採点対象範囲
プロローグ1
要約
機械学習は識別と生成が存在する。
識別器は三つのアプローチがある。
- 生成モデル
- 識別モデル
識別したいものかを0から1の確率で出力する。 - 識別関数
識別したいものに合致するかどうかを0か1で出力する。
万能近似定理により、ある深さのニューラルネットワークで関数が近似できる。
ニューラルネットワークの全体像
要約
深層学習は回帰と分類問題が解ける。
自動売買やチャットボット、翻訳、音声解釈、囲碁・将棋AIなどで使われている。
Session1:入力層~中間層
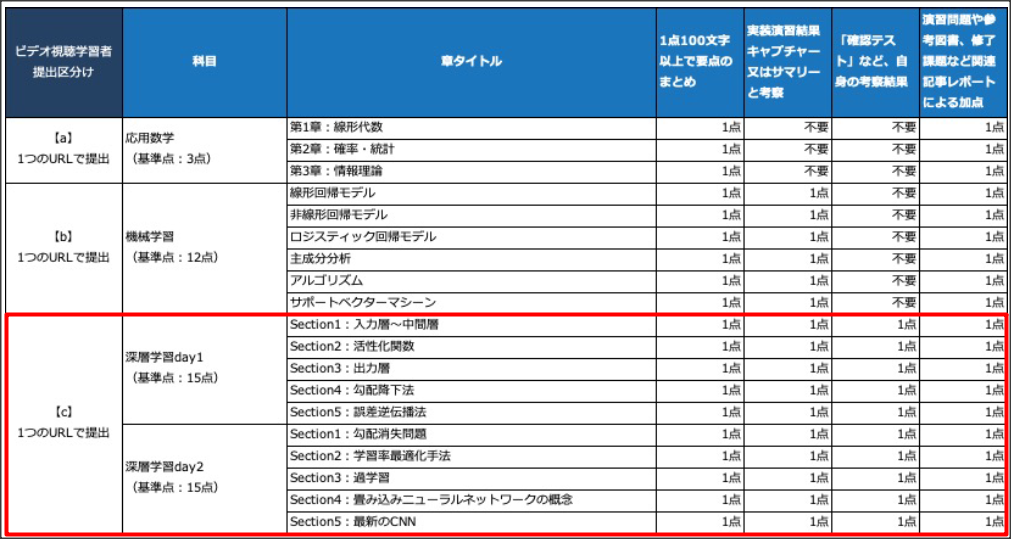
1点100字以上で要点のまとめ
入力$x=(x_1, ... , x_n)$に対し、$W^{(i)}=(w_1^{(i)}, ..., W_n^{(i)}) i=1, ..., k$、$W = (W^{(1)}, ..., W^{(k)}), b = (b_1, ..., b_n)$と置くことで、中間層$u = (u_1, ..., u_k)$が下記のように計算できる。
$$ u = Wx + b$$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
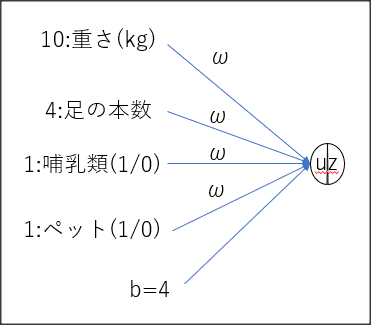
確認テスト この図式動物分類の実例を入れてみよう。
確認テスト $u = W * x + b$をpythonで計算する

確認テスト 中間層を抜き出す

演習問題や参考図書、修了課題など関連記事レポート
考察:ニューラルネットワークの万能近似定理

(https://qiita.com/mochimochidog/items/ca04bf3df7071041561aより抜粋)
これによると、連続関数は、それを近似するような中間層を持つニューラルネットワークが必ず存在する
(より正確に言えば、どんな$ε>0$であっても、誤差が$ε$より小さくなるニューラルネットワークが存在する)。
これはニューラルネットワークでどんな関数でも学習できる十分条件にはならないが、必要条件ではある。
逆にこれを満たせない識別器は、ある種の関数に近づけるよう学習ができないということとなる。
Session2: 活性化関数
1点100字以上で要点のまとめ
活性化関数は、$u=wx+b$に対し、その値を変換する関数$f(u)$のこと。中間層に使う活性化関数と出力層に使う
活性化関数がある。活性化関数は10種類ある。
ReLU関数、シグモイド関数、ステップ関数
(1) ステップ関数 (現在は使われない)
$f(x) = 0 (x < 0), f(x) = 1 (x \ge 0)$
線形分離可能な関数しか学習できない。
(2) シグモイド関数
$f(u) = \frac{1}{1 + e^{-u}}$
勾配がなだらかなところでは、勾配消失問題が発生した。
(3) ReLU関数
$f(u) = 0 (u < 0), f(u) = u (u \ge 0)$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
確認テスト 線形と非線形の違いを図にかいて説明せよ
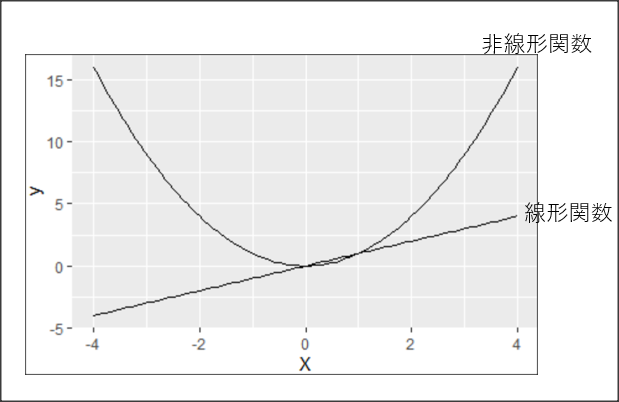
線形な関数は、$f(x + y) = f(x) + f(y)$、$f(kx)=kf(x)$が成り立つ。非線形は線形でない関数。
確認テスト 活性化関数が使われているところを探せ

演習問題や参考図書、修了課題など関連記事レポート
Session3: 出力層
1点100字以上で要点のまとめ
誤差関数
出力層の役割:人間が欲しいデータを出す。分類の問題であれば、犬の確率、猫の確率など。
誤差関数:ニューラルネットワークと訓練データのデータ差異を表す。
$(x, y) \in \mathbb{R}^k \times \in \mathbb{R}^l$という訓練データが与えられたときに、
ニューラルネットワークfに$x$を与えると、$\hat{y} = f(x)$が返ってきたとする。
この場合に、
$E(x) =\frac{1}{2}\sum{(\hat{y}_i - y_i)^2}$を二乗平方誤差関数という。
分類はクロスエントロピー誤差関数、回帰は平均二乗誤差関数を用いることが多い。
活性化関数
出力層の活性化関数は、データを使いやすいよう加工するのが目的。
||回帰|二値分類|多値分類|
|活性化関数|恒等関数|シグモイド関数|softmax関数|
|誤差関数|二乗誤差|交差エントロピー|交差エントロピー|
交差エントロピー$E=-\sum{d_i\log{y_i}}$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
なぜ誤差関数は二乗し、$\frac{1}{2}$をかけるのか。
二乗することで、誤差の大きさを足し合わせている。二乗しないと、誤差が打ち消しあう可能性がある。
微分したとき、$\frac{df(x)^2}{dx}=2f(x)\frac{df}{dx}$となり、$2$と$\frac{1}{2}$が打ち消しあうため、
$\frac{1}{2}$倍する。
ソフトマックス関数の処理を1行ずつ説明しろ
def softmax(x):
if x.ndim == 2:
# ミニバッチの場合
x = x.T
# オーバーフロー対策で、最大値を0にする
x = x - np.max(x, axis=0)
# Softmaxの値の計算。全体を合計すると1になるように、合計値で割っている。
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
# オーバーフロー対策で、最大値を0にする
x = x - np.max(x) # オーバーフロー対策
# Softmaxの値の計算。全体を合計すると1になるように、合計値で割っている。
return np.exp(x) / np.sum(np.exp(x))
クロスエントロピーの処理を説明せよ
def cross_entropy_error(d, y):
# ミニバッチの時の処理
if y.ndim == 1:
# dを(1, d.size)の形に変更する
d = d.reshape(1, d.size)
# dを(1, y.size)の形に変更する
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
# バッチサイズはyの大きさとなる。
batch_size = y.shape[0]
# クロスエントロピーを求める。1e-7を足すことで、値が0に落ちないよう工夫している。
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
演習問題や参考図書、修了課題など関連記事レポート
Session4: 勾配降下法
1点100字以上で要点のまとめ
確率勾配法
誤差関数を最小にする$\omega$を見つけていくのが勾配降下法。
$\omega^{t+1}=\omega^{t} - \epsilon \nabla E$
学習率$\epsilon$が小さいと収束するのが遅くなる。また、局所最適解に陥ってしまう可能性もある。
勾配降下法の$\epsilon$を選ぶためのアルゴリズムが4つある。
Momentum
AdaGrad
AdaDelta
Adam
1回のデータに対し誤差関数を計算し、勾配降下法で重みを更新するサイクルをエポックという。
確率的勾配降下法
確率的勾配降下法は、全データで学習するのではなく、データの中からランダムに一データを選んで、
そのデータを用いて学習する。
勾配降下法は、全データを用いるため、データが増えるとメモリに乗らない。
ミニバッチ勾配降下法
ミニバッチ勾配降下法は、全データで学習するのではなく、データをランダムに分割して、
分割したデータを用いて学習する。オンライン勾配降下法より計算資源を有効に活用できるため、
学習効率が良い。
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
∇Eが出現するコードを特定する

