概要
- アンケート集計を行なっていると、複数回答形式の回答の処理が面倒な場面があります
- アンケート回答システムによっては、複数回答項目をカンマ区切りで一つのセルに入った状態で渡されます
- このままでは集計できないので、ダミー変数のテーブルに変換する必要があるのですが、標準パッケージにはない為、独自に処理ロジックを作成する必要があります
- 同じ場面に遭遇した方の為に参考までの共有です
受領したデータ
| 回答者 | 回答(複数選択) |
|---|---|
| 回答_0 | a,b,c |
| 回答_1 | b,c,d,e,f |
| 回答_2 | d,e,f |
| 回答_3 | a,b,c,d |
| 回答_4 | c,d,e,f |
| 回答_5 | e,f |
集計で欲しいデータ
| 回答者 | 回答_a | 回答_b | 回答_c | 回答_d | 回答_e | 回答_f |
|---|---|---|---|---|---|---|
| 回答_0 | 1 | 1 | 1 | 0 | 0 | 0 |
| 回答_1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 回答_2 | 0 | 0 | 0 | 1 | 1 | 1 |
| 回答_3 | 1 | 1 | 1 | 1 | 0 | 0 |
| 回答_4 | 0 | 0 | 1 | 1 | 1 | 1 |
| 回答_5 | 0 | 0 | 0 | 0 | 1 | 1 |
アプローチ
- 複数回答選択肢をユニークで取得(集計で欲しいデータのヘッダー)
- 回答を一つづつ確認していき、回答選択肢を含んでいたらTrue、含んでいなかったらFalseを返す
- Bool(True or False)型をint(1 or 0)に変換し元のデータフレームへ結合
コード
- 複数回答形式のサンプルデータの作成
sample = pd.DataFrame(['a,b,c','b,c,d,e,f','d,e,f','a,b,c,d','c,d,e,f','e,f'], columns=['複数回答'])

- 複数回答選択肢をユニークで取得(集計で欲しいデータのヘッダー)
# 複数回答データを','で分割して、1つのリストにまとめる
ans = [sample['複数回答'][i].split(',') for i in range(len(sample))]
# リストのflattening
ans_ = []
for s in ans:
ans_.extend(s)
# 重複を除きユニークな回答選択肢を取得
ans_ = np.unique(ans_)
- 回答を一つづつ確認していき、回答選択肢を含んでいたらTrue、含んでいなかったらFalseを返す
- まずは回答を固定して動作確認
- ans_0が含まれているかを a in bで検証して、True / Falseを返している
[ans_[0] in sample['複数回答'][i] for i in range(sample.shape[0])]

- 回答をfor文で一つづつ動かして、True/Flseの行列を作成
- 作成した行列をPandas.Dataframeへ変換(回答選択肢ごとにTrue/Falseを判定しているため、Transpose(転置)する
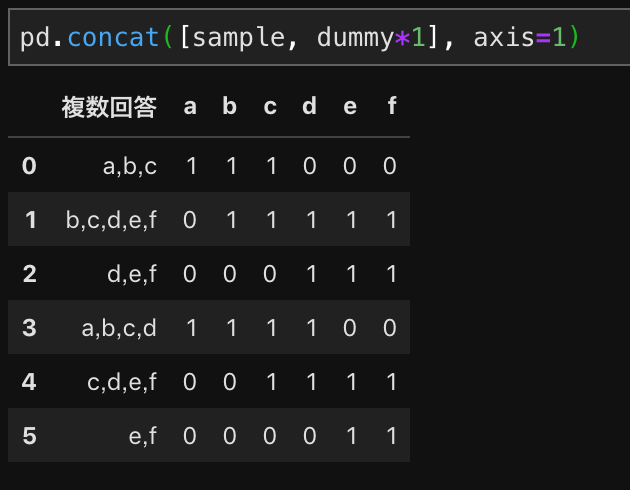
- dummy*1をすることで、True/Falseを1/0へ変換して、元のデータフレームを結合
dummy = []
for j in range(len(ans_)):
dummy.append([ans_[j] in sample['複数回答'][i] for i in range(sample.shape[0])])
dummy = pd.DataFrame(dummy, index=ans_).T
pd.concat([sample, dummy*1], axis=1)