そもそも「Beyond the Twelve-Factor App」とは? 📚
2012年当時パブリッククラウド市場でパイオニアの地位を占めていた、Webアプリケーションをデプロイ・運用できるPaaS型プラットフォームとして「Heroku」というサービスがあります。そして、その「Heroku」の開発者によって、サービスを提供する中で得られたモダンなWebアプリ開発の方法論・知見をまとめた「The Twelve-Factor App」というドキュメントがあります。
この「The Twelve-Factor App」については、エンジニア界隈でも有名であり、現在も参考にされている方法論ですが、これを更に、pivotal社のアーキテクトによって「クラウドネイティブアプリ」向けに2016年にアップデートしたのものが「Beyond the Twelve-Factor App」になります。「The Twelve-Factor App」にあった12項目をアップデートし、新しく3項目を追加したものになります。
以下、「Beyond the Twelve-Factor App」の1章から15章まで、自分なりに噛み砕いて意訳してみたものを、もし何かのご参考になればと思い、晒します(もともと社内で毎週で一章ずつ書き下していたものです)。
勿論、誤りがあったり、自分の理解が及ばない点もあったりすると思われますが、そこはご容赦ください ![]()
- 後半(9~15章)はこちら
1章. One codebase, one application(1 コードベース、1 アプリケーション)
アプリケーション毎に管理されている1つのコードベースである必要があり、そのコードベースから複数の環境(開発/ステージング/本番)に分けてデプロイできる必要があることが述べられています。1つのコードベースに複数のチームが存在する場合は、「コンウェイの法則」を利用して、マイクロサービス化しコードベースを分割することの検討を奨めています。
ただ、ある特定のコードが複数のアプリケーションを跨って共有されることが許されないわけではなく、そのような共有されるコードは、1つの別のコードベースとして管理されるべきであり、それだけでマイクロサービス化する必要が必ずしもないと説明されています。
2章. API First (APIファースト)
「APIエコノミー」という言葉があるように、社外・社内を問わず、各サービスが提供する「API」を通して通信し合うことで、ユーザにより喜ばれる一連のサービスを提供することができるようになっています。このAPIエコノミーに加わるには、またAPI通信による連携・統合に失敗しないために、システム開発者は、開発プロセスにおいて「API(インターフェイス)」を第一級品の成果物として認識する必要がある、と述べられています。そして、「APIファースト」の考え方によって、各開発チームに、各内部の開発プロセスに干渉すること無く、お互いの「パブリックに向けた契約 = API」に対して開発することができるようになります。
「API」を別の言葉で表現すると、「外部の振る舞い」や「外部と約束しているインプットとアウトプット」と言うことができます。ただ、API開発の初心者にとって、この「APIファースト」の考え方やイメージを理解するのは多少時間がかかる気がしています。特に、Rest API(Restful API)の形式のAPIは、書き方の自由度があり過ぎて、Restful APIとして良しとされる書き方やベストプラクティスを無視して定義されているAPIが沢山生まれてしまいます。柔軟なAPI設計ができる分、Googleなどが提供する「Restful API」とされる書き方やベストプラクティスをしっかりと学ぶ必要があります。Rest API(JSON)以外にも、クライアント側に重きをおいたGraphQLや、より高速な通信が可能なgRPCなどの他のAPIの種類も普及しつつあります。それらのAPIにも、各種ベストプラクティスが蓄積されつつあるので、そちらにもキャッチアップしていく必要があります。
3章. Dependency Management (依存管理)