オンライン学習とは何か
学習データが1データだけで学習する。
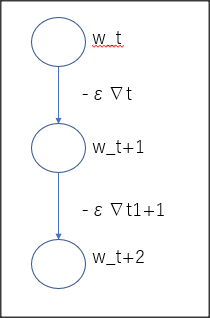
w_t+1 <- w_t - ε∇Eを図解せよ。
演習問題や参考図書、修了課題など関連記事レポート
Session5: 誤差逆伝搬法
1点100字以上で要点のまとめ
誤差勾配の計算
$\nabla E$の計算方法は実際に微分を用いる。
数値微分を用いる方法…$\frac{E(w_m +h) - E(w_m - h)}/2h$を計算する。
この方法は、それぞれの重み$w_1,...,w_k$で$\frac{E(w_m +h) - E(w_m - h)}/2h$を計算しなければならないため計算量が多い。
これは計算量が多いため、誤差逆伝搬法を用いる。
誤差逆伝搬法
$\nabla E = [\frac{\partial E}{\partial w_m}]$
を求めるために、誤差逆伝搬法を用いる。
誤差を後ろから計算して後ろの重みから更新し、前の重みを再帰的に更新する。
後ろの重みを計算したときの微分値を使えるため、計算量が少なくて済む。
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
誤差逆伝搬法のコード
def backward(x, d, z1, y):
# print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
#delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
## 試してみよう
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
delta1 = delta1[np.newaxis, :]
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
x = x[np.newaxis, :]
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
