はじめに
前回、Oracle Container Engine for Kubernetes(OKE)にRook-CephをデプロイしてWordPressを構築してみたという記事を書かせていただきました。
この記事のまとめにも記載した通り、Rook-Cephのアーキテクチャについてみていこうと思います。
内容については、前回の記事に沿ってみていきます。
自分なりに正確に書いているつもりですが、前回同様に間違いがあればご指摘いただけると幸いです!
Rookとは?
まずは「Rookってそもそも何?」というところから始めたいと思います。
公式ページをみると、
Open-Source, Cloud-Native Storage for Kubernetes
というコンセプトが書かれています。
Kubernetesでストレージ管理をするためのオープンソースプロジェクトということですね。
v1.0がリリースされたのが2019年5月とまだまだ新しいプロジェクトで今後も様々な進化が見込まれています。
みんな大好きCNCFのLandspaceにも、「Cloud Native Storage」ジャンルに大きく描かれています。

RookはOperatorである
RookはKubernetes上で動作する「operator」というソフトウェアになります。
operatorについてここで説明すると長くなってしまうので、気になる方はこちらを参考にしてください。
ここでは、ユーザが独自に定義できるKubernetes上のリソース(Custom Resource)を管理するためのコンポーネントおよびソフトウェアということだけ理解していれば大丈夫かと思います。
そもそもKubernetesは運用管理者のタスクを自動化する目的で作られたプラットフォームですが、Rookも例外ではなく、ストレージ管理者の運用タスクを自動化するためのソフトウェアです。
ストレージ管理者の運用タスクとしては
- プロビジョニング
- スケーリング
- 災害復旧
- モニタリング
など、いろいろ挙げられますね。
これらのタスクをKubernetes上で自動化してくれるのがRookになります。
Rookが対応しているストレージ
次にRookが管理を自動化できる対象のストレージには何があるかを見ていきたいと思います。
公式ページによると、Rookがサポート対象としているのは以下のようです。
- Ceph
- EdgeFS
- CockroachDB
- Cassandra
- NFS
- Yugabyte DB
ストレージそのものから、関連して各種データベースもサポートしているようです。
ただし、RookがstableでサポートしているのはCephとEdgeFSのみで、その他はalphaとなっています。(2020年5月現在)
| Storage Provider | Status |
|---|---|
| Ceph | stable/v1 |
| EdgeFS | stable/v1 |
| CockrouchDB | alpha |
| Cassandra | alpha |
| NFS | alpha |
| Yogabyte DB | alpha |
Rook-Cephは、Rookがサポートする上記のStorage ProviderからCephを利用しているということですね。
Cephとは?
続いて、Cephを見ていきます。
Cephは先ほど確認したRookが対応しているストレージの一つになります。
公式ページのドキュメントを見てみると、
Ceph uniquely delivers object, block, and file storage in one unified system.
と書かれているので、どうやらオブジェクトストレージ、ブロックストレージ、ファイルストレージのような様々なストレージを1つのクラスタとして管理する分散ストレージプラットフォームのようです。
Cephについても、CNCFのLandspaceの「Cloud Native Storgae」ジャンルに記載されています。

Rookとは違い、CephはKubernetesの台頭前から存在しているプロダクトで、OpenStackでもストレージシステムとして利用されています。
Cephは分散ストレージプラットフォーム
Cephの土台となる基板は、RADOS(Reliable Autonomic Distributed Object Store)と呼ばれる仕組みをベースにしたCeph Storage Clusterと呼ばれるものです。
