本記事では語呂合わせの自動生成ツール、ゴロツクを紹介します。以下のリンクから試せます。
困りごと
私が所属する大学の研究室は、鍵が4桁の暗証番号式になっています。たった4桁ですが、研究室内に人がいる時はドアが開放されているので暗証番号を入力する必要はなく、利用機会が少ないことから、なかなか覚えられません。さらに悪いことに、研究室内には高価な機器がたくさん置いてあり、セキュリティ目的で半年ごとに暗証番号が変わります。暗証番号を覚える頃には暗証番号が変わるのです。
大学全体として4桁の暗証番号で入る部屋は多くあります。例えば研究室のゼミで使っている会議室もそうです。半年に一回しか回ってこない準備当番の際は、半年前に入力した暗証番号を思い出さなければいけません。学生証に内蔵の IC チップで入れる部屋は年々増えていますが、すべてが置き換わるにはまだ時間がかかります。
暗証番号を覚えなくても、メモしておいてそれを見返せばいいと思われるかもしれません。しかし、暗証番号を覚えていないのは日常的に暗証番号を入力していないからです。そういう人が暗証番号を必要とするとき、それは得てして非常事態です。暗証番号を気合いで思い出そうとしたりメモをひっぱりだそうとしたりする数十秒は永遠のように感じられ、焦る気持ちはさらなる悲劇を招きます(遠い目)。
解決策
たかが4桁、どうにか簡単に暗記できないかと考え、辿り着いたのが語呂合わせです。年号を覚えるために使っていた人も多いでしょう。不規則な数字の並びを意味のある単語の並びに対応付けることで記憶の定着を図る、あのテクニックです。
語呂合わせの問題点は、それが人間のひらめきの産物であることにあります。覚えやすい語呂合わせを捻り出すのは簡単なことではありません。しかし、こじつけたような語呂合わせでは、不規則な数字の並びと大差ありません。
この問題を解決するために作ったのがゴロツクです。筆者は大学院でコンピュータに言葉を理解させる技術、自然言語処理の研究をしています。ゴロツクの大きなポイントは、筆者の専門を活かし、自然言語処理の要素技術である言語モデルを利用して、単語の並びの自然さを考慮した語呂合わせを生成する点にあります。以降、ゴロツクの仕組み・実装について詳しく説明します。
仕組み
基本的には、数字に対して可能な語呂合わせの候補を列挙し、そこから自然なものを選び取ることで語呂合わせを生成します。

語呂合わせの候補を列挙する処理には、少量のシードデータから自動生成した語呂合わせ辞書を使っています。自然な語呂合わせを選び取る処理には、単語の並びの自然さを計算する自然言語処理の技術、言語モデルを使っています。すべての語呂合わせ候補を列挙・比較するのは計算コストが大きいため、ビームサーチという方法で探索範囲を狭めています。
