環境・バージョン
OS:Windows10
言語:python 3..8.3
パッケージ:tweepy3.9.0, pndas1.0.5
はじめに
前回の記事でツイートを取得する方法を紹介したので、今回はそれをcsvファイルとして記録する方法についてまとめます。ファイルへの書き込み/読み込みをするだけなら標準ライブラリのcsvモジュールを使ってもできますが、応用することを考えてpandasパッケージを利用します。予めインストールしておいてください。
pip install pandas
csvとは
csv(Comma Separated Value)とは、「テキストデータをカンマで区切ったデータ形式」です。例えば、以下はcsvファイルです。
1,あ
hoge,23
csvファイルへの書き込み
csvファイルへの書き込みは以下の手順でできます。
- データフレームの作成
- to_csvメソッドで書き込み
データフレームとは二次元構造のデータです。例えば数学における行列はデータフレームです。
# pandasをインポート(以降省略)
import pandas as pd
# データフレームの作成
# 定義:df = pd.DataFrame(data = 格納するデータ, index = 行名, columns = 列名)
b = pd.DataFrame(
data=[[3,4],[5,6]],
index=["1行目","2行目"],
columns=["1列目","2列目"]
)
# csvファイルへの書き込み
# df.to_csv("ファイルへのパス")
# ファイル名のみの場合はカレントディレクトリに作成される。
b.to_csv("b.csv")
,1列目,2列目
1行目,3,4
2行目,5,6
pd.DateFrameのindexとcolumnsは省略可能です。その場合、行も列も0始まりの連番が付けられます。
また、indexとcolumnsはそれぞれ削除してcsvファイルに出力することもできます。
# indexとcolumnsを省略
c = pd.DataFrame(
data=[[3,4],[5,6]]
)
# indexとcolumnsを削除して出力
c.to_csv("c.csv",index=False,header=False)
3,4
5,6
csvファイルの読み込み
csvファイルを読み込むにはread_csvメソッドを使います。先ほどのb.csvを読み込んでみます。
# b.csvを読み込む
d = pd.read_csv("b.csv")
# 確認
print(d)
Unnamed: 0 1列目 2列目
0 1行目 3 4
1 2行目 5 6
一応読み込むことはできましたが、「1行目」「2行目」が行名として認識されず、おかしなことになってしまいました。
これを回避するにはオプション「index_col=0」を追加します。
# b.csvを読み込む
e = pd.read_csv("b.csv",index_col=0)
# 確認
print(e)
1列目 2列目
1行目 3 4
2行目 5 6
正しく読み込めました。データフレームの特定の行や列を抽出したい場合は以下のようにします。
print(e["1列目"])
print("-------------------")
print(e.loc["1行目"])
print("-------------------")
print(e.at["1行目","1列目"])
1行目 3
2行目 5
Name: 1列目, dtype: int64
-------------------
1列目 3
2列目 4
Name: 1行目, dtype: int64
-------------------
3
初めから特定の列だけ読み込む場合は以下のようにします。
f=pd.read_csv("b.csv",usecols=["1列目"])
# 確認
print(f)
1列目
0 3
1 5
取得したツイートをcsvファイルへ保存してから取り出す
本題に入ります。前回のtweepyと今回のpandasを組み合わせて、ツイートを取得してcsvファイルに保存し、さらに特定のデータだけ抽出してみます。
取得するツイートは以下のTLとします。
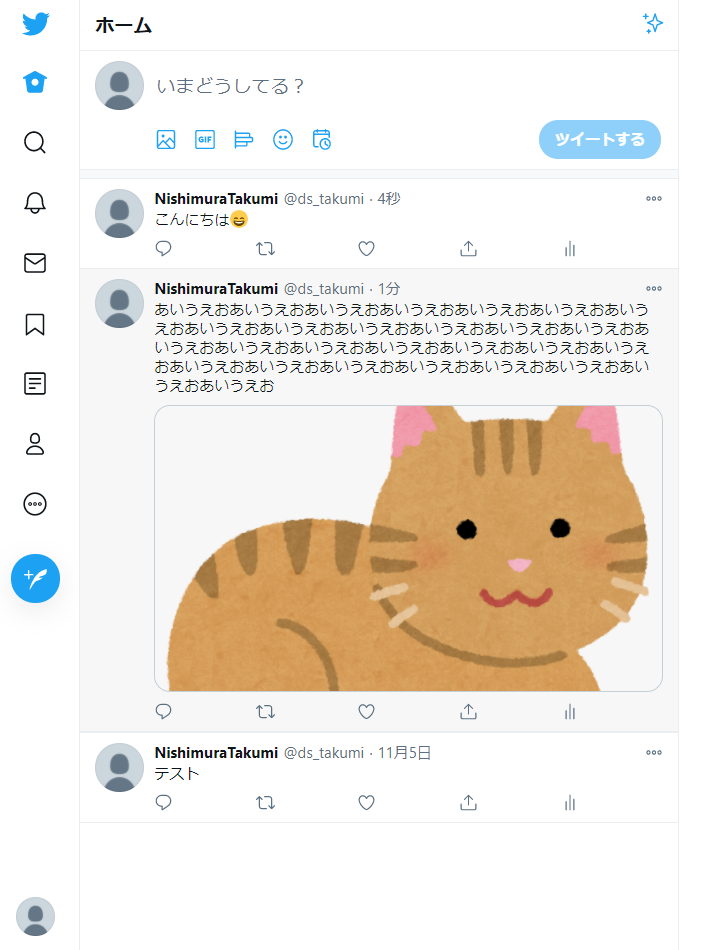
長くなりますがプログラムを一気に書きます。
# tweepyとpandasをインポート
import tweepy
import pandas as pd
# OAuth認証
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = ""
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# APIクラスをインスタンス化
api = tweepy.API(auth)
# TLのツイートを取得する
# 全文取得したいのでtweet_mode = "extended"を付ける
TL_tweets = api.home_timeline(tweet_mode = "extended")
# データフレームを作成する
# 「ツイート日時」、「ユーザーネーム」、「本文」の順に保存する
TL_tweets_df_data = [[i.created_at,i.user.name,i._json["full_text"]] for i in TL_tweets]
TL_tweets_df_columns = ["ツイート日時","ユーザーネーム","本文"]
TL_tweets_df = pd.DataFrame(
data = TL_tweets_df_data,
columns = TL_tweets_df_columns
)
# csvファイルに書き込む
TL_tweets_df.to_csv("TL.csv")
# ツイート本文だけ取り出す
TL_tweets_text = pd.read_csv("TL.csv",usecols=["本文"])
# データフレームの表示幅を変更
# これがないと途中までしか表示されない
pd.options.display.max_colwidth = 300
# 確認
print(TL_tweets_text)
本文
0 こんにちは😄
1 あいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえお https://t.co/BrX4mQVv21
2 テスト
最後に
今回はpandasを使って取得したツイートをcsvファイルに保存しました。
次回は一定時間自動的にsearchメソッドでツイートを取得し、csvファイルに追記していくプログラムを作ります。その際、スパムを取り除いたり、重複なく取得する工夫や特殊な文字に対する処理が課題になると思います。