目的
データサイエンスはそこまで詳しくはないのですが、ChatGPT4oを使ってKaggleの問題に挑戦してみました。結果からすると、データを処理して回答を出すところまではいきましたが、成績は全然よくなかった。
取り組んだ問題
所感
- 一発のプロンプトでいきなり正解にたどり着くことは絶対にない
- ChatGPTは言ったことは大体やってくれるが、細かい部分でエラーがでたりする
- 本人がそれなりにPandasなどの使い方をわかっていないと成功しない
- ChatGPTはエラーメッセージを渡せば対処してくれる
- データ結合など、処理が複雑になってくると段々間違いが多くなってくる
- 大きいデータは渡せないので、最初の100行くらいで構成されているデータを渡すといろいろ解釈してくれる
- ファイル構成を画像から認識してくれる
- 最後までいけるようになったら、特徴量エンジニアリングとかモデル作成とかをがんばればよいものができるのかも
プロンプト
とりあえず、一発目はこのように指定しました。その後たくさんのやりとりがある。
以下は、データの内容です。このデータからTARGETを予測するモデルを作ることが目的です。オリジナルのデータファイルは大きすぎるので、先頭100行を含んでいます。
1) 各データをEDAしてデータを可視化するためのスクリプトを作成してください
2) データをSK_ID_CURRのキーをベースに統合して、nanは適宜置換か削除し、予測モデルに不要なデータを削除し。データからモデル作成ができるようダミーデータなどを用いてデータを加工するスクリプトを作成してください
3) 2で統合したデータをベースに HomeCredit_columns_description.csv を参考にしながら予測モデル作成のための特徴量エンジニアリングをするスクリプトを作成してください
4) 3で作成したデータからTARGETを予測するための予測モデルを作成するためのスクリプトを作成してください。最終的な出力がsample_submission.csvのようになるように、最終出力を作成してください。
application_{train|test}.csv
This is the main table, broken into two files for Train (with TARGET) and Test (without TARGET).
Static data for all applications. One row represents one loan in our data sample.
bureau.csv
All client's previous credits provided by other financial institutions that were reported to Credit Bureau (for clients who have a loan in our sample).
For every loan in our sample, there are as many rows as number of credits the client had in Credit Bureau before the application date.
bureau_balance.csv
Monthly balances of previous credits in Credit Bureau.
This table has one row for each month of history of every previous credit reported to Credit Bureau – i.e the table has (#loans in sample * # of relative previous credits * # of months where we have some history observable for the previous credits) rows.
POS_CASH_balance.csv
Monthly balance snapshots of previous POS (point of sales) and cash loans that the applicant had with Home Credit.
This table has one row for each month of history of every previous credit in Home Credit (consumer credit and cash loans) related to loans in our sample – i.e. the table has (#loans in sample * # of relative previous credits * # of months in which we have some history observable for the previous credits) rows.
credit_card_balance.csv
Monthly balance snapshots of previous credit cards that the applicant has with Home Credit.
This table has one row for each month of history of every previous credit in Home Credit (consumer credit and cash loans) related to loans in our sample – i.e. the table has (#loans in sample * # of relative previous credit cards * # of months where we have some history observable for the previous credit card) rows.
previous_application.csv
All previous applications for Home Credit loans of clients who have loans in our sample.
There is one row for each previous application related to loans in our data sample.
installments_payments.csv
Repayment history for the previously disbursed credits in Home Credit related to the loans in our sample.
There is a) one row for every payment that was made plus b) one row each for missed payment.
One row is equivalent to one payment of one installment OR one installment corresponding to one payment of one previous Home Credit credit related to loans in our sample.
HomeCredit_columns_description.csv
This file contains descriptions for the columns in the various data files.
