はじめに
これは「imtakalab Advent Calendar 2023」の25日目の記事です。
私は理系大学の学部4年生で、主に機械学習について研究・学習しています。この記事では、VAE(Variational Auto-Encoder)についての論文『Auto-Encoding Variational Bayes』を読んだのでそのアウトプットと、後半ではVAEの実装をしていきたいと思います。
VAE概要
生成モデルとは
VAEは深層生成モデルに分類されます。そもそも生成モデルとは、観測データ $x$ が何かしらの確率分布 $p(x)$ に従って生成されていると仮定し、その生成過程を確率分布 $p_\theta(x)$ によってモデル化する手法です。つまり生成モデルがデータの真の分布 $p(x)$ を近似するときの $\theta$ を求めることが目標です。
この確率分布を深層ニューラルネットワークによって表現したモデルが深層生成モデルです。
準備
VAEでは観測データの背景にある因子として潜在変数 $\boldsymbol{z}$ を仮定し、確率分布を$p_\theta(\boldsymbol{x})=\int_{z} p_\theta(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{z}) d\boldsymbol{z}$ とします。以下の図の実践部分です。
また、点線の部分は解析的に計算できない事後分布 $p_\theta(\boldsymbol{z}|\boldsymbol{x})$ に対しての近似事後分布$q_\phi(\boldsymbol{z}|\boldsymbol{x})$ を表します。

事後分布が解析的に計算できない理由
確率変数が連続値をとる場合において事後分布の分母は積分計算になり計算が難しいため。(未観測の確率変数のとりうる組み合わせを調べ尽くすことが困難)
詳しくは以下を参照ください。
https://t-keita.hatenadiary.jp/entry/2021/04/22/015755
全体像
VAEはエンコーダとデコーダの2つのニューラルネットにより構成されています。エンコーダは $q_\phi(\boldsymbol{z}|\boldsymbol{x})$ を推定し、デコーダは $p_\theta(\boldsymbol{x}|\boldsymbol{z})$ を推定します。

(参考:https://www.slideshare.net/masa_s/ss-199311999)
具体的には、入力に対して$q_\phi(\boldsymbol{z}|\boldsymbol{x})$ が平均 $\boldsymbol{\mu}$ と分散$\boldsymbol{\sigma}$ を出力し $\boldsymbol{z}$ をサンプリングし、$p_\theta(\boldsymbol{x}|\boldsymbol{z})$ は潜在変数 $\boldsymbol{z}$ を入力として $\boldsymbol{x}$ を再構成します。
目的関数
VAEでは以下の対数尤度の変分下限(variational lower bound)を最大化することでパラメータ $\theta$ と$\phi$ を最適化します。
\log p_\theta(\boldsymbol{x}^{(i)}) \geq \mathbb{E}_{q_\phi(\boldsymbol{z}|\boldsymbol{x})}[\log p_\theta(x|\boldsymbol{z})] - D_{KL}[q_\phi(\boldsymbol{z}|\boldsymbol{x}) \| p(\boldsymbol{z})]
右辺の第1項は対数尤度の近似事後分布に対する期待値(負の値)、第2項は近似事後分布と事前分布のKLダイバージェンスを表しています。
簡単に説明すると、第1項でニューラルネットの出力と入力を近づけるように学習し、第2項では事後分布が事前分布(正規分布)に近づくように学習します。
目的関数の右辺は、対数尤度の変分下限と言われ、対数尤度を最大化したときの下限を表しています。導出は対数尤度のイェンセン(Jensen)の不等式を利用することで得られます。(かなり長くなるので今回は省略、時間あったら詳しく書きたい)
