概要
2018/12/1にChainer Beginner's Hands-on Course #01に参加しました。
その中でfashion mnistのaccuracyを88%を超えるようにチューニングするという課題で、88%超えは多くの人は達成できたけど、90%以上の人は1人しかいないという結果だったので、自分も90%以上になるように調整してみました。
結果から言うと90%ギリギリ達成できました。
条件
以下、課題の条件です。
- Google Colaboratory上(GPU)で実行する。
- エポック数10以下
- 訓練時間100秒以内
- 全結合層のみ
- テスト用データにおいて精度88%
以下のページに必要なコードと条件などが書かれています。
00 ColaboratoryでChainerを動かしてみよう
ベースモデル
以下のモデルをチューニングしていきます。
class MLPNew(Chain):
def __init__(self):
# Add more layers?
super(MLPNew, self).__init__()
with self.init_scope():
self.l1=L.Linear(784, 200)
self.l2=L.Linear(200, 200)
self.l3=L.Linear(200, 10)
def forward(self, x):
h1 = F.tanh(self.l1(x))
h2 = F.tanh(self.l2(h1))
y = self.l3(h2)
return y
パラメータ探索順序
以下のパラメータが今回チューニングできる要素
- 各ユニットのノード数
- レイヤー数
- 活性化関数
- オプティマイザ
- オプティマイザに関するパラメータ(学習率など)
- エポック数
- ミニバッチサイズ
まずどのパラメータからチューニングするから決める。
3以降はモデルによってベストなものが変わってきそうなので、まず「ノード数」と「レイヤー数」を決める。
そのあとに「活性化関数」、「オプティマイザ」の順により精度が良くなるものを探す。
「エポック数」はとりあえず最大の10、「ミニバッチサイズ」は256にしておく。
「活性化関数」と「オプティマイザ」もまずはreluとSGDにしておく。
ノード数
ベースモデルの中間層を徐々に多くしていって、accとlossの変化を観察する。
数字は10epoch目の結果を記載。
![]() マークは一番結果が良かったものを表している。
マークは一番結果が良かったものを表している。
| node | trn_acc | val_acc | trn_loss | val_loss | time(sec) |
|---|---|---|---|---|---|
| 200 | 0.825 | 0.818 | 0.506 | 0.524 | 33 |
| 300 | 0.827 | 0.816 | 0.501 | 0.521 | 33 |
