この記事はTakumi Akashiro ひとり Advent Calendar 2020の18日目の記事です。
始めに
みなさまは正規表現使ってますかー?!!!
私は最後に使ったのが1ヶ月前ぐらいですね。
必要なときが来るとバリバリ使います。
そんな正規表現ですが、しっかり使うと任意の文字列群を良い感じに抽出できます。
TLDL
文字列群を取り出すときは名前付きグループを使おう!
>> text = "environ/house-food/apple-pie02.fbx"
>> import re
>> reg_text = r'(?P<main>(chara|environ))/(?P<sub>[^-/]*)-?(?P<sub_sub>[^/]*)/(?P<filling>[^-]*)-pie'
>> match = re.search(reg_text, text)
>> print(match.groupdict())
{'main': 'environ', 'sub': 'house', 'sub_sub': 'food', 'filling': 'apple'}
正規表現の基本
まず正規表現の基本、適当にマッチをしていきます。
# ! python3
import re
def main():
# NOTE: どうでもいいですけど、正規表現のサンプルでアップルパイってよく見かけますよね。
text = "environ/house-food/apple-pie02.fbx"
match_obj= re.search(r'pie', text)
if match_obj:
print("ヒットしたよ!")
else:
print("ヒットしないよ!")
if __name__ == '__main__':
main()
ま、こんなもんです。超簡単ですね。
速度が求められて先頭一致が可能な場合はre.matchを使ったり、置換したいときはre.sub使うぐらいできれば、
とりあえず正規表現を使うのには困らないですね。1
ではここで、pieの前にある文字列appleを抽出するにはどうしましょう。
色々文字列を削ったりして取り出すと思います。
でも取得対象が複数あるときは?例えばenviron、house、foodとappleを一気に取りたい場合は?
こんなときに利用できるのがグループです。
ちょっと公式ドキュメントを読んでみましょう。
正規表現のシンタックス
(中略)
(...)
丸括弧で囲まれた正規表現にマッチするとともに、グループの開始と終了を表します。
グループの中身は以下で述べるように、マッチが実行された後で回収したり、その文字列中で以降 \number 特殊シーケンスでマッチしたりできます。
リテラル '(' や ')' にマッチするには、( や ) を使うか、文字クラス中に囲みます: [(]、 [)] 。
……どう使うんだか分からん……
というわけでサンプルを出してみます。
グループを使ってみる
# ! python3
import re
def main():
text = "environ/house-food/apple-pie02.fbx"
match_obj= re.search(r'([^/-]*)-?pie)', text)
print(match_obj.groups())
if __name__ == '__main__':
main()
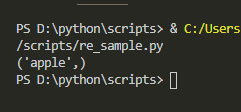
マッチオブジェクトに対してmatch_obj.groups()することで、
グループ化した正規表現に引っかかった文字列のリストが取得できます。
なので上記のtextからenviron、house、foodとappleを取り出したいと考えて,
# ! python3
import re
def main():
text = "environ/house-food/apple-pie02.fbx"
match = re.search(r'([^/-]*)/([^/-]*)-?([^/-]*)/([^/-]*)-?pie', text)
if match:
print(match.groups())
if __name__ == '__main__':
main()
とすれば……
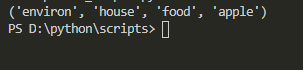
無事、出来ましたね!
まあまあ便利ですね!
listじゃなくてdictとしてほしいんだよなーとか、
正規表現じゃ()はよく使うから、必要な部分だけほしいんだよなーとかあると思います。
そんなときにはコレ「名前付きグループ」です!
例のごとく、公式ドキュメントを読んでみます。
正規表現のシンタックス
(中略)
(?P<name>...)
通常の丸括弧に似ていますが、このグループがマッチした部分文字列はシンボリックグループ名 name でアクセスできます。
グループ名は有効な Python 識別子でなければならず、各グループ名は 1 個の正規表現内で一度だけ定義されていなければなりません。
シンボリックグループは、そのグループが名前付けされていなかったかのように番号付けされたグループでもあります。
名前付きグループ を使ってみる
ま、とりあえず使えばわかるでしょうの精神で書きます。
# ! python3
import re
def main():
text = "environ/house-food/apple-pie02.fbx"
match = re.search(r'(?P<main>[^/-]*)/(?P<sub>[^/-]*)-?(?P<sub_sub>[^/-]*)/(?P<filling>[^/-]*)-?pie', text)
if match:
print(match.groupdict())
if __name__ == '__main__':
main()
マッチオブジェクトに対してmatch_obj.groupdict()することで、
名前がついたグループ化の辞書が取得できます。

いい感じに取り出せてますね!
締め
なんも思いつかねえ……
便利ですね!
-
追記: 速度を気にするような話であれば、forループ内で同じ正規表現を使う場合、forの外で
re.compileして再利用するとが若干早くなりますね。 ↩