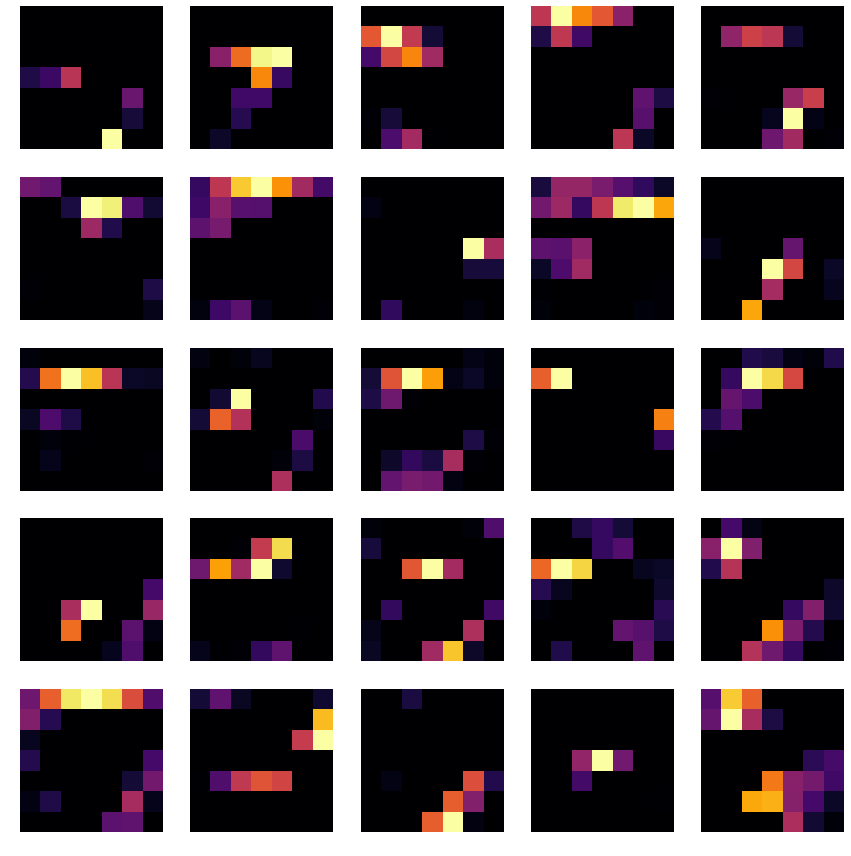概要
KerasでMNISTを学習させる記事。
やったこと
- 学習データの可視化
- データの前処理
- モデル定義
- 学習
- 学習経過をグラフで表示
- 評価
- CNNの出力マップを可視化
この記事の対象読者
- これからKerasを勉強しようと思っている人
コードと簡単な解説
まずは必要なモジュールをimport
import os,re
import keras
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
from keras.preprocessing import image
from keras import models
from keras.models import Model
from keras import Input
from keras.layers import Activation, Conv2D, MaxPooling2D, Flatten, Dense
from keras.callbacks import TensorBoard, ModelCheckpoint
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
1.学習データの可視化
MNISTをロード
# 学習データとテストデータを取得する。
(_x_train_val, _y_train_val), (_x_test, _y_test) = mnist.load_data()
# 学習中の検証データがないので、train_test_split()を使って学習データ8割、検証データを2割に分割する。test_sizeが検証データの割合になっている。
_x_train, _x_val, _y_train, _y_val = train_test_split(_x_train_val, _y_train_val, test_size=0.2)
print("x_train : ", _x_train.shape) # x_train : (48000, 28, 28)
print("y_train : ", _y_train.shape) # y_train : (48000,)
print("x_val : ", _x_val.shape) # x_val : (12000, 28, 28)
print("y_val : ", _y_val.shape) # y_val : (12000,)
print("x_test : ", _x_test.shape) # x_test : (10000, 28, 28)
print("y_test : ", _y_test.shape) # y_test : (10000,)
学習データを表示
plt.figure(figsize=(10,10))
# MNISTの0から9の画像をそれぞれ表示する。
for i in range(10):
data = [(x,t) for x, t in zip(_x_train, _y_train) if t == i]
x, y = data[0]
plt.subplot(5,2, i+1)
# plt.title()はタイトルを表示する。ここでは画像枚数を表示している。
plt.title("len={}".format(len(data)))
# 画像を見やすいように座標軸を非表示にする。
plt.axis("off")
# 画像を表示
plt.imshow(x, cmap='gray')
plt.tight_layout()
plt.show()
- plt.figure()とplt.subplot()については、matplotlib基礎 | figureやaxesでのグラフのレイアウトがとても参考になります。
- plt.imshow()で画像を表示。cmapで色を指定できる。cmapで指定できる色は、matplotlib:colormaps_reference.pyを参照。
- plt.tight_layout()はグラフのラベルなどが重なっている場合、重ならないように自動調整してくれる。詳しくは、matplotlib:Tight Layout guideを参照。
学習データ表示結果

- 学習データは1のデータ数(5407)が一番多くて、5のデータ数が一番少ない(4335)。
2.データの前処理
前処理用関数
# 学習、検証、テストデータの前処理用関数。
def preprocess(data, label=False):
if label:
# 教師データはto_categorical()でone-hot-encodingする。
data = to_categorical(data)
else:
# 入力画像は、astype('float32')で型変換を行い、レンジを0-1にするために255で割る。
# 0-255 -> 0-1
data = data.astype('float32') / 255
# Kerasの入力データの形式は(ミニバッチサイズ、横幅、縦幅、チャネル数)である必要があるので、reshape()を使って形式を変換する。
# (sample, width, height) -> (sample, width, height, channel)
data = data.reshape((-1, 28, 28, 1))
return data
前処理用関数を使って学習/検証/テストデータを生成
x_train = preprocess(_x_train)
x_val= preprocess(_x_val)
x_test = preprocess(_x_test)
y_train = preprocess(_y_train, label=True)
y_val = preprocess(_y_val, label=True)
y_test = preprocess(_y_test, label=True)
print(x_train.shape) # (48000, 28, 28, 1)
print(x_val.shape) # (12000, 28, 28, 1)