Ceph Storage Clusterは主に以下の2つのプロセスがあります。
-
OSD(Object Storage Device)
ストレージごとに置かれ、オブジェクト配置管理、実ストレージデータ読み書き、データ冗長化などを行う -
モニター
Ceph Storage Clusterの構成情報(クラスタマップ)をもとにして、OSD構成、クラスタ管理、稼働状態監視を行う
この2つのプロセスについて見ていこうと思います。
OSD(Object Storage Device)
OSDは、実際にデータを格納するコンポーネントになり、2台以上が必要です。クライアントがデータにアクセスする場合にはOSDに直接アクセスして入出力を行います。データはオブジェクトの単位でOSDに冗長配置されます。オブジェクトのコピー(レプリカ)配置は、OSDがクラスターマップとCRUSHアルゴリズム1で配置すべきOSDを計算して行います。
CRUSHはOSDの物理的な位置を考慮してデータを配置するルールを設定できます。あるレプリカを全てのOSDの間で配置するとした場合、すべてのレプリカが同じノード内のOSDに配置されてしまって、1つのノードに問題が発生しただけで当該データにアクセスできなくなることもあります。このような状況を避けるために、「オブジェクトは同じノードには1レプリカしか持てない」というルールが決められています。
モニター
モニターは、ノード上に配置されたモニターが「クラスタ内にどのようなOSDがあるか」、「アクセス可能なOSDはどれか」などの情報(CRUSH map)を持っています。
モニターとOSD間ではヘルスチェックが定期的に行われており、状況が変わるとCRUSH mapが更新されます。
モニター間は「Paxos」という合意形成アルゴリズムを用いて通信し合うことによって、クライアントないしOSDと通信する際には常に最新のCRUSH mapを元に判断ができるようになっています。モニターはSplit-brainを回避するために原則として奇数台になります。
Cephにおけるスケールアウト
Cephクラスタをスケールアウトしたい場合は、新しいOSDをクラスタに登録することによって容量を拡張することができます。OSDが新しく登録されるとCRUSH mapが更新されて、リバランスというオブジェクトの再配置が行われます。
Cephにおけるセルフヒーリング
Cephクラスタ内のノードがダウンするなどの理由によってOSDがクラスタから見えないという状態が長時間続くと、CephはOSDがダウンしたものとみなしてCRUSH mapを更新します。ここでリバランスにより、ダウンしたOSDのデータは他のレプリカのデータをもとに別のOSDに移動することによって再配置が行われます。ダウンしたノードが再びクラスタが認識すると、再度リバランスが行われ、オブジェクトは元のOSDにリカバリされます。
Cephのインターフェース
Cephクラスタのインタフェースは以下の3通りがあります。
-
ファイルストレージ
Ceph FSを利用してNFSやHDFSなどのストレージが利用できます -
ブロックストレージ
RBDを利用して各クラウドベンダーのブロックストレージソリューションのバックエンドとして利用できます -
オブジェクトストレージ
RADOSGWを利用してAmazonS3やSwiftなどで利用できます。
Rook-Cephのアーキテクチャ
ここまでは、RookとCephそれぞれの概要を見てきました。
ここからは、Rook-Cephとしてのアーキテクチャを見ていきたいと思います。
Rook-CephにおけるPod構成
Rook-CephはCSI(Container Storage Interface)と呼ばれるインタフェースに準拠しています。
CSIは、コンテナオーケストレータ(Kubernetesだけとは限りません)からストレージを扱うインタフェースを定めたものです。
CSIについては、別記事で深堀りできたらと思います。
Rook-Cephを調査していくと以下のような絵をよく見かけます。
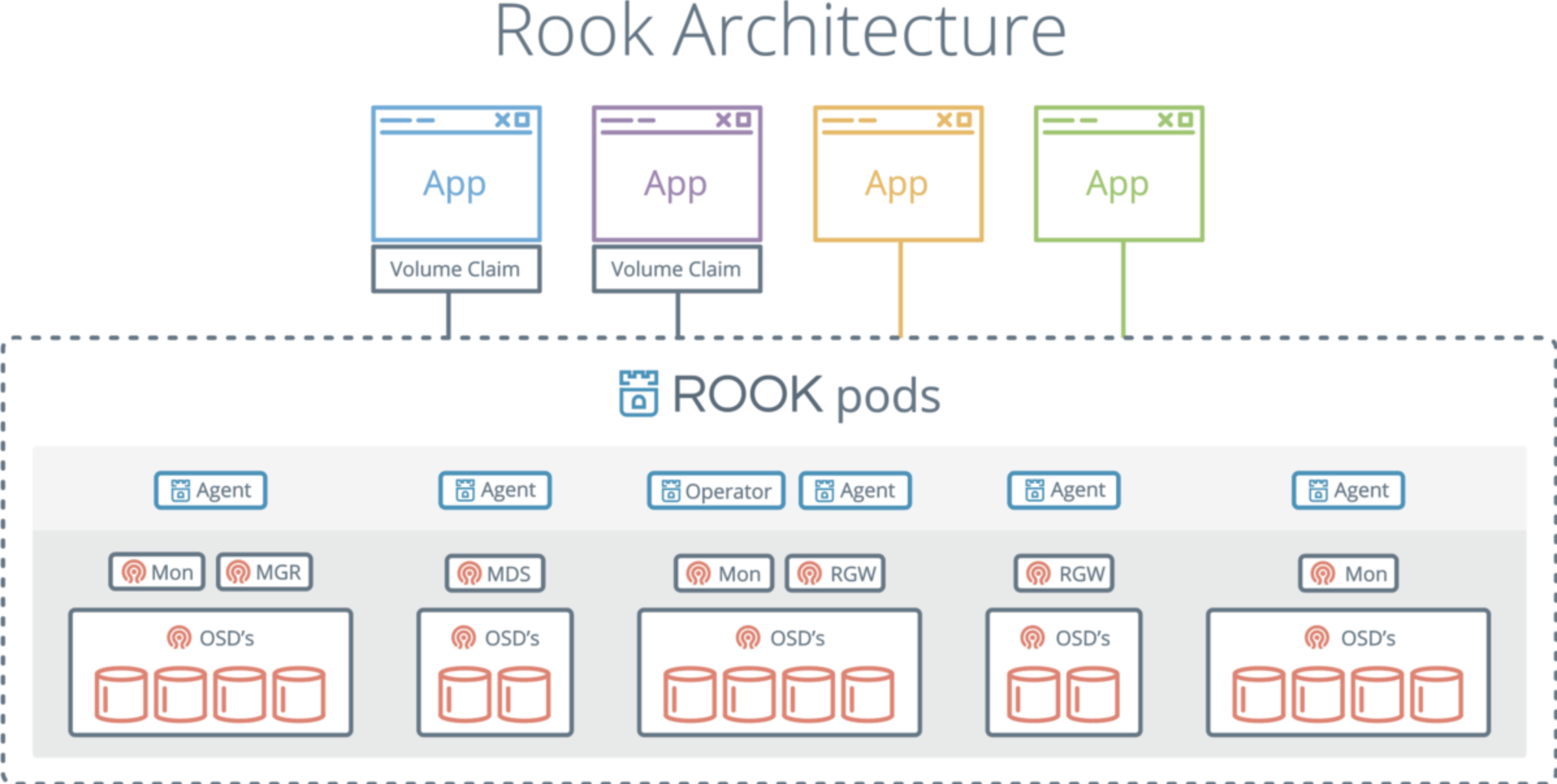
上記の絵と先日の記事でのRook-Cephデプロイ時のPodを合わせて見ていきたいと思います。
Rook-Cephデプロイ時のPodの状態が以下のような形でした。
