そもそも「Beyond the Twelve-Factor App」とは? 📚
2012年当時パブリッククラウド市場でパイオニアの地位を占めていた、Webアプリケーションをデプロイ・運用できるPaaS型プラットフォームとして「Heroku」というサービスがあります。そして、その「Heroku」の開発者によって、サービスを提供する中で得られたモダンなWebアプリ開発の方法論・知見をまとめた「The Twelve-Factor App」というドキュメントがあります。
この「The Twelve-Factor App」については、エンジニア界隈でも有名であり、現在も参考にされている方法論ですが、これを更に、pivotal社のアーキテクトによって「クラウドネイティブアプリ」向けに2016年にアップデートしたのものが「Beyond the Twelve-Factor App」になります。「The Twelve-Factor App」にあった12項目をアップデートし、新しく3項目を追加したものになります。
以下、「Beyond the Twelve-Factor App」の1章から15章まで、自分なりに噛み砕いて意訳してみたものを、もし何かのご参考になればと思い、晒します(もともと社内で毎週で一章ずつ書き下していたものです)。
勿論、誤りがあったり、自分の理解が及ばない点もあったりすると思われますが、そこはご容赦ください ![]()
- 前半(1~8章)はこちら
9章. Environment Parity (環境の一致)
組織が進化するにつれて、開発環境、QA環境、そして本番環境が異なるものになる傾向になります。例えば、DBドライバ、セキュリティルール、ファイアウォールの設定です。そして、ある環境にはデプロイできるのに、他の環境にはそれができない事象が起き始めます。ついには、デプロイする自体を恐れ、ある環境で動いたプロダクトが別の環境では動くことに全く自信が持てなくなってしまいます。
この「自分の環境では動く」というシナリオには、クラウドネイティブのアンチパターンとなります。これは障害時のトラブルシューティングの時に聞く「QA環境では上手く動いた」や「本番環境では動いた」というシナリオにも、同様に当てはまります。
「Environment Parity (環境の一致)」を厳密に守る目的は、チームや組織全体が「アプリケーションがどの環境でも動く」という自信を持たせるためです。
環境間での差異が生じさせる最も共通する原因は大抵、時間(Time)、人間(People)、そしてリソース(Resource)です。
・時間(Time)- Check-in to Deployment
コードをチェックインして本番にデプロイするまでの時間が長いと、開発者は本番にリリースする変更がどんなものかを忘れ、そのコードがどんなものであったかも忘れてしまいます。
現代的なアプローチを採用するならば、チェックインから本番デプロイまでは数分・数時間に収めるべきです。適切なCDパイプラインでは、ある変更に対して、本番とは異なる環境でのテストが自動で走り、その後本番環境に自動でプッシュされる仕組みであるはずです。クラウドプラットフォームが提供するダウンタイムが無いデプロイを用いれば、この仕組み・パターンが標準化する可能は十分にあります。
・人間(People)- Human Error
開発者とデプロイする人は同じ人であるべきだ、と原書の「The Twelve-Factor App」でも示されていますが、パブリッククラウドにデプロイする場合はこれは大変理にかなっていますが、大企業内のプライベートクラウドにデプロイする場合は、この方法でも上手くいかない、と思われます。なぜなら、人が介在する限り、ニューマンエラーが必ず発生するからです。
さらに、筆者は、自分のワークステーションやサンドボックスの環境では無い限り、その他の全環境に対しては手動でデプロイするべきではない、と主張しています。1ボタンでデプロイできるか、またはあるイベントに反応して自動デプロイすることができないならば、ヒューマンエラーが発生すると指摘しています。
・リソース(Resource) - Compromises(妥協)
私たちはデスクワークする中で忙しくしていると、全員が何かしら妥協をします。この妥協が、少しの技術的負債だけではなく、致命的な失敗を招くことが可能性があります。
よくこの妥協をしてしまうのが、バッキングサービスを使う、立てる時です。例えば、本番ではOracleDBやPostgres Serverに繋ぎますが、開発ではそれをセットアップするのは骨が折れるため、妥協してインメモリーのDBを使いがちです。