# print_vec("偏微分_重み1", grad["W1"])
# print_vec("偏微分_重み2", grad["W2"])
# print_vec("偏微分_バイアス1", grad["b1"])
# print_vec("偏微分_バイアス2", grad["b2"])
return grad
空欄を埋めろ
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
grad['W1'] = np.dot(x.T, delta1)
演習問題や参考図書、修了課題など関連記事レポート
その他
ディープラーニングの開発環境
クラウドであればAWS、GCPで開発できる。
ディープラーニングを行うためのH/W:CPU、GPU、FPGA、ASIC(TPU)
入力層の設計
欠損値が多いとダメ。異なるクラスが同じ値を示している場合も正しく分類できない。
過学習
教師データでは良い成績を残すが、検証データではいい成績が得られない状態。
学習のノードが多いと、発生する場合がある。ドロップアウトという手法で防ぐ方法がある。
データ拡張
画像データの分類で使える手法。
画像を拡大・縮小したり、一部を隠したり、などの手法を使うことで、画像を大量に水増しして
教師データを増やす手法。
ディープラーニングの中間層にノイズを入れる手法もある。
CNN
次元方向につながりのあるデータを扱う。
転移学習
画像認識の層が浅いところは基本的な特徴を捉えているはずなので、すでに学習済みの層が浅いところを
別の学習に用いることができる。このように、学習モデルを他で使うことを転移学習という。
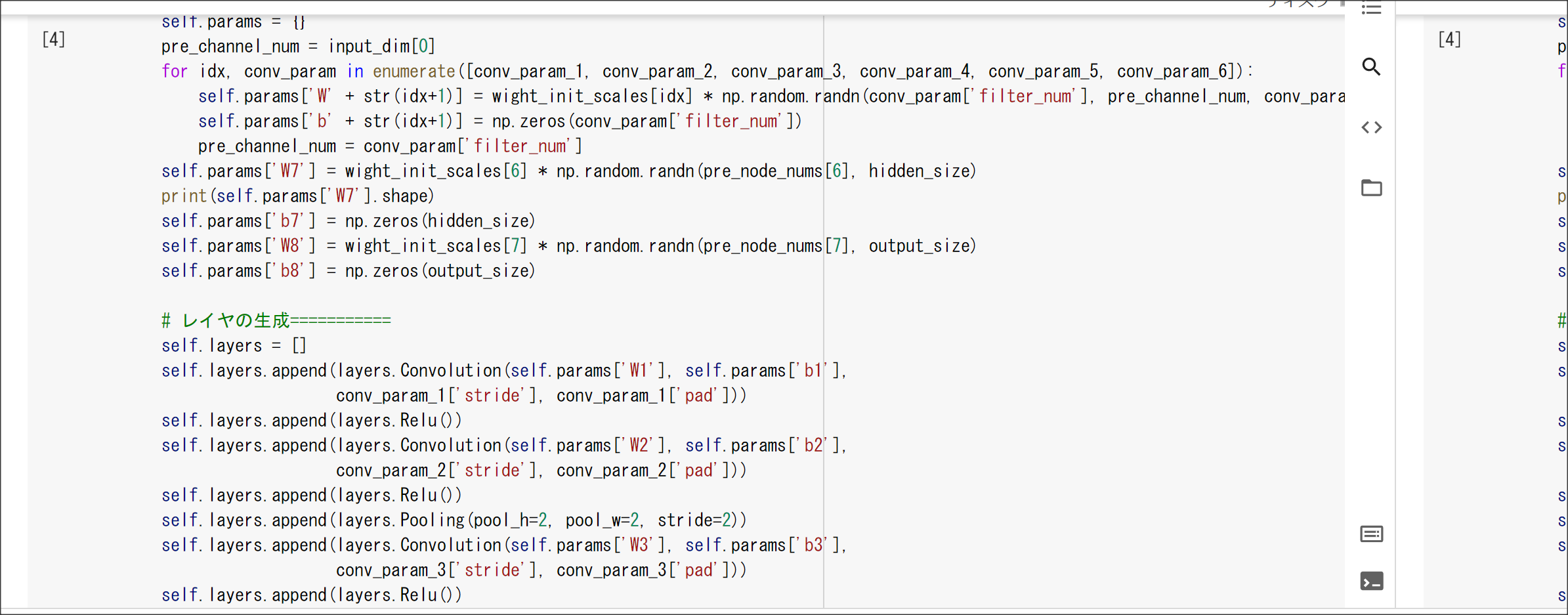
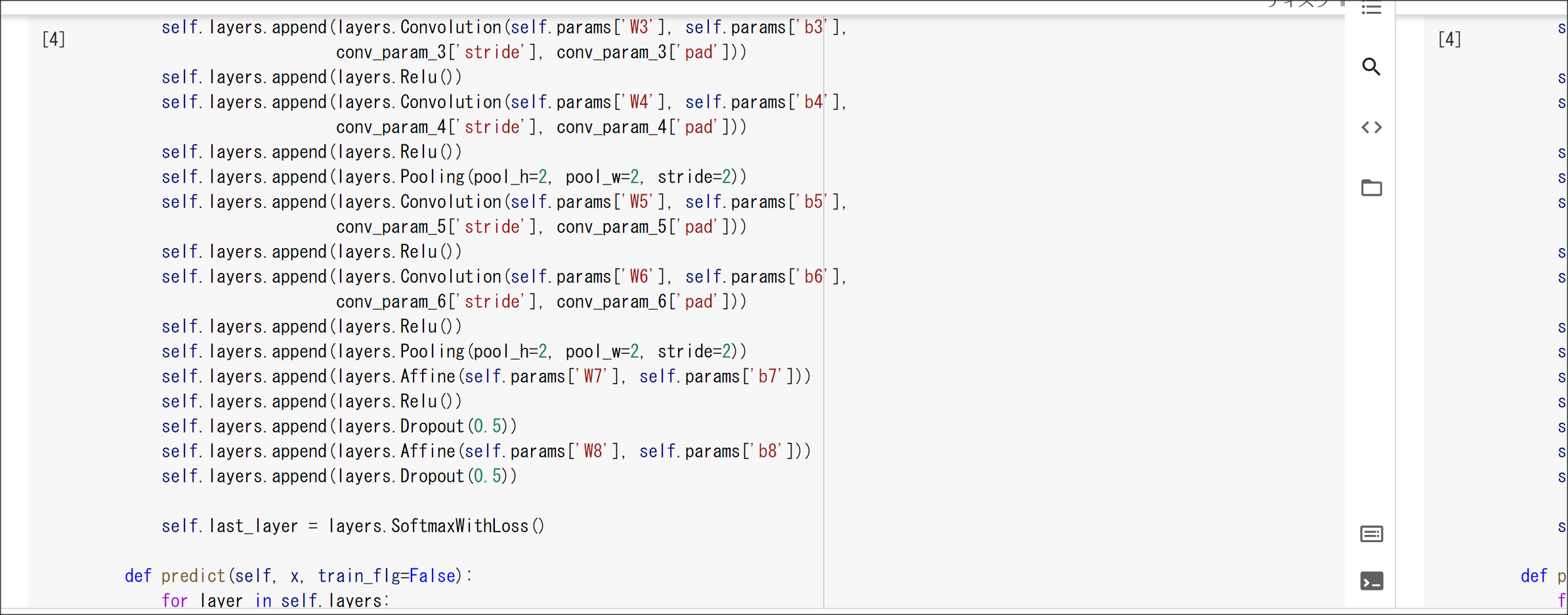
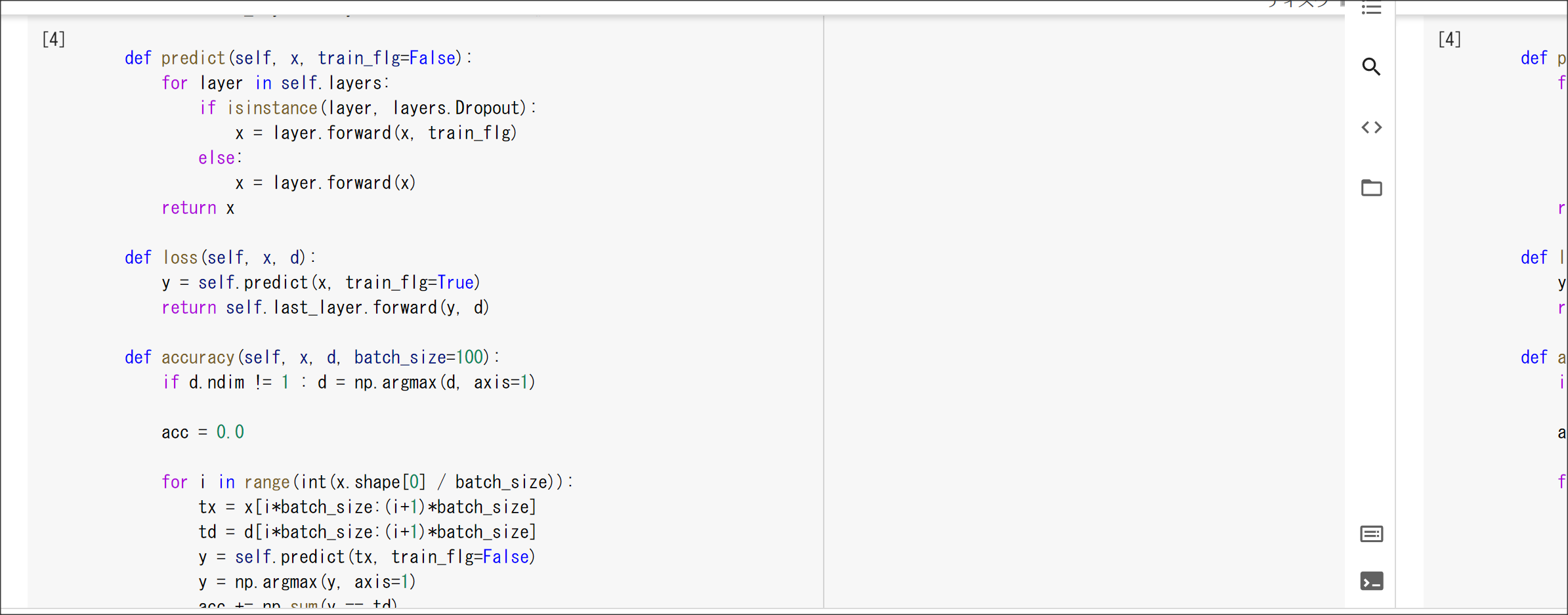
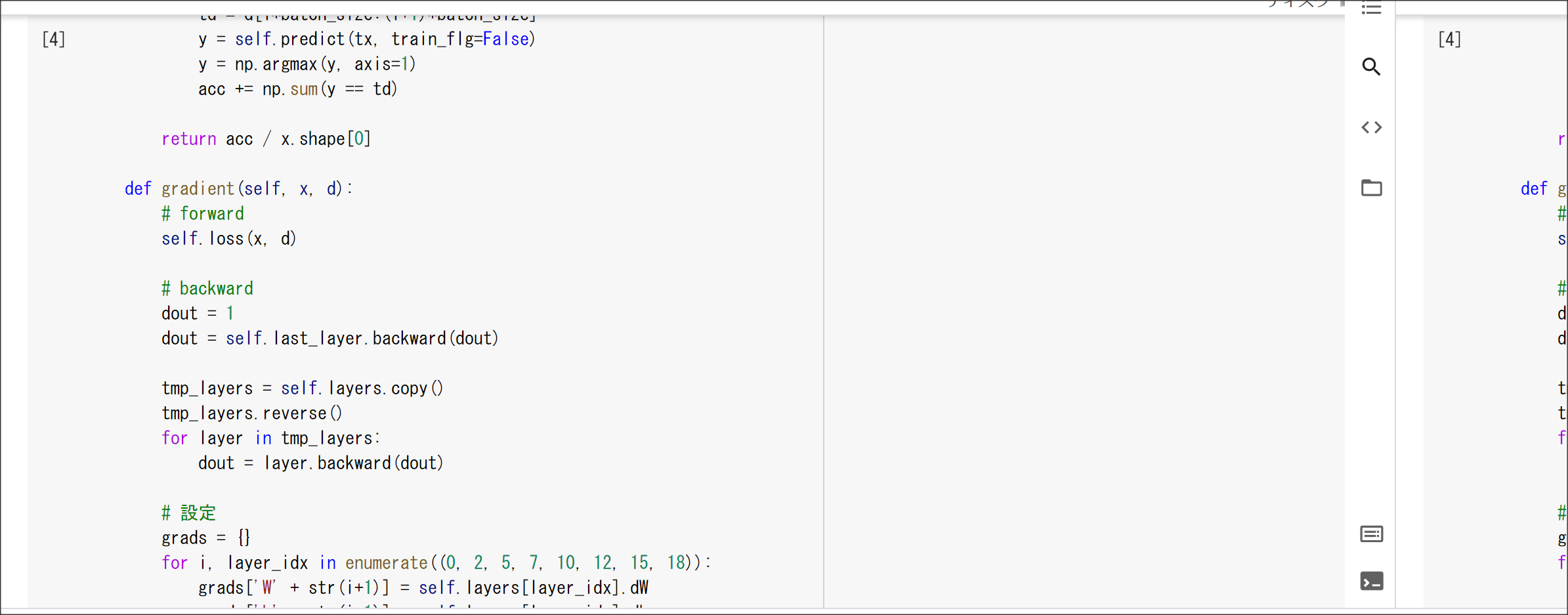
実装演習結果キャプチャ
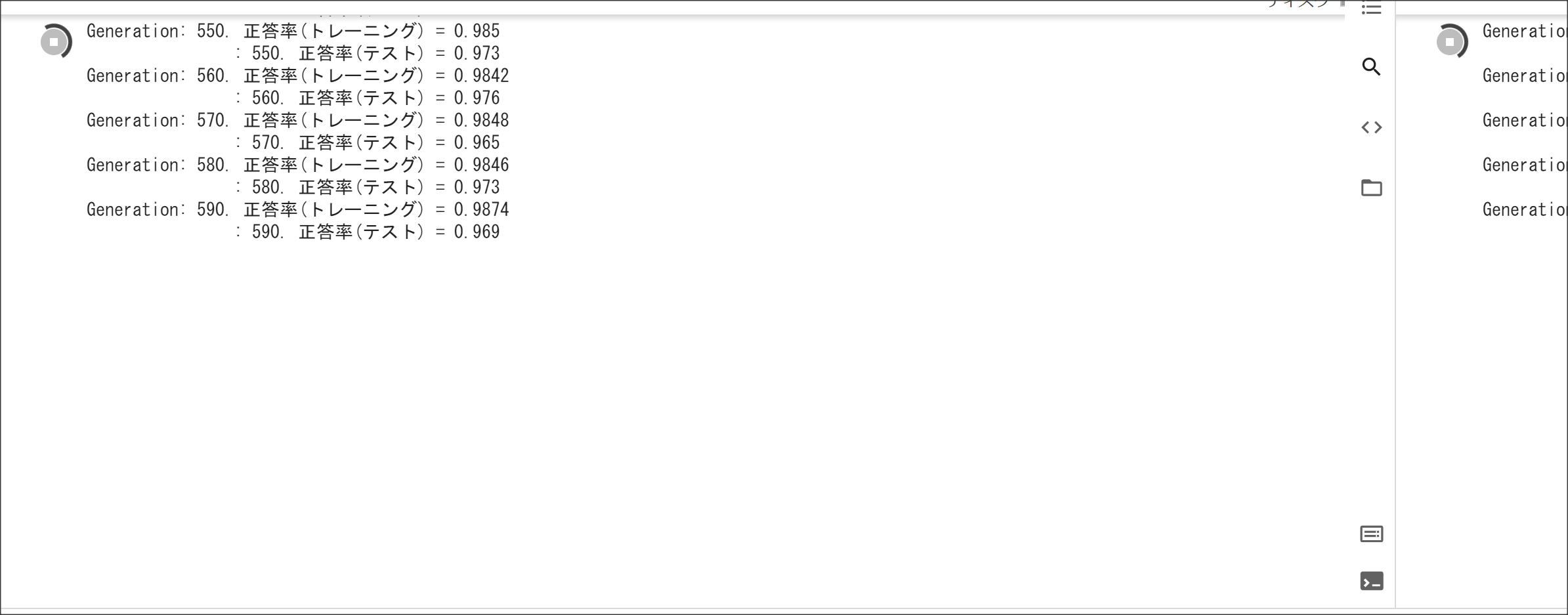
1_1_forward_propagation_after.ipynb







