はじめに
いままでpythonや機械学習によるデータ分析の勉強に取り組んできて、いよいよデータサイエンティストとしての転職も視野に入ってきました。
就職活動を始めるにあたり「転職先の企業はどんなところが良いのか?」を悩み始めまたところです。
せっかくデータ分析を学んだのでの、企業データからどの企業が自分に向いているのかをある程度判定できるのではないか?と思い、やってみました。
50社の企業の「待遇面の満足度」「 風通しの良さ」「会社の将来性」 「年収」 「ワークライフバランス」に関するデータを集めて、このデータ分析をした結果どういう傾向が見えたのかをこの資料としてまとめます。
解決したい社会課題
就職や転職する際に、企業のデータからどの企業を選ぶべきかを、それぞれの人材が重視する項目よりどの企業が良いかを分析し、就職後のミスマッチを減らしたい。
実行環境
パソコン:MacBook Pro
開発環境:Google Coraboratory
言語:Python
ライブラリ:Pandas、Numpy、Matplotlib
分析するデータ
以下のデータを利用して、分析結果をまとめます。
| 企業No. | 待遇面の満足度 | 風通しの良さ | 会社の将来性 | 年収 | ワークライフバランス |
|---|---|---|---|---|---|
| 1 | 45 | 42 | 47 | 49 | 38 |
| 2 | 47 | 52 | 40 | 51 | 42 |
| 3 | 54 | 52 | 47 | 50 | 48 |
| 4 | 47 | 47 | 48 | 48 | 51 |
| 5 | 51 | 55 | 54 | 53 | 60 |
| 6 | 43 | 47 | 55 | 59 | 60 |
| 7 | 45 | 41 | 45 | 54 | 51 |
| 8 | 38 | 45 | 48 | 43 | 51 |
| 9 | 40 | 37 | 50 | 41 | 45 |
| 10 | 40 | 42 | 46 | 45 | 50 |
| 11 | 40 | 36 | 31 | 32 | 36 |
| 12 | 60 | 54 | 57 | 53 | 59 |
| 13 | 55 | 45 | 50 | 50 | 53 |
| 14 | 62 | 59 | 55 | 74 | 52 |
| 15 | 44 | 70 | 50 | 40 | 47 |
| 16 | 49 | 57 | 59 | 59 | 52 |
| 17 | 56 | 55 | 58 | 57 | 57 |
| 18 | 42 | 49 | 43 | 39 | 48 |
| 19 | 59 | 57 | 50 | 54 | 46 |
| 20 | 53 | 45 | 33 | 40 | 49 |
| 21 | 43 | 47 | 50 | 53 | 43 |
| 22 | 48 | 43 | 39 | 48 | 64 |
| 23 | 53 | 54 | 58 | 61 | 60 |
| 24 | 43 | 45 | 47 | 50 | 48 |
| 25 | 42 | 47 | 44 | 49 | 48 |
| 26 | 38 | 48 | 47 | 81 | 46 |
| 27 | 46 | 46 | 60 | 61 | 54 |
| 28 | 48 | 42 | 57 | 77 | 57 |
| 29 | 63 | 64 | 55 | 57 | 66 |
| 30 | 58 | 63 | 70 | 53 | 59 |
| 31 | 54 | 52 | 39 | 41 | 46 |
| 32 | 61 | 44 | 44 | 43 | 46 |
| 33 | 59 | 50 | 59 | 54 | 57 |
| 34 | 58 | 53 | 49 | 44 | 43 |
| 35 | 58 | 47 | 41 | 36 | 45 |
| 36 | 59 | 48 | 42 | 37 | 46 |
| 37 | 60 | 49 | 43 | 38 | 47 |
