向性が見えてきます。
尚、基礎統計量や分布については、「5. 基礎集計と可視化」のところで扱います。
では、早速やってみましょう。
step1. データセットの読込み
Kaggleの下記サイトからCSVをダウンロードします。(ファイル名:"marketing_campaign.csv")
その際、サイトに記載されている各カラムの説明データもコピーしてテキストファイルに貼り付け、保存します。(ファイル名:"marketing_campaign_cols.txt")
https://www.kaggle.com/datasets/imakash3011/customer-personality-analysis
2つのファイルをMyDrive配下のCustomer_Analysisというディレクトリの配下に置き、下記コードでデータフレームとして読込みます。
(※Google Colaboraoryはローカルにアクセスできないので、Google Driveにデータを置く必要があります)
# MyDriveをマウントする
drive.mount('/content/drive')
# MyDrive配下のディレクトリ"Custoemr_Analytics"に保存したCSVを読み込む
main_dir = os.path.join("/content/drive/MyDrive/Aidemy_DataSet/", "Customer_Analysis")
file_path_sales = os.path.join(main_dir,'marketing_campaign.csv')
file_path_cols = os.path.join(main_dir,'marketing_campaign_cols.txt')
# 売上データ
df = pd.read_csv(file_path_sales, sep='\t')
df.head()
# カラムの説明データ
cols_details = pd.read_table(file_path_cols, sep=':',names=['col_name', 'col_meaning'])
cols_details
# 行と列の数
print(df.shape)
# >>> (2240, 29)
売上データの最初の5行がこちら。行と列は2240×29です。

各列の説明データはこんな感じです。
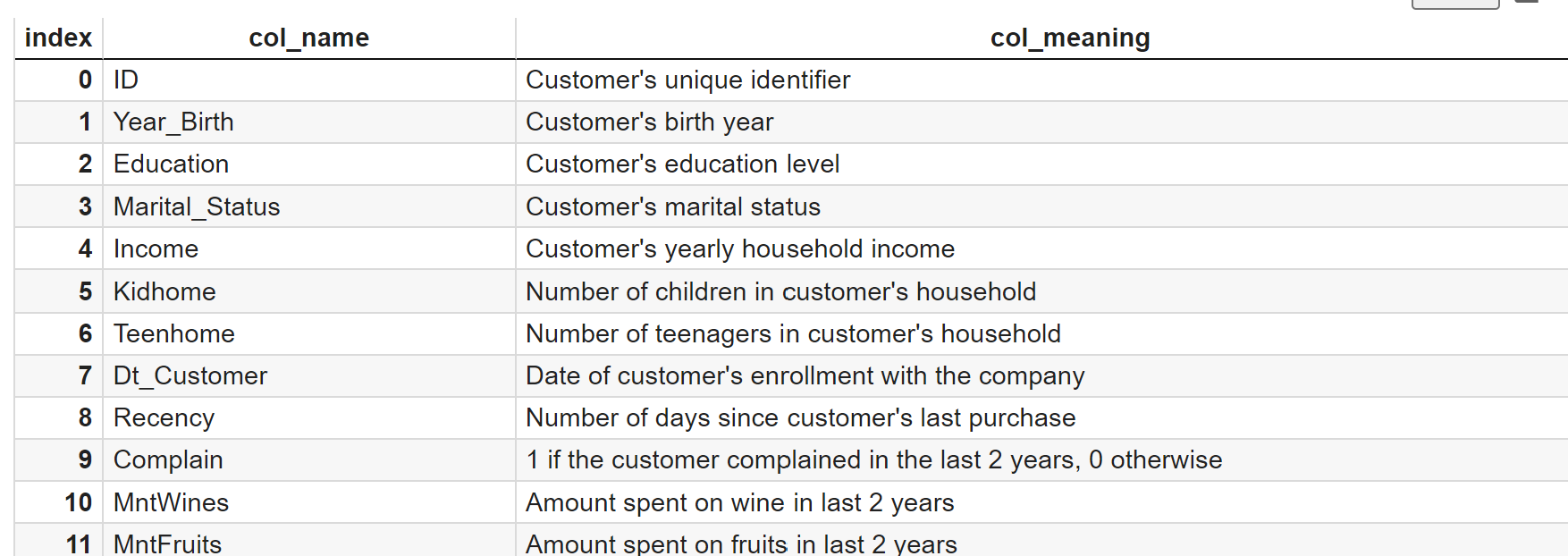
step2: データセットの基礎調査
より具体的にデータの中身を見ていきたいので、29個のカラムの意味・データ型・値のサンプル・欠損しているレコード数・ユニークのレコード数を一覧化します。(今後、この一覧のことを便宜上「テーブル定義書」と呼びます。データベースの管理業務における厳密なお作法に則っていないことはご容赦ください![]() )
)
### 列ごとのデータ型、データサンプル、欠損値の数をデータフレームにする(何度か使うかもしれないので、関数にしておく)
def func_data_definition(df):
# データ型
dtype_sr = df.dtypes
# print(dtype_sr[:3])
# >>>
# ID int64
# Year_Birth int64
# Education object
# 欠損値の数
nullcnt_sr = df.isnull().sum()
# print(nullcnt_sr[:3])
# >>>
# ID 0
# Year_Birth 0
# Education 0
# データサンプル(上限5つ)と、ユニークカウント
sample_list = []
unicnt_list = []
for col in df.columns:
uq = sorted(df[col].unique())
sample, unicnt = ",".join(map(str, uq[:5])), len(uq)
sample_list.append(sample)
unicnt_list.append(unicnt)
sample_sr = pd.Series(sample_list, index=df.columns)
unicnt_sr = pd.Series(unicnt_list, index=df.columns)
# print(sample_sr[:3])
# >>>
# ID [0, 1, 9, 13, 17]
# Year_Birth [1893, 1899, 1900, 1940, 1941]
# Education [2n Cycle, Basic, Graduation, Master, PhD]
# print(unicnt_sr[:3])
# >>>
# ID 2240
# Year_Birth 59
# Education 5
df_info_base = pd.DataFrame({'data_type':dtype_sr, 'sample':sample_sr, 'unique_cnt': unicnt_sr, 'null_cnt':nullcnt_sr})
df_info_base.reset_index(inplace= True)
df_info_base.rename(columns={'index':'col_name'}, inplace=True)
df_info_base = pd.merge(df_info_base, cols_details, on='col_name', how='left')
return df_info_base
df_info_base = func_data_definition(df)
display(df_info_base)
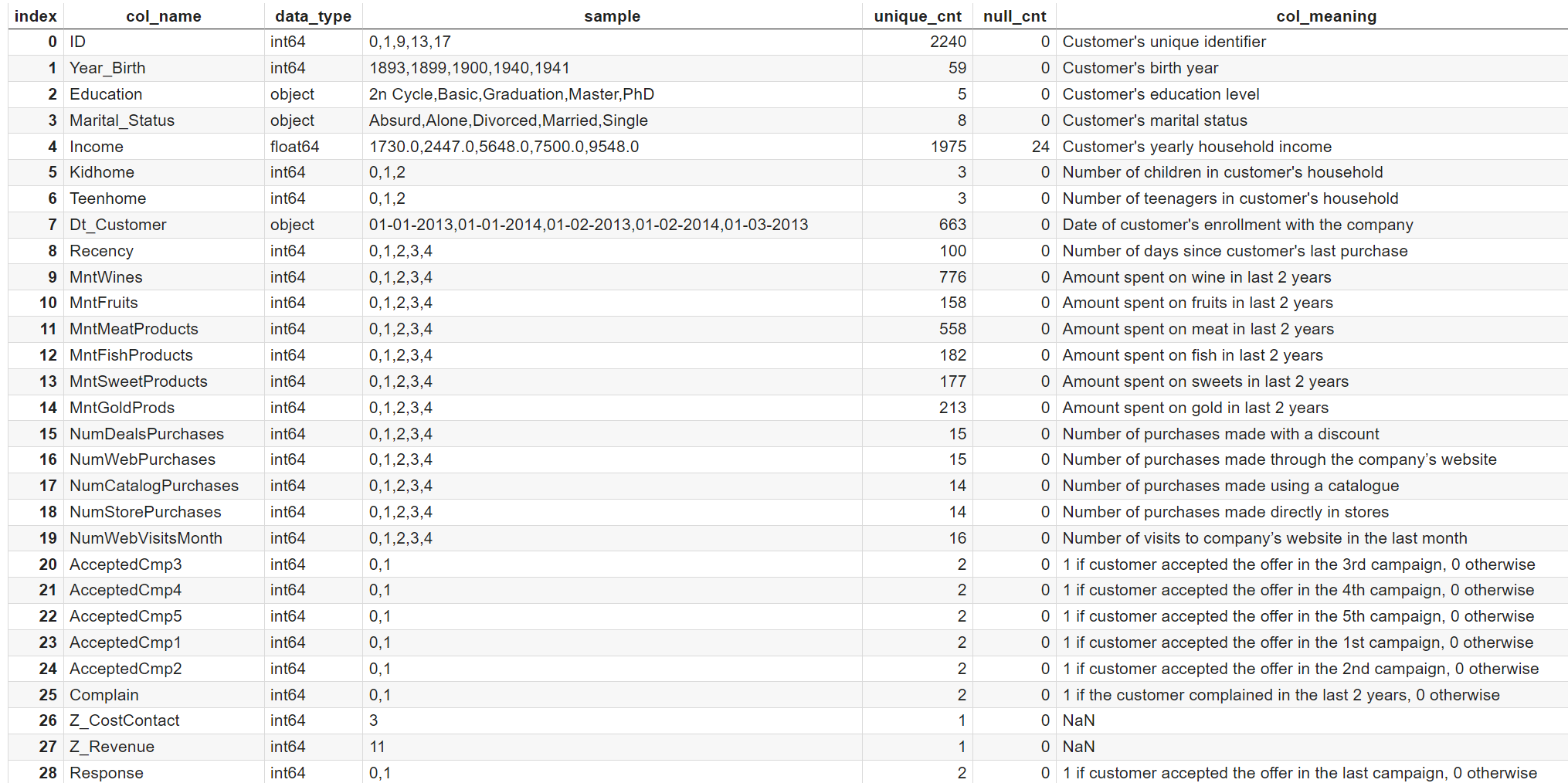
だいぶデータのイメージがつかめてきました!