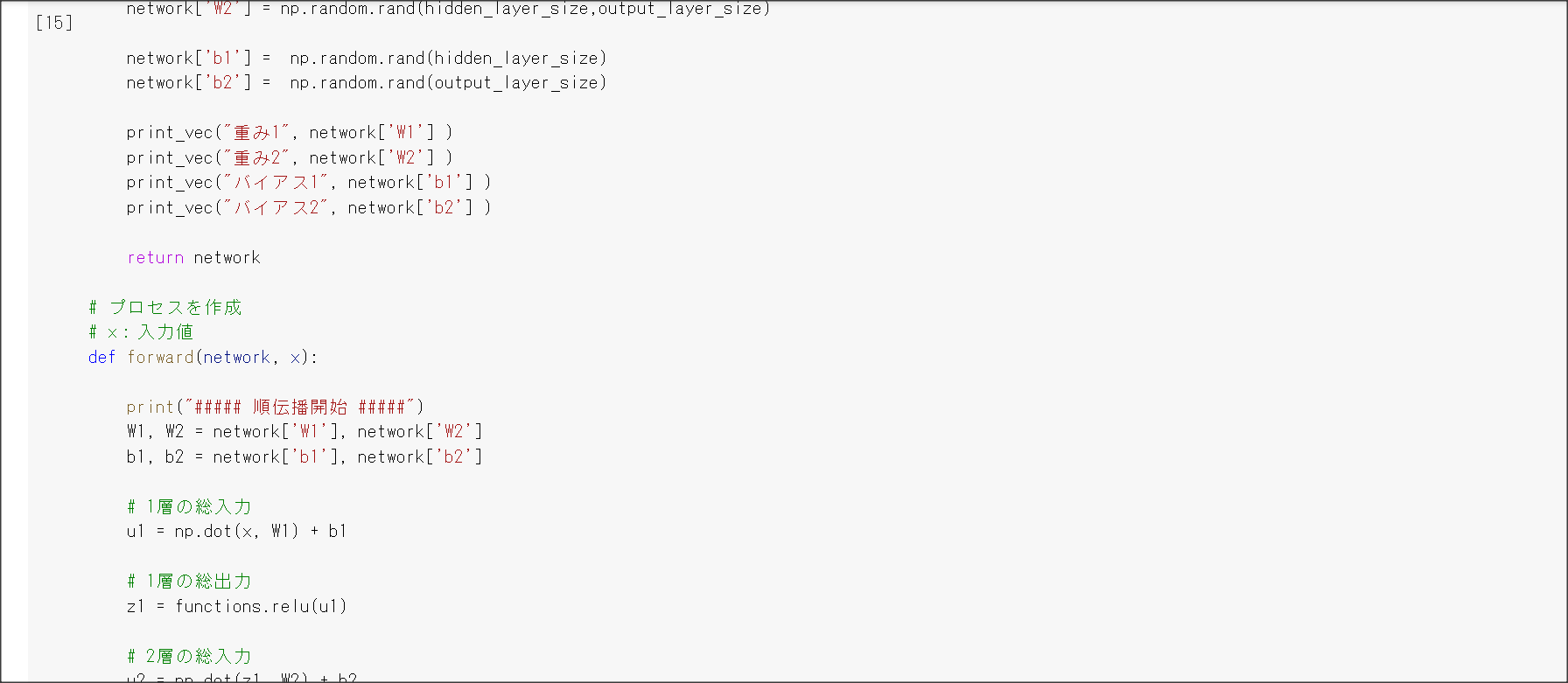

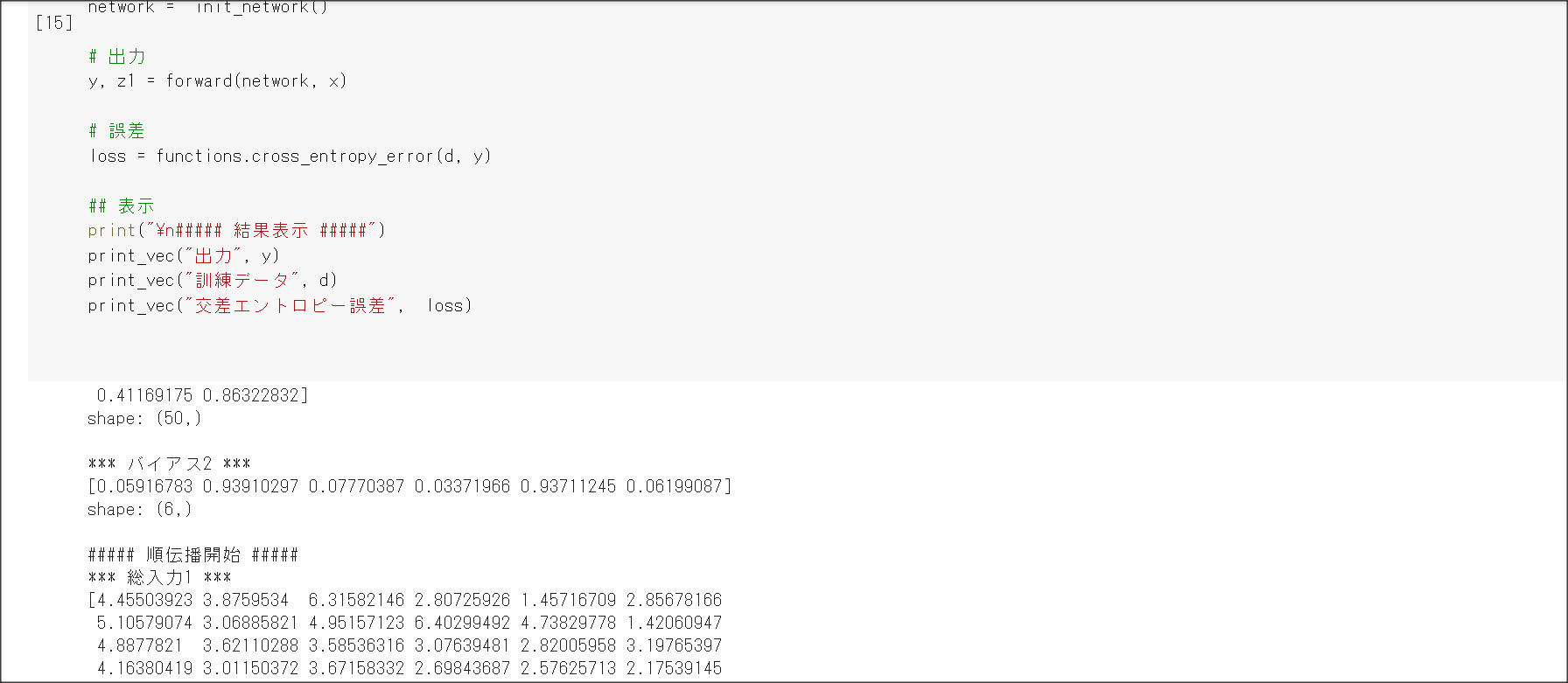
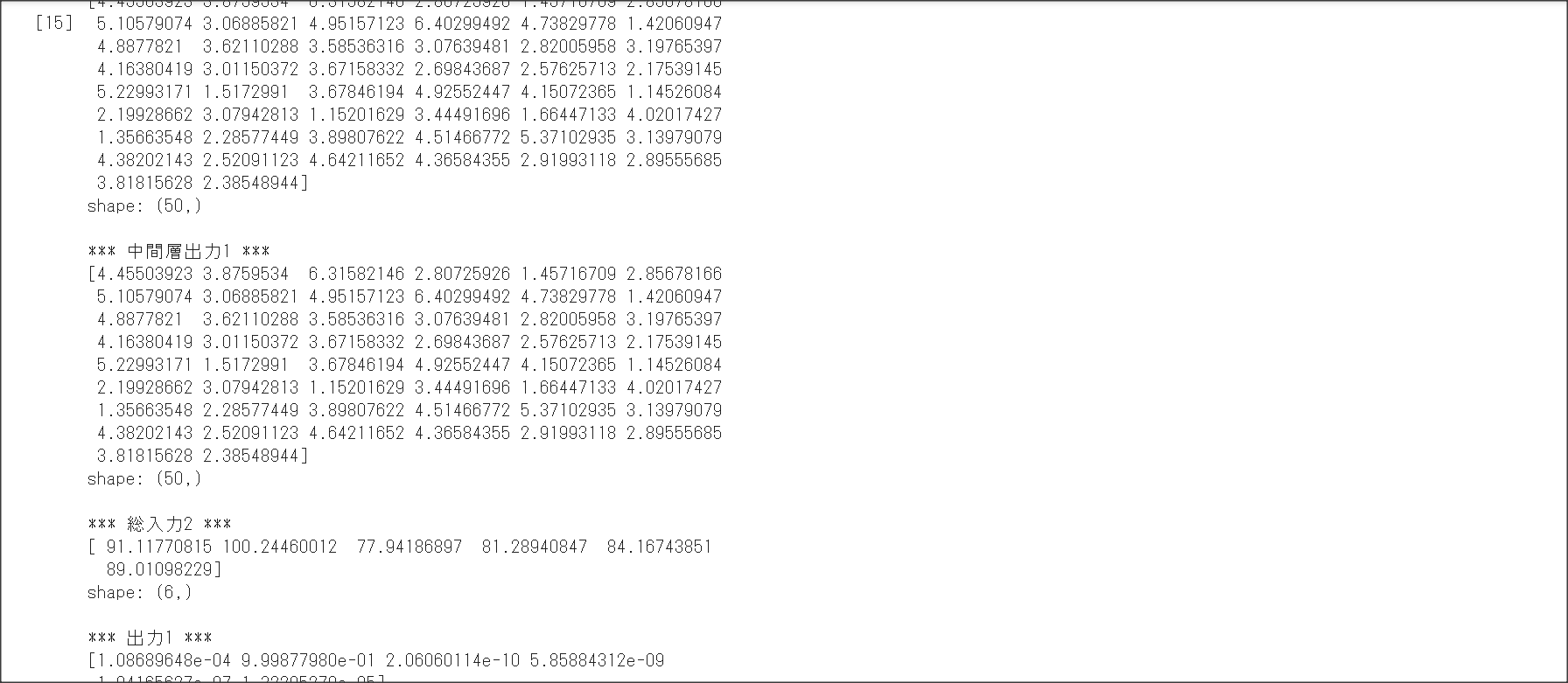
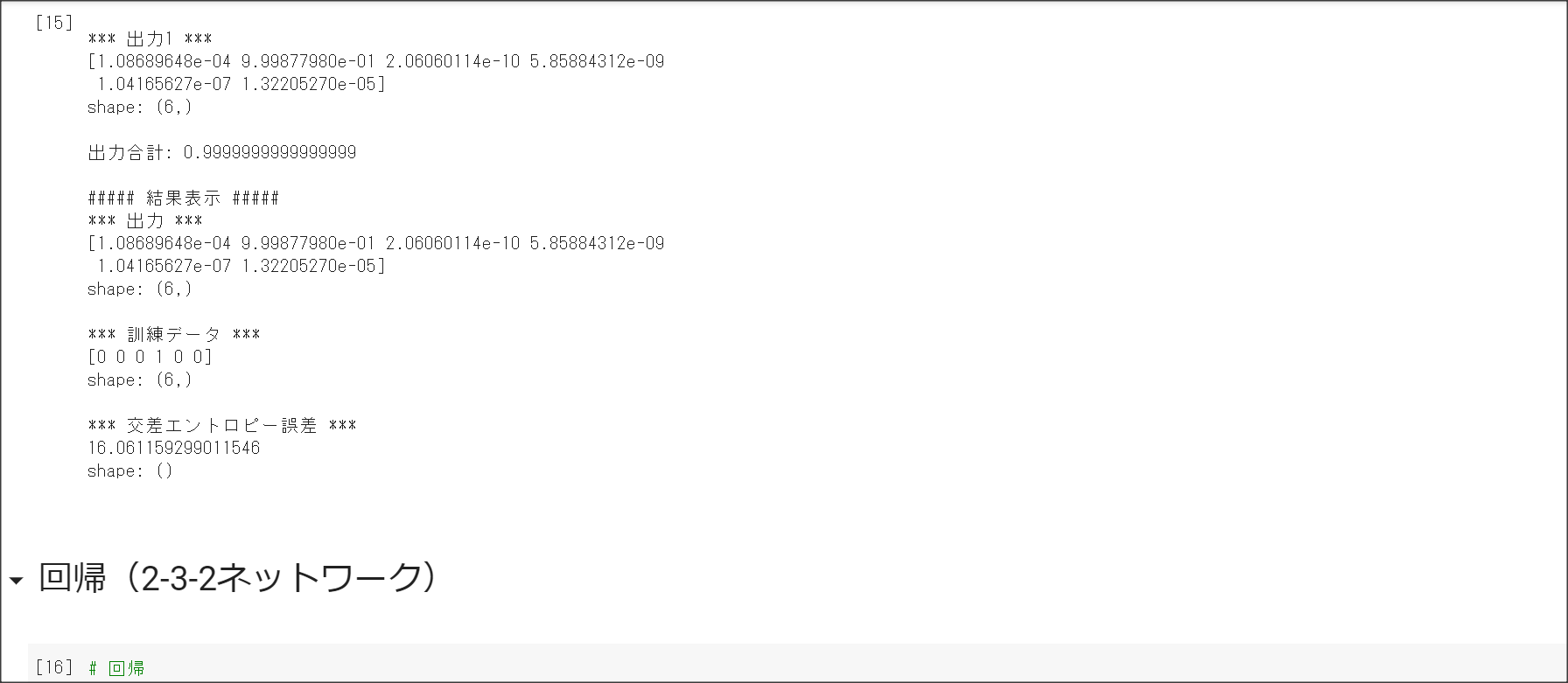
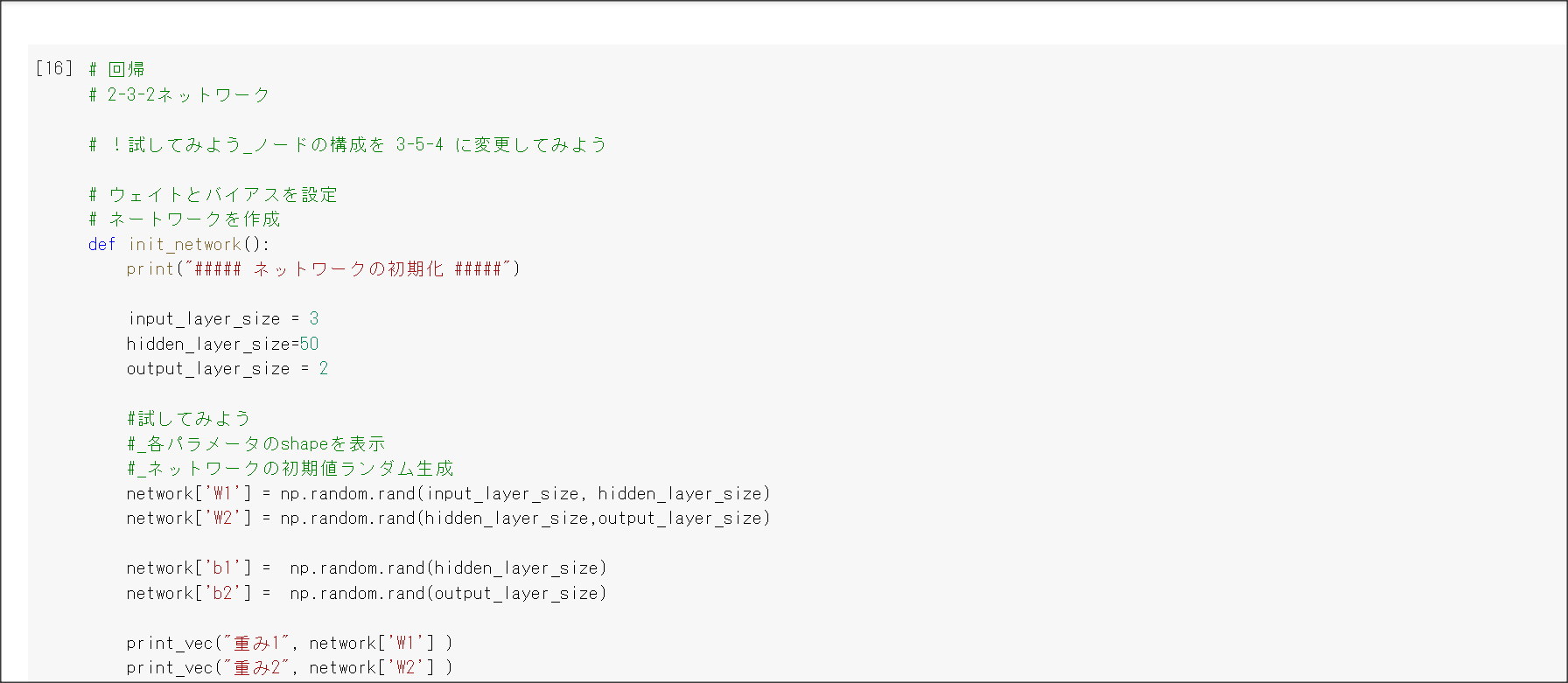