| 38 | 61 | 50 | 44 | 39 | 48 |
| 39 | 56 | 58 | 50 | 50 | 48 |
| 40 | 50 | 41 | 48 | 58 | 58 |
| 41 | 64 | 63 | 65 | 64 | 74 |
| 42 | 53 | 47 | 51 | 50 | 52 |
| 43 | 57 | 56 | 60 | 56 | 53 |
| 44 | 50 | 48 | 53 | 52 | 54 |
| 45 | 51 | 43 | 51 | 55 | 53 |
| 46 | 55 | 56 | 45 | 44 | 43 |
| 47 | 87 | 54 | 42 | 38 | 41 |
| 48 | 46 | 48 | 74 | 47 | 41 |
| 49 | 47 | 49 | 50 | 80 | 52 |
| 50 | 53 | 52 | 61 | 58 | 61 |
分析の流れする
- データの確認をする
- データの加工をする
- 重視する要素の決定
- レーダーチャートで可視化する
データの確認をする
まずは必要なライブラリのインポートと、上記のデータのCSVファイルを読み込みます。
実行したコード
#必要なライブラリをimport
import pandas as pd
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import collections
import japanize_matplotlib
import numpy as np
from collections import Counter
from google.colab import drive
drive.mount('/content/drive')
#読み込み先設定
df_company = pd.read_csv('/content/drive/MyDrive/最終課題1.csv',encoding='utf-8')
df1 = df_company.copy()
df1['合計'] = df1.iloc[:,1:6].sum(axis=1)
#データの確認
df_company.head()
特徴量の可視化
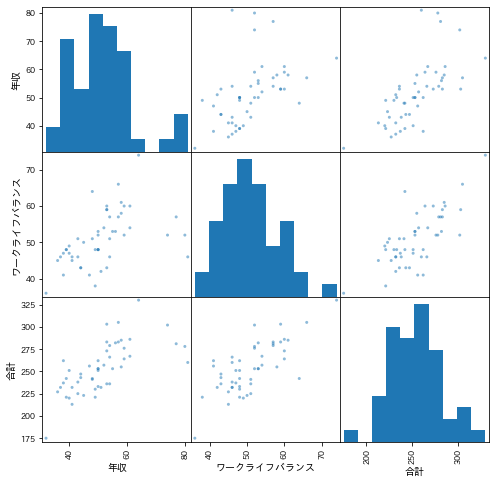
データの加工
最大値や最小値を算出、合計値の算出する
実行したコード
df1 = df_company.copy()
df1['合計'] = df1.iloc[:,1:6].sum(axis=1)
df1.describe()
集計結果
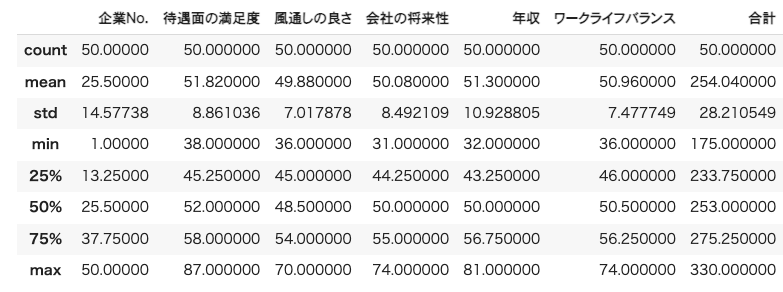
分析したデータから得られた情報
「年収」と「会社の将来性」の相関関係の有無
会社選びで重要視する要素として「年収」を選択。
「会社の将来性」との相関関係を調べて、長く続けられる仕事になるかをデータから調べてみる。
実行したコード
#重視する要素一つのときのその要素上位25%
want = str(input('重要視する要素は?⇒'))
#選んだ要素についてのグラフ
df25up = df1[df1[want] >= df1[want].quantile(q=0.75)]
df25up[['企業No.',want]].plot(kind='bar',x=df25up.columns[0],title=want)
#選んだ要素の偏差値について
df25up[want+'ss'] = (df25up[want]-df25up[want].mean()) / df25up[want].std() * 10 + 50
df25up[['企業No.',want+'ss']].plot(kind='bar',x=df25up.columns[0])
#選んだ要素との相関関係について
df25up.plot.scatter(x = want,y = (input('調べたい相関はどれか?⇒')))
実行結果
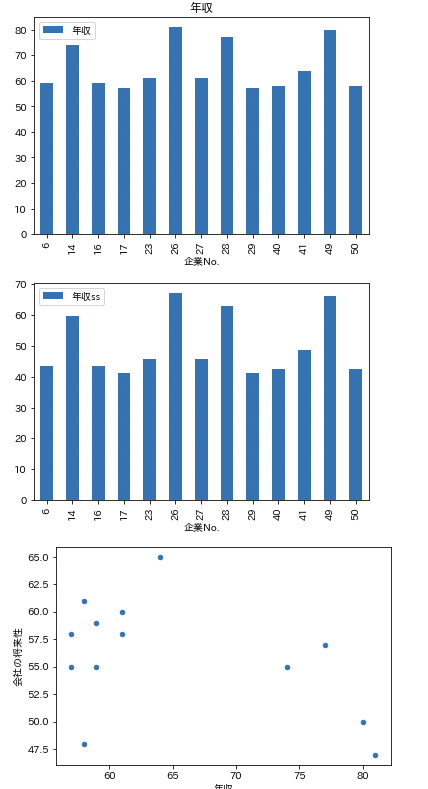