[opc@oke-client kubernetes]$ kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-8d7p6 3/3 Running 0 11m
csi-cephfsplugin-lws5k 3/3 Running 0 11m
csi-cephfsplugin-provisioner-74579b599c-ks9t9 5/5 Running 0 11m
csi-cephfsplugin-provisioner-74579b599c-mdfpt 5/5 Running 0 11m
csi-cephfsplugin-rz7qr 3/3 Running 0 11m
csi-rbdplugin-czfnw 3/3 Running 0 11m
csi-rbdplugin-d26t7 3/3 Running 0 11m
csi-rbdplugin-provisioner-79cdfdbc64-9nk46 6/6 Running 0 11m
csi-rbdplugin-provisioner-79cdfdbc64-jwg69 6/6 Running 0 11m
csi-rbdplugin-rrb27 3/3 Running 0 11m
rook-ceph-crashcollector-10.0.10.10-94bd48669-rt68l 1/1 Running 0 46m
rook-ceph-crashcollector-10.0.10.11-86bfb47dbb-dnccv 1/1 Running 0 46m
rook-ceph-crashcollector-10.0.10.9-67d95475d9-pct86 1/1 Running 0 22m
rook-ceph-mgr-a-7d4b5f56-nwlnb 1/1 Running 0 47m
rook-ceph-mon-a-78f5c44b88-7hbj2 1/1 Running 0 45m
rook-ceph-mon-b-68db8964f6-xr2bc 1/1 Running 0 46m
rook-ceph-mon-c-f9475b799-t64dp 1/1 Running 0 45m
rook-ceph-operator-7d99d768f4-8p94q 1/1 Running 0 23m
rook-ceph-osd-0-f6b7945b7-fvdx5 1/1 Running 0 22m
rook-ceph-osd-1-567995f68b-65xb9 1/1 Running 0 22m
rook-ceph-osd-2-6cb9b454f-fqd68 1/1 Running 0 22m
rook-ceph-osd-prepare-10.0.10.10-7wvdg 0/1 Completed 0 22m
rook-ceph-osd-prepare-10.0.10.11-wqvjc 0/1 Completed 0 22m
rook-ceph-osd-prepare-10.0.10.9-vh7nf 0/1 Completed 0 22m
rook-discover-42n6l 1/1 Running 0 14m
rook-discover-lzn6q 1/1 Running 0 14m
rook-discover-vwl6p 1/1 Running 0 14m
先ほどのRook-Cephのアーキテクチャと上記のPodを元にすると3種類に分類できます。
-
Rook
-
rook-ceph-operator:Rookそのもの(operator)
-
rook-discover:接続されるストレージデバイスをリアルタイムに検知してくれるプロセス
-
Ceph
-
rook-ceph-mon:Cephクラスタの監視。上記で述べたモニターにあたる
-
rook-ceph-osd:データを格納するデバイスを抽象化したもの。デバイスが増えるとこのPodも増える
-
rook-ceph-osd-prepare:rook-ceph-osdをデプロイするための事前準備を行うJob
-
rook-ceph-mgr:Cephクラスターの管理を行う。ダッシュボードも提供している
-
rook-ceph-crashcollector:Cephクラスタ内のコアダンプを収集し、Cephマネージャに送信する
-
Ceph CSI
-