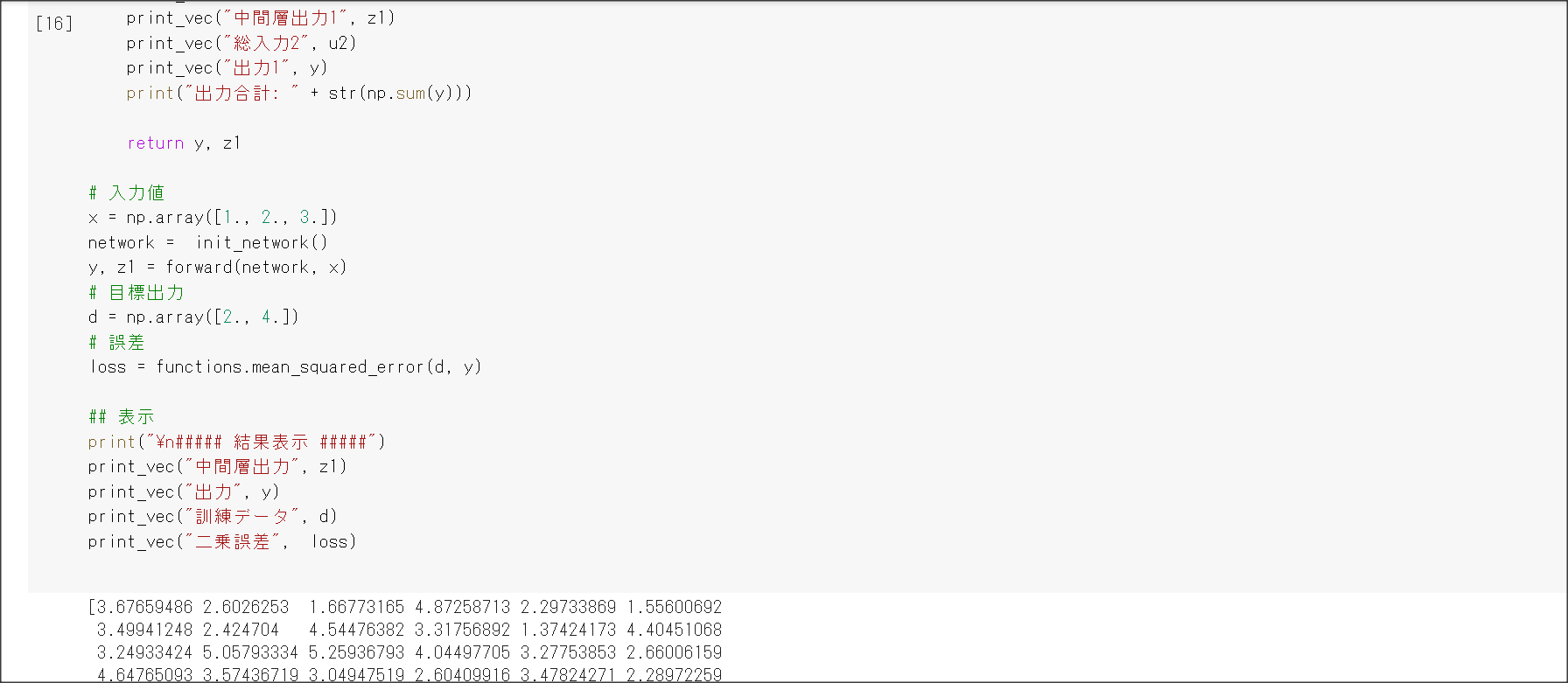
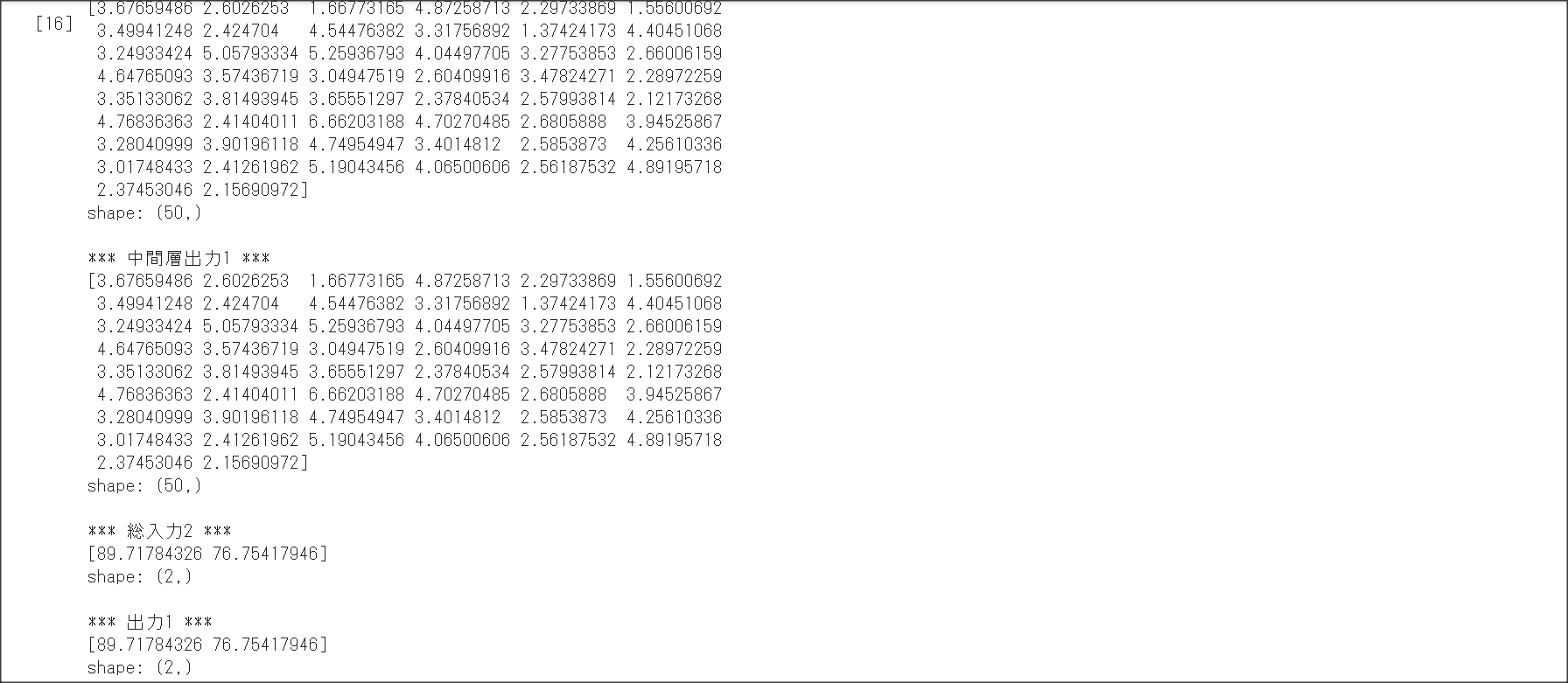


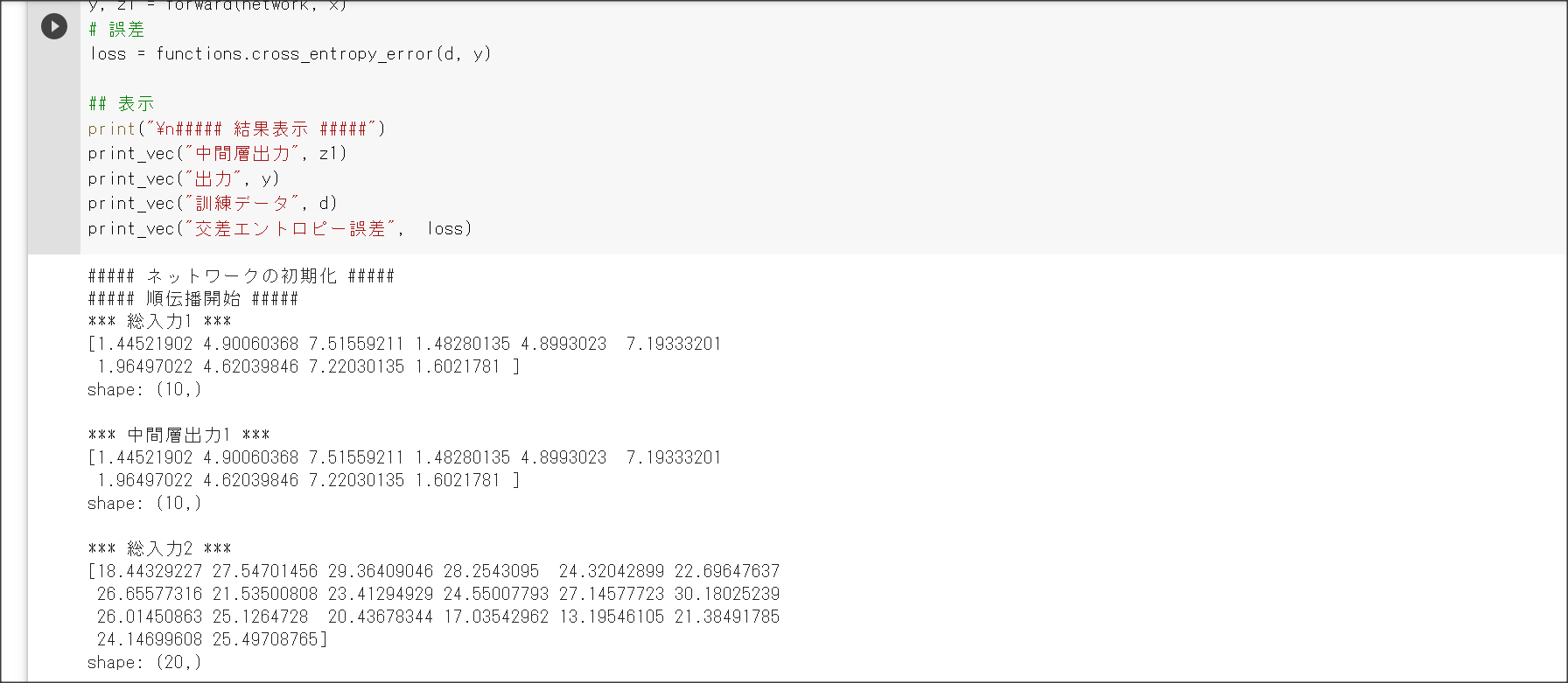
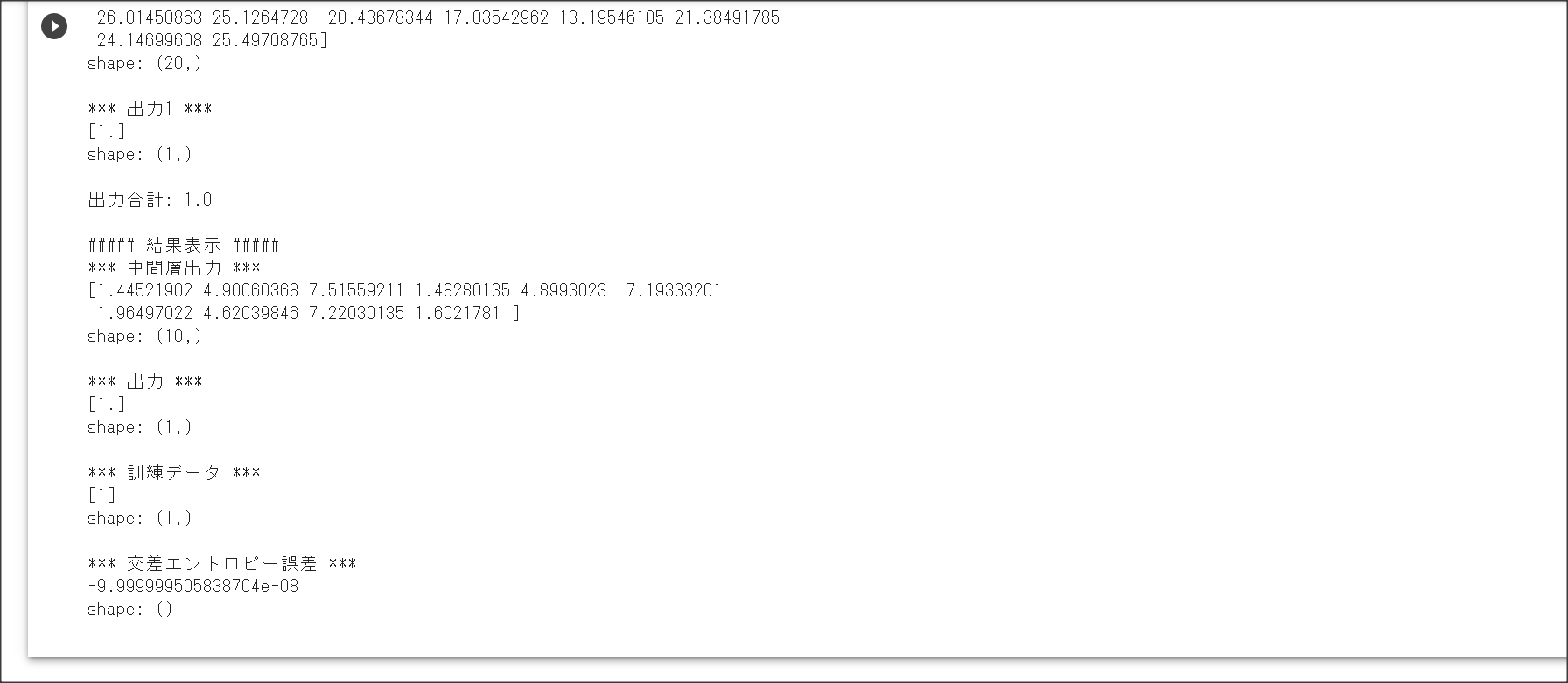
1_1_forward_propagation.ipynb