画像のようなデータ同士の対応付になっています。SK_ID_PREVのデータを、対応するSK_ID_CURRにくっつけてSK_ID_PREV自体は削除してください。同様にSK_ID_BUREAUのデータを、対応するSK_ID_CURRにくっつけてSK_ID_BUREAU自体は削除してください。最終的に上記のクレジットカードの滞納をする人を予測するために必要だと思われるRowラベルを残し、trainデータとtestデータを作成してください。SK_ID_CURRとTARGETはオリジナルの値を保持するようにしてください。application_train.csv, application_test.csv, bureau.csv, bureau_balance.csv, previous_application.csv, instalments_payments.csv, credit_card_balance.csv, POS_CASH_balance.csvを読み込んで、上記の関連するRowデータを残す処理をするスクリプトを作成してください。
画像と言っているのは、以下のファイルの相関を表す画像のこと
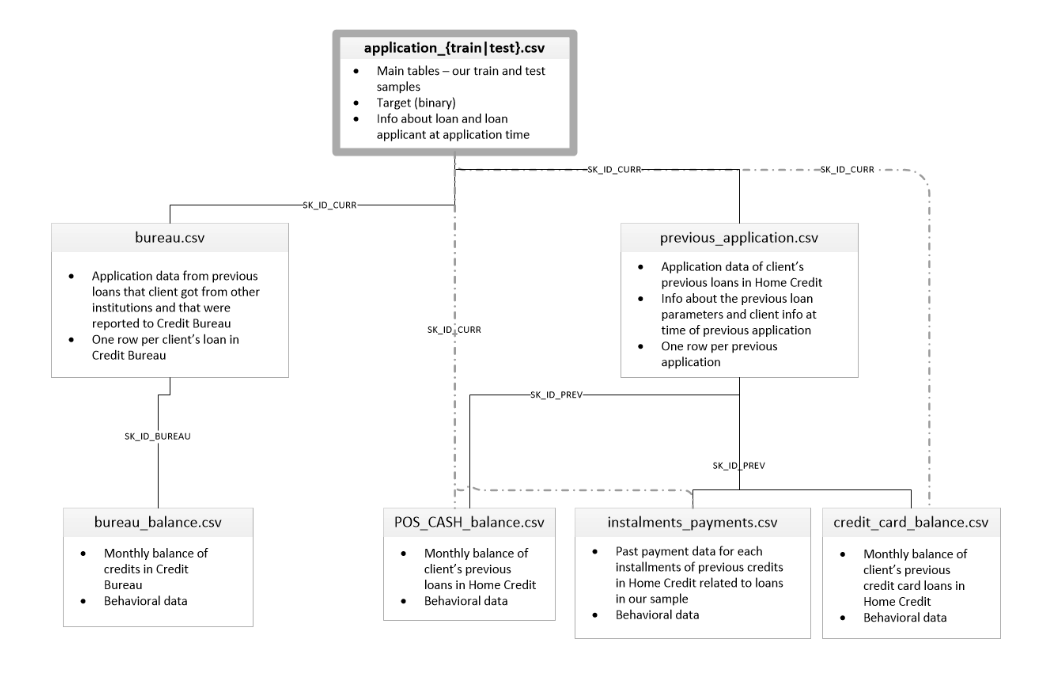
それぞれのデータのcsvファイルは先頭100行を切り取ったデータを渡した。HomeCredit_columns_description.csvはデータの説明なのでそのままChatGPTに渡している。
プロンプトをそのままシェアしようと思ったが、データを含むプロンプトはシェアできないのだとか。以下は出力されたスクリプトにあとからごちゃごちゃ修正を入れた最終形。別に優れたコードでもないのですが、ChatGPTに作ってもらったらどうなるのか、という参考まで。
スクリプト Step1 EDA
こういう単純な作業は結構しっかりやってくれる。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
# データ読み込み
application_train = pd.read_csv('application_train.csv')
application_test = pd.read_csv('application_test.csv')
# 結果を保存するディレクトリを作成
output_dir = 'data/'
os.makedirs(output_dir, exist_ok=True)
# 基本統計量の表示
application_train.describe().to_csv(os.path.join(output_dir, 'train_describe.csv'))
application_test.describe().to_csv(os.path.join(output_dir, 'test_describe.csv'))
# 欠損値の確認
application_train.isnull().sum().to_csv(os.path.join(output_dir, 'train_missing_values.csv'))
application_test.isnull().sum().to_csv(os.path.join(output_dir, 'test_missing_values.csv'))
# TARGETの分布
plt.figure(figsize=(16, 10))
sns.countplot(x='TARGET', data=application_train)
plt.title('Distribution of TARGET variable')
plt.savefig(os.path.join(output_dir, 'target_distribution.png'))
plt.close()
# 数値変数の分布
num_cols = application_train.select_dtypes(include=['int64', 'float64']).columns
application_train[num_cols].hist(figsize=(24, 20), bins=50, xlabelsize=8, ylabelsize=8)
plt.savefig(os.path.join(output_dir, 'numeric_columns_distribution.png'))
plt.close()
# カテゴリ変数の分布
cat_cols = application_train.select_dtypes(include=['object']).columns
for col in cat_cols:
plt.figure(figsize=(16, 10))
sns.countplot(y=col, data=application_train, order=application_train[col].value_counts().index)
plt.title(f'Distribution of {col}')
plt.savefig(os.path.join(output_dir, f'{col}_distribution.png'))
plt.close()
スクリプト Step2 データクレンジングとマージ
ここが結構苦労した。自分のマシンのメモリが足らなくて、いろいろな試行錯誤が必要だった。メモリが足りない、というのをChatGPTに相談したらそのへんはちゃんとやってくれたが、それでもダメだったのでtrainのデータを間引いている。とりあえず、最後までやりきるのが目的だったので、精度は求めない。SK_ID_CURRというのが個人を表すIDでファイル間でこのIDを使ってデータを紐づけしている。データがでかいので、関係ありそうなものを抜粋するようにした。
import pandas as pd
import gc
# Base directory for input files
base_dir = '/data' #ローカルディレクトリ名なのでここはダミー
# Output directory for final datasets
output_dir = '/output' #ローカルディレクトリ名なのでここはダミー