VAEの考え方は変分ベイズ(variational bayesian:VB)の手法が元になっています。変分ベイズは、近似事後分布を最適化する手法ですが、近似事後分布に平均場近似(分布が独立な分布の積で表されているという仮定)をしているため近似事後分布の表現力に限界があり、一般的な場合に取り扱いにくいという性質があります。この欠点を補ったのがVAEです。
変分ベイズについて詳しくは以下を参照ください。
https://academ-aid.com/ml/vae#index_id6
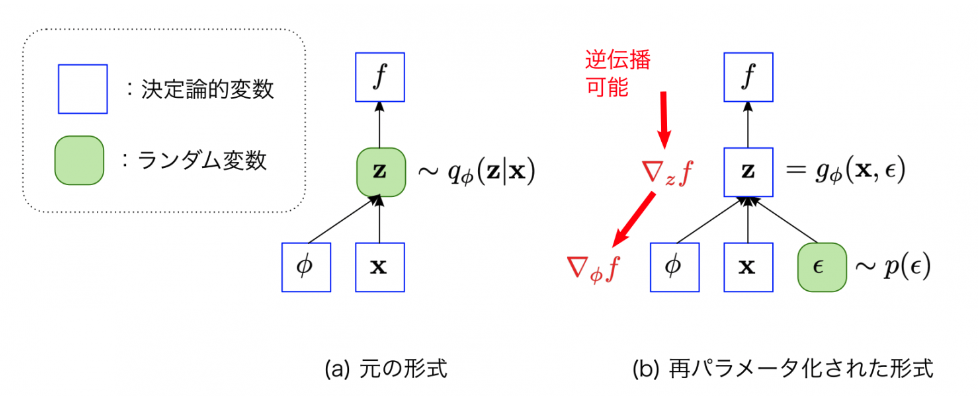
再パラメータ化トリック(reparameterization trick)
$q_\phi(\boldsymbol{z}|\boldsymbol{x})$ を用いて $\boldsymbol{z}$ のサンプリングをおこないましたが、$\boldsymbol{z}$ は平均 $\boldsymbol{\mu}$ と分散$\boldsymbol{\sigma}$ から出力されるものなのでモンテカルロ勾配推定法を適応すると高い分散をとってしまいます。また、誤差逆伝播可能にするためにはサンプリング処理では微分不可能なため改良が必要です。
そこで、パラメータ $\phi$ による分布であった $\boldsymbol{z}$ をパラメータ $\phi$ による決定的な関数とノイズで表すことにします。これが再パラメータ化トリックです。
\boldsymbol{z} = g_\phi(\boldsymbol{x}, \epsilon)
ここで $\epsilon$ は正規分布からのサンプリングです。この $\epsilon$ に $\boldsymbol{z}$ の確率変数的な値を表現する役割を移すことで逆誤差伝播可能にしています。
実装
次に、実装に入ります。
実装では全体を見やすくするため主要なコード以外は折りたたんでいます。コードを確認したい方はお手数ですが、コードを開いて確認ください。
参考
実装は以下のサイトをかなり参考にしました。本記事での改善点は、プログラムを上記の説明に合わせた解説がついている部分と、特定の範囲の潜在空間から画像を生成する部分を追加したことです。
このサイトは 2023/12/25 現在 Google Colaboratory上で動くことを確認済みです。
ライブラリのimport
pytorch, matplotlibなどの必要なライブラリをimportします。
コード
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
データセットの取得
データは以下のようなMNISTの手書き文字データを使用します。
訓練データとテストデータの割合は8:2とします。
つまり、全体のデータ数が60000枚なので訓練データ48000枚、テストデータ12000枚です。
またバッチサイズは100にしています。(今回はキリがいいので)
コード
# データを取得(引数の詳細:https://pytorch.org/vision/main/generated/torchvision.datasets.MNIST.html)
data = MNIST("./data",
train=True,
download=True,
transform=transforms.ToTensor())
# 訓練データとテストデータの割合
train_size = int(len(data) * 0.8)
test_size = int(len(data) * 0.2)
train_data, test_data = torch.utils.data.random_split(data, [train_size, test_size])
# バッチごとにデータを読み込む(バッチサイズ100)
train_loader = DataLoader(dataset=train_data,
batch_size=100,
shuffle=True,
num_workers=0)
test_loader = DataLoader(dataset=test_data,
batch_size=100,
shuffle=True,
num_workers=0)
データの確認