csi-cephfsplugin/csi-rbdplugin:前者はCeph FS、後者はRBDのPV(Persistent Volume)を使うためのドライバー
-
csi-cephfsplugin-provisioner/csi-rbdplugin-provisioner:kube-apiserverにリクエストされたCeph RBD/CephFS PV関連のリクエストのブローカー
このような形になります。
Rook-CephとStorageClass
Rook-Cephを利用するにあたって忘れてはいけないのは、Cephプールと呼ばれるオブジェクトを保存するための論理ボリュームを作成することです。
先日の記事では、CephBlockPoolというCustom Resourceをデプロイしています。
これがCephプールにあたります。manifestは以下でした。
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
CephBlockPoolとしては、お決まりのような定義で非常にシンプルな定義となっています。
定義としては、failureDomainとreplicatedがあります。
ここで注目したいのは、replicatedです。sizeが3になっています。
これにより、オブジェクトのコピー(レプリカ)を3つ作成することになり、2つのホストの障害を許容できることが保証されます。
次にストレージクラスです。
先日の記事では、以下のようなmanifestでした。
(コメント行は削除しています)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: xfs
reclaimPolicy:
こちらも、Roook-Cephでブロックボリュームを利用する場合はお決まりのような定義となっています。
patametersのところで重要なポイントを見ていこうと思います。
poolは先ほどのmanifestで見たCephBlockPoolの名前を定義します。この定義のより、StorageClassに対してCephBlockPoolを利用できます。
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
この部分は、Cephクラスタに関するcredentialsを示した定義です。
Rookレポジトリにあるmanifestをデフォルトで利用する場合は、このような定義になります。
csi.storage.k8s.io/fstype: xfs
最後にこちらはファイルシステムタイプを定義します。今回はxfsです。
これらのリソースを適用することで、Worker NodeにアタッチしているブロックボリュームをCephクラスタとして管理できるようになります。
まとめ
今回は、Rook-Cephの概要と実際にデプロイされたPodをベースにしたアーキテクチャを前回執筆した記事を参考に見てきました。
私自身がもともとインフラに強い方ではないので、ほぼほぼイメージだけで書いた記事になっていますが、少しでもRook-Cephのイメージができればいいと思っています。
まだ自分の中で落とし込めていない部分もあるので、今後もしばらくは(CSIも含めて)Rook-Cephの記事を書いていこうと思います。
参考記事
Rook公式ドキュメント
https://rook.io/docs/rook/v1.3/
Ceph公式ドキュメント
https://ceph.readthedocs.io/en/latest/
CNCF Cloud Native Interactive Landscape
https://landscape.cncf.io/
Rook-Ceph学習者には非常に参考になるうつぼさんのブログ
http://ututaq.hatenablog.com/entry/rook/01
サイボウズ様のCephについて分かりやすく解説されているブログ
https://blog.cybozu.io/entry/2018/12/13/103039
-
個々のオブジェクトのコピー(レプリカ)を配置する際には、Controlled Replication Under Scalable Hashing(CRUSH)というアルゴリズムを利用して配置場所を決定しています。これは、オブジェクトのハッシュ値および既存オブジェクトのリストを元にレプリカをどこに配置するかを決定するアルゴリズムです。 ↩