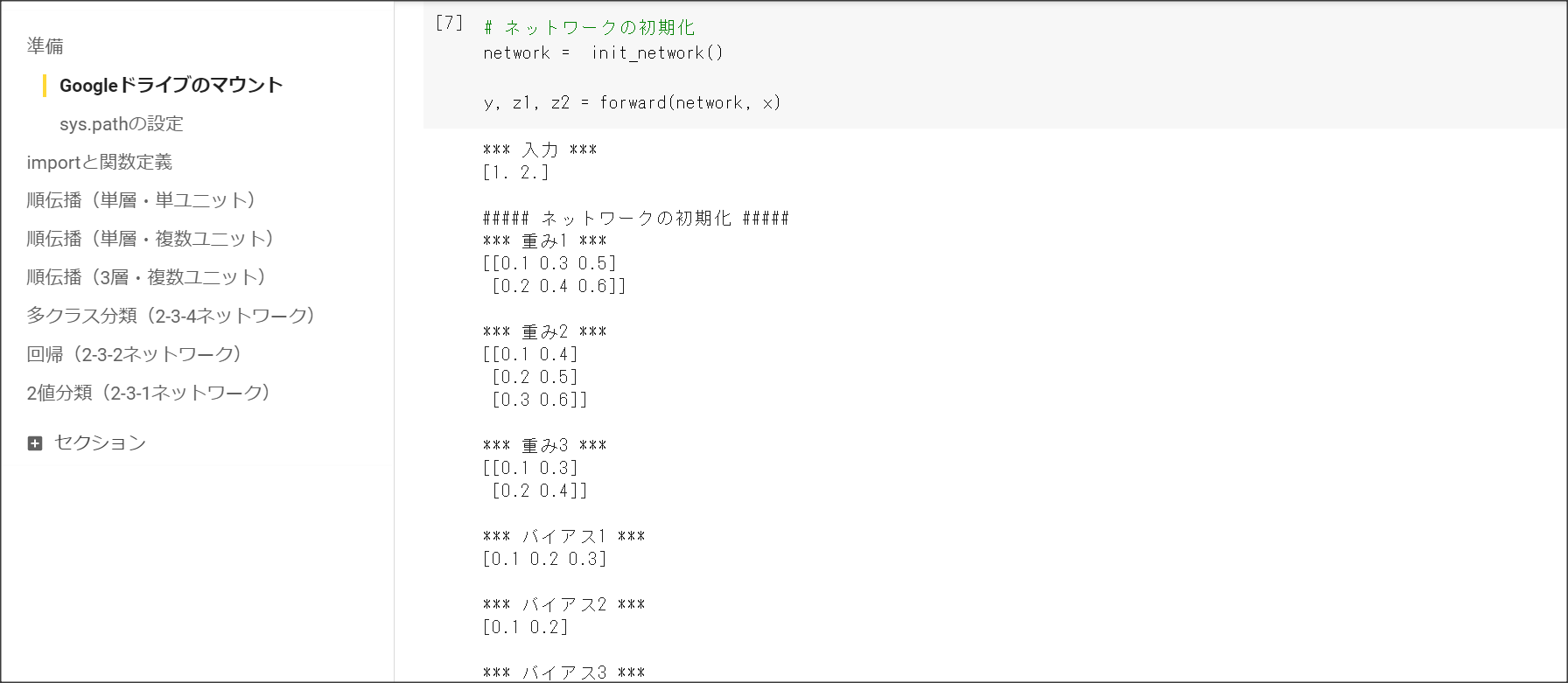






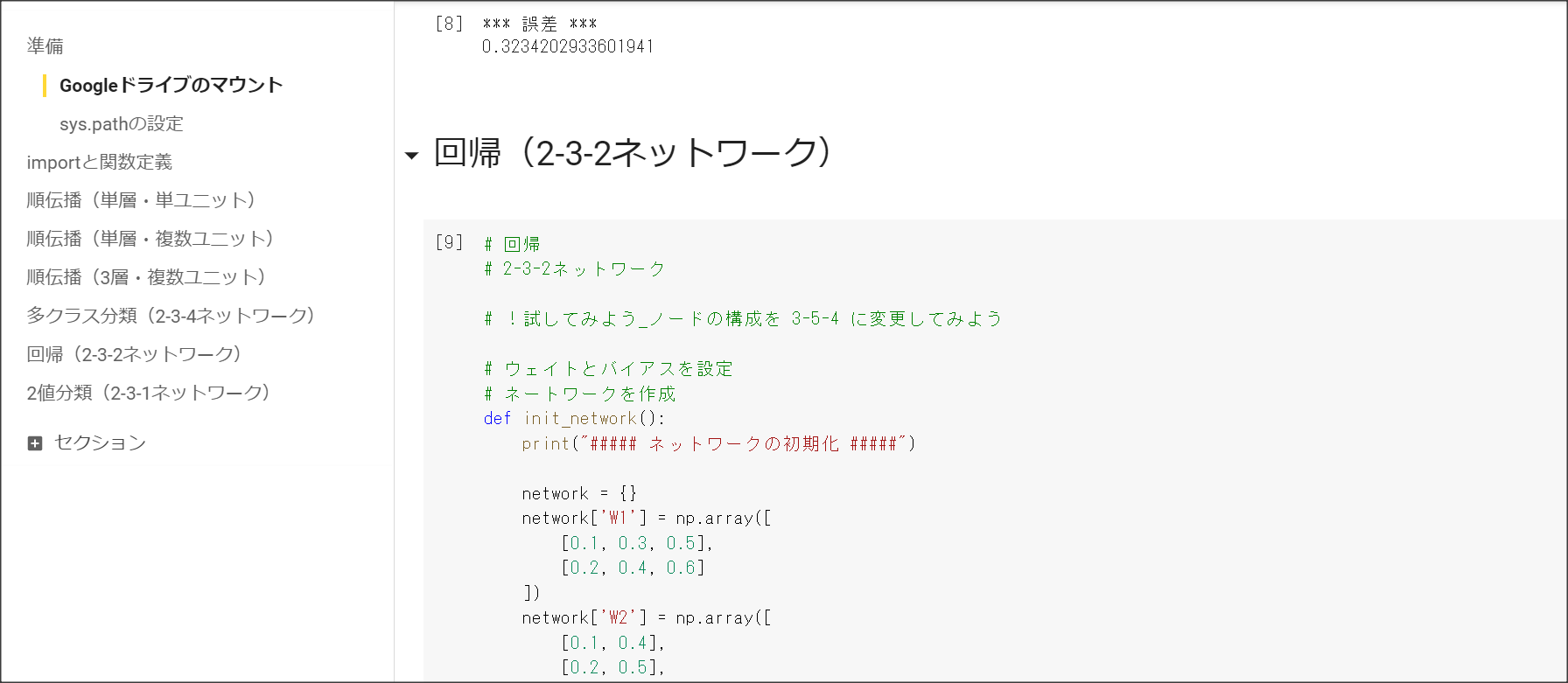




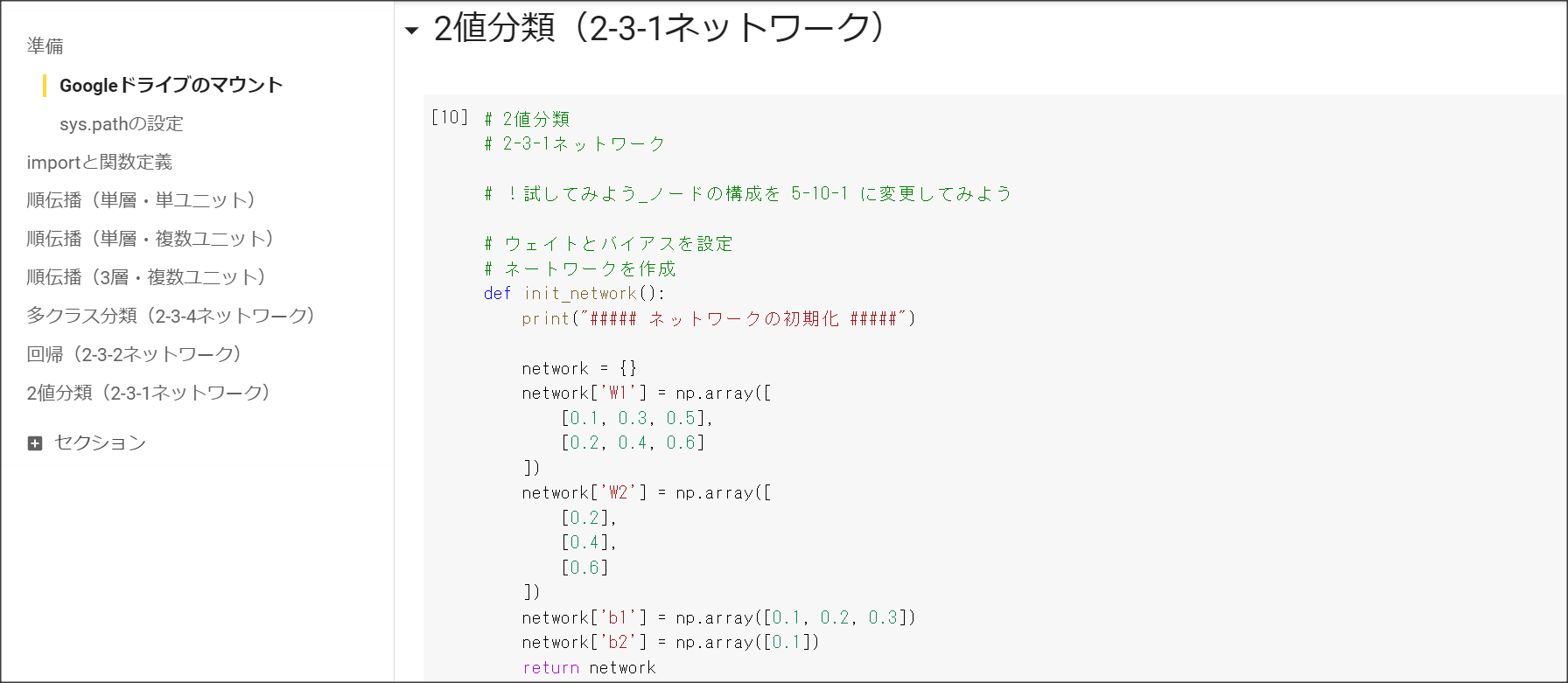

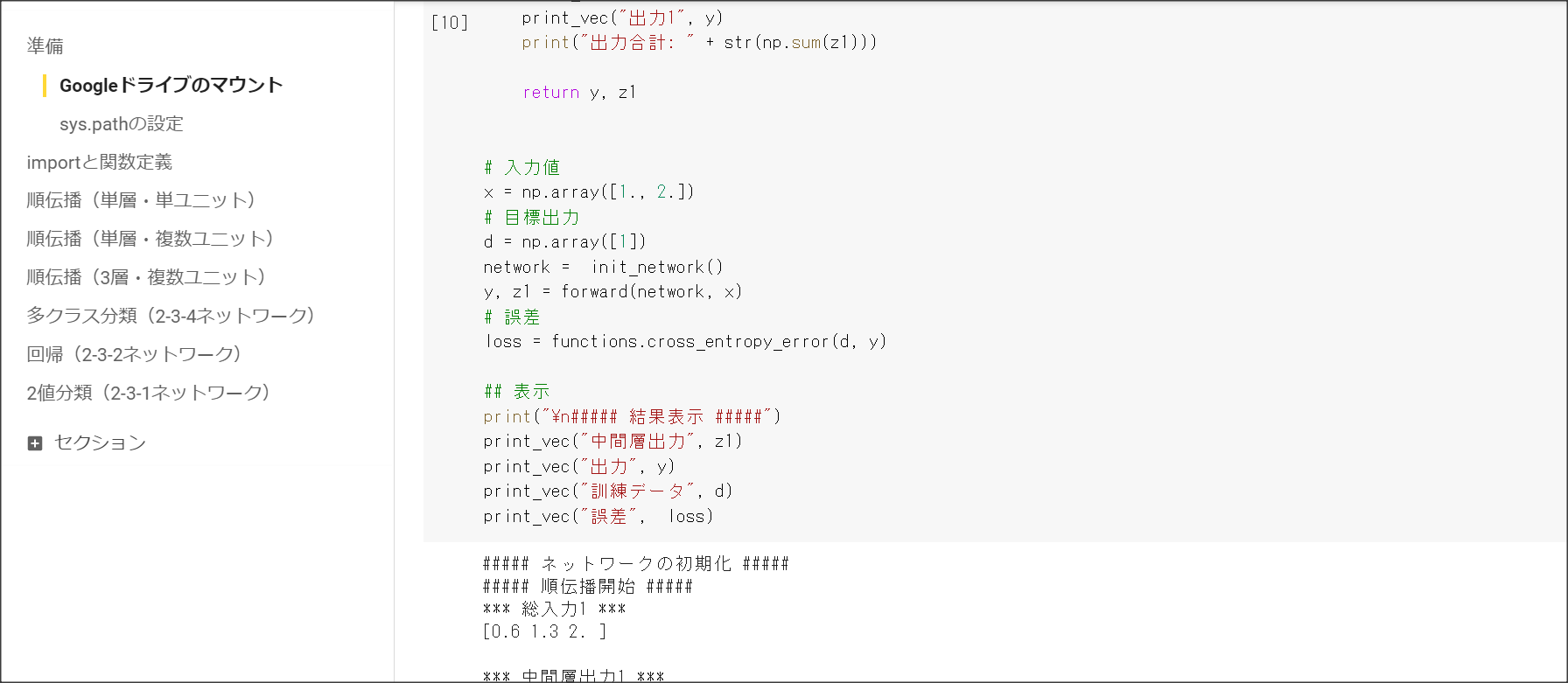
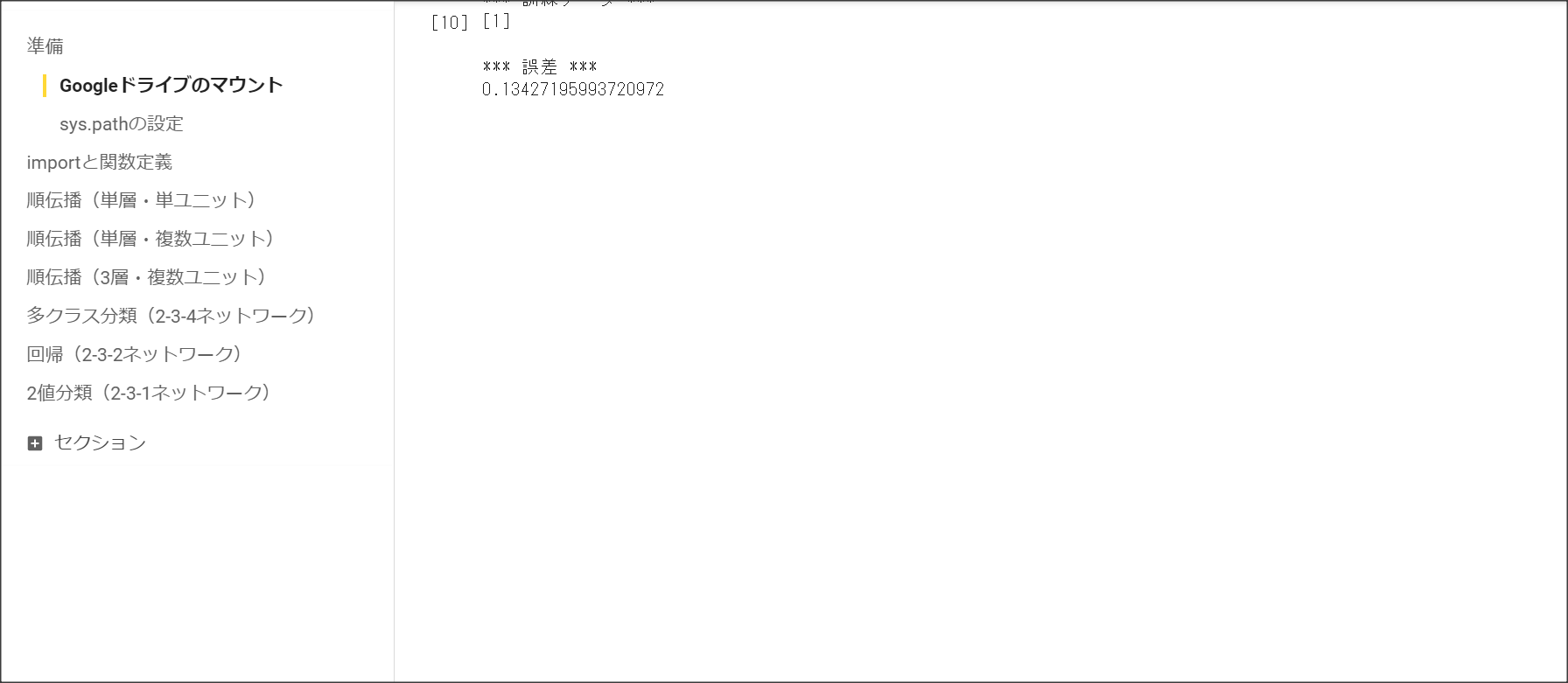
1_2_back_propagation.ipynb






1_3_stochastic_gradient_descent.ipynb





1_4_1_mnist_sample.ipynb
MNISTのデータをダウンロードするコードで、HTTP Error 503: Service Unavailableが出て学習できない。
実装演習結果としては問題ないと判断し、画面キャプチャは割愛。