語呂合わせ辞書
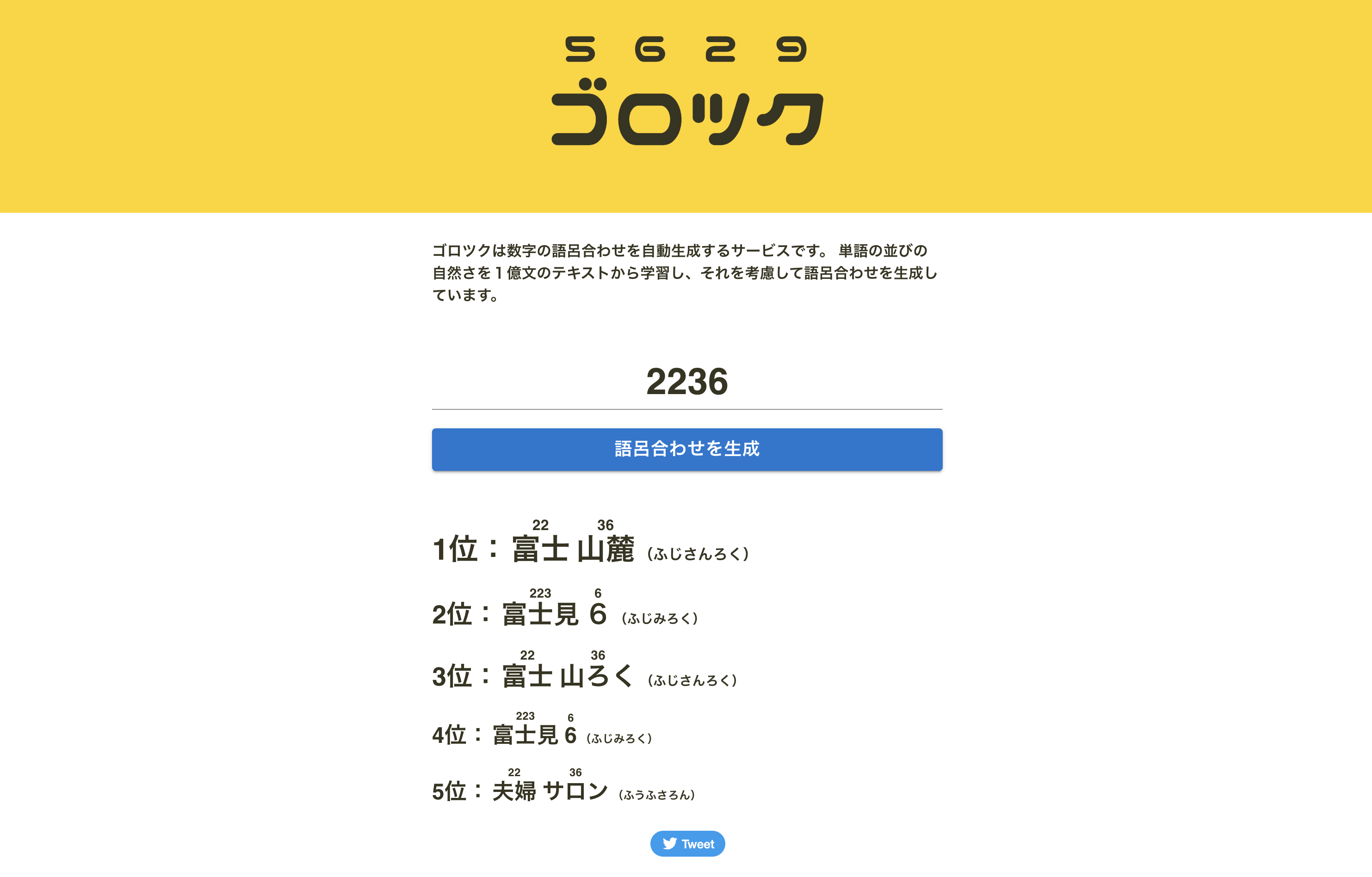
語呂合わせ辞書は数字をひくと、その語呂合わせになる単語が出てくる辞書です。たとえば、ゴロツクの語呂合わせ辞書で「22」をひくと「富士(ふじ)」「不治(ふじ)」「人事(じんじ)」など計255単語が出てきます。これを使って数字から語呂合わせの候補を列挙しています。
語呂合わせ辞書は、数字-読み辞書と読み-単語辞書を結合することで作れます。読み-単語辞書はふつうの国語辞典のようなもので、既存の辞書データから簡単に作れます。問題は数字-読み辞書です。これはふつうには手に入らないので、自作する必要があります。
ゴロツクでは数字-読み辞書を少量のシードデータから自動構築しています。まず、シードデータとして、1桁の数字と10など特殊な読みが存在する数字に関してのみ、手作業で数字-読み辞書を整備します。たとえば「2」には「に」「ふ」じ」などの読みを付与しておきます。それ以外の数字の読みは自動的に付与します。たとえば「22」は「2」+「2」に分解できます。シードデータから「2」が「に」「ふ」じ」と読めることは分かるので、「22」に「にに」「にふ」...「じじ」の読みを付与します。加えて、読みを接続するとき、間に「ー」「っ」「ん」を挟んでも語呂合わせには影響しないので、「にーに」「にっに」...「じんじ」の読みも合わせて付与します。
ゴロツクの語呂合わせ辞書は5桁の数字まで対応しています。大きい桁数になると人が考えて捻り出すのは難しい例が出てきます。たとえば、ゴロツクの語呂合わせ辞書で「22492」をひくと「不織布(ふしょくふ)」が出てきます。「22492」をぐっと睨んでこの語呂合わせをひらめく人は中々いないでしょう。少量のシードデータと単純な規則からこんな例が産まれたことを思うと感動を覚えます。
言語モデル
言語モデルは単語の並びの自然さを計算する技術です。言語モデルには色々な応用があります。たとえばパソコンやスマホに搭載されている音声認識です。試しに「きょうのてんき」と話しかけてみてください。「今日の天気」と認識されるはずです。これは当たり前のようですが「きょうのてんき」という音だけを考えれば「今日の転機」と認識されてもおかしくないことに気が付きます。「今日の天気」と認識できるのは、言語モデルを使って単語の並びの自然さ、つまり「今日/の/天気」の方が「今日/の/転機」より単語の並びとして自然なことを考慮しているからです。
