はじめに
SIGNATE様が提供しているプラクティスコンペに参加してみました。
使用データは、ある銀行の顧客属性データおよび、過去のキャンペーンでの接触情報、などで、これらのデータを元に、当該のキャンペーンの結果、口座を開設したかどうかを予測します。
ねらい
今回はデータの前処理や、パラメータ設定の理解に重きを置くため、決定木のみ(ランダムフォレスト等のアンサンブル学習を使わない)でモデル作成に取り組みました。
決定木で出せる予測値の限界?とされている0.91以上を目指してみます。
環境
Anaconda JupyterLab
データ分析
準備
ライブラリーのインポート
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DT
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.externals.six import StringIO
from sklearn.metrics import roc_auc_score
import pydotplus
from IPython.display import Image
データの読み込み
# Path
input_path = "../input_data/"
# Set Display Max Columns
pd.set_option("display.max_columns", 50)
train = pd.read_csv(input_path + "bank/train.csv", sep=",", header=0, quotechar="\"")
test = pd.read_csv(input_path + "bank/test.csv", sep=",", header=0, quotechar="\"")
前処理
対数変換
## ヒストグラムでプロットしたときに、分布に偏りがある項目
train["log_balance"] = np.log(train.balance - train.balance.min() + 1)
train["log_duration"] = np.log(train.duration + 1)
train["log_campaign"] = np.log(train.campaign + 1)
train["log_pdays"] = np.log(train.pdays - train.pdays.min() + 1)
test["log_balance"] = np.log(test.balance - test.balance.min() + 1)
test["log_duration"] = np.log(test.duration + 1)
test["log_campaign"] = np.log(test.campaign + 1)
test["log_pdays"] = np.log(test.pdays - test.pdays.min() + 1)
drop_columns = ["id", "balance", "duration", "campaign", "pdays"]
train = train.drop(drop_columns, axis = 1)
test = test.drop(drop_columns, axis = 1)
trainとtestに分けてしまったため、冗長な書き方に...
(trainデータに)monthを数値、datetimeを作成
# month を文字列から数値に変換
month_dict = {"jan": 1, "feb": 2, "mar": 3, "apr": 4, "may": 5, "jun": 6,
"jul": 7, "aug": 8, "sep": 9, "oct": 10, "nov": 11, "dec": 12}
train["month_int"] = train["month"].map(month_dict)
# month と day を datetime に変換
data_datetime = train \
.assign(ymd_str=lambda x: "2014" + "-" + x["month_int"].astype(str) + "-" + x["day"].astype(str)) \
.assign(datetime=lambda x: pd.to_datetime(x["ymd_str"])) \
["datetime"].values
# datetime を int に変換する
index = pd.DatetimeIndex(data_datetime)
train["datetime_int"] = np.log(index.astype(np.int64))
# 不要な列を削除
train = train.drop(["month", "day", "month_int"], axis=1)
del data_datetime
del index
(testデータに)monthを数値、datetimeを作成
# month を文字列から数値に変換
month_dict = {"jan": 1, "feb": 2, "mar": 3, "apr": 4, "may": 5, "jun": 6,
"jul": 7, "aug": 8, "sep": 9, "oct": 10, "nov": 11, "dec": 12}
test["month_int"] = test["month"].map(month_dict)
# month と day を datetime に変換
data_datetime = test \
.assign(ymd_str=lambda x: "2014" + "-" + x["month_int"].astype(str) + "-" + x["day"].astype(str)) \
.assign(datetime=lambda x: pd.to_datetime(x["ymd_str"])) \
["datetime"].values
# datetime を int に変換する
index = pd.DatetimeIndex(data_datetime)
test["datetime_int"] = np.log(index.astype(np.int64))
# 不要な列を削除
test = test.drop(["month", "day", "month_int"], axis=1)
del data_datetime
del index
One Hot Encoding