散布図を見てみると、「年収」が60~65付近に、と「会社の将来性」が60以上の高い数値が集まっているように見受けられる。
重要視する要素を増やしてみた
「年収」に加えて、「ワークライフバランス」を重要視する項目として分析してみた。
実行したコード
#重視する要素の決定
need = int(input('重要視する要素の数は1つor2つ?⇒'))
if need == 1:
a = str(input('重要視する要素名は?⇒'))
df25up = df1[df1[a] >= df1[a].quantile(q=0.75)]
df25up[['企業No.',a]].plot(kind='bar',x=df25up.columns[0],title=want,figsize=(8,8))
elif need ==2:
a = input('最も重要視するものは?⇒')
b = input('次に重要なものは?⇒')
df25up = df1[df1[a] >= df1[a].quantile(q=0.75)]
df25up[['企業No.',a,b]].plot(kind='bar',x=df25up.columns[0],stacked=True,figsize=(8,8))
labels = ['待遇面の満足度','風通しの良さ','会社の将来性','年収','ワークライフバランス']
#解析する企業No.を入力
num_com = int(input('気になっている企業Noは??⇒'))
# 多角形を閉じるためにデータの最後に最初の値を追加する。
values = df1.iloc[0,1:6].values
print(values)
radar_values = np.concatenate([values, [values[0]]])
# プロットする角度を生成する。
angles = np.linspace(0, 2 * np.pi, len(labels) + 1, endpoint=True)
# メモリ軸の生成
rgrids = [0, 20, 40, 60, 80, 100]
fig = plt.figure(facecolor="w")
# 極座標でaxを作成
ax = fig.add_subplot(1, 1, 1, polar=True)
# レーダーチャートの線を引く
ax.plot(angles, radar_values)
# レーダーチャートの内側を塗りつぶす
ax.fill(angles, radar_values, alpha=0.2)
# 項目ラベルの表示
ax.set_thetagrids(angles[:-1] * 180 / np.pi, labels)
# 円形の目盛線を消す
ax.set_rgrids([])
# 一番外側の円を消す
ax.spines['polar'].set_visible(False)
# 始点を上(北)に変更
ax.set_theta_zero_location("N")
# 時計回りに変更(デフォルトの逆回り)
ax.set_theta_direction(-1)
# 多角形の目盛線を引く
for grid_value in rgrids:
grid_values = [grid_value] * (len(labels)+1)
ax.plot(angles, grid_values, color="gray", linewidth=0.5)
# メモリの値を表示する
for t in rgrids:
# xが偏角、yが絶対値でテキストの表示場所が指定される
ax.text(x=0, y=t, s=t)
# rの範囲を指定
ax.set_rlim([min(rgrids), max(rgrids)])
ax.set_title('企業No.'+str(num_com), pad=20)
plt.show()
実行結果
データの可視化より気になった会社「企業No.49」の企業のレーダーチャーを表示。
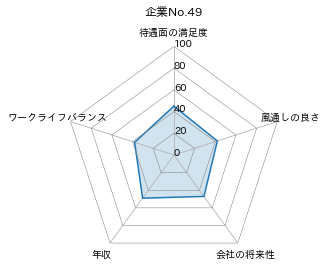
年収は高いが他の項目は平均的といったところか?