明示されていないライブラリやモジュールの依存は問題であり、それは頻繁な繰り返し可能なデプロイを妨げると解説されています。
JavaではMavenやGradle、RubyならBundler、Go言語ならGo Moduleというように、最近のプログラミング言語では、ライブラリへの依存を管理するツールが充実しています。これらのツールを活用することで、依存関係を解決できないことによるエラーを未然に防ぐことができます。
また、アプリケーションが依存するライブラリ等は、稼働させる環境に設定するのではなく、アプリ自身によって定義する、つまり、環境側に依存関係の前提を何も置かないことが重要となります。自身で依存関係を解決する=どこでも動くアプリケーションにすることで、高度な移植容易性を実現することができます。移植性においては、Docker等のコンテナ技術を利用することで、実行環境だけでなく、開発環境の構築も容易にすることができます。
4章. Design, build, release, and run (設計、ビルド、リリース、実行)
開発プロセスにおいて、設計(コーディグ)→ビルド→リリース→実行のステップの順番を辿りますが、これはウォーターフォールのように設計から実行にかけて密結合した一連のフローを意味しているわけではなく、4つの各々のステップの中でイテレーションを繰り返して容易に変更することが可能であり、各々のステップが独立しており、別々に発生させるようにすることが重要である、と説かれています。
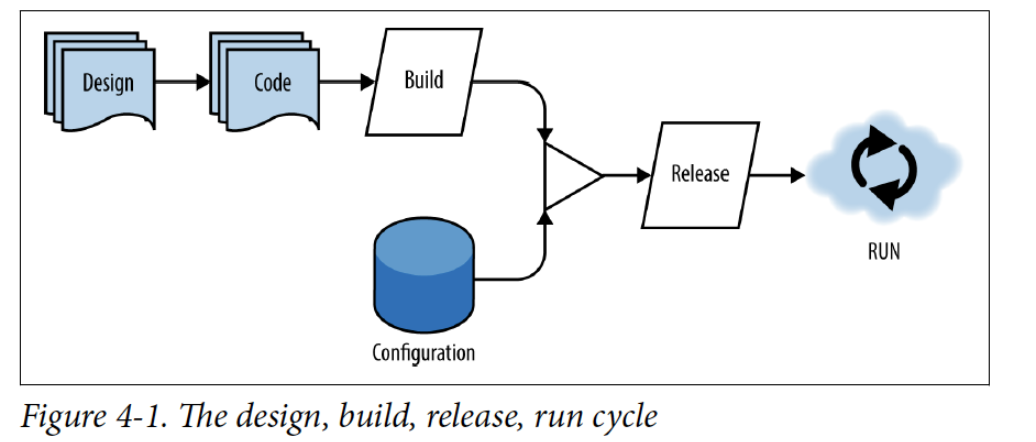
つまり、実際の開発プロセスの流れとしてはこのフローの順番どおりに行われる必要があるのですが、4つの各々のステップがお互いを気にすること無く、好きに変更を加えることができるように整える必要がある、ということだと理解しています。その手段の一つとして、成熟したCI/CDパイプラインを構築することが有効であると説明されています。
以下、4つの各ステップに関して見ていきたいと思います。
・「設計」
ウォーターフォール開発プロセスにおいては、このステップに、一行のコードを書く前に多大な時間を費やしていたが、リリースの早さが求められる現代のアプリ開発には向いていません。
しかしながら、それは設計が全く必要無いということを意味するのではなく、リリースできる小さい単位の機能を設計したり、開発者全員が何をすればいいのかを指し示す抽象度が高いレベルの設計を考慮する必要があります。ただし、設計は変化するものであり、毎回のイテレーションの中で少しずつ変化していくものであることも認識しておく必要があります。
また、このステップの時点において、どのライブラリを使うか、そしてどのようにそれらの依存関係を整理するかも考慮する必要があります。
・「ビルド」
このステップによって、設計してコーディングされたレポジトリは、バージョンニングされたバイナリの成果物(アーティファクト)に変換されます。この期間で、設計時に考慮したライブラリの依存関係が整理された成果物(いわゆる「ビルド」)へと出来上がっているはずです。
このビルドは、CI(継続的インテグレーション)によって生成されることが推奨されています。
そして、この1つのビルドによって、複数の環境(開発、ステージング、本番など)にリリースできるようにする必要があり、環境毎の固有の設定(図でいう「Configuration」)以外が原因で問題が発生した場合は、それは上述したように、4つのステップを正しく分離・独立できていない兆候である、と述べられています。
・「リリース」
ビルドに環境毎の固有の設定やアプリ固有の設定を施して、実行環境に移すことで、リリースとなります(個人的に、どちらかという「配布」という意味に近いと思います)。
実行環境はクラウド環境が望ましいとされ、そのリリース毎に不変なユニークなIDを付与(タグ付け)することが重要であると述べられています。そうすることで、トラブルシューティングやロールバックの際のリリース世代履歴の管理が容易になります。
・「実行」