IDはその名の通り顧客に振られるユニークなIDです。
レコード数とunique_cntがどちらも2240で、1IDにつき1レコードになっていますね。
つまり、このデータはPOSのような買い物単位の明細ではなく、ID単位でのデータです。
データの種類を整理すると、ざっくりこんな感じでしょうか。
- 属性:Year_Birth, Education, Marital_Status, Income, Kidhome, TeenHome, Dt_Customer
- 購入数:Mnt〇〇(MntWinesなど)
- 購買チャネル:Num〇〇(NumWebPurchaseなど)
- キャンペーンへの反応:AcceptedCmp〇(AcceptedCmp3など)
- その他:Response, Complain, Z_CostContact, Z_Revenue
クレンジングは、ひとまず下記で進めようと思います。
- ID:数値型になっているので、文字列に変換したい
- Year_Birth:年齢に変換し、かつ10歳区切りにしたい
- Income:欠損が24レコードあるので、削除もしくは穴埋め
- Dt_Customer:文字列になっているので、日付型に変換したい。また、顧客になってからの経過日数として"Customer_Days"を算出したい
- 値が1か0のカラムすべて:Boolean値なので、数値型から文字列に変換したい
- Response:col_meaningでは「最後のキャンペーンへの反応」とのこと。わかりづらいので、カラム名を"AcceptedCmp6"に変えたい
- NumDealsPurchase:col_meaningでは「割引で購入した回数」とのこと。わかりづらいので、カラム名を"NumDiscountPurchase"に変えたい
- NumWebVisitMonth:col_meaningは「先月Web訪問した回数」とのこと。分析の用途が限られており、今回は使わなさそう→削除したい
- AcceptedCmp〇〇:計6回のキャンペーンに反応した回数の合計として、"AcceptedCmp_total"を作成したい
- MntProducts〇〇:各アイテムの購入数を合計した"MntProucts_total"を作成したい
- Num〇〇:Web/Catalog/Storeの各訪問数を合計した"NumVisit_total"を作成したい
- Z_CostContact, Z_Revenue:col_meaningがNaN(=col_detailsに含まれていない)、unique_cntが一つ(=すべて同じ値)なので、分析に使えそうにない→削除したい
5. データセットのクレンジング
先ほど決定した方針を、下記4stepで実行していきます。
尚、欠損値の処理(Income)については、値の分布を確認してから方法を決めたいので、可視化の後に実行します。
- step1. データ型の修正
- step2. カラム名の修正
- step3. 新しいカラムの作成
- step4. 不要カラムの削除
step1. データ型の修正
- ID: 数値→文字列
- Dt_Customer: 文字列→日付
- 値が0/1のカラムすべて: 数値→文字列
### ID列をintからstrにする
# 桁を確認
print(min(df['ID']),max(df['ID']))
# >>>
# 0 11191
# strにしてから、5桁でzeropadding
df['ID'] = df['ID'].apply(lambda x: str(x).zfill(5))
### Dt_Customer列をstrからdateにする
df['Dt_Customer'] = pd.to_datetime(df['Dt_Customer'], format='%d-%m-%Y')
### intだがcategoricalとして扱うべき列をstrにする
cat_columns = df_info_base.query('sample == "0,1"')['col_name'].values
print(cat_columns)
# >>>
# ['AcceptedCmp1' 'AcceptedCmp2' 'AcceptedCmp3' 'AcceptedCmp4'
# 'AcceptedCmp5' 'Complain' 'Response']
df[cat_columns] = df[cat_columns].astype(str)
### 動作確認
print(df.loc[:3, ['ID','Dt_Customer']])
# >>>
# ID Dt_Customer
# 0 05524 2012-09-04
# 1 02174 2014-03-08
# 2 04141 2013-08-21
# 3 06182 2014-02-10
print(df[cat_columns].dtypes)
# >>>
# AcceptedCmp1 object
# AcceptedCmp2 object
# AcceptedCmp3 object
# AcceptedCmp4 object
# AcceptedCmp5 object
# Complain object
# Response object
step2. カラム名の修正
- 「割引購入した回数」:NumDealPurchase → NumDiscountPurchase
- 「最後のキャンペーンに反応したか」:Reponse → AcceptedCmp6
df.rename(columns={'NumDealsPurchase': 'NumDiscountPurchase', 'Response':'AcceptedCmp6'}, inplace=True)
step3. 新しいカラムの作成
- Dt_Customer(顧客になった日付):Customer_Days(顧客になってからの経過日数), Customer_Year, Customer_Month, Customer_Day(年/月/日をそれぞれ抽出したもの)
- Year_Birth(生まれた年):Age(年齢), Age_gp(10歳区切り)
- AcceptedCmp〇 :AcceptedCmp_total(キャンペーンの反応回数の合計)
- Mnt〇〇 :MntProducts_total(各アイテムの購入数合計)
- Num〇〇 :NumVisit_total(Web/Catalog/Storeの訪問数合計)
上記2つを算出するには、「現在の日付」を起点とした日付同士の引き算が必要となるため、仮に「2015/1/1」とします。(Dt_Customer(顧客になった日付)の直近年が2014年だったため)
### 'Dt_Customer'からCustomer_Daysと、年/月/日をそれぞれ抽出した列を作成
# Customer_Days'(顧客になってからの経過日数)を作成(現在を"2015/1/1"とする)
now_date = datetime.datetime(2015,1,1)
df['Customer_Days'] = df['Dt_Customer'].apply(lambda x: (now_date - x).days)
print(df.loc[:5, ['Dt_Customer','Customer_Days']])
# >>>
# Dt_Customer Customer_Days
# 0 2012-09-04 849
# 1 2014-03-08 299
# 2 2013-08-21 498
# 3 2014-02-10 325
# 4 2014-01-19 347
# 5 2013-09-09 479
# 年/月/日のカラムを追加
df['Customer_Year'] = df['Dt_Customer'].dt.strftime('%Y')
df['Customer_Month'] = df['Dt_Customer'].dt.strftime('%m')
df['Customer_Day'] = df['Dt_Customer'].dt.strftime('%d')
# 年ごとのminとmaxの日付を確認(それぞれの年が12か月分あるのか)
year_check = df.groupby('Customer_Year').agg(min_date=("Dt_Customer", "min"), max_date=("Dt_Customer", "max"))
print(year_check)
# >>>
# min_date max_date
# Customer_Year
# 2012 2012-07-30 2012-12-31
# 2013 2013-01-01 2013-12-31
# 2014 2014-01-01 2014-06-29
# 注意点:2012年と2014年は半期分しかない→年ごとの比較はできない
### 'Yaear_Birth'列から'Age'列を作成(現在を"2015/1/1"とする)
df['Age'] = now_date.year - df['Year_Birth']
df['Age_gp'] = df['Age'].apply(lambda x: x // 10 * 10)
# 分布確認
print(df.groupby('Age_gp').agg({'Age':['min','max'],'ID':'count'}).reset_index())