他の企業と比較してみる
第2候補の「企業No.41」と比べてみる。
実行したコード
num_com = int(input('一つ目に気になる企業Noは?⇒'))
num_com2 = int(input('二つ目に気になる企業Noは?⇒'))
values = df1.iloc[num_com-1,1:6].values
values2 = df1.iloc[num_com2-1,1:6].values
labels = ['待遇面の満足度','風通しの良さ','会社の将来性','年収','ワークライフバランス']
# 多角形を閉じるためにデータの最後に最初の値を追加する。
radar_values = np.concatenate([values, [values[0]]])
radar_values2 = np.concatenate([values2, [values2[0]]])
# プロットする角度を生成する。
angles = np.linspace(0, 2 * np.pi, len(labels) + 1, endpoint=True)
# メモリ軸の生成 #数字加えればメモリ増やせる
rgrids = [0, 20, 40, 60, 80,100]
fig = plt.figure(facecolor="w",figsize=(8,8))
# 極座標でaxを作成
ax = fig.add_subplot(1, 1, 1, polar=True)
# レーダーチャートの線を引く
ax.plot(angles, radar_values,color='yellow')
ax.plot(angles, radar_values2,color='red')
# レーダーチャートの内側を塗りつぶす
ax.fill(angles, radar_values, alpha=0.2,color='yellow')
ax.fill(angles, radar_values2, alpha =0.2,color='pink')
# 項目ラベルの表示
ax.set_thetagrids(angles[:-1] * 180 / np.pi, labels)
# 円形の目盛線を消す
ax.set_rgrids([])
# 一番外側の円を消す
ax.spines['polar'].set_visible(False)
# 始点を上(北)に変更
ax.set_theta_zero_location("N")
# 時計回りに変更(デフォルトの逆回り)
ax.set_theta_direction(-1)
# 多角形の目盛線を引く
for grid_value in rgrids:
grid_values = [grid_value] * (len(labels)+1)
ax.plot(angles, grid_values, color="gray", linewidth=0.5)
for grid_values2 in rgrids:
grid_values2 = [grid_values2] * (len(labels)+1)
ax.plot(angles,grid_values2, color="gray", linewidth=0.5)
# メモリの値を表示する
for t in rgrids:
# xが偏角、yが絶対値でテキストの表示場所が指定される
ax.text(x=0, y=t, s=t)
# rの範囲を指定
ax.set_rlim([min(rgrids), max(rgrids)])
ax.set_title('企業No.'+str(num_com)+'と企業No.'+str(num_com2), pad=20)
ax.legend(["No."+str(num_com),"No."+str(num_com2)])
plt.show()
実行結果
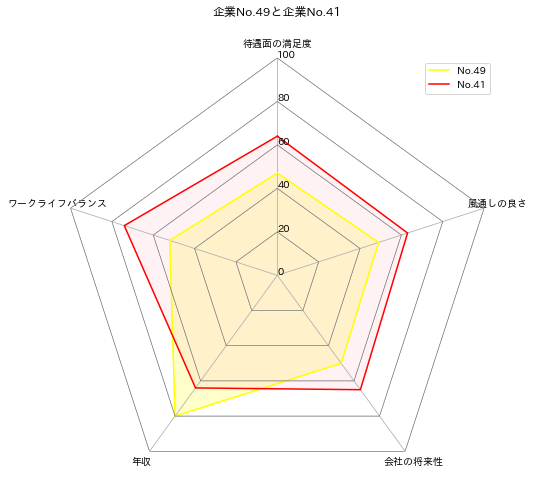
No.41の企業はワークライフバランスは良くて働きやすそうだが、年収はほどほどです。
No.49の企業との比較だと年収とのワークライフバランスのどちらを取るかという選択になりそう。
傾向
年収が高い会社ほど会社の将来性があるとは限らないと言えそう。
年収が高い企業は、ワークライフバランスが悪いことがある。
ワークライフバランスが良い企業は、年収が低いことがある。
課題
年収が高い会社はこの先伸び代が少ないということだろうか?
年収とワークライフバランスの両方を叶えることは難しいかも。
考察
今回は「年収」を軸にデータ分析してみた。
可視化した分析結果から、
年収が高い企業だと、業務で求められる仕事量や難易度が高まる分、ワークライフバランスが悪くなっていることが考えられる。
逆にワークライフバランスが良い企業では、仕事が比較的仕事量がく少なかったり求められる責任も少ない分、年収も下がっているように見える。
まとめ
「ワークライフバランス」と「年収」を重要視した時、両方を獲得できる企業は少なく、転職・就職活動での企業選びではどちらかを選択する必要がありそう。
転職・就職活動において「企業選び」がいかに難しくて重要であるかということが、データの分析結果からも読み取ることができました。
他の視点でもデータ分析をしてみて企業研究をして慎重にデータサイエンティストへの転職活動を進めようと思いました。
分析結果によっては、無理して転職しなくても今の仕事を続けるという選択肢も出てくるのではないか?と思います。
引き続きデータ分析手法の研究も含めて、企業データの分析をやってみたいと思います。