MacでPDFからコピペした時のNFD問題の対策。
MacでPDFからコピペした文字が、濁点/半濁点が離れる。
- 「お読みください」
- 「お読みくた゛さい」
Macのファインダーのコピーだと見た目的な違いが無いので判別が難しい。
原因
MacOSのファイルシステムであるHFS+が使用している、UTF-8の正規化方法が「NFD」というもので、2文字に分けて正規化されてしまうことが原因。
対策とどこでクリアするか?
NFD → NFCに変換をする。
nkf(Network Kanji Filter)で変換が可能。
どこで?
- コピーした時点で変換する。
- タスクランナーに組み込んで変換する。
とりあえずの前者の仕組みを MacのAutomaterでシェルスクリプトを実行してクリップボードにコピーするで実現する。
やる
nkfをインストール(npm でもインストールが可能)
- [Macにnkfコマンドをインストールしてみる]
(http://kengo92i.hatenablog.jp/entry/2016/09/06/120854)
nkfで --ic=UTF8-MACオプションを指定して実行
- [Macでファイル名をコピペすると濁点と半濁点がおかしくなる。]
(http://qiita.com/damassima/items/1813af7e501994aa0cf8)
実行するシェルスクリプトは以下
/usr/local/bin/nkf -w --ic=UTF8-MAC
↑コレをAutomaterで処理を登録
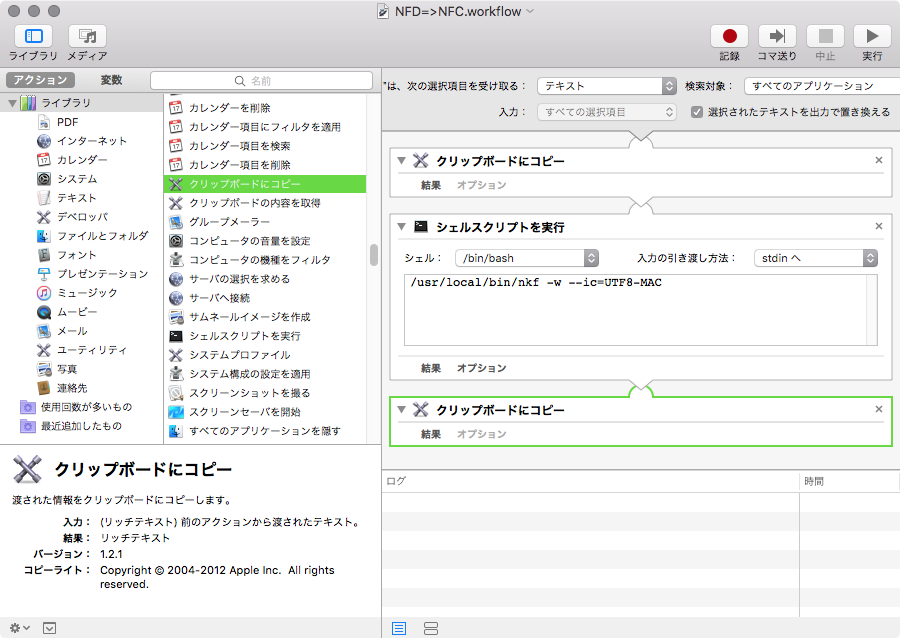
この処理だけでok。
クリップボードの内容を取得のフローを入れてたら、テキストが2重に表示されたりしてちょっとハマった。
検証
テキストファイルを2つ用意して、
コピペしてみる。
NFCとNFDのサンプルは↓こちらからお借りします。
http://pollux.sakura.ne.jp/test/unicode/
【NFDのサンプル】
ガギグゲゴ|パピプペポ
変換前
cat test.txt | od -tx1c
0000000 e3 80 90 4e 46 43 e3 81 ae e3 82 b5 e3 83 b3 e3