# >>>
# Age_gp Age ID
# min max count
# 0 10 19 19 2
# 1 20 20 29 187
# 2 30 30 39 506
# 3 40 40 49 685
# 4 50 50 59 492
# 5 60 60 69 341
# 6 70 70 75 24
# 7 110 115 116 2
# 10代と20代はまとめる、60歳以上もまとめる
def func_age_regroup(age_gp):
if age_gp <= 20:
return "10&20"
elif age_gp >= 60:
return "60_over"
else:
return str(age_gp)
df['Age_gp'] = df['Age_gp'].apply(lambda x: func_age_regroup(x))
# 再度分布を確認
print(df.groupby('Age_gp').agg({'Age':['min','max'],'ID':'count'}).reset_index())
# >>>
# min max count
# 0 10&20 19 29 189
# 1 30 30 39 506
# 2 40 40 49 685
# 3 50 50 59 492
### 各AcceptedCmp〇の合計の列'AcceptedCmp_total'(キャンペーン反応回数の合計)を作成
# AcceptedCmpで始まる列名のリスト
cmp_columns = df.columns[df.columns.str.startswith('AcceptedCmp')]
# 合計列を作成
df['AcceptedCmp_total'] = df[cmp_columns].apply(lambda x: sum(x.astype(int)), axis=1)
### 各Mnt〇〇の合計の列'MntProducts_total(購買数の合計)を作成
# Mntで始まる列名のリスト
mnt_columns = df.columns[df.columns.str.startswith('Mnt')]
# 合計列を作成
df['MntProducts_total'] = df[mnt_columns].apply(lambda x: sum(x.astype(int)), axis=1)
### 各Num〇〇の合計の列'NumVisit_total'(訪問回数の合計)を作成
# Numで始まる列名のリスト(※NumWebVisitsMonth'と 'NumDealsPurchases'は意味が異なるので対象外)
# 合計列を作成
num_columns = ['NumWebPurchases', 'NumCatalogPurchases', 'NumStorePurchases']
df['NumVisit_total'] = df[num_columns].apply(lambda x: sum(x.astype(int)), axis=1)
step4. 不要カラムの削除
分析に使わないカラムは削除します。
# col_meaningがない列や、他の情報に加工済みでもう使わない列は削除する
delete_columns = ['Z_CostContact', 'Z_Revenue', 'Age', 'Year_Birth','Dt_Customer','NumWebVisitsMonth']
df.drop(columns = delete_columns, inplace=True)
6. 可視化
データ特性をより詳しくつかむための可視化のプロセスに入ります。
各カラムごとに実施していくのですが、ただ一つ一つ可視化してもイメージがつかみづらいので、大まかな分析軸ごとにまとめて見ていきたいと思います。
また、可視化の仕方も、カテゴリ値のカラムは構成比の横棒グラフ、連続値のカラムはヒストグラムと、使い分けます。
可視化の後、欠損値/外れ値の処理や、再クレンジングも必要になるので、下記stepに分けて実施していきます。
- step1. データ定義書の更新
- step2. カテゴリ値のカラムの可視化
- step3. 連続値のカラムの可視化
- step4. 欠損値/外れ値の処理
- step5. 連続値のカラムの相関の可視化
- step6. 連続値のカラムのカテゴリ化
- step7. カテゴリ値のカラムの再編成
step1. データ定義書の更新
クレンジング後のデータでデータ定義書を更新し、連続値/カテゴリ値の分類と、分析軸を追加します。
可視化をfor文で実施する際に、こちらを活用します。
### クレンジング後のデータで定義書を更新する
df_info = func_data_definition(df)
### sampleの内容によって連続値かカテゴリ値かに分類する関数を作成
# 連続値の場合:continuous
# カテゴリ値(文字列だけではなく数値型だが[0,1]になっている列も含む): categorical
def func_data_type(unique_cnt, data_type):
if (data_type == object) or (unique_cnt == 2):
return "categorical"
else:
return "continuous"
### 分析軸ごとに{分析軸の名前:該当データ項目のリスト}の辞書を作成
# 人物属性
people_attrs = {'people': ['Education','Marital_Status','Kidhome','Teenhome','Age_gp', 'Income']}
# 顧客属性
customer_attrs = {'customer': ['Customer_Days','Recency','Complain']}
# キャンペーンに対する反応
campaign_attrs = {'campaign': df.columns[df.columns.str.startswith('AcceptedCmp')].values.tolist()}
# 購買商品
products_attrs = {'products': df.columns[df.columns.str.startswith('Mnt')].values.tolist()}
# 購買チャネル
channel_attrs = {'channel': df.columns[df.columns.str.startswith('Num')].values.tolist()}
# その他
others_attrs = {'others': ['ID','Customer_Year', 'Customer_Month', 'Customer_Day']}
## 辞書を統合
attrs_dict = dict(**people_attrs, **customer_attrs, **campaign_attrs, **products_attrs, **channel_attrs, **others_attrs)
# 内容確認、およびKeyとValueを逆にした辞書も作成
attrs_dict_rev = {}
for key, val in attrs_dict.items():
print(key, ':', val)
for v in val:
attrs_dict_rev[v] = key
# >>>
# people : ['Education', 'Marital_Status', 'Kidhome', 'Teenhome', 'Age_gp', 'Income']
# customer : ['Customer_Days', 'Recency', 'Complain']
# campaign : ['AcceptedCmp3', 'AcceptedCmp4', 'AcceptedCmp5', 'AcceptedCmp1', 'AcceptedCmp2', 'AcceptedCmp6', 'AcceptedCmp_total']
# products : ['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds', 'MntProducts_total']
# channel : ['NumDiscountPurchase', 'NumWebPurchases', 'NumCatalogPurchases', 'NumStorePurchases', 'NumVisit_total']
# others : ['ID', 'Customer_Year', 'Customer_Month', 'Customer_Day']
### data_infoに連続値/カテゴリ値の分類と、分析軸を追加する
df_info['data_type2'] = df_info[['unique_cnt', 'data_type']].apply(lambda x: func_data_type(x[0],x[1]),axis=1)
ex_list = ['Kidhome', 'Teenhome', 'AcceptedCmp_total']
df_info.loc[df_info['col_name'].isin(ex_list), 'data_type2'] = 'categorical' #実際はカテゴリ値ではないが、見やすさの面でカテゴリ値扱いとしたい
df_info['attr'] = df_info['col_name'].apply(lambda x: attrs_dict_rev[x])