print(x_test.shape) # (10000, 28, 28, 1)
print(x_train.max()) # 1.0
print(x_val.max()) # 1.0
print(y_test.max()) # 1.0
print(y_train.shape) # (48000, 10)
print(y_val.shape) # (12000, 10)
print(y_test.shape) # (10000, 10)
- 前処理用関数を使って各データを変換する。
- 各データのshapeとmax値が所望の値になっていることがわかる。
3.モデル定義
モデルの書き方はSequentialモデルとFunctional APIの2パターンがあります。
Sequentialモデルは、層を単純に重ねていくモデルです。DeepLearningのモデルには層が分岐したり、多入力、多出力のモデルがあり、そういったモデルを実装する場合では、単純に層を積み重ねるSequentialモデルでは対応できません。
Functional APIは、こういった複雑なモデルを書くためのより柔軟なAPIです。
今回は、Sequentialモデルで十分なモデルですが、参考にFunctional APIで同じモデルを書いています。
Sequentialモデル
def model_sequential():
activation = 'relu'
model = models.Sequential()
model.add(Conv2D(32, (3, 3), padding='same', name='conv1', input_shape=(28, 28 , 1)))
model.add(Activation(activation, name='act1'))
model.add(MaxPooling2D((2, 2), name='pool1'))
model.add(Conv2D(64, (3, 3), padding='same', name='conv2'))
model.add(Activation(activation, name='act2'))
model.add(MaxPooling2D((2, 2), name='pool2'))
model.add(Conv2D(64, (3, 3), padding='same', name='conv3'))
model.add(Activation(activation, name='act3'))
model.add(Flatten(name='flatten'))
model.add(Dense(64, name='dense4'))
model.add(Activation(activation, name='act4'))
model.add(Dense(10, name='dense5'))
model.add(Activation('softmax', name='last_act'))
return model
Functional API
def model_functional_api():
activation = 'relu'
input = Input(shape=(28, 28, 1))
x = Conv2D(32, (3,3), padding='same', name='conv1')(input)
x = Activation(activation, name='act1')(x)
x = MaxPooling2D((2,2), name='pool1')(x)
x = Conv2D(64, (3,3), padding='same', name='conv2')(x)
x = Activation(activation, name='act2')(x)
x = MaxPooling2D((2,2), name='pool2')(x)
x = Conv2D(64, (3,3), padding='same', name='conv3')(x)
x = Activation(activation, name='act3')(x)
x = Flatten(name='flatten')(x)
x = Dense(64, name='dense4')(x)
x = Activation(activation, name='act4')(x)
x = Dense(10, name='dense5')(x)
output = Activation('softmax', name='last_act')(x)
model = Model(input, output)
return model
モデルのコンパイル
model = model_sequential()
model.summary()
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
- model.summary()はモデルの構成をプリントする関数。
- model.compile()はどのように学習を行うのかを決定する。
- optimizerは最適化を行う関数。使用できるoptimizerはkeras optimizersを参照。
- lossは誤差計算を行う関数。多クラス分類問題では、'categorical_crossentropy'を指定する。使用できるlossはkeras lossesを参照。
- metricsはモデルの性能を測る指標を指定する。accuracyは推論した数に対して、何回正解したかを計算してくれる。
4.学習
コールバック
ckpt_name = 'weights-{epoch:02d}-{loss:.2f}-{acc:.2f}-{val_loss:.2f}-{val_acc:.2f}-.hdf5'
cbs = [
TensorBoard(log_dir=log_dir),
ModelCheckpoint(os.path.join(log_dir, ckpt_name),
monitor='val_acc', verbose=0,
save_best_only=False,
save_weights_only=True,
mode='auto', period=1)