# Load the datasets
bureau = pd.read_csv(f'{base_dir}/bureau.csv')
bureau_balance = pd.read_csv(f'{base_dir}/bureau_balance.csv')
previous_application = pd.read_csv(f'{base_dir}/previous_application.csv')
installments_payments = pd.read_csv(f'{base_dir}/installments_payments.csv')
credit_card_balance = pd.read_csv(f'{base_dir}/credit_card_balance.csv')
pos_cash_balance = pd.read_csv(f'{base_dir}/POS_CASH_balance.csv')
# Define the relevant columns for predicting credit card defaults
relevant_columns_train = {
'application': ['SK_ID_CURR', 'TARGET', 'NAME_CONTRACT_TYPE', 'CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY',
'CNT_CHILDREN', 'AMT_INCOME_TOTAL', 'AMT_CREDIT', 'AMT_ANNUITY', 'AMT_GOODS_PRICE', 'NAME_TYPE_SUITE',
'NAME_INCOME_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'NAME_HOUSING_TYPE', 'DAYS_BIRTH',
'DAYS_EMPLOYED', 'FLAG_MOBIL', 'FLAG_EMP_PHONE', 'FLAG_WORK_PHONE', 'FLAG_CONT_MOBILE', 'FLAG_PHONE',
'FLAG_EMAIL', 'OCCUPATION_TYPE', 'CNT_FAM_MEMBERS', 'REGION_RATING_CLIENT', 'REGION_RATING_CLIENT_W_CITY'],
'bureau': ['SK_ID_CURR', 'SK_ID_BUREAU', 'CREDIT_ACTIVE', 'CREDIT_CURRENCY', 'DAYS_CREDIT', 'CREDIT_DAY_OVERDUE',
'DAYS_CREDIT_ENDDATE', 'DAYS_ENDDATE_FACT', 'AMT_CREDIT_MAX_OVERDUE', 'CNT_CREDIT_PROLONG', 'AMT_CREDIT_SUM',
'AMT_CREDIT_SUM_DEBT', 'AMT_CREDIT_SUM_LIMIT', 'AMT_CREDIT_SUM_OVERDUE', 'CREDIT_TYPE', 'DAYS_CREDIT_UPDATE', 'AMT_ANNUITY'],
'bureau_balance': ['SK_ID_BUREAU', 'MONTHS_BALANCE', 'STATUS'],
'previous_application': ['SK_ID_CURR', 'SK_ID_PREV', 'NAME_CONTRACT_TYPE', 'AMT_ANNUITY', 'AMT_APPLICATION', 'AMT_CREDIT',
'AMT_DOWN_PAYMENT', 'AMT_GOODS_PRICE', 'WEEKDAY_APPR_PROCESS_START', 'HOUR_APPR_PROCESS_START',
'FLAG_LAST_APPL_PER_CONTRACT', 'NFLAG_LAST_APPL_IN_DAY', 'NAME_CASH_LOAN_PURPOSE', 'NAME_CONTRACT_STATUS',
'DAYS_DECISION', 'NAME_PAYMENT_TYPE', 'CODE_REJECT_REASON', 'NAME_TYPE_SUITE', 'NAME_CLIENT_TYPE',
'NAME_GOODS_CATEGORY', 'NAME_PORTFOLIO', 'NAME_PRODUCT_TYPE', 'CHANNEL_TYPE', 'NAME_SELLER_INDUSTRY',
'CNT_PAYMENT', 'NAME_YIELD_GROUP', 'PRODUCT_COMBINATION', 'DAYS_FIRST_DRAWING', 'DAYS_FIRST_DUE',
'DAYS_LAST_DUE_1ST_VERSION', 'DAYS_LAST_DUE', 'DAYS_TERMINATION', 'NFLAG_INSURED_ON_APPROVAL'],
'installments_payments': ['SK_ID_CURR', 'SK_ID_PREV', 'NUM_INSTALMENT_VERSION', 'NUM_INSTALMENT_NUMBER', 'DAYS_INSTALMENT',
'DAYS_ENTRY_PAYMENT', 'AMT_INSTALMENT', 'AMT_PAYMENT'],
'credit_card_balance': ['SK_ID_CURR', 'SK_ID_PREV', 'MONTHS_BALANCE', 'AMT_BALANCE', 'AMT_CREDIT_LIMIT_ACTUAL', 'AMT_DRAWINGS_ATM_CURRENT',
'AMT_DRAWINGS_CURRENT', 'AMT_DRAWINGS_OTHER_CURRENT', 'AMT_DRAWINGS_POS_CURRENT', 'AMT_INST_MIN_REGULARITY',
'AMT_PAYMENT_CURRENT', 'AMT_PAYMENT_TOTAL_CURRENT', 'AMT_RECEIVABLE_PRINCIPAL', 'AMT_RECIVABLE',
