やりたいこと
古い図面群(PDF)から過去の特注仕様を調べることが多いので、この目視作業をやめたい。減らしたい。
画像認識的なやつでこんなことができたらと思って始めてからの学習メモを育てていく。
- 特注仕様(姿図や記号、文字列)を図番ごとに分類
- 指定の特注仕様(姿図や記号、文字列)を持つ図面を発掘
やること・やったこと
取り消し線引いてないやつは未完
何のこっちゃからネットコピペで体験(GoogleColab)カスケード分類器を自作する(VSCode createsamples.exe)- PDFの読み込みと評価
PDF→JPEGに変換- 変換後のJPEGを探索
- 判定結果を返す
- 複数ファイルを巡回
- 複数条件で巡回
各項目
何のこっちゃからネットコピペで体験
この記事のとおりにやったらまあできた(顔認証のところまで)
GoogleColabの導入から懇切丁寧なのでマジで助かる
GitHubからxmlファイルをDLする時、一覧からだと後々xml読み込みエラーになった
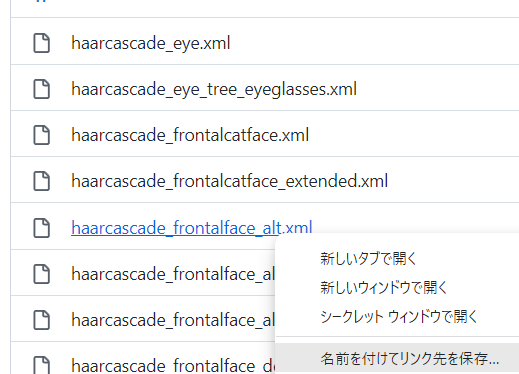
一覧から開いてRowのボタンを右クリック>保存
とすると上手くいった

ここまでやってきたのはどうやら既存のカスケード分類器なるものを使って画像を評価しにいってるっぽい
やりたいことは顔や目などの分類器から顔認証的なことではなく、図面の特定の部位の姿図や記号を分類器として図面内を探索、判定していくことなので、次に手を付けるべきは分類器の作成かな
カスケード分類器を自作する
createsamples.exe欲しさにGoogleColabではなくローカル版OpenCVをDL
最新版(ver.4.6.0)だとそれが無い・・・
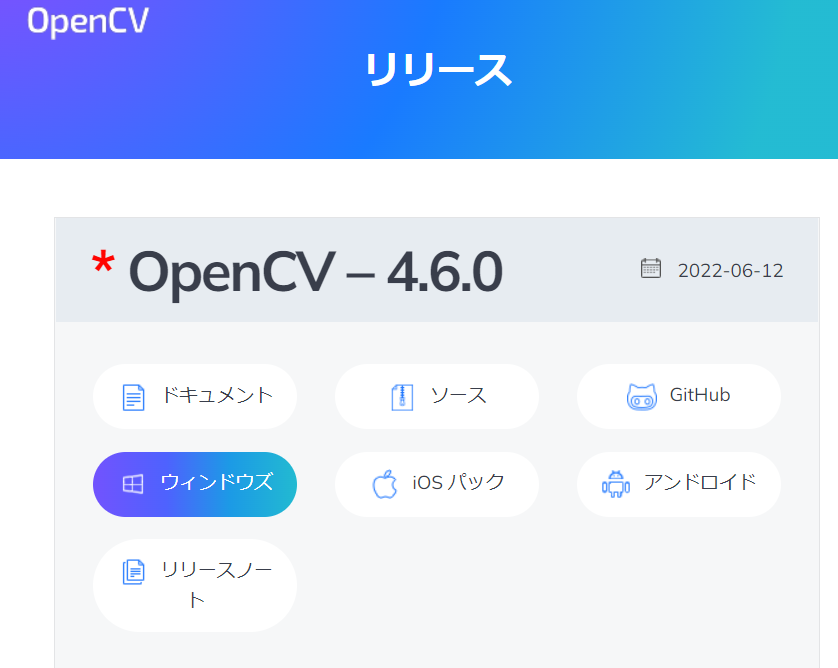
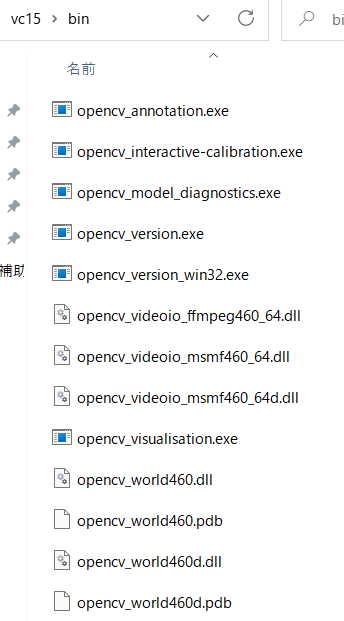
ver.3.4.16にはあった

NGリストのファイル名はng.listではなくnglist.txt
cmdで読み込むこの部分に合わせる(or作成したNGリストのファイル名と保存先をcmd側で変える)
opencv_traincascade.exe -data ./cascade/ -vec ./test.vec -bg ./ng/nglist.txt -numPos 800 -numNeg 40
cascade.pyに食わせるxmlファイルのパスはフルパス?
これを
custom_cascade = cv.CascadeClassifier('cascade.xml')
こうしたら
custom_cascade = cv.CascadeClassifier(r"C:\Users\hoge\OpenCV\cv\cascade\cascade.xml")
できて・・・ない・・・(矩形の色を水色にした)
右の方誤検出ばっかりすごいけど・・・

分類器の作り方が悪いのかな・・・
このあたりの作り込みは素材集めと根気の作業になるっぽいのでいったんパス。
相手はモノクロの2D図面だしね。
PDFの読み込みと評価
ここまではjpgやpngといった画像ファイルを扱ってきたが、本番の相手はpdf。
どうやってOpenCVに食わせるか
- pdfを画像に変換して食わせる
- pdfのまま食わせる
できれば変換なしそのまま食わせたい気もするがとりあえずググった。
pdfを画像に変換して食わせるパターン
前処理としてPDFを画像として大量に保存しとく用
検索したい部品ごとに毎回変換するの面倒そうだなーと思ったので前処理はまとめてやっといた方が良いかも。
フォルダを2つ作成しておく
- in_pdf
- out_image

pdfのまま食わせるパターン
ない・・・?
ヒットしない・・・というか変換パターンが上位に来まくってる時点でこのパターンは少なくともメジャーではない?
今日のところは変換パターンでやろう・・・