データは28ピクセル×28ピクセルの白黒(1次元)のデータが100枚(バッチサイズ分)入っています。
コード
# 最初のバッチのデータを取り出す
images, labels = next(iter(train_loader))
print("images_size:",images.size()) #images_size: torch.Size([100, 1, 28, 28])
モデル構築
今回はエンコーダ、デコーダそれぞれを中間層2層の全結合層を持つニューラルネットによって表します。
class Encoder(nn.Module):
# z_dim は潜在変数の次元数
def __init__(self, z_dim):
super().__init__()
self.lr = nn.Linear(28*28, 300)
self.lr2 = nn.Linear(300, 100)
self.lr_ave = nn.Linear(100, z_dim) # 平均を求めるNN
self.lr_dev = nn.Linear(100, z_dim) # 分散を求めるNN
self.relu = nn.ReLU()
def forward(self, x):
x = self.lr(x)
x = self.relu(x)
x = self.lr2(x)
x = self.relu(x)
ave = self.lr_ave(x) # (1)平均
log_dev = self.lr_dev(x) # (2)分散
epsilon = torch.randn_like(ave) # ε
z = ave + torch.exp(log_dev / 2) * epsilon # (3)平均、分散から潜在変数zを求める
return z, ave, log_dev
class Decoder(nn.Module):
def __init__(self, z_dim):
super().__init__()
self.lr = nn.Linear(z_dim, 100)
self.lr2 = nn.Linear(100, 300)
self.lr3 = nn.Linear(300, 28*28)
self.relu = nn.ReLU()
def forward(self, z):
x = self.lr(z)
x = self.relu(x)
x = self.lr2(x)
x = self.relu(x)
x = self.lr3(x)
x = torch.sigmoid(x) # MNISTのピクセル値の分布はベルヌーイ分布に近いと考えられるので、シグモイド関数を適用します。
return x
class VAE(nn.Module):
def __init__(self, z_dim):
super().__init__()
self.encoder = Encoder(z_dim)
self.decoder = Decoder(z_dim)
# (4)
def forward(self, x):
# 入力 x からエンコーダにより潜在変数 z を出力
z, ave, log_dev = self.encoder(x)
# 潜在変数 z から x を再構成
x = self.decoder(z)
return x, z, ave, log_dev
(1)で平均 $\boldsymbol{\mu}$ を求め、(2)で分散 $\boldsymbol{\sigma}$ を求めています。
ここから $\boldsymbol{z}$ をサンプリングしてしまうと勾配計算ができないので、(3)のように $\epsilon$ を使って $\boldsymbol{z}$ を決定的な関数としています。(再パラメータ化トリック(reparameterization trick)
(4)は全体像の実装部分です。入力 $\boldsymbol{\sigma}$ から潜在変数 $\boldsymbol{z}$、潜在変数 $\boldsymbol{z}$ から $\boldsymbol{x}$ を再構成していることがわかります。
中間層100層と300層は変更可能です。また、エンコーダの入力、デコーダの出力が 28*28 なのは画像のデータサイズに合わせてです。
目的関数の定義