| 1000 | 0.836 | 0.826 | 0.473 | 0.492 | 33 |
| 2000 | 0.845 | 0.834 | 0.452 | 0.474 | 38 |
| 3000 | 0.848 | 0.836 | 0.441 | 0.465 | 33 |
| 4000 | 0.851 |
|
0.433 | 0.458 | 44 |
| 5000 | 0.852 |
|
0.425 |
|
60 |
| 6000 |
|
0.838 |
|
|
77 |
気づいたこと
- 中間層のノード数を増やしていくとaccは徐々に上がり、lossは徐々に下がる。
- ノード数4000からはacc/lossの推移が鈍ってくる。
- ノード数3000まではノード数を増やしているにもかかわらず処理時間の変化が少ない。
- ノード数4000からはノード数を増やすと処理時間も一緒に伸びてくる。
-
 マークの数だと6000が多いけど、val_accとval_lossで見ると5000が良さそう。
マークの数だと6000が多いけど、val_accとval_lossで見ると5000が良さそう。
結果
ノード数は5000が一番良さそう。
*処理時間について
処理時間がノード数3000まで変わらないのは、おそらくGPUが1度に並列処理できる最大量に達していないからだと推測してます。
GPUは多くの演算を並列化することで、CPU以上の速度が出せるけど、並列化する数が少ないと速度がでないみたいです。ノード数200〜3000まではGPUの1回に並列処理できる範囲に収まっているから処理時間が変わらないのかなと思っています。(詳しい方いましたら教えてください![]() )
)
レイヤー数
ノード数と同様にレイヤー数も徐々に増やしていき、結果を観察する。
| layer | trn_acc | val_acc | trn_loss | val_loss | time(sec) |
|---|---|---|---|---|---|
| 2 | 0.813 | 0.805 | 0.562 | 0.573 | 29 |
| 3 | 0.821 | 0.816 | 0.523 | 0.537 | 34 |
| 4 |
|
|
0.501 |
|
38 |
| 5 | 0.825 | 0.806 |
|
0.539 | 42 |
| 6 | 0.82 | 0.804 | 0.514 | 0.558 | 46 |
気づいたこと
- ノード数と同様にレイヤー数を増やしていくとaccは徐々に上がり、lossは徐々に下がる。
- レイヤー数4をピークに、そのあとは変化がなかったり、逆に性能が落ちている項目がある。
- ノード数と異なり、layer数を増やすと必ず処理時間が増える。
結果
レイヤー数は4が一番良さそう。
活性化関数とオプティマイザ
活性化関数とオプティマイザは特に数字を記録していなかったので結果だけ。