cat_cols = ["job", "marital", "education", "default", "housing", "loan", "contact", "poutcome"]
train_dummy = pd.get_dummies(train[cat_cols])
test_dummy = pd.get_dummies(test[cat_cols])
データ結合
train_tmp = train[["age", "datetime_int", "log_balance", "log_duration", "log_campaign", "log_pdays", "y"]]
test_tmp = test[["age", "datetime_int", "log_balance", "log_duration", "log_campaign", "log_pdays"]]
train = pd.concat([train_tmp, train_dummy], axis=1)
test = pd.concat([test_tmp, test_dummy], axis=1)
目的変数を分離
train_x = train.drop(columns=["y"])
train_y = train[["y"]]
train_x.head()

モデル作成からテストデータへの適用まで
交差検証とグリットサーチによるパラメータの最適化
from sklearn.model_selection import KFold
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn import tree
K = 3 #今回は3分割
kf = KFold(n_splits=K, shuffle=True, random_state=17)
clf = tree.DecisionTreeClassifier(random_state=17)
# use a full grid over all parameters
param_grid = {"max_depth": [6, 7, 8, 9],
# "max_features": ['log2', 'sqrt','auto'],
"min_samples_split": [2, 3, 4],
"min_samples_leaf": [15, 17, 18, 19, 20, 25, 26],
"criterion": ["gini"]} #gini係数で評価
# 次に、GridSearchCVを読んで、グリッドサーチを実行する。
tree_grid = GridSearchCV(estimator=clf,
param_grid = param_grid,
scoring="accuracy", #metrics
cv = K, #cross-validation
n_jobs =-1) #number of core
tree_grid.fit(train_x,train_y) #fit
tree_grid_best = tree_grid.best_estimator_ #best estimator
print("Best Model Parameter: ",tree_grid.best_params_)
print("Best Model Score : ",tree_grid.best_score_)
Best Model Parameter: {'criterion': 'gini', 'max_depth': 7, 'min_samples_leaf': 18, 'min_samples_split': 2}
Best Model Score : 0.9002875258035977
*tree_gridではなく、tree_grid_bestを使用すること。交差検証の評価から得た最適解が、tree_grid_bestの方に入っているので(モデル性能が悪くなり、ここで、かなり足止めを食らった...)
visualization
col_name = list(train_x.columns.values)
dot_data = StringIO()
export_graphviz(tree_grid_best, out_file=dot_data, feature_names=col_name, filled=True, rounded=True)
tree_graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
tree_graph.progs = {"dot": u"graphvizのdot.exeがあるパスを指定"} #windowsでは必要
tree_graph.write_png('tree.png') #画像の保存
Image(tree_graph.create_png())

読み方としては、青色の濃い部分は目的変数である、定額預金の申し込みが有(yes) が多い分類、逆にオレンジ色は少ないということになります。
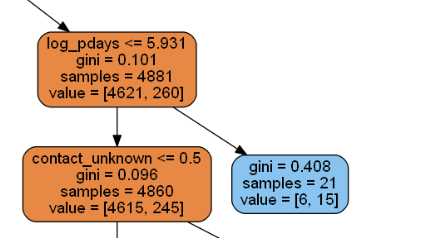
上図の青色のboxを例にあげると、log_pdays<=5.931 ではない(つまり log_pdays> 5.931)の区分に青色が多い。また、gini係数の値が0に近いほど、よく分離できている(条件式として優秀)ということが分かる。
改めてAUCでモデルの評価(あまり意味がないが...)
pred = tree_grid_best.predict_proba(train_x)[:, 1]
roc_auc_score(train_y, pred)
0.9124593798479221
テストデータに適用
pred_test = tree_grid_best.predict_proba(test)[:, 1] #ちゃんとtree_grid_bestに
投稿用にデータを整形
test_for_id = pd.read_csv(input_path + "bank/test.csv", sep=",", header=0, quotechar="\"")
ID = np.array(test_for_id[["id"]]).astype(int)
my_solution = pd.DataFrame(pred_test, ID).reset_index()
# Submit File
my_solution.to_csv(
path_or_buf="../submit/submit_tree_20190601_005.csv", # 出力先
sep=",", # 区切り文字
index=False, # indexの出力有無
header=False # headerの出力有無
)
結果

0.91までまだまだ。さらなる調整が必要...
