はじめに
この記事はOUCC Advent Calendar 2020の22日目に登録された記事です。
8月の勉強会にML-Agentsという、Unity で強化学習(機械学習の一つ)ができるようになるツールについて書きましたが、それ以来触っていませんでした。ずっと放置するのももったいないので、自分の理解を深めるため、自分でオリジナルの機械学習をしてみたかったので今回やってみることにしました。
#環境
Unity:2019.4.16f1
ML-Agents: latest_release
Python: 3.7
環境構築の方法は8月の記事に書いてあるので割愛します。
#学習方法
この強化学習では、「セルフプレイ」という学習方法を使用します。「セルフプレイ」とは、敵対的ゲームでエージェント(AI)どうしを競い合わせることで、上達させる方法です。例として、リアルタイムストラテジーゲームで人間のトッププレイヤーを破ったAI「OpenAI Five」などに使われています。
#学習環境の作成
Unity でプロジェクトHockeyを作成します。外観はこのようになります。
➀ステージ:奥と手前の両方にスペースが空いており、そこにホッケーが入ることで勝敗が決まる様になっています。
➁ホッケー:摩擦なし、空気抵抗なし、完全弾性で動くようにします。
➂Agent:AIが操作します。ホッケーを跳ね返す、相手側のゴールに入れることで報酬を得られるようにします。
#観察方法
学習環境の状態を観察する方法として、今回はVector Observation を用います。この方法は、問題解決に必要な情報を格納した浮動小数配列を観察します。これだけだとわかりにくいので今回の学習を例に取ると、
Vector Observation(サイズ8、スタック2)
0:ホッケーのx座標 1:ホッケーのz座標
2:ホッケーのx速度 3:ホッケーのz速度
4:Agentのx座標 5:Agentのz座標
6:Agentのx速度 7:Agentのz速度
の計8つの数字を観察します。
#➀ステージ
####ScoreArea
奥と手前のスペースにはメッシュを削除、Box ColliderのIs Triggerにチェックを入れた、透明のオブジェクトがあります。
そのオブジェクトに次のスクリプトを追加します。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class ScoreArea : MonoBehaviour
{
public GameManager gameManager;
public int agentid;
void OnTriggerEnter (Collider other)
{
gameManager.EndEpisode(agentid);
}
}
#➁ホッケー
####PerfectBounce
ホッケーにはPhysic MaterialをPerfectBounceという名前でコライダーに追加し、以下のように設定します。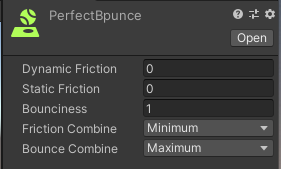
これでホッケーが完全弾性で跳ねるようになります。
#➂AI
####HockeyAgent
黄色い円柱のオブジェクトに次のスクリプトを追加します。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
public class HockeyAgent : Agent
{
public int agentId;
public GameObject Hockey;
private string targetTag = "Target";
Rigidbody HockeyRb;
Rigidbody Rigidbody;
//初期化時に呼ばれる
public override void Initialize()
{
this.HockeyRb = this.Hokkei.GetComponent<Rigidbody>();
this.Rigidbody = this.GetComponent<Rigidbody>();
}
//観察取得時に呼ばれる
public override void CollectObservations(VectorSensor sensor)
{
float dir = (agentId == 0) ? 1.0f : -1.0f;
//観察方法で紹介したもの
sensor.AddObservation(this.Hockey.transform.localPosition.x * dir);
sensor.AddObservation(this.Hockey.transform.localPosition.z * dir);
sensor.AddObservation(this.HockeyRb.velocity.x * dir);
sensor.AddObservation(this.HockeyRb.velocity.z * dir);
sensor.AddObservation(this.transform.localPosition.x * dir);
sensor.AddObservation(this.transform.localPosition.z * dir);
sensor.AddObservation(this.Rigidbody.velocity.x * dir);
sensor.AddObservation(this.Rigidbody.velocity.z * dir);
//ホッケーとエージェントの衝突開始時に呼ばれる
void OnCollisionEnter(Collision collision)
{
if(collision.collider.tag == targetTag)
{
//報酬
AddReward(0.4f);
}
}
//行動実行時に呼ばれる
public override void OnActionReceived(float[] vectorAction)
{
//Agentの移動
float dir = (agentId == 0) ? 1.0f : -1.0f;
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[1] * dir;
controlSignal.z = vectorAction[2] * dir;
this.Rigidbody.velocity = controlSignal * 10;
}
//ヒューリスティックモード(人が操作するモード)で行動決定時に呼ばれる
public override void Heuristic(float[] actionsOut)
{
actionsOut[1] = Input.GetAxis("Horizontal");