上記の式(目的関数)を計算すると目的関数は、(5)の入力データ $\boldsymbol{x}$ とVAEの出力 $\boldsymbol{x}$ のクロスエントロピーと(6)によって得られます。
詳しい計算過程は論文の付録やこの記事を参考にしてください。
def criterion(predict, target, ave, log_dev):
# (5)
bce_loss = F.binary_cross_entropy(predict, target, reduction='sum')
# (6)
kl_loss = -0.5 * torch.sum(1 + log_dev - ave**2 - log_dev.exp())
loss = bce_loss + kl_loss
return loss
目的関数では、目的関数を最大化する問題として扱いましたが、実装では最小化問題に置き換えています。なので変数名も loss としています。
学習
潜在変数は後で見るときに我々にもわかるように2次元に設定し、エポック数は20で学習します。
コード
z_dim = 2
num_epochs = 20
# おまじない(詳細:https://atmarkit.itmedia.co.jp/ait/articles/2008/28/news030.html)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# インスタンス化
model = VAE(z_dim).to(device)
# 最適化アルゴリズム(今回はAdam使用)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[15], gamma=0.1)
# loss、分散、平均など記録用
history = {"train_loss": [], "test_loss": [], "ave": [], "log_dev": [], "z": [], "labels":[]}
for epoch in range(num_epochs):
model.train() # 学習モーード☆に切り替え
# 訓練データを取り出し学習
for i, (x, labels) in enumerate(train_loader):
# 入力xからxを再構成
input = x.to(device).view(-1, 28*28).to(torch.float32)
output, z, ave, log_dev = model(input)
# 諸々記録
history["ave"].append(ave)
history["log_dev"].append(log_dev)
history["z"].append(z)
history["labels"].append(labels)
loss = criterion(output, input, ave, log_dev)
# 最適化、誤差逆伝播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 50 == 0:
print(f'Epoch: {epoch+1}, loss: {loss: 0.4f}')
history["train_loss"].append(loss)
model.eval() # 推論ターイム☆☆に切り替え
with torch.no_grad():
# 訓練データを取り出し学習
for i, (x, labels) in enumerate(test_loader):
# 入力xからxを再構成
input = x.to(device).view(-1, 28*28).to(torch.float32)
output, z, ave, log_dev = model(input)
loss = criterion(output, input, ave, log_dev)
# lossが下がっているか(うまく学習できているか)の確認のため記録
history["test_loss"].append(loss)
print(f'Epoch: {epoch+1}, test_loss: {loss: 0.4f}')
scheduler.step()
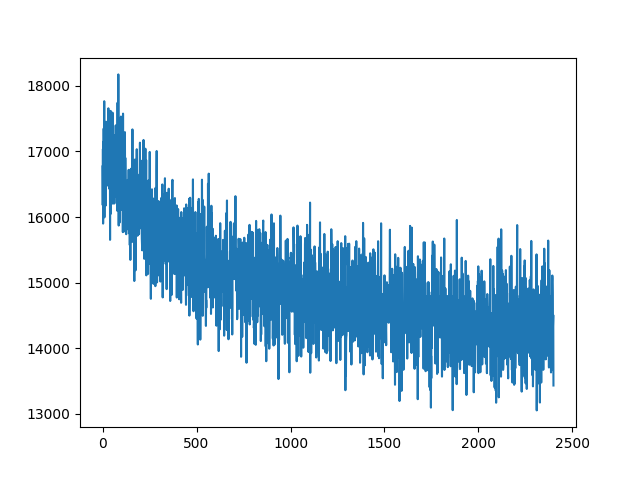
loss の確認