しかしながら、こういった妥協の積み重ねが、本番環境と開発環境のギャップを大きくしています。それがアプリが動く予測をしづらくし、信頼性を失い、継続的なデプロイができなくなり、全てやることに脆さを感じるようになってしまいます。最悪のケースが、手遅れになるまで、開発と本番のギャップの広がりに気づかないことです。
しかしながら、最近では、Dockerの技術やPaaSを使うことで、手間を妥協すること無く、複数の環境間で共通するリソースのインスタンスを立ち上げることが容易になってきており、開発者は妥協できる言い訳を失ってきています。
そのため、たとえその時はあまり重要ではない差異に思えても、環境間の差異を許すことで問題を回避しようとする衝動には抵抗する必要があります。
・Every Commit Is a Candidate for Deployment
クラウドファーストなやり方でアプリを構築する場合、変更をコミットする度にその変更は短い期間の後に本番に適用されるべきです。その短い期間では、全てのテストが実行され、全て統合テストでその変更が検証され、本番前の環境にデプロイされます。
開発、テスト、そして本番で環境で異なるならば、変更したコードが本番環境でどのように振る舞うのか正確に予測することができません。本番環境に向かうコードへの信頼感や自信は、継続的なデリバリー(CD)や高速な開発には不可欠であり、それはアプリとその開発チームがクラウド上の環境で成功を収めることに繋がります。
10章. Administrative Processes (管理プロセス)
TL;DR「アプリ内に管理プロセスを持つな」
原書の「The Twelve-Factor App」では「管理タスクは単発のプロセスとして実行しろ」と示されていますが、これは紛らわしい言い回しであると主張されています。
原書での推奨の裏にある問題点は、対話型のプログラミングシェル(REPL)をサポート・推奨するRubyのようなインタプリタ型言語への偏った意見で書かれていることです。
また、管理プロセスを使うことがある特定の状況下においては実際に良くないアイディアであることがあり、管理プロセスはあなたが欲しいものかどうか、他の設計やアーキテクチャであなたのニーズをより満たすことはできないかを常に自問する必要がある、と主張されています。他の方法に見直すべき管理プロセスの例として以下が挙げられます。
・データ移行
・対話型プログラミング・コンソール(REPL)での処理
・夜間バッチや毎時取り込みのような時限のスプリントの実行
・一度だけ特別な処理をする単発ジョブの実行
まず、Cronなどのアプリ内で管理されるタイマーの問題について考えてみると、1つの案として、タイマーをアプリ内に内蔵化し、N時間毎にそれを起動させ、バッチ処理を実行することができます。これは表面的には良いとは思われますが、あるゾーンには20つのインスタンス、他のゾーンに15のインスタンスがあるアプリを想像してみてください。その場合、全てタイマーで同じバッチ処理が実行されると、その時点でカオスを引き起こし、破損・重複したデータは、それから引き起こされる恐ろしい事態の一つに過ぎないことだと分かるでしょう。
次に、対話型シェルにおいても、たとえシェルを開けたとしても、ある一つのインスタンスの一時的なメモリと対話していることに過ぎません。つまり、もしアプリがステートレスなプロセスとして適切に立ち上げられているとしたら、プロセス内の閲覧のためにREALとして公開する価値はほとんど無いのではないか、と主張されています。
さらに、時限またはバッチの管理プロセスをトリガーする仕組みについて考えると、たいていの場合、Cron等の外部のタイマーによってシェルスクリプトが実行される仕組みになっています。
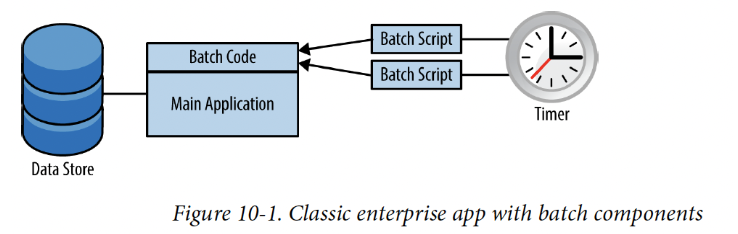
しかしながら、クラウド上では、シェル上のコマンドを実行することは期待できないので、アプリ上でアドホックな処理をトリガーする他の方法を考える必要があります。
そこで、アプリがクラウドネイティブな場合に特に有効な方法として、アドホックな処理を実行するために使うことができるRESTfulなエンドポイントをアプリで公開するという手があります。
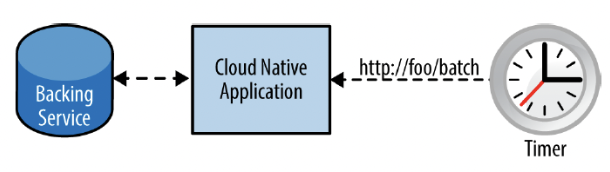
他の方法として、バッチ関連のコードをアプリから抽出し、別のマイクロサービスとして構築する手もあります。これは、時限の機能を任意に呼び出すことができますが、そのトリガーをアプリの外へ移動させることになります。
さらに、この方法は、動的にスケールするインスタンスの中で内部タイマーから最大1回実行する処理の問題も解決することになります。バッチの操作は、アプリの数あるインスタンスのうちの1つによって一度だけ実行され、引き続きその処理を完遂させるために他のバッキングサービスとやりとりするかもしれません。