リリースの実行はクラウドプロバイダーに任せるのが、クラウドネイティブアプリ開発においては、典型的であると述べられています。クラウドプロバイダーが提供するCD(継続的デプロイ)を構築してデプロイ(実行)することで、開発者を手動デプロイ時の緊張や注意力の拘束から開放することができます。
また、アプリが実行している間、クラウドの実行環境には、アプリが正常に動いていること=Healthyであることを監視したり、ログを集約させたりする一方で、動的スケーリングやフォールトトレランス(耐障害性)などの多くの管理作業を施すことにも、責任を持たせる必要があります。
5章. Configuration, Credentials, and Code (設定、認証情報、コード)
「設定、認証情報、そしてコードは、それぞれは混ぜると爆発する揮発性物質のように扱え」と述べられています。
設定をコードや認証情報から分離することで、環境固有の設定値に依存しないコードベースを構築することができます。
「設定」として参照する値として、以下のようなものが挙げられます。
・URLsやその他バックエンドサービスに関する情報
・データベースの特定・接続に必要な情報
・AWSやGoogle Maps APIなどのサードパーティサービスの認証情報
外部化すべき「設定」の基準は「それがアプリ自体の一部の内部情報を含んでいるかどうか」であり、全てデプロイ環境を通して変わらない情報・値であれば、それは「設定」と見なしません。
次に、「あなたのアプリケーションのコードはオープンソースのように扱え」と述べられています。
もし仮にあなたのチームのアプリケーションの全コードを外部に一般公開した場合、アプリが依拠するリソースやサービスに関する「秘密情報」を晒すことにならないか?それを想像することで、「コード」と「設定」・「認証情報」がどれだけ分離できているかを確認することができます。
「認証情報」を外部化する理由が自明ではあるものの、「設定」を外部化する理由はそれほど自明ではないと思われています。しかしながら、クラウドベンダーが提供する環境においては、CDパイプラインを通して自動的に環境毎に固有の設定を施してデプロイすることでそれが可能となっています。
本章の最後においても、「設定」の外部化は、現実に現場でなかなか実践されていないことが言及されています。例えば、Javaアプリケーションの現場だと、リリースする成果物と一緒に「設定」を含むプロパティファイルをバンドルしているかもしれません。
そこで、最後に、「設定」を外部化する実践的な方法として、以下2つ挙げられています。
1, 環境変数を利用する
2, 設定を提供するサーバを立てて使用する(k8sでいうConfigMap?)
上記のいずれにおいても、バージョン管理をサポートしているかを考慮する必要があり、そのサポートがあることで、安全にデータを変更することができます。
6章. Logs (ログ)
ログは、「時間に沿ってアプリケーションから流れてくるイベントストリーム」と認識すべきであると述べられています。そして、クラウドネイティブなアプリでは、そのログの出力の処理や保管を気にしない、ただ標準出力と標準エラーに吐き出すだけの作りにする必要がある、と説明されています。
従来の大きなエンタープライズアプリケーション開発においては、開発者は、ログ出力の形式や出力先まで厳格に管理し、その内容をアプリ内の設定ファイル等に定義する習慣がありました。
しかしながら、クラウドネイティブなアプリにおいては、どんなファイルシステムに出力され、どんな形式でどこにログを吐き出すべきなのか等を想定を置きません。ログの集約、処理、保管や分析は、ElasticSearchやSplunkなどのクラウドプロバイダーが提供するようなログ専用のツールを使い、それに任せることが推奨されています。
そうすることで、アプリケーションのコードがよりシンプルになり、ログの集約、処理、保管や分析に対して変更は発生したとしても、アプリへの修正は必要無く、アプリは柔軟な拡張性を手にすることができます。
確かに、決まったサーバ数やディスクのログ保管サイズの上で決まったインスタンス数で実行させる場合は、ログ関連の関心事を厳密に管理することに意味があるかもしれません。しかしながら、1つのインスタンスから100つまで動的に拡張したり、どこでどんなサーバのスペックのもとでインスタンスが実行されるかを想定しないクラウドネイティブなアプリにおいては、クラウドプロバイダー側にログの集約などを代行してもらうことが望ましいと考えられます。