テストデータの loss が下がっているのが確認できます(訓練データの loss は省略、本来は訓練データの loss も下がっていることを確認してください)。ひとまず学習はうまくいっているようです。
コード
# numpyに変換してからplot
train_loss_tensor = torch.stack(history["test_loss"]) # ここをtrain_lossにすることで訓練データのlossも見れる
train_loss_np = train_loss_tensor.detach().numpy().copy()
plt.plot(train_loss_np)
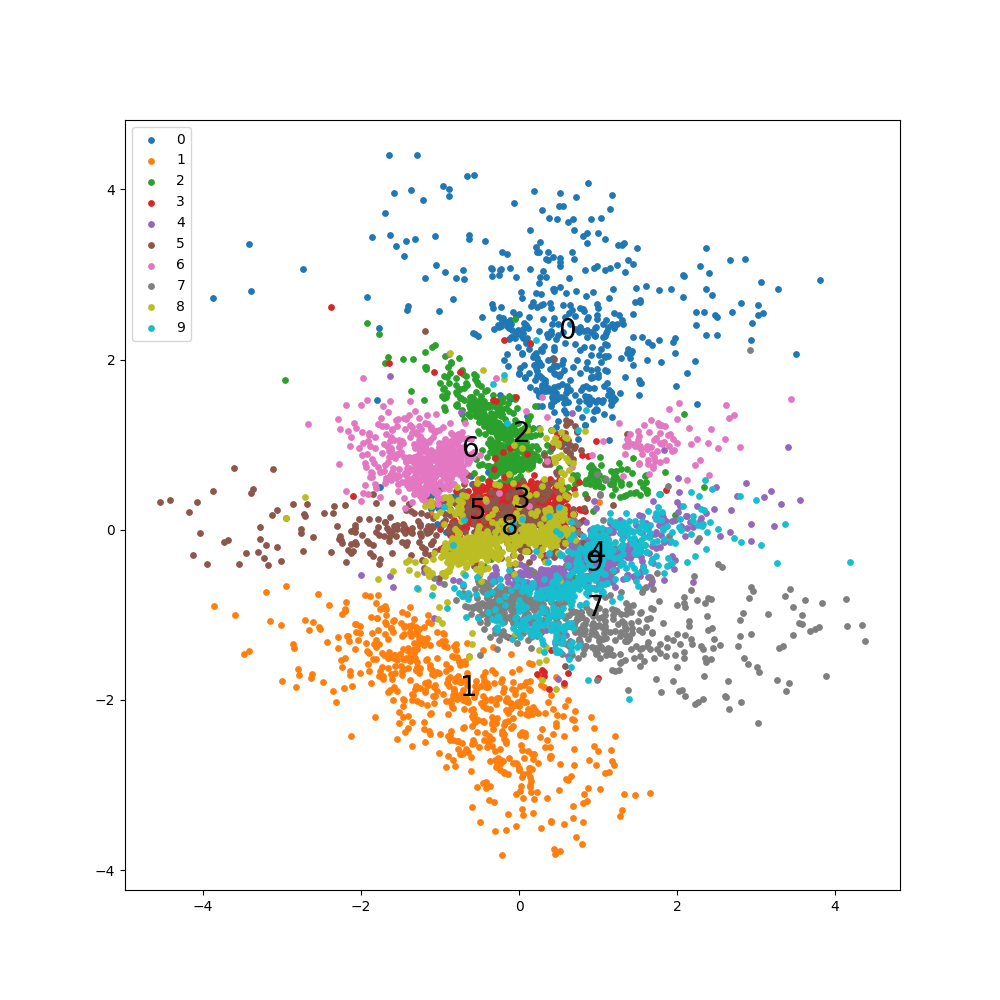
潜在変数の可視化
以下の図を見るとおおむね綺麗に分類できていることがわかります。
数字は各線変数の平均値です。
コード
# zと正解ラベルをnumpyに変換
z_tensor = torch.stack(history["z"])
z_np = z_tensor.detach().numpy().copy()
labels_tensor = torch.stack(history["labels"])
labels_np = labels_tensor.detach().numpy().copy()
cmap_keyword = "tab10"
cmap = plt.get_cmap(cmap_keyword)
# バッチが9550以降のzを可視化
batch_num = 9550
plt.figure(figsize=[10,10])
for label in range(10):
x = z_np[batch_num:,:,0][labels_np[batch_num:,:] == label]
y = z_np[batch_num:,:,1][labels_np[batch_num:,:] == label]
plt.scatter(x, y, color=cmap(label/9), label=label, s=15)
plt.annotate(label, xy=(np.mean(x),np.mean(y)),size=20,color="black")
plt.legend(loc="upper left")
画像生成
デコーダに潜在変数の値を入れることで画像を生成することができます。
これを利用して潜在変数のx軸とy軸を動かしたときの生成画像を作成すると以下のようになります。
うまく上の潜在変数の可視化とマッチしているのがわかります。
(範囲を細かくしたり狭めたりするとよりはっきりと可視化できます)
コード
f, ax = plt.subplots(10, 10, figsize=(8, 8))
for i, x in enumerate(np.linspace(-1.5, 1.5, 10)):
for j, y in enumerate(np.linspace(-2, 2, 10)):
# エンコーダにzを入れた出力をplot
z = torch.tensor([x, y], dtype = torch.float32)
output = model.decoder(z)
np_output = output.detach().numpy().copy()
np_image = np.reshape(np_output, (28, 28))
ax[9-j][i].imshow(np_image, cmap='gray')

おわりに
ここまで付き合っていただきありがとうございました!
かなりざっくりですがVAEについてまとめてみました。やってみて論文を読んでまとめることの難しさを痛感しました(特に今回の論文)。式の変形や概念をもう少し丁寧にやりたかったのですが間に合いませんでした。申し訳ないです!
実装も画像生成の精度が上がるように色々いじりたかったのですが、時間が足りませんでした。申し訳ないです!なので画像生成の部分以外の実装は他の記事のコード解説になってしまいました。
まだ生成画像がぼやけているものがあるのでそこら辺を改善できるようこれから頑張ります!(気が向いたらgithubにあげます)
そして忘れてました、メリークリスマス!!🎅🎄
こんな時間まで起きてる人のところにはサンタさん来ないです泣