df_info = df_info.sort_values(['attr','data_type2','unique_cnt','col_name']).reset_index(drop=True)
display(df_info)
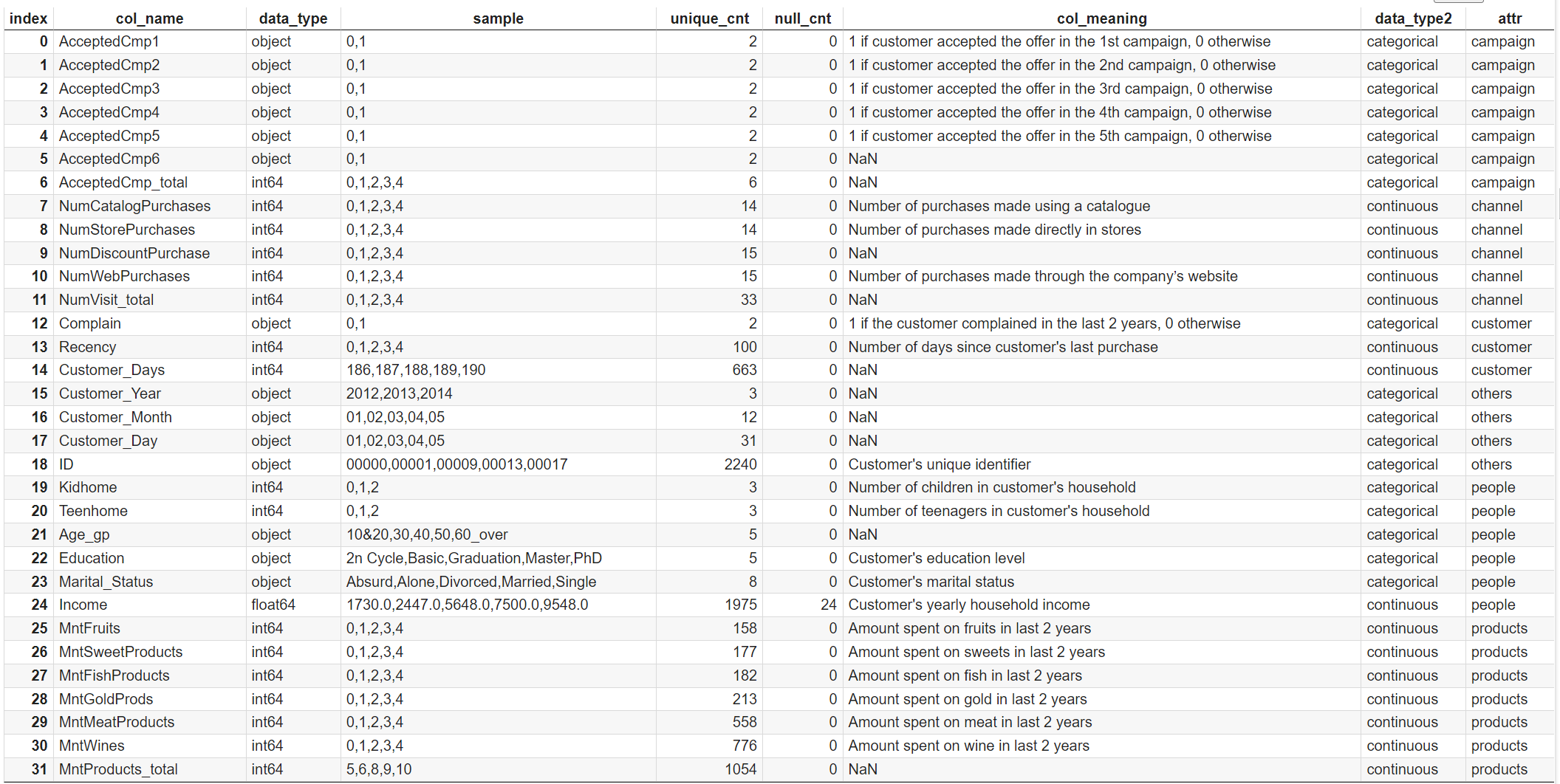
step2. カテゴリ値のカラムの可視化
カテゴリ値の分布を、構成比の横棒グラフで可視化します。
構成比の可視化では円グラフや積み上げ棒グラフが使われやすいですが、ケースバイケースだとは思うものの、基本見づらいと感じてしまいます。
個人的には、度数の横棒グラフの構成比バージョンが一番見やすくて好みです。
### 指定した分析軸に紐づくカテゴリ値のカラムの、構成比の横棒グラフを作成する関数
def func_cat_attr_graphs(attr_name):
# attr_name(例:people)に紐づくカラム名を抽出
cols = attrs_dict[attr_name]
# >>>['Education', 'Marital_Status', 'Kidhome', 'Teenhome', 'Age_gp, 'Income']
# attr_name(例:people)に紐づくカラム名のうち、data_type2が"categorical"のカラム名のみ抽出
cols_target = df_info.query('col_name in @cols and data_type2 == "categorical"')['col_name'].values.tolist()
# >>>['Age_gp', 'Education', 'Marital_Status']
# たまにカテゴリ値の列がないこともあるので、cnt > 0のときのみグラフを描画をするという条件をつける
g_cnt = len(cols_target)
if g_cnt > 0:
# 1画面に描画するグラフ枠のうち、縦の数(nrows)を算出する ※横の数(ncols)は3で固定するので、算出不要
ncols = 3
if g_cnt == 1:
nrows = 1
else:
if g_cnt % ncols == 0:
nrows = g_cnt // ncols
else:
nrows = g_cnt // ncols + 1
# グラフ描画サイズを設定(横は固定なので縦のみ)
fsize = (10, nrows * 2.5)
# グラフ枠を作成
# ・"tight_layout=True":グラフ同士の文字列が重ならないように配置する
fig = plt.figure(figsize=fsize, tight_layout=True)
plt.suptitle(attr_name, fontsize=20)
for i in range(g_cnt):
# 描画するデータを抽出
col_name = cols_target[i]
cat_cnt = df[col_name].astype(str).value_counts(normalize=True).sort_index(ascending=False)
labels, values = cat_cnt.index, cat_cnt.values
# グラフ描画
ax = fig.add_subplot(nrows, ncols, i+1)
ax.barh(labels, values, align="center", color='c')
ax.set_yticks(range(len(labels))) #ラベルの位置を指定。これを省くとwarningが出る
ax.set_yticklabels(labels, fontsize=10)
ax.xaxis.set_major_formatter(matplotlib.ticker.PercentFormatter(1))
ax.set_title(col_name)
for i, val in enumerate(values): #データラベルの追加
ax.text(x = 0.01, #表示位置の横の座標
y = i, #表示位置の縦の座標
s = '{:.1%}'.format(val), #表示する値
ha = 'left',
va = 'center')
# グラフ表示
plt.show()
### 各分析軸ごとに可視化
for attr in attrs_dict.keys():
if attr != 'others':
func_cat_attr_graphs(attr)
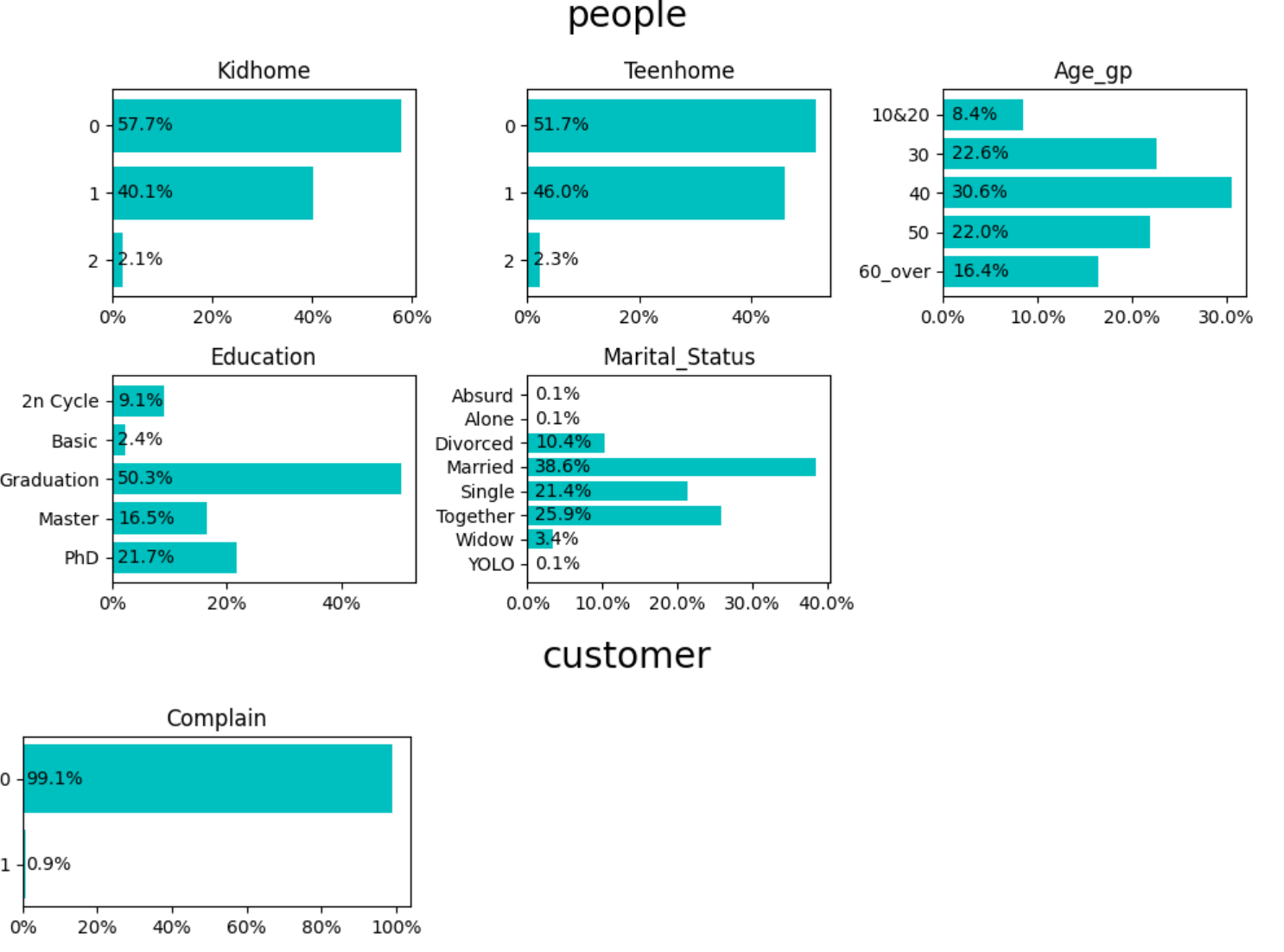
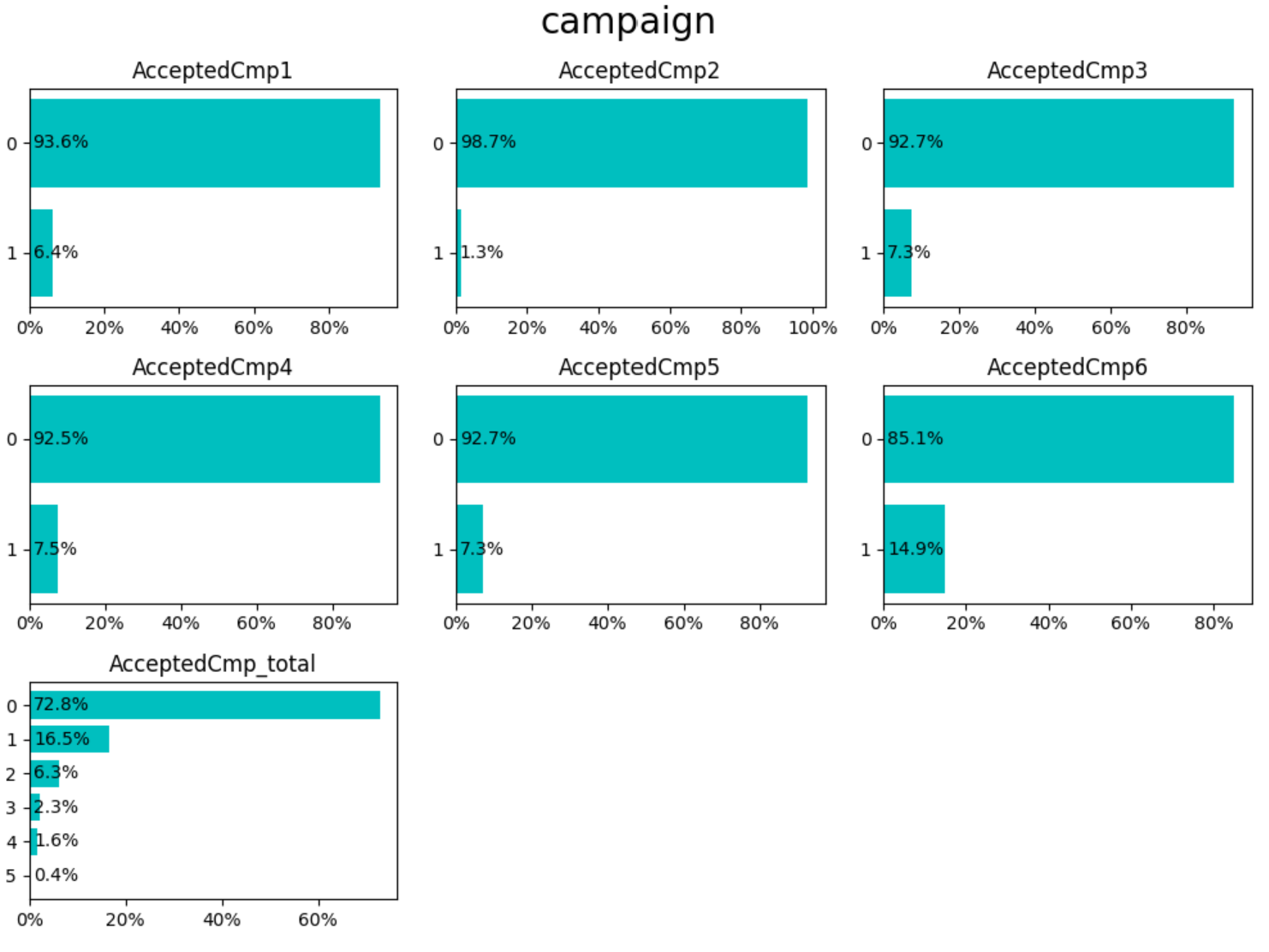
この可視化で気づいたことをまとめておきます。
People
- KidhomeとTeenHome:
- ほぼ同じ分布なのでどちらか一方のみでよさそう。上位概念であるKidhomeだけ使えばいいのでは
- 顧客の半分以上が子供と同居していない
- [2](2人)は2%くらいなので、[1](1人)と一緒にして「1人以上」としてまとめたい → 実質Boolean値(0/1)になる
- Age_gp:
- ボリュームゾーンは30代・40代・50代で、全体の75%
- Education:
- 一番多いのはGraduation(50%)だが、Master(16.5%)とPhD(21.7%)もわりと多い
- 2nCycle(9.1%)は修士課程らしい。PhDに含めてよさそう
- Basic(2.4%)はGraduationに含めてよさそう
- MaritalStatus:
- AbusurdとYOLOはまともに回答する気がなさそう。Otherとしてまとめても0.2%なので、Singleに含める
- AloneもSingleに含める
- widowとDivorcedは「もともと結婚していたが、今は一人という意味で同じなので「Formerly married」にする?
- Togetherは「同居者がいる」という意味ではMarriedと同じだが、同性カップルや、異性カップルでもあえて結婚しないなど、やや特殊な感じがするので分けておく
Customer
- Complain:
- [1]が0.9%なので、苦情をいう客はほぼいない
- 分析にはあまり使えなさそう
Campaign
- 2回目のみ反応が悪く1.3%だが、1回目と3-5回目は6-7%、6回目は15%超(2回目と6回目が特殊?)
- totalCntで、0回、1回、2回以上でまとめてよさそう
step3. 連続値のカラムの可視化
続いて、連続値のカラムをヒストグラムで可視化していきます。
外れ値があるとその度数の棒は見えづらくなるので、縦軸は対数表示にしています。(何人くらいいるのかはわかりづらくなりますが、「分布の形の見やすさ」を優先しています)
また、基本統計量の数値も追加しています。
### 指定した分析軸に紐づく連続値のヒストグラムを作成する関数
def func_num_attr_graphs(attr_name):
# attr_name(例:people)に紐づくカラム名を抽出
cols = attrs_dict[attr_name]
# attr_name(例:people)に紐づくカラム名のうち、data_type2が"continuous"のカラム名のみ抽出
cols_target = df_info.query('col_name in @cols and data_type2 == "continuous"')['col_name'].values.tolist()
# たまにカテゴリ値の列がないこともあるので、cnt > 0のときのみグラフを描画をするという条件をつける
cnt = len(cols_target)
if cnt > 0:
# 1画面に描画するグラフ枠のうち、縦の数(nrows)を算出する ※横の数(ncols)は3で固定するので、算出不要
ncols = 3
if cnt == 1:
nrows = 1
else:
if cnt % ncols == 0:
nrows = cnt // ncols
else:
nrows = cnt // ncols + 1
# グラフ描画サイズを設定(横は固定なので縦のみ)
fsize = (10, nrows * 3)
# グラフ枠を作成
fig = plt.figure(figsize=fsize, tight_layout=True)
plt.suptitle(attr_name, fontsize=20)
for i in range(cnt):
# 描画するデータを抽出
col_name = cols_target[i]
num_data = df[col_name]
# グラフ描画
ax = fig.add_subplot(nrows, ncols, i+1)
ax.hist(num_data,color = 'b',alpha = 0.3, ec='black', log=True) #外れ値が見えやすいようにy軸を対数に
ax.set_title(col_name)
# グラフ表示
plt.show()
# 統計量を表示( floatの表示方法を、小数点以下1桁で設定する処理をつけておく)
pd.options.display.float_format = '{:.1f}'.format
print(df[cols_target].describe())
pd.reset_option('all')