おまけ(0.91を超えるまで挑戦)
効果のうすい特徴量を除いて、モデルの精度を高める戦略をとってみました。
特徴量それぞれに対してモデルへの貢献度を評価し、貢献度が低い特徴量を除外していきました。
特徴量の評価
import matplotlib.pyplot as plt
# 特徴量の重要度
feature = tree_grid_best.feature_importances_
# 特徴量の重要度を上から順に出力する
f = pd.DataFrame({'number': range(0, len(feature)),
'feature': feature[:]})
f2 = f.sort_values('feature',ascending=False)
f3 = f2.ix[:, 'number']
# 特徴量の名前
label = train_x.columns[0:]
# 特徴量の重要度順(降順)
indices = np.argsort(feature)[::-1]
for i in range(len(feature)):
print(str(i + 1) + " " + str(label[indices[i]]) + " " + str(feature[indices[i]]))
plt.title('Feature Importance')
plt.bar(range(len(feature)),feature[indices], color='lightblue', align='center')
plt.xticks(range(len(feature)), label[indices], rotation=90)
plt.xlim([-1, len(feature)])
plt.tight_layout()
plt.show()
1 log_duration 0.48118891419583315
2 poutcome_success 0.23194787672253572
3 datetime_int 0.14076888561566822
4 housing_yes 0.061776203845371615
5 contact_unknown 0.039507261913598296
6 log_pdays 0.02166450679741274
7 log_balance 0.011808092183242474
8 poutcome_failure 0.006485491293160224
9 job_blue-collar 0.002558537869262011
10 education_secondary 0.0009964078313506293
11 education_tertiary 0.0009323192208194946
12 job_admin. 0.00019370017176108365
13 job_student 0.00013699657044161448
14 job_management 3.4805769542740264e-05
15 job_entrepreneur 0.0
16 job_housemaid 0.0
17 job_retired 0.0
18 job_self-employed 0.0
19 job_services 0.0
20 poutcome_unknown 0.0
21 job_technician 0.0
22 job_unemployed 0.0
23 job_unknown 0.0
24 education_unknown 0.0
25 default_no 0.0
26 default_yes 0.0
27 housing_no 0.0
28 loan_no 0.0
29 loan_yes 0.0
30 contact_cellular 0.0
31 contact_telephone 0.0
32 poutcome_other 0.0
33 education_primary 0.0
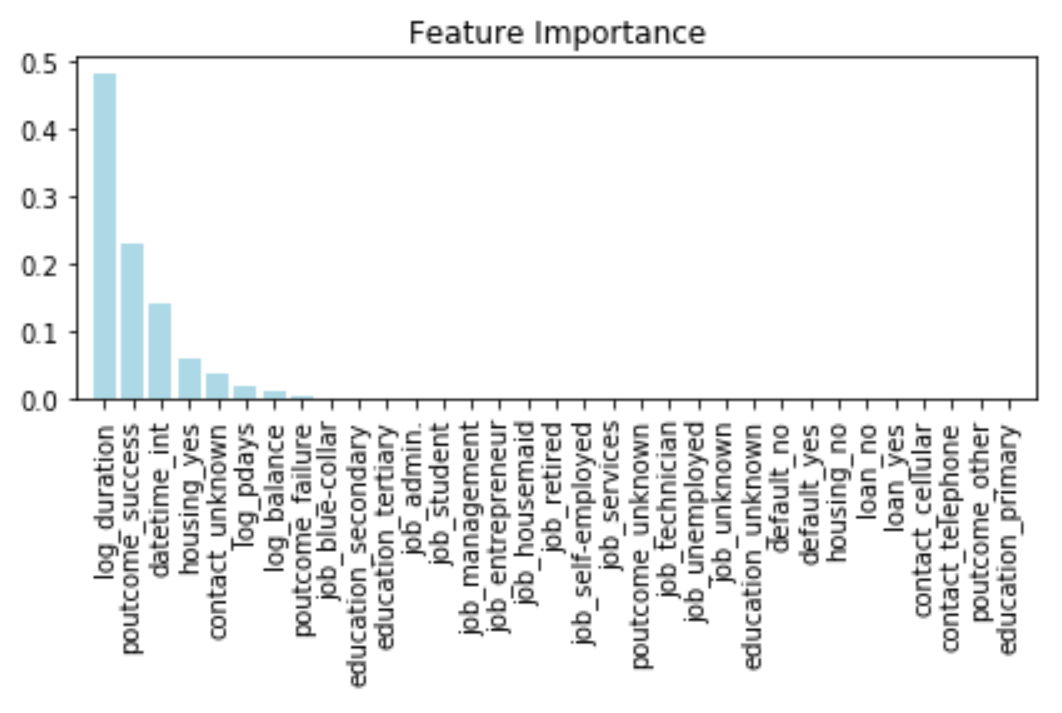
*項目が多すぎると、グラフは表示されないみたいです。
*上記は選抜した後のため、すべての特徴量が入っておりません。
モデルの作成→特徴量の評価→特徴量削除→モデルの作成→特徴量の評価→・・・を繰り返し、特徴量を選抜していきました。
"age", "campaign", "marial"を削除
前処理
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DT
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.externals.six import StringIO
from sklearn.metrics import roc_auc_score
import pydotplus
from IPython.display import Image
# Path
input_path = "../input_data/"
# Set Display Max Columns
pd.set_option("display.max_columns", 50)
train = pd.read_csv(input_path + "bank/train.csv", sep=",", header=0, quotechar="\"")