ゴロツクでは語呂合わせの生成に言語モデルを利用します。例として「2236」の語呂合わせを考えます。語呂合わせの候補として「富士(22)山麓(36)」、「夫婦(22)サロン(36)」、「譜(2)時差(23)ロック(6)」の3つがあるとします。言語モデルを使えば「富士/山麓」、「夫婦/サロン」、「譜/時差/ロック」の順で単語の並びが自然だとわかり、語呂合わせとして一番上手いのは「富士山麓」だと判断できます。
ゴロツクでは日本語ウェブテキスト1億文から学習した言語モデル1を利用しています。
ビームサーチ
語呂合わせ辞書を使って語呂合わせ候補を列挙すると、あっという間に候補数が大変な数に膨れ上がります。そのすべてに対して言語モデルでスコアを計算して並び替えて...としていると現実的な時間で処理が終わりません。
そこでビームサーチという手法を使って計算をサボります。上述の概要図のように、ビームサーチでは、先頭から順に数字を単語に変換していきます。その際、語呂合わせの途中経過を言語モデルでランク付けし、見込みのあるものだけ続きの数字を単語に変換していきます。
実装
ゴロツクではクライアントサイドで語呂合わせの生成を行います。語呂合わせで覚えたい数字の中には暗証番号などセキュリティに関わるものも含まれ、そうしたケースでは、どんな形であれ第三者が管理しているサーバに数字を渡したくないだろうと考えたからです。したがってゴロツクは、クライアントが語呂合わせ辞書・言語モデルを fetch し、ビームサーチで語呂合わせを探索する、という構成になっています。
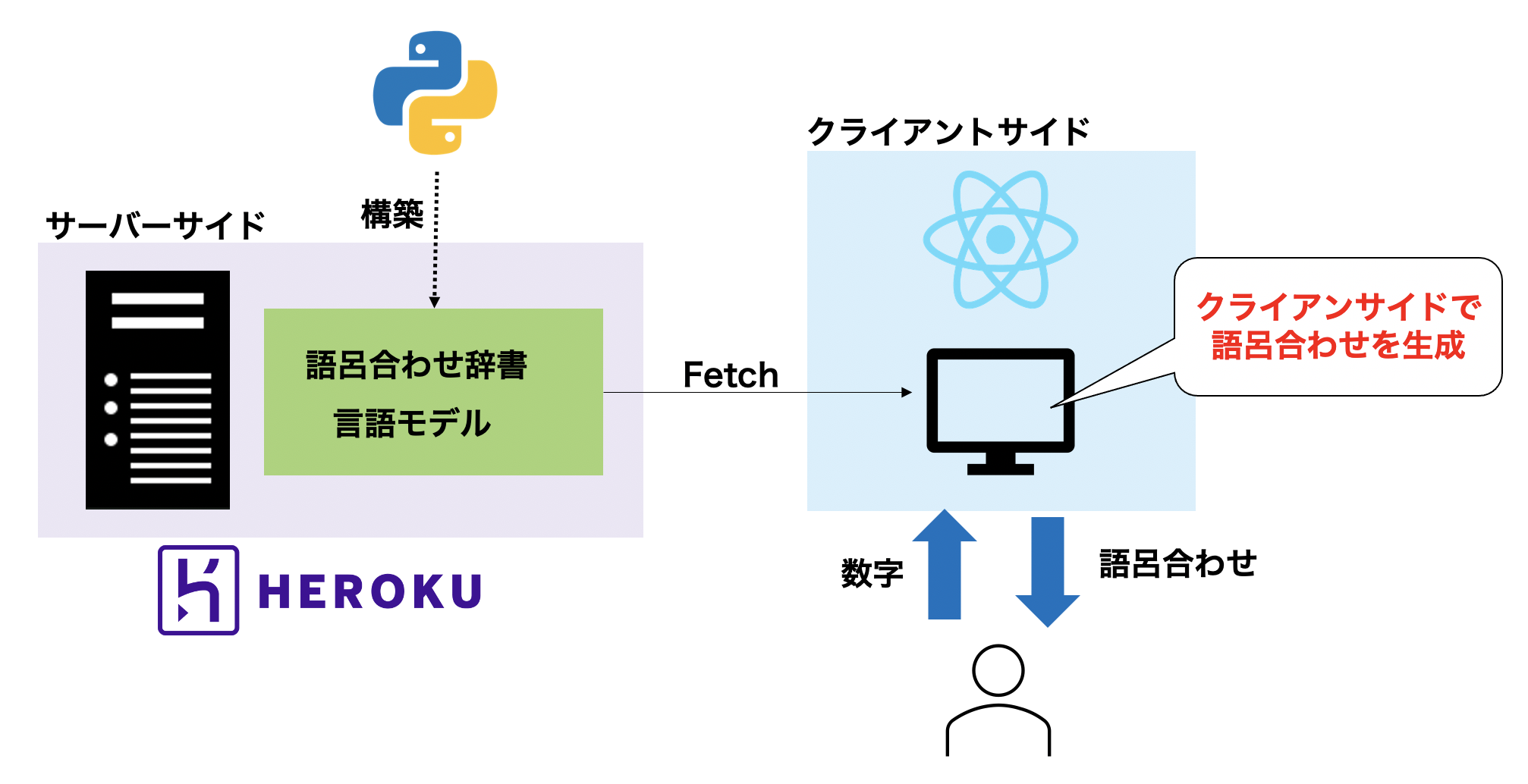
語呂合わせ辞書・言語モデルを構築する処理は Python で実装しました。技術選定の主な理由はライブラリの整備状況です。特に言語モデルの構築は、自然言語処理系のライブラリが充実していると実装が楽で、その意味でここは Python 一択でした。語呂合わせ辞書・言語モデルは JSON ファイルとして吐き出してデプロイしています。
クライアントサイドは React で実装しました。ウェブ開発は素人ですが、昨今のデファクトスタンダードだと聞いています。入力の validation と生成した語呂合わせのレンダリングが簡単に実装できて満足しています。
アプリケーションのデプロイ先としては、手軽さと運用コストを考慮して Heroku を選びました。今のところ特に困ってはいませんが、今後の開発の経過によっては AWS 等に移行するかもしれません。(追記: 2022/11/26) Heroku有料化のため、Vercelに移行しました。
具体例
ゴロツクで作られた語呂合わせの具体例をいくつか紹介します。
成功例
以下の2つは言語モデルによって単語の並びの自然さをうまく考慮できた例です。
| 数字 | 語呂合わせ |
|---|---|
| 4122 | 良い夫婦 |