### 各分析軸ごとに可視化
for attr in attrs_dict.keys():
if attr != 'others':
func_num_attr_graphs(attr)
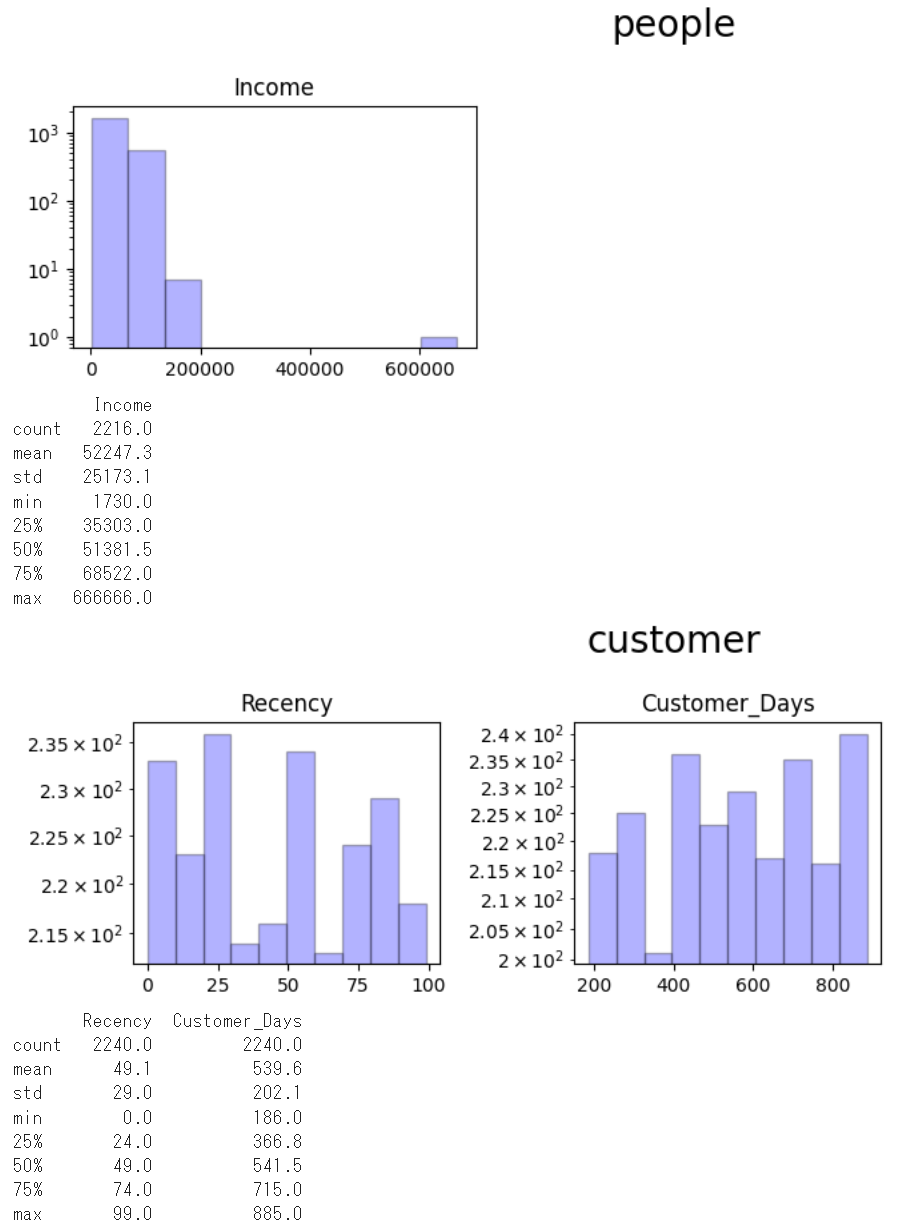
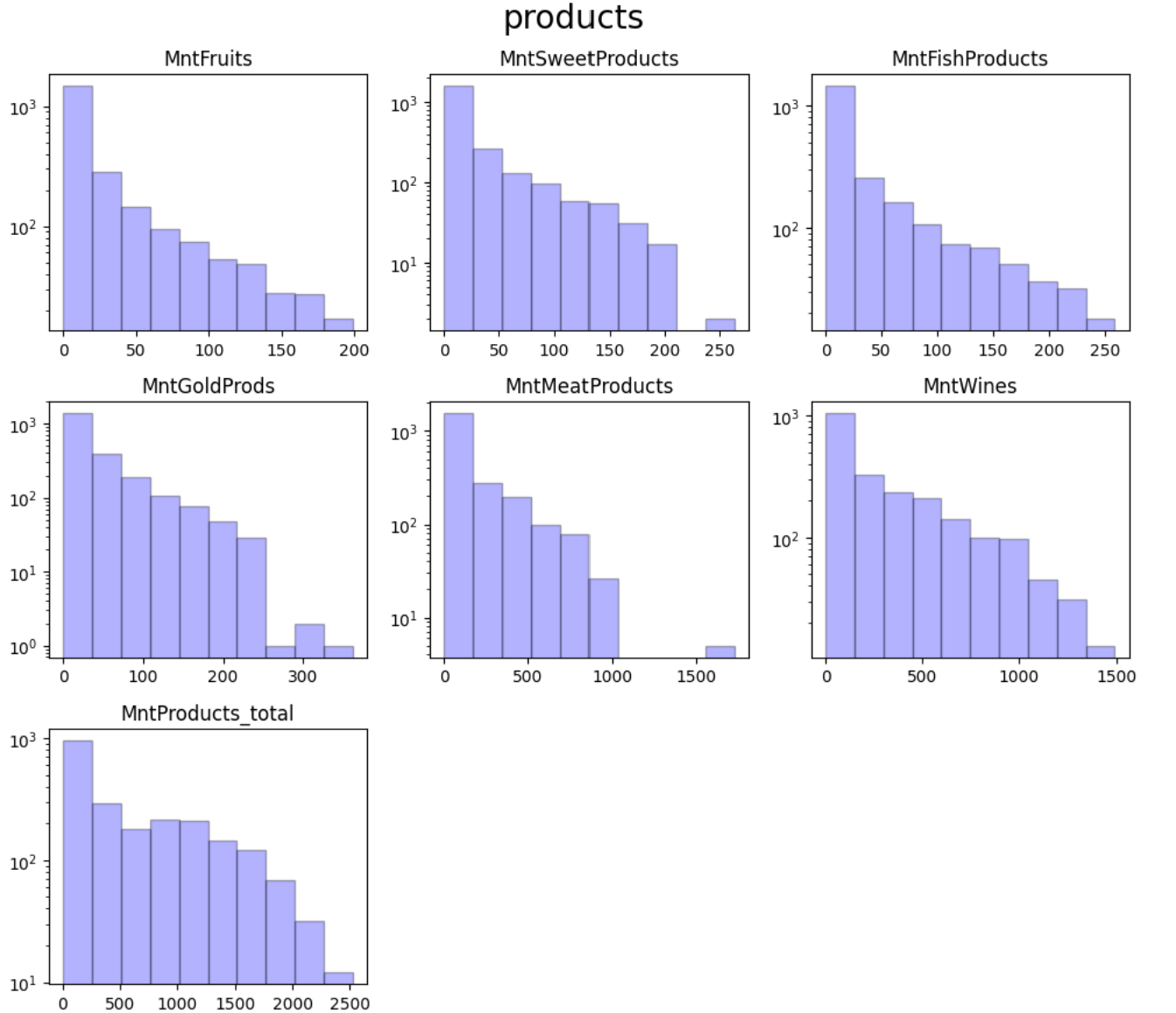
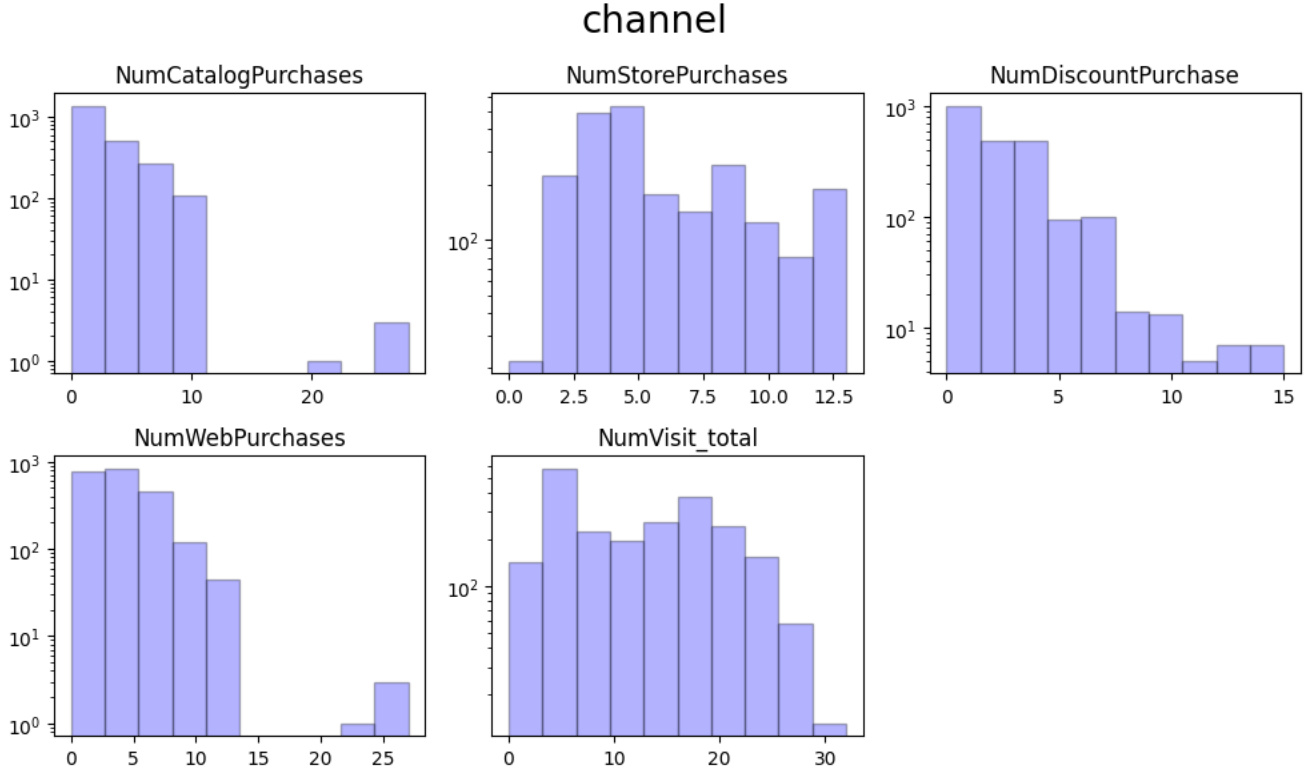
ここでも、気づいたことをまとめておきます。
People
- Income
- 外れ値がある。「666,666」と6だけの6桁の数字なので、適当に書いているような印象を受ける → NULL扱いにする
- 平均値/中央値はさほど変わらないが、外れ値がなければ中央値のほうが小さくなりそう→ 欠損は中央値で補完する
Customer
- Recency
- 平均値/中央値とも49日。日用品の買い物であれば1週間に1回は来そうなので、平均値/中央値はもっと小さい値になるかと思った。普通のスーパーではない?
- Customer_Days
- 特になし
Products
- MeatとWineの標準偏差が大きく、ロングテールになっている
- 高級肉とワインが売れ筋のデパ地下のようなお店?
Channel
- Store訪問が一番多い
- WebとCatalogは同じような分布で、外れ値がある→外れ値といっても27,28くらいなので特に処理せずそのままにする
step4. 欠損値/外れ値の処理
Incomeのカラムを、異常値(666666)のレコードを削除してから中央値で補完します。
# NULLが含まれる列も一応残しておく(後で属性に偏りがあるか調査するため)
df['Income_with_NULL'] = df['Income']
#異常値と思われるレコードを削除
df = df.query('Income != 666666').copy().reset_index(drop=True)
# 中央値で補完
df['Income'] = df['Income'].fillna(df['Income'].median())
step5. 連続値のカラムの相関の可視化
連続値のカラム同士で相関があるかを確認します。
まずはヒートマップで可視化してみます。
### 数値列を抽出
# print(df.select_dtypes(include='number').columns)
# >>>
# Index(['Income', 'Kidhome', 'Teenhome', 'Recency', 'MntWines', 'MntFruits',
# 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
# 'MntGoldProds', 'NumWebPurchases', 'NumCatalogPurchases',
# 'NumStorePurchases', 'Customer_Days', 'AcceptedCmp_total',
# 'MntProducts_total', 'NumVisit_total', 'Income_NULL_flg',
# 'Income_with_NULL'],
# dtype='object')
target_col_list = ['Income','Recency','Customer_Days', 'AcceptedCmp_total',
'MntWines', 'MntFruits','MntMeatProducts', 'MntFishProducts', 'MntSweetProducts','MntGoldProds'
,'NumWebPurchases', 'NumCatalogPurchases', 'NumStorePurchases','NumDiscountPurchase']
### ヒートマップで可視化
corr_data = df[target_col_list].corr()
sns.heatmap(
corr_data,
vmax = 1,
vmin = -1,
annot=True,
fmt='.1f',
annot_kws={'fontsize': 8, 'color':'black'})
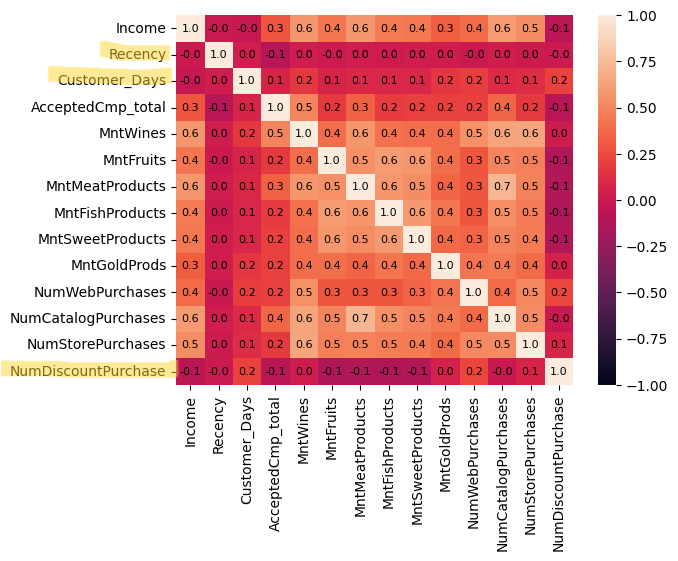
カラムが多すぎるせいか、一目見てインサイトが得られる、という感じではないですね。
Recency・Customer_Days・NumDiscountPurchaseが、全体的にほかのカラムとの相関が弱いとうことくらいでしょうか。
シンプルに「相関が強いのはどのカラムの組み合わせか」を知りたいので、ランクをつけてTOP5とWORST5を抽出してみます。
### ヒートマップだとわかりづらいので、相関係数のTOP5とWORST5を抽出
corr_data_st = corr_data.stack().reset_index()
corr_data_st.columns = ['col1', 'col2', 'corr']
corr_data_st['col_set'] = corr_data_st[['col1', 'col2']].apply(lambda x: '-'.join(sorted([x[0], x[1]])), axis=1)
corr_data_st = corr_data_st.drop_duplicates(subset='col_set')
corr_data_st = corr_data_st.query('corr < 1').copy()
corr_data_st.drop(columns='col_set', inplace=True)
# TOP5
print('【正の相関 TOP5】')
display(corr_data_st.sort_values('corr', ascending=False).reset_index(drop=True).head())
# WORST5
print('【負の相関 WORST5】')
display(corr_data_st.sort_values('corr', ascending=True).reset_index(drop=True).head())
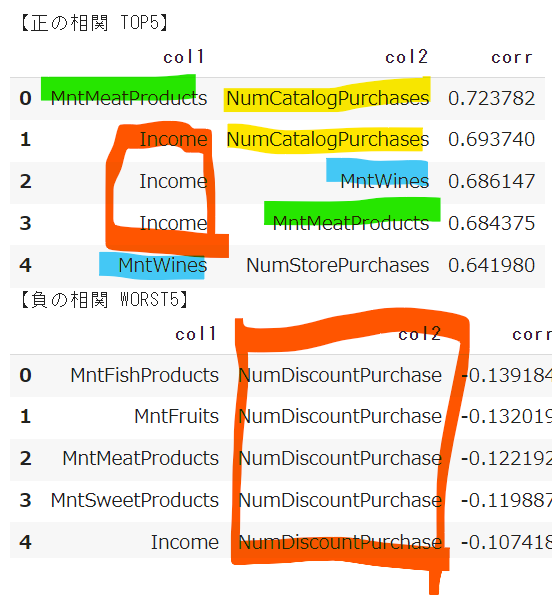
なかなかおもしろい結果になりました。
正の相関TOP5のうちIncomeとMntMeat・MntWines・NumCatalogPurchasesの相関が強く、ハイソサエティが強く匂う(?)感じがします。
ワインは店舗と、肉はカタログとの相関が強いのも興味深いです。
実務であれば、「どの商品をどのチャネルで何個買ったか?」というデータを取りに行きたいところです。
一方、負の相関TOP5(といっても相関係数の絶対値がかなり小さいのでほぼ相関はないです。。)のうち、5つすべてNumDiscountPurchaseが入っており、うち4つはMnt〇〇、残りはIncomeとの組み合わせです。
「割引で購入した回数」と「商品の購入数」や「収入」が相関しないというのは、やはり高級店ぽい感じがします。
step6. 連続値のカラムのカテゴリ化
ここからは、後続の分析をしやすくするための加工です。
連続値のカラムを、3分位["01_low", "02_middle", "03_high"]でカテゴリ化します。
目的はRFMのセグメントを作ることなので、厳密にはRecency(R)・NumVisit_total(F)・ MntProducts_total(M)のみでいいのですが、他も使えるかもしれないので全部やっておきます。
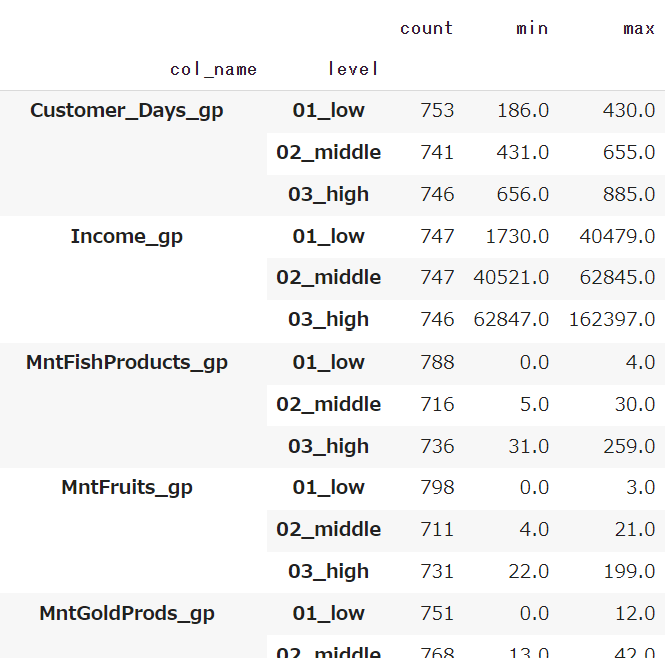
閾値についてはただprintして確認するだけでもいいのですが、後で確認しやすいようにデータフレームとして持っておきます。
### Income/Customer_Days/Recnecy/Mnt〇〇/Num〇〇を3分位で分割
qcnt = 3
check_df = pd.DataFrame(columns=['level','count','min','max','col_name'])
for col in ['Income', 'Customer_Days', 'Recency'] + attrs_dict['products'] + attrs_dict['channel']:
gp_col = col + '_gp'
#gp_list = [col + '_' + str(i).zfill(2) for i in range(1,qcnt + 1)]
gp_list = ['01_low', '02_middle', '03_high']
# Recencyに関しては、日数が少ないほど直近で来ている(=優良顧客)ので、ラベルのつけ方を逆にする
if col == 'Recency':
gp_list = sorted(gp_list, reverse=True)
df[gp_col] = pd.qcut(df[col], qcnt, labels = gp_list)
check = df.groupby(gp_col).agg({col: ['count', 'min', 'max']}).reset_index()
check.reset_index(drop=True)
check.columns = ['level','count','min','max']