test = pd.read_csv(input_path + "bank/test.csv", sep=",", header=0, quotechar="\"")
## ヒストグラムでプロットしたときに、分布に偏りがある項目
train["log_balance"] = np.log(train.balance - train.balance.min() + 1)
train["log_duration"] = np.log(train.duration + 1)
train["log_campaign"] = np.log(train.campaign + 1)
train["log_pdays"] = np.log(train.pdays - train.pdays.min() + 1)
test["log_balance"] = np.log(test.balance - test.balance.min() + 1)
test["log_duration"] = np.log(test.duration + 1)
test["log_campaign"] = np.log(test.campaign + 1)
test["log_pdays"] = np.log(test.pdays - test.pdays.min() + 1)
drop_columns = ["id", "balance", "duration", "campaign", "pdays"]
train = train.drop(drop_columns, axis = 1)
test = test.drop(drop_columns, axis = 1)
# month を文字列から数値に変換
month_dict = {"jan": 1, "feb": 2, "mar": 3, "apr": 4, "may": 5, "jun": 6,
"jul": 7, "aug": 8, "sep": 9, "oct": 10, "nov": 11, "dec": 12}
train["month_int"] = train["month"].map(month_dict)
# month と day を datetime に変換
data_datetime = train \
.assign(ymd_str=lambda x: "2014" + "-" + x["month_int"].astype(str) + "-" + x["day"].astype(str)) \
.assign(datetime=lambda x: pd.to_datetime(x["ymd_str"])) \
["datetime"].values
# datetime を int に変換する
index = pd.DatetimeIndex(data_datetime)
train["datetime_int"] = np.log(index.astype(np.int64))
# 不要な列を削除
train = train.drop(["month", "day", "month_int"], axis=1)
del data_datetime
del index
# month を文字列から数値に変換
month_dict = {"jan": 1, "feb": 2, "mar": 3, "apr": 4, "may": 5, "jun": 6,
"jul": 7, "aug": 8, "sep": 9, "oct": 10, "nov": 11, "dec": 12}
test["month_int"] = test["month"].map(month_dict)
# month と day を datetime に変換
data_datetime = test \
.assign(ymd_str=lambda x: "2014" + "-" + x["month_int"].astype(str) + "-" + x["day"].astype(str)) \
.assign(datetime=lambda x: pd.to_datetime(x["ymd_str"])) \
["datetime"].values
# datetime を int に変換する
index = pd.DatetimeIndex(data_datetime)
test["datetime_int"] = np.log(index.astype(np.int64))
# 不要な列を削除
test = test.drop(["month", "day", "month_int"], axis=1)
del data_datetime
del index
cat_cols = ["job", "education", "default", "housing", "loan", "contact", "poutcome"]#marial削除
train_dummy = pd.get_dummies(train[cat_cols])
test_dummy = pd.get_dummies(test[cat_cols])
train_tmp = train[["datetime_int", "log_balance", "log_duration", "log_pdays", "y"]]#age, log_campaign削除