'AMT_TOTAL_RECEIVABLE', 'CNT_DRAWINGS_ATM_CURRENT', 'CNT_DRAWINGS_CURRENT', 'CNT_DRAWINGS_OTHER_CURRENT',
'CNT_DRAWINGS_POS_CURRENT', 'CNT_INSTALMENT_MATURE_CUM', 'NAME_CONTRACT_STATUS', 'SK_DPD', 'SK_DPD_DEF'],
'pos_cash_balance': ['SK_ID_CURR', 'SK_ID_PREV', 'MONTHS_BALANCE', 'CNT_INSTALMENT', 'CNT_INSTALMENT_FUTURE', 'NAME_CONTRACT_STATUS',
'SK_DPD', 'SK_DPD_DEF']
}
relevant_columns_test = {
'application': ['SK_ID_CURR', 'NAME_CONTRACT_TYPE', 'CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY',
'CNT_CHILDREN', 'AMT_INCOME_TOTAL', 'AMT_CREDIT', 'AMT_ANNUITY', 'AMT_GOODS_PRICE', 'NAME_TYPE_SUITE',
'NAME_INCOME_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'NAME_HOUSING_TYPE', 'DAYS_BIRTH',
'DAYS_EMPLOYED', 'FLAG_MOBIL', 'FLAG_EMP_PHONE', 'FLAG_WORK_PHONE', 'FLAG_CONT_MOBILE', 'FLAG_PHONE',
'FLAG_EMAIL', 'OCCUPATION_TYPE', 'CNT_FAM_MEMBERS', 'REGION_RATING_CLIENT', 'REGION_RATING_CLIENT_W_CITY'],
'bureau': relevant_columns_train['bureau'],
'bureau_balance': relevant_columns_train['bureau_balance'],
'previous_application': relevant_columns_train['previous_application'],
'installments_payments': relevant_columns_train['installments_payments'],
'credit_card_balance': relevant_columns_train['credit_card_balance'],
'pos_cash_balance': relevant_columns_train['pos_cash_balance']
}
# Extract relevant columns from each dataframe
bureau = bureau[relevant_columns_train['bureau']]
bureau_balance = bureau_balance[relevant_columns_train['bureau_balance']]
previous_application = previous_application[relevant_columns_train['previous_application']]
installments_payments = installments_payments[relevant_columns_train['installments_payments']]
credit_card_balance = credit_card_balance[relevant_columns_train['credit_card_balance']]
pos_cash_balance = pos_cash_balance[relevant_columns_train['pos_cash_balance']]
print("Data loaded and relevant columns extracted")
# Merge bureau_balance with bureau
bureau = pd.get_dummies(bureau)
bureau_balance = pd.get_dummies(bureau_balance)
bureau_balance_grouped = bureau_balance.groupby('SK_ID_BUREAU', as_index=False).mean()
bureau_merged = bureau.merge(bureau_balance_grouped, on='SK_ID_BUREAU', how='left')
print("Bureau and bureau_balance merged")
# Merge previous_application with its related datasets
installments_payments = pd.get_dummies(installments_payments)
installments_payments_grouped = installments_payments.groupby('SK_ID_PREV', as_index=False).mean()
credit_card_balance = pd.get_dummies(credit_card_balance)
credit_card_balance_grouped = credit_card_balance.groupby('SK_ID_PREV', as_index=False).mean()
pos_cash_balance = pd.get_dummies(pos_cash_balance)
pos_cash_balance_grouped = pos_cash_balance.groupby('SK_ID_PREV', as_index=False).mean()
previous_application = pd.get_dummies(previous_application)