また、それは、権限のある人しか操作できないように、バッチ操作のエンドポイントを安全にすることが簡単になります。
さらに便利なのは、そのバッチ操作が弾力的にスケールできるので、他のクラウドの利点を最大限活用できることです。
この方法においても、バッチやアドホックな機能をアプリとして公開する必要が全く無いアーキテクチャの選択肢もいくつかあります。
それでもまだ管理プロセスを使う必要があると思うときは、クラウドプロバイダーが提供する機能に沿った形にしたほうがいいです。言い換えると、あなたの好きな言語でジョブを実行する新しいプロセスを生む必要はありません。クラウドネイティブな方法で単発プロセスを実行するように設計された他の方法を採るべきです。この場合、例えばAWS Lambdasを使うと、任意に機能を呼び出すことができ、前述の例で示したマイクロサービスような専用のサーバを稼働させる必要が無くなります。
以上、最後に、制約が全く無いアプリ開発の場合にせよ、既存との互換性が求められるアプリ変更の場合にせよ、ただあなたのアプリに管理プロセスが本当に必要なのか、アーキテクチャ上の少し変更を加えるだけでそれを避けることができのか、を自問することが重要となります。
11章. Port Binding (ポートの割り当て)
TL;DR「アプリとホストするサーバの関係は1対1であるべき。各環境に固有のポートを割り当てよ」
既に企業内で稼働しているウェブアプリは、何らかのサーバコンテナ内で実行されていることが多いと思います。クラウドではない環境では、アプリはそのようなコンテナにデプロイされており、そのコンテナがポートを複数のアプリに割り当てる役割を担っています。
自身でウェブサーバを管理している企業においては、一つの同じコンテナで複数のアプリをホストし、ポート番号やURL階層によってアプリを分け、DNSを使ってサーバに関するユーザーフレンドリーなファサード(簡潔なインタフェース)を提供することが、極めて一般的なパターンです。
ここで、PaaSを採用すれば、開発者も運用者も、もう上記のようなマイクロマネジメントを行う必要は無くなります。
なぜなら、クラウドプロバイダーは、ルーティング、スケーリング、高可用性やフォールト・トレランス(耐障害性)なども管理しているため、今回のポートの割り当てについても管理してくれるでしょう。これらの仕事は、ホスト名とポートのルーティング、外部に公開するポート番号とコンテナ内部のポート番号のマッピングなどを含む、ネットワークの特定の側面を管理しているものだからです。
しかしながら、クラウドネイティブなアプリにおいては、既存のエンタープライズのアプリとは異なり、外部のサーバやコンテナに対してアプリが注入されることを想定していません。アプリ自身がコンテナ化されており、自己完結しています。
そのため、既存のエンプラのアプリにおいては、「アプリとアプリを動かすサーバの関係は常に1対1の関係でなければならない」という少し緩やかなガイドラインで問題無いと思われます。
言い換えると、クラウドプロバイダーが、ウェブアプリのコンテナを提供することはあっても、同じコンテナ内で複数のアプリをホストすることをサポートする可能性は極めて低いでしょう。なぜなら、その場合は、耐久性、拡張性そしてレジリエンスを実現することがほぼ不可能になるからです。
最新のアプリにおいてポートの割り当てが開発者に与える影響は、かなり単純なものです。例えば、あなたのアプリは、開発者の(ローカル等の)ワークステーション上では「http://localhost:12001」で実行され、QA(ステージング)環境では「http://192.168.1.10:2000」で実行され、本番環境では「http://app.company.com」で実行される、ようなことです。
外部提供されるポートの割り当てを十分に考慮して開発されたアプリでは、コードを変更すること無く、各環境に固有のポートの割り当てに対応しています。
最後に、外部提供されたポートの割り当てを可能にして開発されたアプリは、他のアプリにとってはバッキング・サービスとして機能できます。このような柔軟性は、クラウド上で実行できることによる他のメリットと相まって、非常に強力です。
12章. Stateless Processes(状態を持たないプロセス)
TL;DR「状態はアプリ内ではなく、バッキングサービスで持とう」
アプリケーションにおいても、副次的な管理プロセスにおいてはも、単一かつ「状態を持たない」プロセスであるべきです。