]
- コールバックを設定することで、学習の途中経過をTensorBoardで見たり、学習中の重みをファイルとして残せたりすることができる。
- コールバックについては、Kerasのcallbackを試す(modelのsave,restore/TensorBoard書き出し/early stopping)が参考になります。
- チェックポイントのファイル名は、ckpt_nameで指定しているように、epochやaccなので情報を使ってファイル名を作ってくれる。例えば、3epoch目のファイル名は「weights-03-0.08-0.98-0.05-0.99-.hdf5」みたいなファイル名になる。これはval_lossが0.05でval_accが0.99の重みであることを示している。
データ拡張
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=False,
vertical_flip=False)
- データ拡張については、Kerasでデータ拡張(Data Augmentation)後の画像を表示するで以前まとめたので、こちらを参照してください。
学習処理
batch_size=128
epochs=3
verbose=1
steps_per_epoch = x_train.shape[0] // batch_size
history = model.fit_generator(
datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=cbs,
verbose=verbose)
- model.fit_generator()は、generator関数を使ってミニバッチを生成しモデルに入力したい場合に使う。今回は、ImageDataGeneratorでデータ拡張した画像を入力したいので使う。
- データ拡張の必要がないのであれば、model.fit()でOK。
-generator関数は無限ループで画像を返すので、何回処理したら1エポックになるかをsteps_per_epochで指定する必要がある。これは「学習データ / バッチサイズ」 で計算できる。
Epoch 1/3
375/375 [==============================] - 15s 41ms/step - loss: 0.4001 - acc: 0.8711 - val_loss: 0.0708 - val_acc: 0.9777
Epoch 2/3
375/375 [==============================] - 15s 39ms/step - loss: 0.1110 - acc: 0.9657 - val_loss: 0.0484 - val_acc: 0.9843
Epoch 3/3
375/375 [==============================] - 15s 40ms/step - loss: 0.0789 - acc: 0.9751 - val_loss: 0.0461 - val_acc: 0.9863
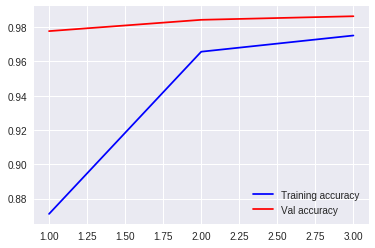
5.学習経過をグラフで表示
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Val accuracy')
plt.legend()
plt.show()
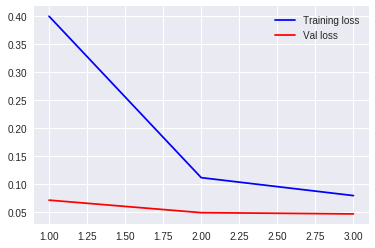
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss)+1 )
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Val loss')
plt.legend()
plt.show()
6.評価
モデルの最新のチェックポイントファイルを取得
def key_sort_by_num(x):
re_list = re.findall(r"[0-9]+", x)
re_list = list(map(int, re_list))
return re_list
def list_from_dir(dir, target_ext=None):
data_list = []
fnames = os.listdir(dir)
fnames = sorted(fnames, key=key_sort_by_num)
for fname in fnames:
if target_ext is None:
path = os.path.join(dir, fname)
data_list.append(path)
else:
_, ext = os.path.splitext(fname)
if ext.lower() in target_ext:
path = os.path.join(dir, fname)
data_list.append(path)
return data_list
def latest_weight(log_dir):
weight_paths = list_from_dir(log_dir, '.hdf5')
return weight_paths[-1]
- 評価時はModelCheckpointコールバックで出力したチェックポイントファイル(重み)をロードして行うので、チェックポイントファイルのパスを取得する関数(latest_weight)を作る。
- チェックポイントファイルはlog_dir内にあり、拡張子は、「.hdf5」なので、list_from_dir(log_dir, '.hdf5')で、log_dir内のファイルのフルパス一覧を生成する。
- list_from_dir()内で、os.listdir()によってファイル名一覧を取得しているが、os.listdir()はファイル名が番号順にならないので、sorted()を使ってファイル名をソートする。このとき、keyにkey_sort_by_num()を与えることで、ファイル名の数字順にソートするようにする。