actionsOut[2] = Input.GetAxis("Vertical");
}
}
####Behavior Parameters
Behavior Parametersを追加し、以下のように設定します。

####Decision Requester
Decision Requesterを追加し、以下のように設定します。

同様にもう1つのAgentを追加し、スクリプトHockeyAgent.csのAgentIdとBehavior ParametersのTeamIdを1に設定します。
#GameManager
ゲームの管理を行うオブジェクトGameManagerを追加します。「セルフプレイ」では、エピソード開始時をエピソード完了時の処理をエージェント別ではなくまとめて行います。
EmptyObjectを作成し、次のスクリプトを追加します。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
public class GameManager : MonoBehaviour
{
public Agent[] agents;
public GameObject Hockey;
public GameObject agent;
public GameObject agent1;
//スタート時に呼ばれる
void Start()
{
Reset();
}
//エピソード開始時に呼ばれる
public void Reset()
{
Rigidbody agentsrb = agent.GetComponent<Rigidbody>();
Rigidbody agents1rb = agent1.GetComponent<Rigidbody>();
//エージェントの位置と速度をリセット
agents[0].gameObject.transform.localPosition = new Vector3(0.0f, 0.32f, -7.0f);
agents[1].gameObject.transform.localPosition = new Vector3(0.0f, 0.32f, 7.0f);
agentsrb.velocity = Vector3.zero;
agents1rb.velocity = Vector3.zero;
//ホッケーの位置と速度をリセット
float speed = 10.0f;
Hockey.transform.localPosition = new Vector3(0.0f, 0.25f, 0.0f);
float radius = Random.Range(45f, 135f) * Mathf.PI / 180.0f;
Vector3 force = new Vector3(
Mathf.Cos(radius) * speed, 0.0f, Mathf.Sin(radius) * speed
);
if(Random.value < 0.5f) force.z = -force.z;
Rigidbody rb = Hockey.GetComponent<Rigidbody>();
rb.velocity = force;
}
//エピソード完了時に呼ばれる
public void EndEpisode(int agentId)
{
if(agentId == 0)
{
agents[0].AddReward(1.0f);
agents[1].AddReward(-1.0f);
}
else
{
agents[0].AddReward(-1.0f);
agents[1].AddReward(1.0f);
}
agents[0].EndEpisode();
agents[1].EndEpisode();
Reset();
}
void FixedUpdate()
{
if(Hockey.transform.position.y < 0)
{
Reset();
}
}
}
#セルフプレイの訓練設定ファイルの設定
behaviors:
Hockey:
trainer_type: ppo
hyperparameters:
batch_size: 1024
buffer_size: 10240
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
checkpoint_interval: 500000
max_steps: 50000000
time_horizon: 1000
summary_freq: 10000
threaded: true
self_play:
save_steps: 50000
team_change: 10
swap_steps: 50000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
#self_playのパラメータ
save_steps:何ステップ毎にポリシーを保存するかを指定します。(10000~100000)
team_change:何ステップ毎に学習チームを切り替えるかを指定します。 (4~10)
swap_step:何ステップ毎に対戦相手のポリシーを交換するかを指定します。(10000~100000)
window:対戦相手として保持するポリシー数を指定します。この値が大きいと、対戦相手が多様になります。(5~30)
play_against_latest_model_ratio:エージェントが現在のポリシーと対戦する確率を指定します。更新ごとに異なる対戦相手と戦うことになります。(0.0~1.0)
initial_elo:ELOの初期値を指定します。デフォルトは1200.0になります。
その上のパラメータは8月に書いたので割愛します。
#セルフプレイの学習を実行
anacondaのプロンプトを開いて以下のコマンドを実行
mlagents-learn config/ppo/Hockey.yaml --run-id=Hockey.yaml-ppo-1
#結果
タイトルに"させたかった"とあるように、うまく行きませんでした・・・。具体的には、学習自体は実行されるが、AIが適切に学習していない状態だった。おそらく、観察する状態もしくはパラメータの設定が適切ではなかったと推測しています。例えば、敵対的ゲームにおいて相対評価で実力を表すために使われる指標の1つに__ELO__があります。これは適切な訓練を行うことで、増加し、その変化量が重要であると言われています。しかし、今回の訓練をでは、__ELO__がずっと一定または少し減少するといった事が起きていて、適切な訓練がなされていなかったことになります。
#感想
・Unity の知識しかない状態で行っていて、実際それでもここまでこれたが、Pythonの知識も身につけるべきだと思った。
・一通り基礎を身に着けてから再挑戦したい。