しかしながら、「状態を持たない=ステートレス」の概念について、混乱を避けるために、実際的な定義が必要です。ここでいう「ステートレス」とは、リクエストを処理する前にメモリの内容を前提にすることは無いし、その後も前提にすることは無い、ことを指します。リクエストやトランザクションを処理する最中は、過度的な状態を持ち得ますが、その状態のデータはクライアントにレスポンスを返した時点で無くなります。
簡単に言うと、長く保持する状態は、アプリの外部にあり、バッキングサービスによって提供される必要があります。つまり、この概念は「状態は存在しない」ということではなく、「状態はアプリ内では保持しない」ということを指します。
共通のリソースを共有することでプロセス間で通信することがよくありますが、クラウドに移行することを考慮しなくても、共有無しのパターン(シャア・ナッシング・パターン)を採用することによって、多くのメリットを得られます。
まず第一に、プロセス間で共有されるものは、その全ての関わるプロセスを脆くしてしまいます。その他、高可用性が求められるシーンでは、クラスター・リーダーの選出、プライマリーかバックアップかの判断など様々な手法で、プロセス間でデータを共有しようと考えます。
しかしながら、クラウド上で動かす場合は、これらのオプションは避ける必要があります。クラウド上でのプロセスは何の警告も無しに消失することがあり得ます。しかしこれは良いことです。プロセスが立ち上がったり停止したり、水平または垂直にスケールしたり、使い捨てが簡単だったりできます。これはつまり、プロセス間で共有するものもあったら、それも一緒に消失してしまい、連鎖的な障害をもたらす可能性が出てきてしまいます。
これは言うまでもないですが、ファイルシステムは、バッキングサービスではありません。つまり、ファイルをアプリがデータを共有する手段だと考えることはできません。クラウド上のディスクは刹那的であり、場合によっては読み取り専用であることもあります。
もし、ウェブ・ファーム(複数のサーバの集合)を形作るプロセス・グループのためのセッション状態のように、プロセス間でデータを共有する必要があるなら、そのセッション状態は外部化され、バッキングサービスを通して利用できるようにすべきでしょう。
長く起動し続けるコンテナベースのWebアプリ間においては特に、プロセスが起動中に頻繁に利用されるデータを(アプリ内に)キャッシュすることが、一般的なパターンです。しかしながら、既に言及した通り、プロセスは直ぐに起動したり停止したりできる必要があるため、インメモリ内にキャッシュを補充することに長い時間がかかってしまっては、左記の原則に反することになります。
さらに良くないのは、アプリが常に利用することができるようにするインメモリのキャッシュは、アプリを肥大化させる可能性があり、本来弾力的にスケールできるはずであるべきインスタンスが、必要以上にRAMを消費するようになってしまいます。
世の中には既にGemfireやRedisのようにサードパーティ製のキャッシングの製品がいくつか存在しており、それらの全ては、あなたのアプリのためにキャッシュするバッキングサービスとして役割を果たすように設計されています。それらは、セッション状態だけではなく、あなたのプロセスが起動中に必要なデータをキャッシュするためにも使うことができ、プロセス間での密結合なデータ共有を避けることができます。
13章. Concurrency(同時並行性)
TL;DR「垂直スケールではなく、水平スケールにさせよう」
CPUやRAM、他の(物理的もしく仮想的な)リソースを一つのモノリシックなアプリに足すことは、「垂直スケール」(「スケールアップ」)と呼ばれ、このような行動は今の最新のアプリ開発においては好まれない、と説明されています。
より最近の方法では、クラウドベンダーが提供するような柔軟なスケーラビリティ=「スケールアウト」「水平スケール」が良しとされます。複数のプロセスを作成し、その中でアプリの負荷を分散させるようにします。
ほとんどのクラウドベンダーはこのような機能を完成させており、そこでは、アプリへの負荷や利用可能な残りのランタイム等の遠隔測定情報に基づいて、アプリのインスタンス数を動的に拡張(=スケール)させるルールを設定することができます。
いつでも破棄できる、状態を内部に持たない、他のプロセスの共有すべきものを持たない複数のプロセスを構築することで、水平スケール、複数の同時並行のインスタンスを起動させることを最大限活用することができます。
14章. Telemetry(遠隔測定法)
TL;DR「クラウドアプリでの監視は難しく、見落とされがち。スケーラビリティに考慮した監視を設計・実装しよう。」