7章. Disposability (廃棄性・使い捨て可能性)
クラウドネイティブなアプリケーションの処理は、「直ぐに使い捨てる」ことができます。つまり、素早く起動させたり、止めたりすることができることを意味します。もし素早く起動させたり、グレースフルに停止(いわゆるgraceful shutdown)したりすることができなければ、素早くスケールさせたり、デプロイしたり、立ち直らせたりすることができません。
大規模なウェブサーバ等のエンタープライズの世界での開発に慣れている方は、分単位で計測される非常に長い起動時間に慣れているかもしれません。高い起動時間は、レガシーorエンタープライズのアプリに限らず、インタプリタ言語で書かれた、またはそもそも書き方が悪いソフトウェアにおいても、同じことが起こり得ます。
アプリが安定した状態までに数分間かかることは、今日のソフトウェアの世界では、(アプリが起動するまでに)数十万のリクエストを拒否することを意味してしまいます。
そして、より重要なことは、アプリを展開するプラットフォーム(クラウド等)によっては、起動までがあまりに遅いと、アプリへのヘルスチェックが失敗し、アラートや警告を発してしまうことがあり得ます。極端に遅い場合だと、アプリがクラウド上でまったく稼働しないことさえ考えられます。
増加する負荷の中で、素早くインスタンス数を増やしてそれらを捌く必要がある場合でも、起動時の遅れがあると、負荷を処理する能力が十分にあったとしても、それを妨げてしまいます。一方で、素早くかつグレースフルに停止することができなければ、障害が発生しても直ぐに復活する能力を妨げたり、リソースの破棄に失敗しデータを破損するリスクを冒したりしてしまいます。
また、キャッシュにデータを取り込んだり、他のランタイムの依存性を解決したりすることで起動に長い時間がかかってしまうアプリは、多くあります。クラウドネイティブなアーキテクチャを真に受け入れるならば、そのような処理は、個別に実行されるようにすることが必要です。例えば、キャッシュするデータは、「バッキングサービス(=アプリが依存する別のサービス)」に外部化することで、アプリは、起動時の先行処理を実行することなく、素早く起動・停止させることができます。
8章. Backing Services (バッキング・サービス)
「バッキング・サービス」とは、アプリケーションがある機能を依存するあらゆるサービスのことを指します。データストア、メッセージングシステム、キャッシュシステムなど、様々なサービスを含みます。
いずれのサービスにおいても、アプリケーションがバッキング・サービスに接続することを宣言するコード上の処理は抽象化(プログラミング言語によるが、インターフェースの使用等)することが推奨されています。また、その接続のための情報(例えば、データベースの場合、ユーザ名、パスワードやURL等)は、コードから分離された外部化した設定(configuration)として保持することが必要です。
そうすることで、アプリケーションを再デプロイすること無く、あるバッキングサービスを自由にアタッチしたり、デタッチしたりすることができるようになります。
そのメリットを享受する具体例を挙げると、アプリケーションが依存するあるデータベースが何らかの理由で応答しなくなった場合、障害が連鎖的に発生し(=カスケード障害)、アプリケーションに危険が及ぶことが想定されます。その際に、そのデータベースからデタッチし、新しく立ち上げたデータベースにアタッチすることが簡単にできると、アプリの運用者は、旧データベースから来るはずの連鎖的な障害の影響をアプリが受けること無く運用することができます。
ちなみに、障害が起きたバッキングサービスとの通信をストップさせ、局所的な障害がシステム全体に波及させないようにする「サーキットブレーカー」という仕組み・技術もあります。
関連記事
- 後半(9~15章)はこちら
参考にした書籍・記事