previous_application_merged = previous_application.merge(installments_payments_grouped, on='SK_ID_PREV', how='left', suffixes=('', '_installments'))
previous_application_merged = previous_application_merged.merge(credit_card_balance_grouped, on='SK_ID_PREV', how='left', suffixes=('', '_credit_card'))
previous_application_merged = previous_application_merged.merge(pos_cash_balance_grouped, on='SK_ID_PREV', how='left', suffixes=('', '_pos_cash'))
print("Previous_application and related datasets merged")
# Release memory
del installments_payments, installments_payments_grouped, credit_card_balance, credit_card_balance_grouped, pos_cash_balance, pos_cash_balance_grouped
gc.collect()
print("Memory released")
# Drop SK_ID_PREV and SK_ID_BUREAU after merging
bureau_merged = bureau_merged.drop(columns=['SK_ID_BUREAU'])
previous_application_merged = previous_application_merged.drop(columns=['SK_ID_PREV'])
print("SK_ID_PREV and SK_ID_BUREAU dropped")
# Merge with main application data for training set
# Convert text data to dummy variables
application_train = pd.read_csv(f'{base_dir}/application_train.csv')
# データをサンプリング
df_key_zero = application_train[application_train['TARGET'] == 0]
df_key_non_zero = application_train[application_train['TARGET'] != 0]
df_key_zero_sample = df_key_zero.sample(frac=0.2, random_state=42)
df_key_non_zero_sample = df_key_non_zero.sample(frac=1.0, random_state=45)
application_train = pd.concat([df_key_zero_sample, df_key_non_zero_sample])
del df_key_zero, df_key_non_zero, df_key_zero_sample, df_key_non_zero_sample
gc.collect()
application_train = application_train[relevant_columns_train['application']]
application_train = pd.get_dummies(application_train)
train = application_train.merge(bureau_merged, on='SK_ID_CURR', how='left')
train = train.merge(previous_application_merged, on='SK_ID_CURR', how='left')
# Select only the relevant columns and drop rows with NaNs
train = train[['SK_ID_CURR', 'TARGET'] + [col for col in train.columns if col != 'TARGET' and col != 'SK_ID_CURR']]
train.fillna(0, inplace=True)
train = train.groupby('SK_ID_CURR').mean().reset_index()
# print(application_train.isnull().sum())
# print(f"Number of rows in train dataset before dropping NaNs: {train.shape[0]}")
# train = train.dropna(how='all').dropna(how='all', axis=1)
# print(f"Number of rows in train dataset after dropping NaNs: {train.shape[0]}")
# Save the training dataset
train.to_csv(f'{output_dir}/processed_train_data.csv', index=False)
# 先頭100行を抽出
train_cut = train.head(100)
# 新しいファイル名を作成
train_full_file_path = f'{output_dir}/processed_train_data_cut.csv'
# 新しいCSVファイルとして保存
train_cut.to_csv(train_full_file_path, index=False)