ローカルでアプリを動かす場合と異なり、クラウド上でアプリを動かす場合は、
アプリを監視する場合、以下のようなデータを監視することになります。
・アプリパフォーマンス監視(APM)
APMは、アプリのパフォーマンスを監視するために、クラウド外のツールによって使用されるストリーム・イベントによって構成されるデータです。パフォーマンスの定義と基準はアプリ毎に異なるので、アプリ開発・監視者がその定義と基準を定めて監視する責任を持つことになります。APMのダッシュボードに提供されるデータはたいてい、かなり一般的なものであるため、複数の事業を跨る複数のアプリから取得されます。
・特定ドメインのテレメトリー
特定ドメインのテレメトリーに関しても、アプリ開発・監視者次第です。このデータは、独自の分析やレポートに使用できる、ビジネス上意味のあるストリーム・イベントのデータを指します。この種のデータは、たびたび「ビックデータ」に提供され、データ整理・保管、分析や予測のために使用されます。
APMと特定ドメインのテレメトリーの違いは、直ぐには分からないかもしれませんが、APMはアプリが処理する1秒当たりのHTTPリクエスト数の平均であり、一方で、特定ドメインのテレメトリーは直近20分間でiPadで販売されたウィジェットの数、というように考えてみてください。
・ヘルス状態とシステムログ
ヘルス状態とシステムログは、クラウドベンダーによって提供されるべきデータです。これらは、ストリーム・イベントによって構成されており、アプリの起動、停止、スケーリング、Webリクエストの追跡(トレース)や定期的なヘルスチェックの結果などが含まれます。
クラウドは多くのことを簡単にしますが、監視とテレメトリーに関してはまだ難しく、従来のエンタープライズ・アプリの監視よりも恐らく難しいです。定期的なヘルスチェック、リクエスト監査、ビジネスレベルのイベント、追跡データ、パフォーマンス測定などのストリーム・データをじっと目線を下に追っていると、信じられない量のデータを見ることになります。
監視の戦略を計画する際は、収集するデータの量、収集するスピード、そのうち保管するデータの量などを考慮する必要があります。アプリが1インスタンスから100インスタンスまで動的にスケールした場合、ログのトラフィックが100倍になることもあり得ます。
クラウドアプリの監査・監視は見落とされがちですが、ことによると、本番でのデプロイにおいて適切に計画し実行されるべき最も重要な事項に含まれるでしょう。
15章. Authentication/Authorization(認証・認可)
TL;DR「セキュリティは開発初日に検討すべきであり、後回しにすべきではない。」
オリジナルの「Twelve-Factor App」では、セキュリティや認証・認可について議論されていません。しかしながら、セキュリティは、あらゆるアプリケーションとクラウド環境にとって不可欠な要素です。セキュリティは決して後回しにすべきではありません。
アプリの機能要件を満たすことに注力するあまり、そのアプリが企業向けか、モバイル機器向けか、クラウド向けかに関係なく、アプリを提供する上で最も重要な側面の1つ=セキュリティを軽視してしまうことがよくあります。
クラウド・ネイティブ・アプリケーションは、安全なアプリであるべきです。
コンパイル済みか裸のコードかにかかわらず、コードは多くのデータセンターに転送され、複数のコンテナで実行され、無数のクライアント(正規のものもあれば悪意のあるものもある)からアクセスされます。
アプリにセキュリティを導入する理由が、どのユーザーがどのデータを変更したか監査証跡を残すためだけだとしても、それだけでもアプリケーションのエンドポイントを保護するために必要な比較的小さな時間と労力を正当化するのに十分なメリットを享受できます。
理想的な世界では、すべてのクラウド・ネイティブ・アプリが、RBAC(ロールベースアクセスコントロール)によってすべてのエンドポイントを保護することになります。アプリのリソースに対するすべてのリクエストは、誰がリクエストしているのか、そしてそのコンシューマーがどのロールに属しているのかを知る必要があります。これらのロールは、呼び出したクライアントに対して、彼らのリクエストをアプリが処理するのに十分な権限を持っているかどうかを決定します。
OAuth2、OpenID Connect、様々なSSOサーバーや標準、そして言語固有の認証・認可ライブラリが無限にあるため、セキュリティは、アプリ開発に初日から組み込まれるべきものであり、アプリが本番稼働された後に追加プロジェクトとして施されるべきものではありません。
関連記事
- 前半(1~8章)はこちら
参考にした書籍・記事