- あとはlist_from_dir(log_dir, '.hdf5')からの戻り値の中で、一番最後のファイルを指定すれば、一番新しいチェックポイントファイルを取得できる。
- しかし、実際は学習最後のチェックポイントが一番良い重みとは限らないので、評価時はチェックポイントのファイル名になっているval_lossやval_accを見て一番良い重みを選ぶ方がいい。
テストデータで評価
model = model_sequential()
ckpt = latest_weight(log_dir)
model.load_weights(ckpt)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
score = model.evaluate(x_test, y_test)
print(list(zip(model.metrics_names, score))) # [('loss', 0.03808286426122068), ('acc', 0.9879)]
- model.load_weights(ckpt)でチェックポイントから重みをロードしている。
- model.evaluate(x_test, y_test)でテストデータを使った評価を実行している。結果は、リストで[loss, acc]の形式で返る。
入力画像と推論結果を表示
「学習データを表示」したときと同様の処理の途中にmodel.predict()を実行し、入力画像と推論結果を同時に表示してみる。
plt.figure(figsize=(10,10))
for i in range(10):
data = [(x,t) for x, t in zip(_x_test, _y_test) if t == i]
x, y = data[0]
pred = model.predict(preprocess(x, label=False))
ans = np.argmax(pred)
score = np.max(pred) * 100
plt.subplot(5,2, i+1)
plt.axis("off")
plt.title("ans={} score={}\n{}".format(ans, score,ans==y))
plt.imshow(x, cmap='gray')
plt.tight_layout()
plt.show()

7.CNNの出力マップを可視化
ckpt = latest_weight(log_dir)
model.load_weights(ckpt)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
- CNNの特徴マップを表示するためにまずは重みをロードしてコンパイルする。
def show_imgs(images, row, column, cm=None):
plt.figure(figsize=(12,12))
for i in range(row*column):
plot_num = i+1
plt.subplot(row, column , plot_num)
plt.axis("off")
if cm is None:
plt.imshow(images[:,:,i])
else:
plt.imshow(images[:,:,i], cmap=cm)
if plot_num == (row * column):
break
plt.tight_layout()
plt.show()
def get_layer(model, layer_name):
target_layer = None
for layer in model.layers:
if layer.name == layer_name:
target_layer = layer
return target_layer
def show_activation_map(model, x, layer_name, row=1, column=1):
target_layer = get_layer(model, layer_name)
activation_model = models.Model(inputs=model.input, outputs=target_layer.output)
# 入力画像準備
input = preprocess(x, label=False)
# マップを出力
activation = activation_model.predict(input)
for act in activation:
print("activation shape : ", act.shape)
# マップの一部のチャンネルを表示
show_imgs(activation[0], row=row, column=column, cm='inferno')
- 重みの可視化は、show_activation_map()で行う。
- get_layer()は指定した名前のlayerオブジェクトを返すだけの関数。
- get_layer()から返ってきた層のlayer.outputをmodels.Modelに設定してモデルを生成する(activation_model)。このモデルにpredict()関数で画像を入力すると、get_layer()から取得した層の出力画像を得ることができる。
- モデルが出力した画像をshow_imgs()関数で表示する。
target_layer_name = 'act1'
input_img = _x_test[0]
show_activation_map(model, input_img, target_layer_name, row=5, column=5)
- target_layer_nameは、モデルを定義したときに、各layerに付けた名前。
- 名前を指定したlayerの出力を表示できる。
1番目のReLUが出力した結果
入力画像は数字の「7」で、特徴マップを見ても入力画像とそんなに変化していないものが多い。

2番目のReLUが出力した結果

3番目のReLUが出力した結果
MaxPooling2Dを2回通っているので画像が粗くなっている。また、7の特定の部分を捉えた画像が多くなっている。