| 4559 | 人工呼吸 |
言語モデルによって「良い/夫婦」「人工/呼吸」という単語の並びが自然であることがわかり、結果、自然な語呂合わせを作ることに成功しています。
以下の2つは、自動構築した語呂合わせ辞書のカバレッジが活きた例です。
| 数字 | 語呂合わせ |
|---|---|
| 2016 | フレイム |
| 4881 | 上海 |
4桁の数字すべてに人手で語呂合わせを付与するのは非現実的ですし、仮にそれを行ったとしても、「フレイム(2016)」や「上海(4881)」を思いつけるかと言われると、かなり厳しいと思います。その意味で、これは語呂合わせ辞書の自動構築が活きた例と言えます。
失敗例
以下の2つは語呂合わせがうまく生成できなかった例です。
| 数字 | 語呂合わせ |
|---|---|
| 7415 | な爺事(なじいごん) |
| 20211218 | 辞令に一つひとつひーばぁ |
「7415」は、語呂合わせ辞書に登録されている単語では単語の並びとして自然な語呂合わせが作れなかった例です。「74」には「梨」、「15」には「いちご」が登録されているので、「梨いちご」なんて語呂が作れても良い気がしますが、日本語テキストには「梨/いちご」という単語列はほとんど現れず、言語モデルにもとづく方法では生成できませんでした。単語の並びとしての自然さが同じくらいのときは、単語間の意味的な類似度を頼りにタイブレークする等の方法で改善できるかもしれません。
「20211218」のように桁数が大きい数字は、ゴロツクが苦手とするところです。どうしても単語数が多くなり、いまのゴロツクが採用している言語モデルでは単語の並びの自然さをうまく評価することができないからです(参考:脚注 1)。
今後の課題
今後の課題として、どの数字にも当てはまらない文字の活用があります。例えば、「で」や「の」と読める数字はありませんが、どちらも格助詞として自然な日本語を作り出すのに役立ちます。これらを使うと、次のような語呂合わせを作ることができるようになります。
| 数字 | 語呂合わせ |
|---|---|
| 269269 | 風呂(で)くつろぐ |
| 2265 | 虹(の)向こう |
しかし、数字に関係しない文字を使いすぎると、単語列としての自然さと引き換えに語呂合わせとしての簡潔さを失います。そこは避けたいところであり、小規模な実験をしつつ、良い落とし所を見つける必要がありそうです。
また、今のシステムは大きな桁数の数字の扱いが苦手で改善の余地があります。しかし、昨今暗記したい数字といえば、暗証番号、年号、誕生日くらいなもので、大体のケースで4桁です。その意味で、実際的な用途ではそれほど問題にならないと考えています。
既存の語呂合わせ生成器