# Load the application_test data
application_test = pd.read_csv(f'{base_dir}/application_test.csv')
# Extract relevant columns from application_test
application_test = application_test[relevant_columns_test['application']] # 'TARGET' is not in test set
# Convert text data to dummy variables
application_test = pd.get_dummies(application_test)
# Merge with main application data for test set
test = application_test.merge(bureau_merged, on='SK_ID_CURR', how='left')
test = test.merge(previous_application_merged, on='SK_ID_CURR', how='left')
# Select only the relevant columns and drop rows with NaNs
test = test[['SK_ID_CURR'] + [col for col in test.columns if col != 'SK_ID_CURR']]
test.fillna(0, inplace=True)
test = test.groupby('SK_ID_CURR').mean().reset_index()
# print(f"Number of rows in test dataset before dropping NaNs: {test.shape[0]}")
# test = test.dropna()
# print(f"Number of rows in test dataset after dropping NaNs: {test.shape[0]}")
# Save the test dataset
test.to_csv(f'{output_dir}/processed_test_data.csv', index=False)
# 先頭100行を抽出
test_cut = test.head(100)
# 新しいファイル名を作成
test_full_file_path = f'{output_dir}/processed_test_data_cut.csv'
# 新しいCSVファイルとして保存
test_cut.to_csv(test_full_file_path, index=False)
スクリプト Step3 特徴量エンジニアリング
ここは全然ダメだった。予測モデルが作れる処理にならなかったので省略。Step2の出力で予測モデルは一応作れる。
スクリプト Step4 予測モデル作成と最終出力
ランダムフォレストで予測モデルを作って、testデータの予測して、最終出力のsubmission.csvが出せた。Kaggleは受け付けて、スコアは0.55とかだったので、ヤマカンよりはちょっと良いくらい。まあ一応最後までたどり着いた。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load the data
train_data_path = 'processed_train_data.csv'
test_data_path = 'processed_test_data.csv'
train_data = pd.read_csv(train_data_path)
test_data = pd.read_csv(test_data_path)
# Separate features and target in the training data
X_train = train_data.drop(columns=['TARGET'])
y_train = train_data['TARGET']
# Drop SK_ID_CURR from training data if it exists
if 'SK_ID_CURR' in X_train.columns:
X_train = X_train.drop(columns=['SK_ID_CURR'])
# Extract SK_ID_CURR for the final output
test_ids = test_data['SK_ID_CURR']
# Drop SK_ID_CURR from the test data to use it for predictions
X_test = test_data.drop(columns=['SK_ID_CURR'])
# Ensure the feature columns match between train and test sets
missing_cols = set(X_train.columns) - set(X_test.columns)
for col in missing_cols:
X_test[col] = 0
X_test = X_test[X_train.columns]
# Initialize and train the model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test data
test_predictions = model.predict(X_test)
# Prepare the submission dataframe
submission = pd.DataFrame({
'SK_ID_CURR': test_ids,
'TARGET': test_predictions
})
# Save the submission file
submission_output_path = 'submission.csv'
submission.to_csv(submission_output_path, index=False)
print(f"Submission file saved to: {submission_output_path}")