本記事は自分が開発している深層強化学習ライブラリ「d3rlpy」の紹介記事です.
d3rlpyとは?
d3rlpyは2020年度未踏IT人材発掘・育成事業に採択されて開発を始めた深層強化学習ライブラリです.未踏事業後の現在でもプライベートで開発を続けています.
d3rlpyの最大の特徴は「オフライン強化学習」というパラダイムを手厚くサポートしている点です.後述しますが,オフライン強化学習は事前に用意されたデータセットを使って強化学習を行うことができるので,ロボットや医療系のドメインなどの探索的に環境とインタラクションすることが困難な用途に強化学習を応用することができます.
d3rlpyはこれまで2021年のNeurIPS Offline RL Workshopで発表したり,昨年の10月あたりにJournal of Machine Learning Research (JMLR)というPFNのChainerRLが掲載された論文誌にも採択されています.これまで主に英語で発表してきたため,海外で多くの人に認知してもらえており,最近ではGitHubスターも1Kを超えて,多くの論文に引用してもらっています.競合ソフトウェアのインストール数(pip installされた数)などの比較をしてみると,海外の有名ライブラリといい勝負をしており,日本発の深層強化学習ライブラリとしては現在世界でもっとも利用されていると言えます.
開発状況としては,2022年度はジャーナル化や社会人博士の博論に追われていたため,機能開発を進めるのがむずかしかったのですが,最近になって博士の公聴会も終わり,ようやく開発を再開することができました.今回の記事では最近メジャーアップデートを行ったバージョンv2系をベースに紹介させていただきます.
オフライン強化学習とは?
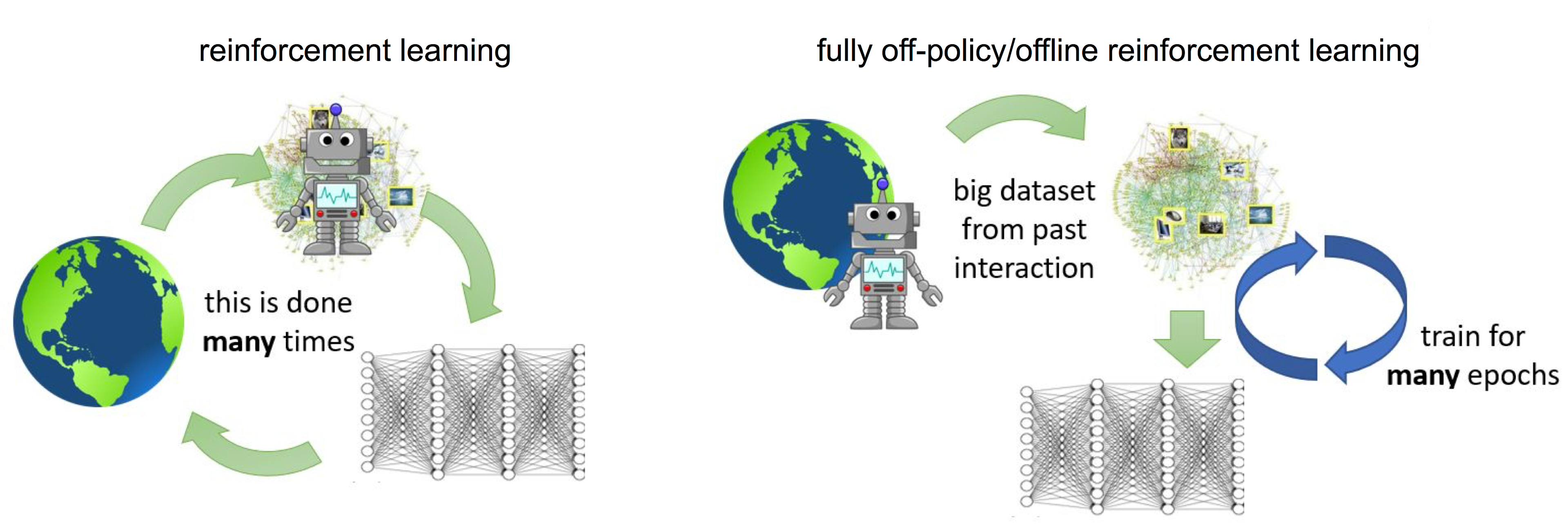
出典: https://bair.berkeley.edu/blog/2019/12/05/bear/
一般的に強化学習と聞いて思い浮かべるのは,上の画像の右側のようにエージェントが環境とインタラクションを繰り返しながら学習していくオンライン学習だと思います.一方,オフライン強化学習は事前に収集された経験データのみを使ってオフラインで学習します.学習中に環境と一切インタラクションがないため,以下のようなケースとの相性がいいです.
- ロボットや自動運転のような試行錯誤するコストの大きいタスク.
- 投薬治験のようなミッションクリティカルなタスク.