「語呂合わせ 自動生成」で検索すると語呂合わせジェネレータというサービスが一番上に出てきます。
実装について記載はありませんが、いくつかの数字に一つの単語を割り当てておき、入力の数字を単語が付与されている数字だけで構成される数列になるべく少ない分割回数で分解し、分割後の各数字に対応する単語を繋ぎ合わせる、という処理をしているようです。この方法の問題は、単語間の関連性を考慮できず、こじつけたような語呂になってしまう点にあります。例えば、語呂合わせジェネレータで「2236」と入力すると「人糞(22)魅力(36)」という語呂が生成されます。「人糞」と「魅力」の間に関連性はなく、上手い語呂合わせとは言えません。
ゴロツクは言語モデルを使って単語の並びの自然さを考慮して上手い語呂合わせを探索しています。一方、今後の課題で述べたように、ゴロツクは大きな桁数の数字を苦手としています。そうしたケースでは、分割数最小の基準で語呂合わせを作った方がマシなことも多く、語呂合わせジェネレータに軍配が上がります。
大きな数字(電話番号やカード番号など)を覚えたいものの、ゴロツクは駄目だし語呂ジェネレータも上手くない、そうした時のワークアラウンドは、ユーザ自身で数字を色々と分割し、それぞれゴロツクに入力してみることです。ユーザ自身に数字を分割してもらわなくて済むようにするには、言語モデル・探索アルゴリズムの改良が不可欠です。
まとめ
本記事では語呂合わせの自動生成ツール、ゴロツクを紹介しました。
語呂合わせは身の回りの「数字を覚える」タスクを楽しく解決してくれます。冒頭で、私たちの研究室は暗証番号式で、暗証番号が半年に一回変わることを説明しました。最近は新しい暗証番号の発表の際、ゴロツクで作った語呂合わせも一緒に発表されています。語呂合わせを発表すると「もっと上手い語呂合わせを作れる気がする」と考え出す人もいて、人間 vs 人工知能の様相を呈しています(?)。暗証番号の発表は面倒なイベントからちょっとしたレクリエーションの時間になりました。
生体認証の普及は目覚ましいですが、依然として暗証番号を使う場面は少なくありません。中学生・高校生諸君は、ある年号を覚えているか否かが受験の合否を左右する日が来るかもしれません。SNS が誕生日を通知してくれるこの時代、誕生日を暗記していると案外喜ばれるものです。
数字を覚えたくなったとき、あなたがゴロツクのことを思い出し、そしてゴロツクが素敵な語呂合わせを生成してくれることを願って、筆を置かせていただきます。
—
ゴロツクのソースコードは Github で公開しています。
謝辞
本記事は、ゴロツクの共同開発者でありかつ研究室の席が隣の@kiyomaro927さんと共同で執筆しました。