test_tmp = test[["datetime_int", "log_balance", "log_duration", "log_pdays"]]#age, log_campaign削除
train = pd.concat([train_tmp, train_dummy], axis=1)
test = pd.concat([test_tmp, test_dummy], axis=1)
train_x = train.drop(columns=["y"])
train_y = train[["y"]]
モデル作成
from sklearn.model_selection import KFold
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn import tree
K = 3 #今回は3分割
kf = KFold(n_splits=K, shuffle=True, random_state=17)
clf = tree.DecisionTreeClassifier(random_state=17)
# use a full grid over all parameters
param_grid = {"max_depth": [6, 7, 8, 9],
# "max_features": ['log2', 'sqrt','auto'],
"min_samples_split": [2, 3, 4],
"min_samples_leaf": [15, 17, 18, 19, 20, 25, 40,42,43, 44,45, 46, 47, 48, 49],
"criterion": ["gini"]} #gini係数で評価
# 次に、GridSearchCVを読んで、グリッドサーチを実行する。
tree_grid = GridSearchCV(estimator=clf,
param_grid = param_grid,
scoring="accuracy", #metrics
cv = K, #cross-validation
n_jobs =-1) #number of core
tree_grid.fit(train_x,train_y) #fit
tree_grid_best = tree_grid.best_estimator_ #best estimator
print("Best Model Parameter: ",tree_grid.best_params_)
print("Best Model Score : ",tree_grid.best_score_)
Best Model Parameter: {'criterion': 'gini', 'max_depth': 8, 'min_samples_leaf': 44, 'min_samples_split': 2}
Best Model Score : 0.9007667354762607
pred_test = tree_grid_best.predict_proba(test)[:, 1] #ちゃんとtree_grid_bestに
visualization
col_name = list(train_x.columns.values)
dot_data = StringIO()
export_graphviz(tree_grid_best, out_file=dot_data, feature_names=col_name, filled=True, rounded=True)
tree_graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
tree_graph.progs = {"dot": u"graphvizのdot.exeがあるパスを指定"} #windowsでは必要
tree_graph.write_png('tree008.png') #画像の保存
Image(tree_graph.create_png())

投稿用にデータを整形
test_for_id = pd.read_csv(input_path + "bank/test.csv", sep=",", header=0, quotechar="\"")
ID = np.array(test_for_id[["id"]]).astype(int)
my_solution = pd.DataFrame(pred_test, ID).reset_index()
# Submit File
my_solution.to_csv(
path_or_buf="../submit/submit_tree_20190601_008.csv", # 出力先
sep=",", # 区切り文字
index=False, # indexの出力有無
header=False # headerの出力有無
)
結果

目標達成!
参考・引用
以下を参考にさせて頂きました。
・https://futurismo.biz/archives/6801/
・https://github.com/mamurata0924/signate_bank_customer_targeting
・https://qiita.com/shinya7y/items/d38716ee4c81b3806eea
・http://aiweeklynews.com/archives/50653819.html