【 ** ** N F D の ** ** サ ** ** ン ** ** プ
0000020 83 97 e3 83 ab e3 80 91 0a e3 82 ab e3 82 99 e3
** ** ル ** ** 】 ** ** \n カ ** ** ゙ ** ** キ
0000040 82 ad e3 82 99 e3 82 af e3 82 99 e3 82 b1 e3 82
** ** ゙ ** ** ク ** ** ゙ ** ** ケ ** ** ゙ **
0000060 99 e3 82 b3 e3 82 99 7c e3 83 8f e3 82 9a e3 83
** コ ** ** ゙ ** ** | ハ ** ** ゚ ** ** ヒ **
0000100 92 e3 82 9a e3 83 95 e3 82 9a e3 83 98 e3 82 9a
** ゚ ** ** フ ** ** ゚ ** ** ヘ ** ** ゚ ** **
0000120 e3 83 9b e3 82 9a
ホ ** ** ゚ ** **
変換後
cat test_nfc.txt | od -tx1c
0000000 e3 80 90 4e 46 43 e3 81 ae e3 82 b5 e3 83 b3 e3
【 ** ** N F D の ** ** サ ** ** ン ** ** プ
0000020 83 97 e3 83 ab e3 80 91 0a e3 82 ac e3 82 ae e3
** ** ル ** ** 】 ** ** \n ガ ** ** ギ ** ** グ
0000040 82 b0 e3 82 b2 e3 82 b4 7c e3 83 91 e3 83 94 e3
** ** ゲ ** ** ゴ ** ** | パ ** ** ピ ** ** プ
0000060 83 97 e3 83 9a e3 83 9d
** ** ペ ** ** ポ ** **
変換できてる。
サービスに登録
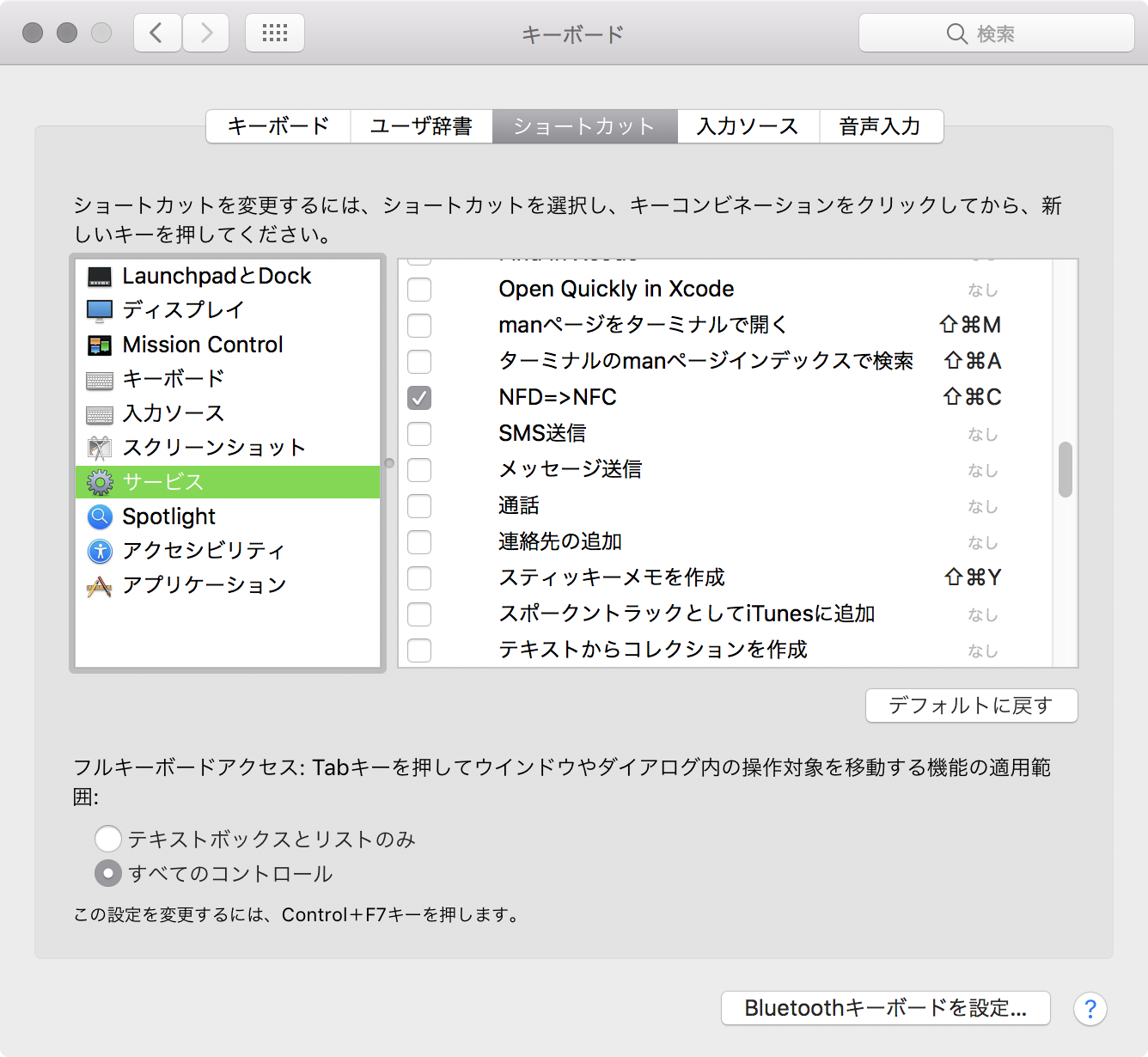
PDFからコピーするときは、これを選んで変換する。
通常のコピー(cmd + c)を上書きすると常に実行されたりもする。
以上。