活性化関数
以下の活性化関数を試した。
- relu
- leaky_relu
- tanh
- sigmoid
上記順番が性能の良かった順。reluが一番良かった。
sigmoid以外は数%の差。
オプティマイザ
またオプティマイザは、以下のものを試した。
- AdaGrad
- Adam
- AdaDelta
- RMSprop
- MomentumSGD
- SGD
こちらも同様に上記順番が性能の良かった順。AdaGradが一番良かった。
AdaGradとSGDでは、val_accが8%くらい差があった。
計測
これまでの決めたパラメータをまとめると以下のようになった。
|node|layer|act_func|optimizer|epoch|mini_batch|
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|5000個|4層|relu|AdaDelta|10|256|
これで実験すると難なくテストデータのaccuracyが88%を超えて、すごく稀に90%になることがあったが、学習時間が10秒を超えてしまっていた。
なので、ここから性能を落とさずに処理時間を削るために試行錯誤した結果、最後の手前の層のノード数を5000->4700に返ると、学習時間が10秒に収まってかつ90%を超えることができた。
最終的なモデル
class MLPNew(Chain):
def __init__(self):
super(MLPNew, self).__init__()
with self.init_scope():
self.l1=L.Linear(None, 5000)
self.l2=L.Linear(5000, 5000)
self.l3=L.Linear(5000, 4700)
self.lout=L.Linear(4700, 10)
def forward(self, x):
activation = F.relu
layers = [self.l1, self.l2, self.l3, self.lout]
for layer in layers:
if layer != self.lout:
h = activation(layer(x))
x = h
else:
y = layer(x)
return y
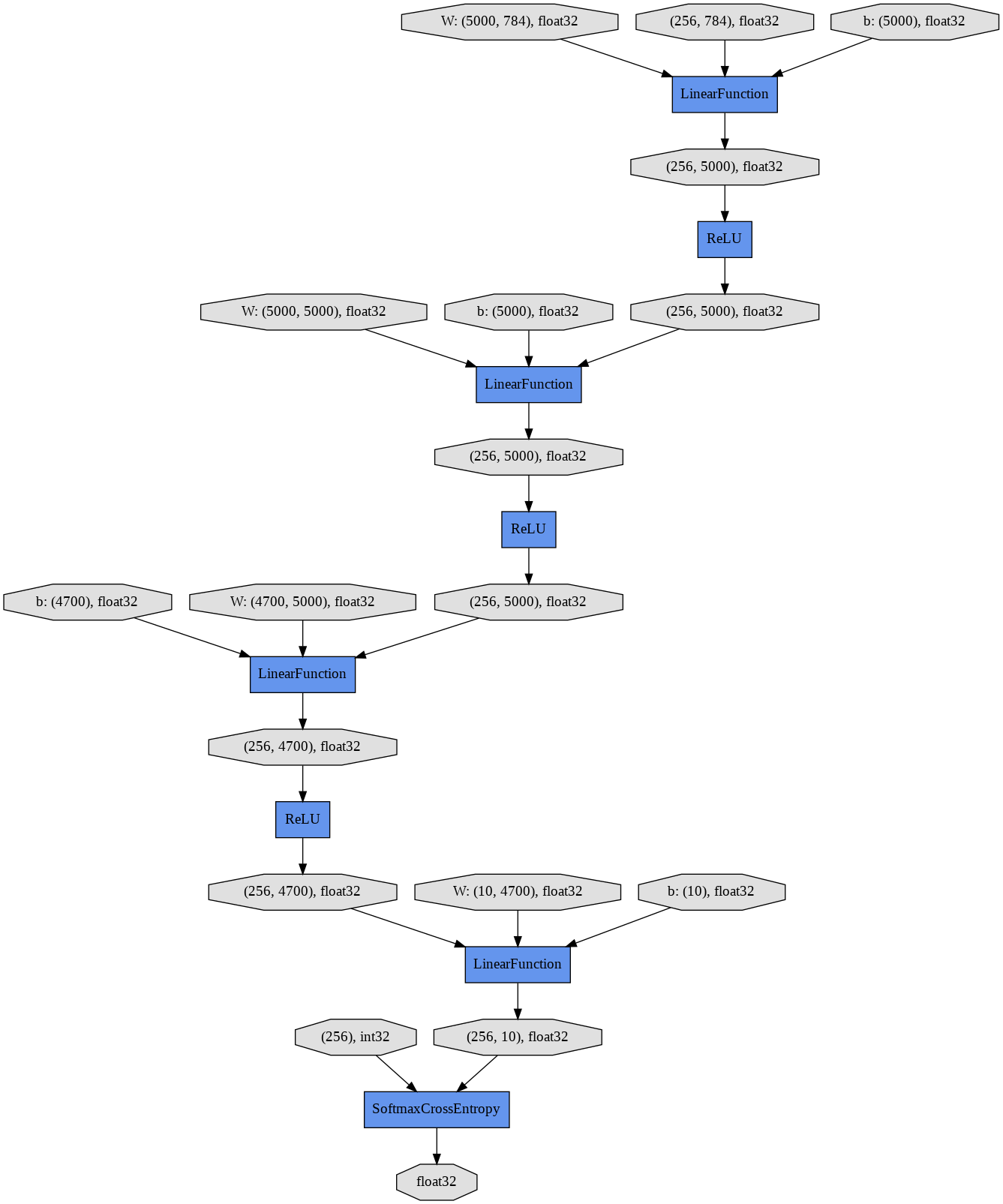
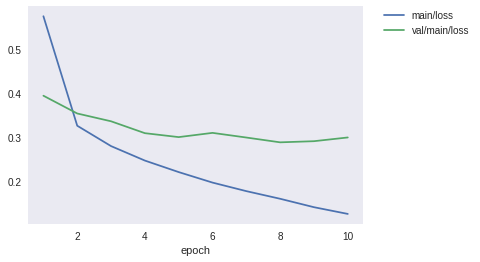
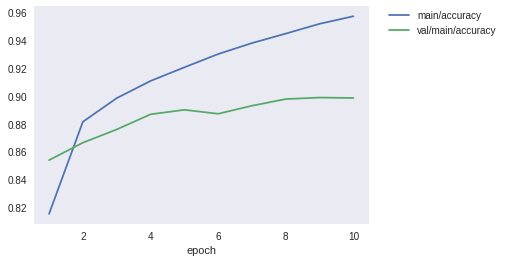
計測結果
何回か試すとたまに90%いきます。
最後の行のTest accuracyがテストデータの結果。

loss
accuracy
まとめ
Chainer分かりやすい。
ちなみにChainer Beginner's Hands-on Course 次回は2月開催みたいです。