check['col_name'] = gp_col
check_df = pd.concat([check_df, check], axis=0)
# 結果確認
check_df = check_df.groupby(['col_name', 'level']).max()
display(check_df)
step7. カテゴリ値のカラムの再編成
さきほどの可視化で振り返った通り、意味が近い値や数が少なすぎる値を統合します。
# Kidhome:0人は"No", 1人以上は"Yes"
df['Kidhome_gp'] = df['Kidhome'].apply(lambda x: 'Yes' if int(x) >= 1 else 'No')
# Education:
# ・2nCycleはPhDに含める
# ・BasicはGraduationに含める
def func_education(val):
if val == 'Basic':
return 'Graduation'
elif val == '2n Cycle':
return 'PhD'
else:
return val
df['Education_gp'] = df['Education'].apply(lambda x: func_education(x))
# MaritalStatus:
# ・Alone,Absurd,YOLOはSingleに含める
# ・Widow,DivoricedはFormery Marriedとしてまとめる
def func_maritalStatus(val):
if val in ('Alone', 'Absurd', 'YOLO'):
return 'Single'
elif val in ('Widow', 'Divorced'):
return 'Formerly Married'
else:
return val
df['Marital_Status_gp'] = df['Marital_Status'].apply(lambda x: func_maritalStatus(x))
# 結果確認
# floatの表示方法を、パーセントで小数点以下1桁まで設定する処理をつけておく)
pd.options.display.float_format = '{:.1%}'.format
for col in ['Kidhome', 'Education', 'Marital_Status']:
new_col = col + '_gp'
check = df[new_col].value_counts(normalize=True)
print(check)
print()
pd.reset_option('all')
# >>>
# Kidhome_gp
# No 57.7%
# Yes 42.3%
# Name: proportion, dtype: float64
# Education_gp
# Graduation 52.7%
# PhD 30.8%
# Master 16.5%
# Name: proportion, dtype: float64
# Marital_Status_gp
# Married 38.6%
# Together 25.9%
# Single 21.7%
# Formerly Married 13.8%
7. 優良顧客の特徴分析
データの特性が把握でき、データもだいぶ使いやすい形になりました。
ここからは、ビジネスに活用できるインサイトを見つけにいきたいと思います。
まずは王道の、「優良顧客の属性上・行動上の特徴は何か」を分析してみます。
具体的に言うと、優良顧客とそれ以外(一般顧客)に分類し、どの軸(カラム)が優良顧客であることに寄与しているのかを調査します。
分類においては、RFM分析を利用します。
調査においては、分布の比較・ロジスティック回帰を試してみたいと思います。
- step1. RFM分析による優良顧客と一般顧客の分類
- step2. 優良顧客と一般顧客の分布の比較
- step3. ロジスティック回帰モデルの説明変数のオッズ比調査
- step4. まとめ
step1. RFM分析による優良顧客と一般顧客の分類
RFM分析は、「現在から最終購入日までの日数(Recency)」「購入頻度(Frequency)」「購入金額(Monetary)」の3つの指標を用いて顧客をグループに分ける分析手法です
▼参考記事:
RFM分析とは?顧客分析の基本手法と施策例を解説
今回のデータにおいてRFMに相当するカラムは下記の通りです。
Mについては、本来は購入金額が相当しますが、今回のデータにはないので、購入数であるMntProducts_totalで代用します。
※注意点※
一点気になることとしては、MntProducts_totalは「過去2年間の購入数合計」なのですが、顧客になってからの経過日数(Customer_Days)が2年に満たない顧客が一定数いるということです。
本来であれば、条件を揃えるために分析母集団を「顧客になってから2年以上経過している顧客」に絞るべきですが、入会日(Dt_Customer)の期間が2012年7月-2014年6月と短いので、絞るとだいぶ人数が減ってしまいます。
もし自分が自由にデータ抽出できる立場であれば、せめて「過去半年」としたいところですが、できないので、今回は「過去2年間」という設定は一旦無視してそのまま進めます。
- R:Recnecy
- F:NumVisit_total
- M:MntProducts_total
さきほどのプロセスで、RFMのそれぞれの指標において、3分位によって3つのグループ「01_low」「02_middle」「01_high」に分けたと思います。
- Rの3セグメント:Recency_gp
- Fの3セグメント:NumVisit_total_gp
- Mの3セグメント:MntProducts_total_gp
つまり3×3×3で計9セグメントがあるわけです。
ただし、今回は優良顧客と一般顧客の2セグメントのみでいいので、この9セグメントをベースに分類の定義を考えたいと思います。
まず、単純に9セグメントそれぞれの人数分布と1人あたりの購入数を確認します。
rfm_seg_count = df.pivot_table(index=['MntProducts_total_gp', 'NumVisit_total_gp'],columns='Recency_gp', values='MntProducts_total', aggfunc='count', margins=True).applymap('{:,.0f}'.format)
rfm_seg_mean = df.pivot_table(index=['MntProducts_total_gp', 'NumVisit_total_gp'],columns='Recency_gp', values='MntProducts_total', aggfunc='mean', margins=True).applymap('{:,.0f}'.format)
print('【人数】')
display(rfm_seg_count)
print('【1人あたりの購入数】')
display(rfm_seg_mean)
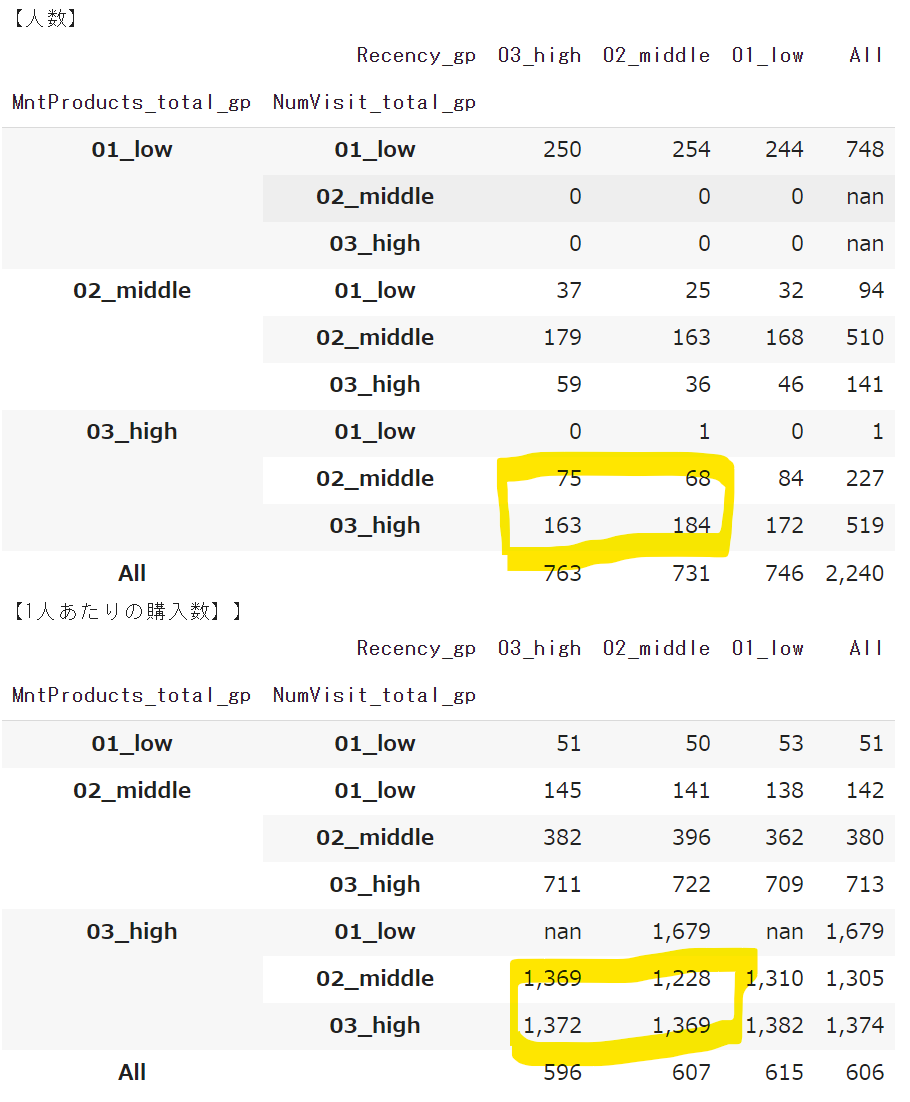
もちろん、一番の「優良顧客」と言えるのはRFMすべてにおいて「03_high」となっている163名ですが、ボリュームが少なすぎます。
1人当たりの購入数の大きさだけを見るのであれば、Mの「03_high」にあたる747名を「優良顧客」とみなしてもいいかもしれませんが、FとRが「01_low」の顧客は、現在進行形で定期的に購入しているというわけではなさそうなので、除外したいところです。
となると、優良顧客の定義は「Mが03_highで、FとRが01_low以外」ということになります。
この定義で優良顧客には"1"を、一般顧客には"0"を割り振る"Royal_flg"というカラムを追加し、人数やRFMの平均値を集計してみます。
### 優良顧客を判定する列(Royal_flg)を追加
df['Royal_flg'] = df[['MntProducts_total_gp', 'NumVisit_total_gp', 'Recency_gp']].apply(lambda x: '1' if x[0]=='03_high' and x[1]!='01_low' and x[2]!= '01_low' else '0', axis=1)
### 優良顧客(Royal_flg=1)と一般顧客(Royal_flg=0)のRFMの平均値と、人数・購入数の構成比を確認
check = df.groupby('Royal_flg').agg(
R_avg=('Recency', 'mean')
,F_avg=('NumVisit_total', 'mean')
,M_avg=('MntProducts_total', 'mean')
,Count=('ID','count')
,M_sum=('MntProducts_total', 'sum')
).reset_index()
check['Count_ratio'] = check['Count']/(check['Count'].sum())
check['M_sum_ratio'] = check['M_sum']/(check['M_sum'].sum())