- Webサービスのように大量のログを定期的に収集できるタスク.
オフライン強化学習を用いることで,強化学習をより多様な問題設定に適用できるようになるため,ここ数年でかなり活発に研究されています.一方,オフライン強化学習の難しさとして次のようなものが挙げられます.
- (特に深層強化学習で)Q学習の推定値が過剰に推定されて発散してしまう.
- 学習中に環境とインタラクションしないため,モデルの性能が実際にデプロイするまでわからない.
オフライン強化学習では1番目の問題があり,通常の強化学習アルゴリズムではうまく学習することができません.これを解決するためにオフライン強化学習の研究では様々なアプローチが提案されており,代表的なものではBCQやCQLといったアルゴリズムが提案されています.
ここでポイントなのが通常のオンライン学習向けのアルゴリズムではオフライン学習を行うのが難しい点です.多くの深層強化学習ライブラリではオンライン学習向けのアルゴリズムを主にサポートしているため,オフライン強化学習の研究開発に利用することができません.そこで,d3rlpyでは多くのオフライン強化学習のアルゴリズムをサポートすることで差別化しています.
次の章で実際にd3rlpyを触ってみましょう.
ハンズオン
まず,d3rlpyをインストールします.v1系では一部Cythonを使っていた部分があり,まれにインストールに詰まる場合があったのですが,v2系からはすべてPythonで書かれているのでさくっとインストールできると思います.
$ pip install d3rlpy
それでは,実際にd3rlpyを使ってオフライン強化学習してみましょう.d3rlpyではいくつかの学習に使えるデータセットも用意しています.今回はCartPoleという簡単な(でも代表的な)タスクを学習してみましょう.この学習は以下のような短いコードで実装できます.
import d3rlpy
# prepare dataset and environment
dataset, env = d3rlpy.datasets.get_cartpole()
# setup Conservative Q-Learning
cql = d3rlpy.algos.DiscreteCQLConfig(target_update_interval=100).create()
# offline RL training
cql.fit(
dataset,
n_steps=10000,
n_steps_per_epoch=1000,
evaluators={"environment": d3rlpy.metrics.EnvironmentEvaluator(env)},
)
上記のコードを実際に実行してみると,CPUだけでもすぐに学習が終わると思います.
それでは実際に学習されたモデルの動作を確認してみましょう.d3rlpyは d3rlpy CLI を提供しており,コマンドラインからd3rlpyの機能を呼び出すことができます.今回は d3rlpy play というコマンドを使って学習済みモデルを動かしてみましょう.
# レンダリングのために必要
$ pip install pygame
# 学習済みモデルをロードして評価 (xxxの部分は実際のディレクトリを確認)
$ d3rlpy play --env-id CartPole-v1 d3rlpy_logs/DiscreteCQL_xxx/model_10000.d3
上記のコマンドを実行すると以下のような振る舞いを見ることができます.
ちなみに,プログラムからなら以下のようにして実行できます.
import d3rlpy
import gym
# prepare environment
env = gym.make("CartPole-v1", render_mode="human")
# load pre-trained model (replace xxx)
cql = d3rlpy.load_learnable("d3rlpy_logs/DiscreteCQL_xxx/model_10000.d3")
# evaluate model
d3rlpy.metrics.evaluate_qlearning_with_environment(cql, env)
この d3 拡張子のファイルはd3rlpy独自の学習済みモデルの仕様になっています.詳しい説明は別の記事で紹介したいと思いますが,一つのファイルにアルゴリズムの設定値をシリアライズしたものとPyTorchのパラメータを保存することによって,あとから簡単にモデルを復元することを可能にしています.
他の機能などに興味があれば,ドキュメントやチュートリアルも整備しているので,そちらもご確認ください.
https://d3rlpy.readthedocs.io/en/v2.0.4/
さいごに
今回はd3rlpyのざっくりした紹介をさせていただきました.
d3rlpyは強化学習の研究者に使ってもらうだけでなく,エンジニアが実際のアプリケーションに強化学習を組み込めるようにすることを目指して開発しています.今回の記事をきっかけにいろいろな人に興味を持っていただけたら嬉しいです.
今後も,ライブラリの設計の詳細や発展的な使い方などを記事にしていく予定です.もし,質問やバグなどを発見しましたら,GitHubのIssueで報告していただけると大変助かります!あと,興味をもっていただけたらGitHubスターをいただけると励みになるのでよろしくおねがいします!
ちなみに,オフライン強化学習の難しい点として上げた
学習中に環境とインタラクションしないため,モデルの性能が実際にデプロイするまでわからない.
に対しては「Off-policy Evaluation (OPE)」という分野があります.
余談ですが,博報堂テクノロジーズがオープンソースとして最近公開したOPEライブラリにd3rlpyががっつり利用されています.そちらも興味があったらぜひご覧ください.
記事: https://prtimes.jp/main/html/rd/p/000000007.000113498.html