check[['R_avg', 'F_avg', 'M_avg', 'Count', 'M_sum']] = check[['R_avg', 'F_avg', 'M_avg', 'Count', 'M_sum']].applymap('{:,.0f}'.format)
check[['M_sum_ratio', 'Count_ratio']] = check[['M_sum_ratio', 'Count_ratio']].applymap('{:.1f}'.format)
display(check)

結果、優良顧客は人数全体の20%とボリュームは少ないですが、購入数全体の50%を占めており、RFMの平均値も一般顧客を大きく上回っていることが確認できました。
step2. 優良顧客と一般顧客の分布の比較
属性・行動特性
まずは2つのセグメントの属性や行動特性の分布の違いを見ていきます。
それぞれのセグメントのN数を100としたときに、各カテゴリの分布がどうなるかを確認します。
### comparison_col(今回は優良顧客顧客/一般顧客)の区分ごとに、各カラムの分布をヒートマップを描画する関数
def func_heatmap(target_col_list, comparison_col):
# グラフ枠の数を設定(横は固定なので縦のみ)
g_cnt = len(target_col_list)
ncols = 3
if g_cnt % ncols == 0:
nrows = g_cnt // ncols
else:
nrows = g_cnt // ncols + 1
# グラフ描画サイズを設定(横は固定なので縦のみ)
fsize = (20, nrows * 4)
fig = plt.figure(figsize=fsize, layout='tight')
#plt.rcParams["font.size"] = 15 # すべてのフォントを一括で同じサイズにしたいときはこれを使う
plt.subplots_adjust(wspace=0.1, hspace=1)
for i, target_col in enumerate(target_col_list):
# 描画するデータを抽出
cross_df_columns = pd.crosstab(df[target_col], df[comparison_col], normalize='columns', margins=False)
y_labels = cross_df_columns.index
x_labels = cross_df_columns.columns
# ヒートマップを描画
ax = fig.add_subplot(nrows, ncols, i+1)
sns.heatmap(cross_df_columns, fmt='.1%', annot=True, lw=1, cmap='Blues', annot_kws={'fontsize': 15}, cbar=False)
ax.set_ylabel(target_col, fontsize=18)
ax.set_xlabel(comparison_col, fontsize=18)
ax.set_yticklabels(y_labels, size=15)
ax.set_xticklabels(x_labels, size=15)
#ax.set_title(target_col, fontsize=20)
# 見たいカラムを指定して、ヒートマップを描画
target_col_list = ['Age_gp','Marital_Status_gp','Education_gp', 'Kidhome_gp', 'Income_gp', 'Customer_Days_gp','AcceptedCmp_total']
comparison_col = 'Royal_flg'
func_heatmap(target_col_list, comparison_col)col, fontsize=18)
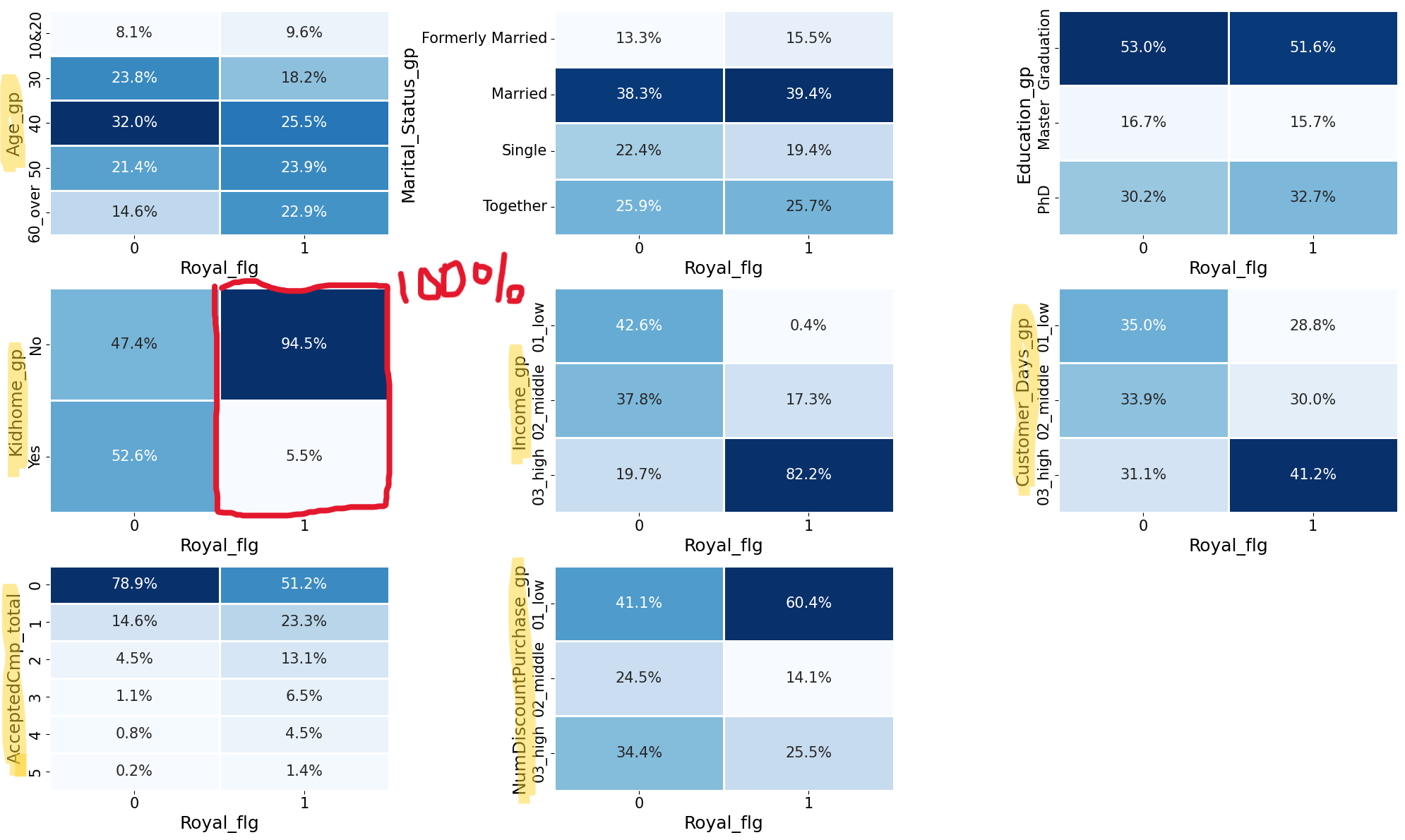
ヒートマップの見方を説明します。
2列あるうちの左が「Royal_flg = 0(一般顧客)」を母集団とする構成比、右が「Royal_flg = 1(優良顧客)」を母集団とする構成比です。
それぞれの列の縦の合計が100%となります。
例えば、中断の"Kidhome_gp"(子供と同居しているかどうか)のヒートマップにおいては、優良顧客のうち"No"と回答しているのは94.5%ですが、一般顧客では"No"と回答しているの47.4%しかおらず、分布の仕方に大きな違いがあります。
このように分布の仕方の差異が大きいところに注目すると、優良顧客の特徴について、下記のことがわかります。
★をつけた軸は、特に大きな差異があります。
- Age_gp:年齢層が高い人の割合が高い
- KidHome_gp:子供がいない人の割合が高い(★)
- Income_gp:収入が高い人の割合が高い(★)
- Customer_Days_gp:登録後経過日数が長い人の割合が高い
- AcceptedCmp_total:キャンペーン反応回数が多い人の割合が高い(★)
- NumDiscountPurchase_gp: 割引をあまり利用しない人の割合が高い(★)
子供が独立したシニア、もしくは、まだ子供がいない働き盛りで、高収入の人たちです。
一般顧客よりも割引を利用することは少なくても、キャンペーンに対する反応は高め。
キャンペーンが全顧客を対象にするのか、何らかの条件を満たした人だけを対象にしているのか、どんな利益を訴求しているのか、内容がわからないので、キャンペーンについてはなんとも言えないですね。
ひとまずこのお店は「百貨店の高級食品売り場/デパ地下」のようなところで、富裕層がワンランク上の生活用品を購入している、というイメージがつかめました。
購入商品・購入チャネル
次に、購入商品や購入チャネルについての違いを見ていきます。
購入数や訪問回数といった「量」については、優良顧客のほうが多くなるのは当然なので、比(優良顧客の購入量÷一般顧客の購入量)を算出して、どの商品・チャネルが特に多いのかを見ていきたいと思います。
### 購入商品ごとの比(優良顧客÷一般顧客)を確認
target_col_list = attrs_dict['products']
avg_df = df[['Royal_flg'] + target_col_list].groupby('Royal_flg').mean()
avg_df = avg_df.T
avg_df_total = pd.DataFrame(df[target_col_list].mean(), columns=['total'])
avg_df = pd.concat([avg_df, avg_df_total], axis=1)
avg_df['1/0'] = avg_df['1']/avg_df['0']
avg_df = avg_df.sort_values(['total', '1/0'], ascending=False)
avg_df['1/0'] = avg_df['1/0'].apply(lambda x: '{:.2f}'.format(x))
display(avg_df)
### 購入チャネルごとの比(優良顧客÷一般顧客)を確認
target_col_list = [x for x in attrs_dict['channel'] if 'Discount' not in x]
avg_df = df[['Royal_flg'] + target_col_list].groupby('Royal_flg').mean()
avg_df = avg_df.T
avg_df_total = pd.DataFrame(df[target_col_list].mean(), columns=['total'])
avg_df = pd.concat([avg_df, avg_df_total], axis=1)
avg_df['1/0'] = avg_df['1']/avg_df['0']
avg_df = avg_df.sort_values(['total', '1/0'], ascending=False)
avg_df['1/0'] = avg_df['1/0'].apply(lambda x: '{:.2f}'.format(x))
display(avg_df)
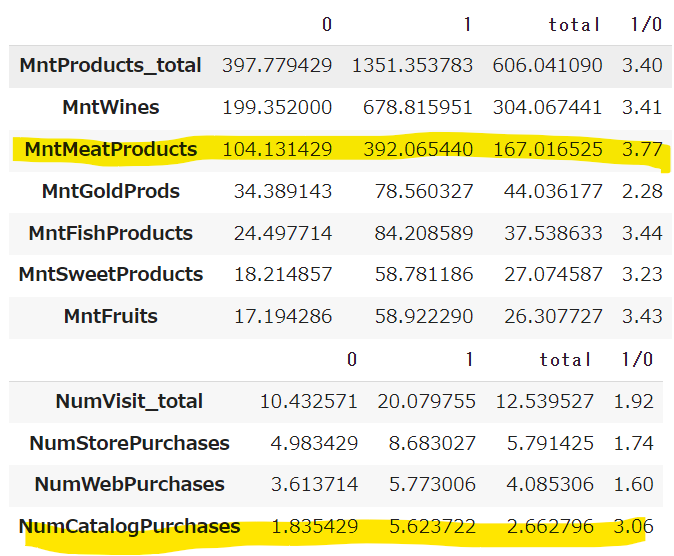
購入商品においては、MntMeatProductsの比が3.77と一番高いです。
購入チャネルにおいては、ボリュームは少ないもののNumCatalogPurhcaseが3.06とかなり大きくなっています。
この二つは優良顧客の判定に寄与していそうです。
step3. ロジスティック回帰モデルの説明変数のオッズ比調査
最後に、優良顧客か一般顧客かを分類するロジスティック回帰のモデルを構築し、各説明変数のオッズ比を調べることで、分類への寄与が高い変数を確認します。
オッズ比は、今回のデータでいうと「説明変数が1増えたときに、優良顧客と分類される確率が一般顧客に分類される確率の〇倍である」ことを示します。
つまり、この値が大きいほど、優良顧客に分類されやすいというわけです。
▼参考記事:
2. Pythonで綴る多変量解析 5-1. ロジスティック回帰分析(scikit-learn)
ロジスティック回帰の基本から実装までわかりやすく解説!
さきほど分布の比較で見つけた軸と同様の結果になるでしょうか。
まず、モデル用にデータを少し加工します。
### Incomeの外れ値を除外しておく
df = df.query('Income != 666666').copy().reset_index(drop=True)
### 分析に使うカラムをリストにしておく
# カテゴリカラム
cat_cols = ['Age_gp', 'Education_gp', 'Marital_Status_gp', 'Kidhome_gp']
# 連続値カラム
num_cols = ['Income', 'Customer_Days', 'Recency', 'AcceptedCmp_total',
'MntWines', 'MntFruits', 'MntMeatProducts','MntFishProducts', 'MntSweetProducts', 'MntGoldProds',
'NumDiscountPurchase', 'NumWebPurchases', 'NumCatalogPurchases','NumStorePurchases']
### カテゴリカラムの加工
# One-hotエンコーディングする(多重共線性を防ぐためdrop_first=Trueにするべきだが、回帰係数がわかりにくくなるのでFalseにしておく)
df_cat = df[cat_cols]
df_cat_oh = pd.get_dummies(df_cat, prefix_sep='-', dtype='int', drop_first=False)
# Kidhome_gpは2項なのでYesの列を削除
df_cat_oh.drop(columns=['Kidhome_gp-Yes'], inplace=True)
# One-hotエンコーディングしたカラムを確認
cat_cols_dummies = []
for col in df_cat_oh.columns:
for pf in cat_cols:
if col.startswith(pf):
cat_cols_dummies.append(col)
display(df_cat_oh[cat_cols_dummies].head())
### 連続値カラムの加工
# データ型をintにする(可視化の際に文字列に変換したものがあるため)
df_num = df[num_cols].astype(int)
# 標準化する(平均を0、分散を1にする)
std_scaler = StandardScaler()
std_scaler.fit(df_num)
df_num_s = pd.DataFrame(std_scaler.transform(df_num), columns=df_num.columns)
### 加工したカラムデータと連続値データを結合
df_log = pd.concat([df_cat_oh, df_num_s], axis=1)
# 説明変数
X = df_log
# 目的変数
Y = df['Royal_flg']
# 訓練データとテストデータに分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
モデルの学習と評価を行います。
目的は精度ではないのですが、Train/Testともに90%を超えているので、なかなか良いです。
# ロジスティック回帰モデルのインスタンスを作成(max_iter=1500を設定しないと、STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.という警告が出る)
# https://qiita.com/tatsu2015/items/8f01c89aa053e12e63b2
# 原因は,LogisticRegressionの最大反復回数に達しなかったことにあるようです.つまり,途中で処理が打ち切られているという事です.この最大反復回数はmax_iterで設定できます.この値を設定しない場合は,デフォルト値である1000が適用されるようです.そのため,max_iterの値を1000より大きくすることで,警告文が消えると考えられます.
lr = LogisticRegression(max_iter=1100)
# ロジスティック回帰モデルの重みを学習
lr.fit(X_train, Y_train)
# 訓練データの正解率
train_score = format(lr.score(X_train, Y_train))
print('正解率(train):', train_score)
# テストデータの正解率
test_score = format(lr.score(X_test, Y_test))
print('正解率(test):', test_score)
# >>>
# 正解率(train): 0.9151785714285714
# 正解率(test): 0.9352678571428571
回帰係数とオッズ比のランキングを出します。
# 学習済みモデルの各変数の係数とオッズ比を取得
regression_coefficient = lr.coef_
odds_ratio = np.exp(lr.coef_)
# DataFrameに変換し、降順で並び替え
df_coef = pd.DataFrame({'coef': regression_coefficient.tolist()[0], 'odds': odds_ratio.tolist()[0]},index = [X.columns.values])
display(df_coef.sort_values('coef', ascending=False))
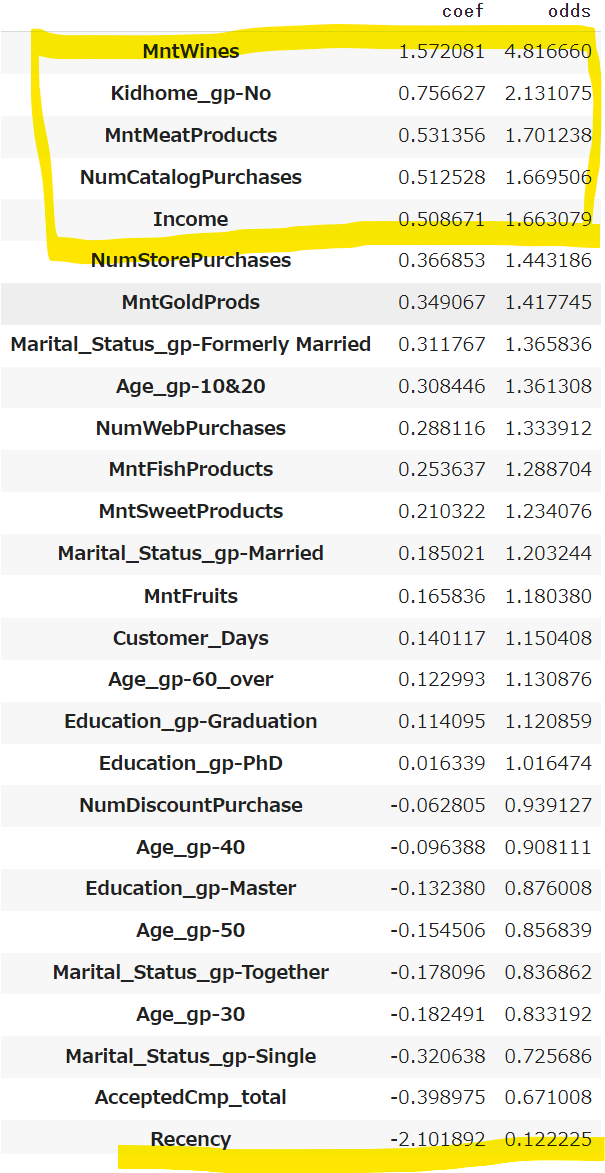
オッズ比のTOP5は、MntWines/Kidhome_gp-No/MntMeatProducts/NumCatarogPurchases/Incomeとなりました。
分布の比較で得た知見と大体一致します!
MntWines/MntMeatProductsが上位なのは、優良顧客の定義においてMntProducts_total(購入数の合計)が一番大きな基準となっており、MntProduct_totalの多くを占めるのがMntWines/MntMeatProductsなので、さもありなん、という感じです。
Recencyはオッズ比は一番小さく、回帰係数もマイナスですが、絶対値は大きいですね。
Recencyは値が小さいほど最近訪問しており、他の指標とは逆で「小さいほどいい値」(ネガティブ指標)なので、マイナスになるわけですが、絶対値が大きいので寄与はしてそうです。
ただ、あまり直感的ではないので、他の値のように「大きいほどいい値」(ポジティブ指標)に変換してオッズ比を見てみたいものです。(こちらは今回は掘り下げず、今後の課題とさせていただきます)
step4. まとめ
以上わかったことをまとめます。
今回の優良顧客の定義は、「購入数と訪問数が多く、休眠もしていない人」です。
優良顧客の特徴は下記になります。
ロジスティック回帰モデルからわかったこと
- 一般顧客よりも「子供がいない or 子供と同居していない」人が多い
- 一般顧客よりも「高収入」
- 一般顧客よりも「ワインと肉をたくさん買っている」
- 一般顧客よりも「カタログ経由での購入が多い」
分布の比較からわかったこと(※オッズ比は高くはないので注意)
- 一般顧客よりも「キャンペーンへの反応はよい」
- 一般顧客よりも「割引を利用する回数は少ない」
※キャンペーンも割引も全員が対象なのかわからない。前提条件や内容についての調査が必要。
可視化で大体の特徴を把握し、ロジスティック回帰モデルから得られたオッズ比で寄与度を確かめることができました。
分布の可視化は直感的でわかりやすいのですが、単変量解析なので相対的な寄与度の大きさはわからないです。
ロジスティック回帰のように多変量での解析をすることで、寄与度の大きさがわかるので、両方実施するのが大事だと思いました。
8. おわりに
今回この記事を書くにあたって、ゴールは「優良顧客の特徴をつかむこと」にしていますが、本来ビジネスにおけるゴールは、「分析を施策に生かして成果を出す(例:優良顧客の数と客単価を増やす)」ことです。
そういった意味では、分析プロセスの部分しかカバーはできないのですが、顧客分析のテンプレを一つ体系的にまとめられたので満足です。
そして、データから情報を得るのはやっぱり楽しいなと思いました!
ここまで読んでいただき、ありがとうございました![]()