[Days2]
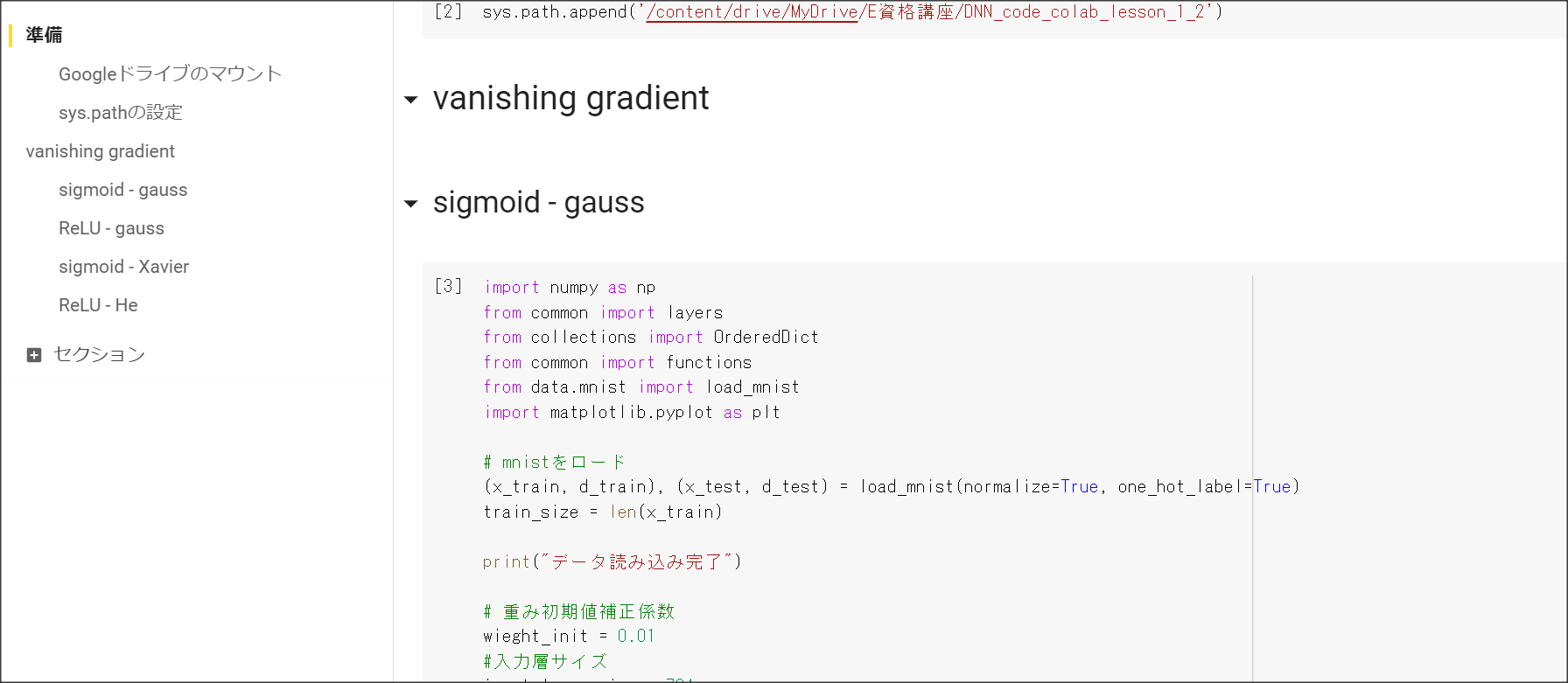
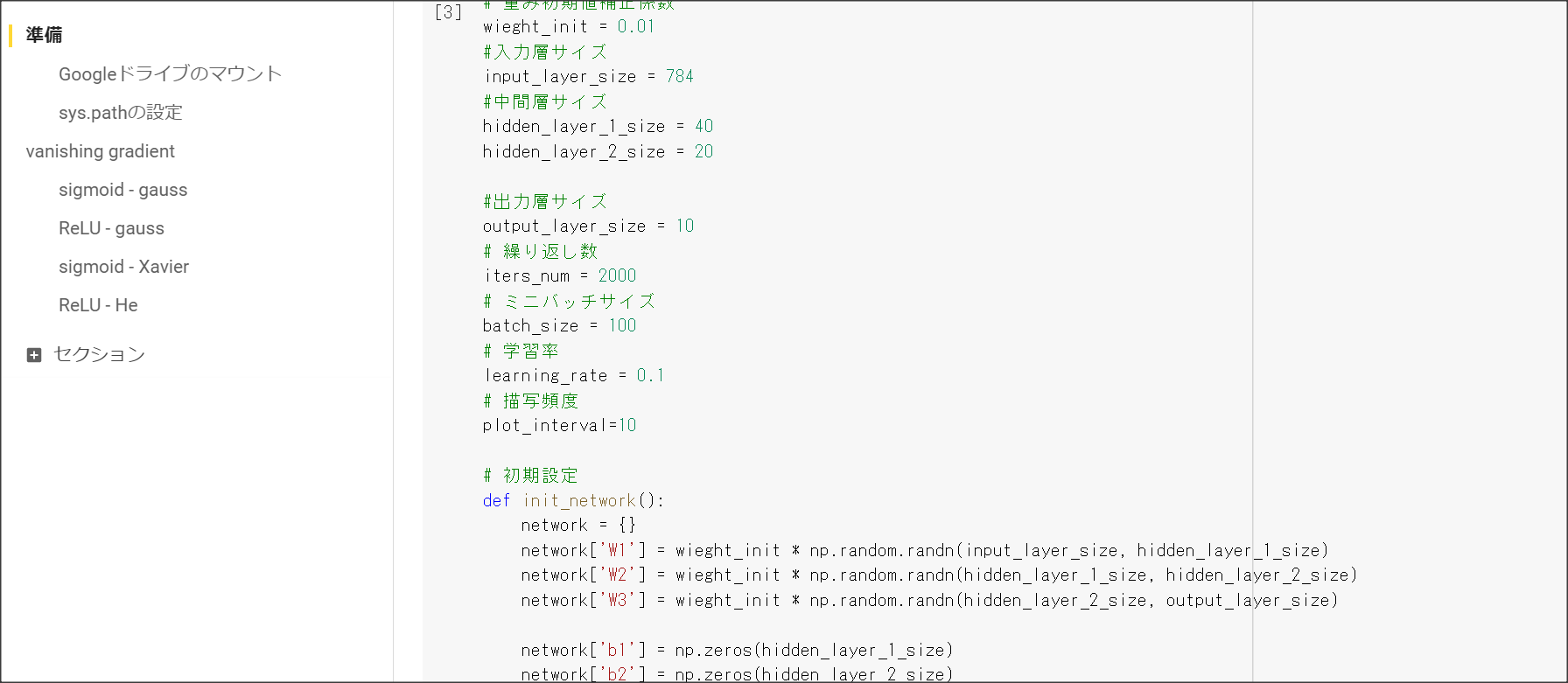
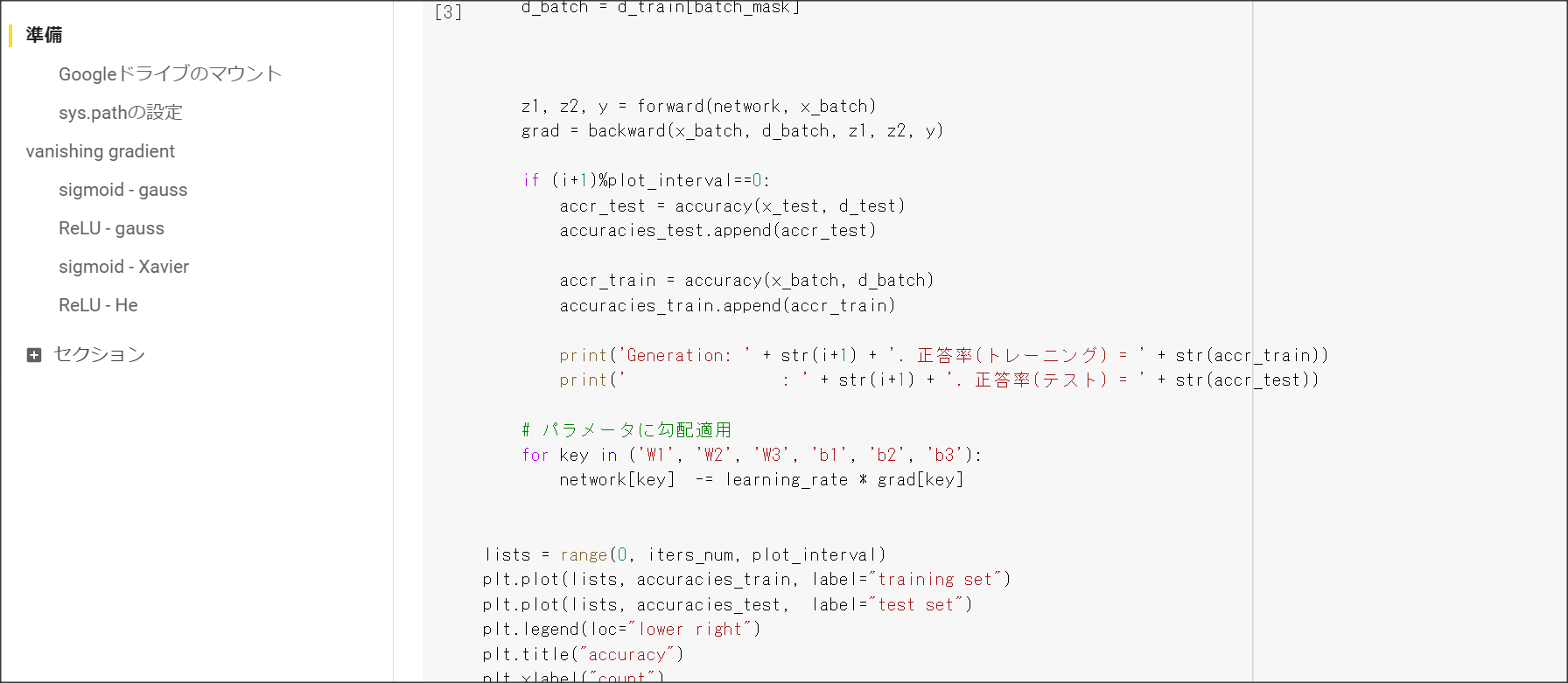
Section1 勾配消失問題
1点100字以上で要点のまとめ
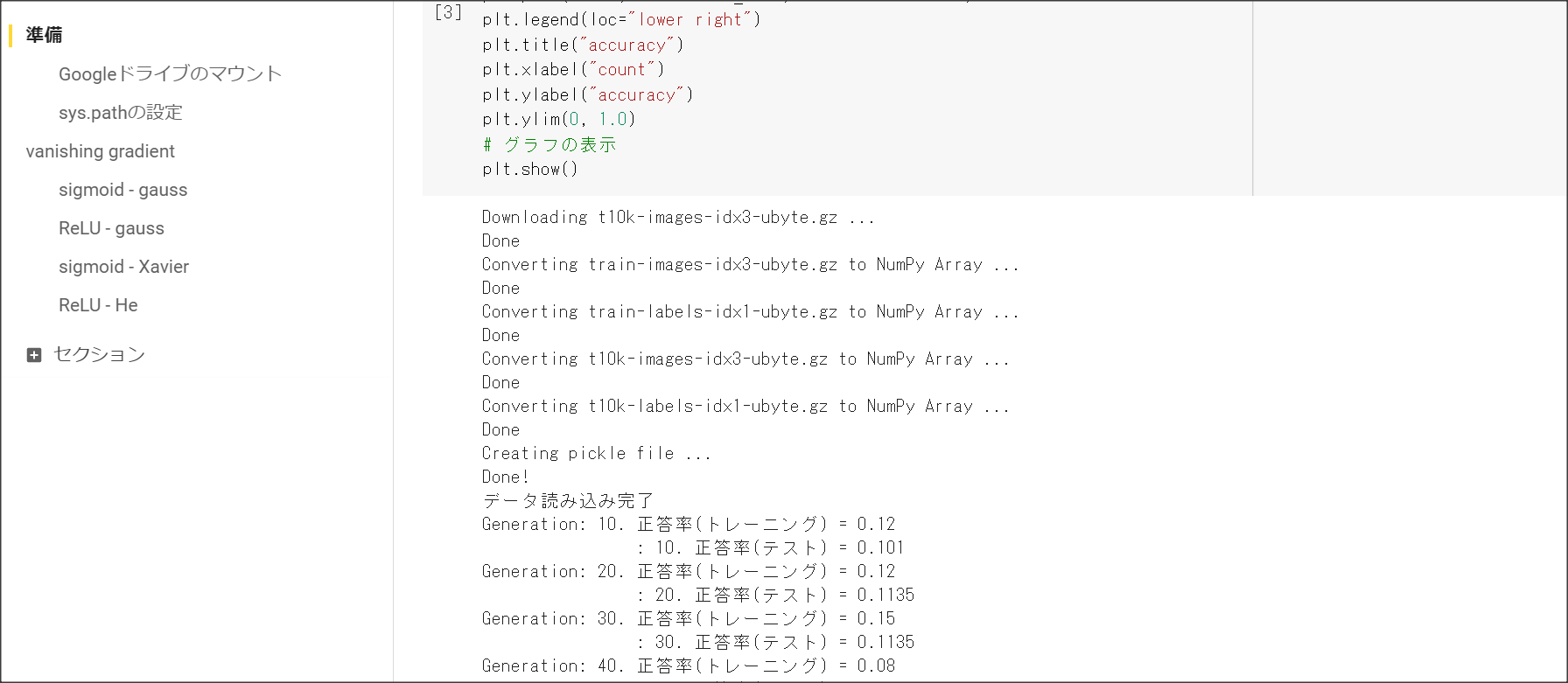
勾配消失問題とは、層が深い場合に、誤差逆伝搬法で、手前の関数の微分の勾配が小さいと、
勾配が消失していき、層が手前の方が学習しなくなってしまう問題を表す。
シグモイド関数の微分の絶対値の最大は0.25のため、層が深くなると勾配が消失してしまう。
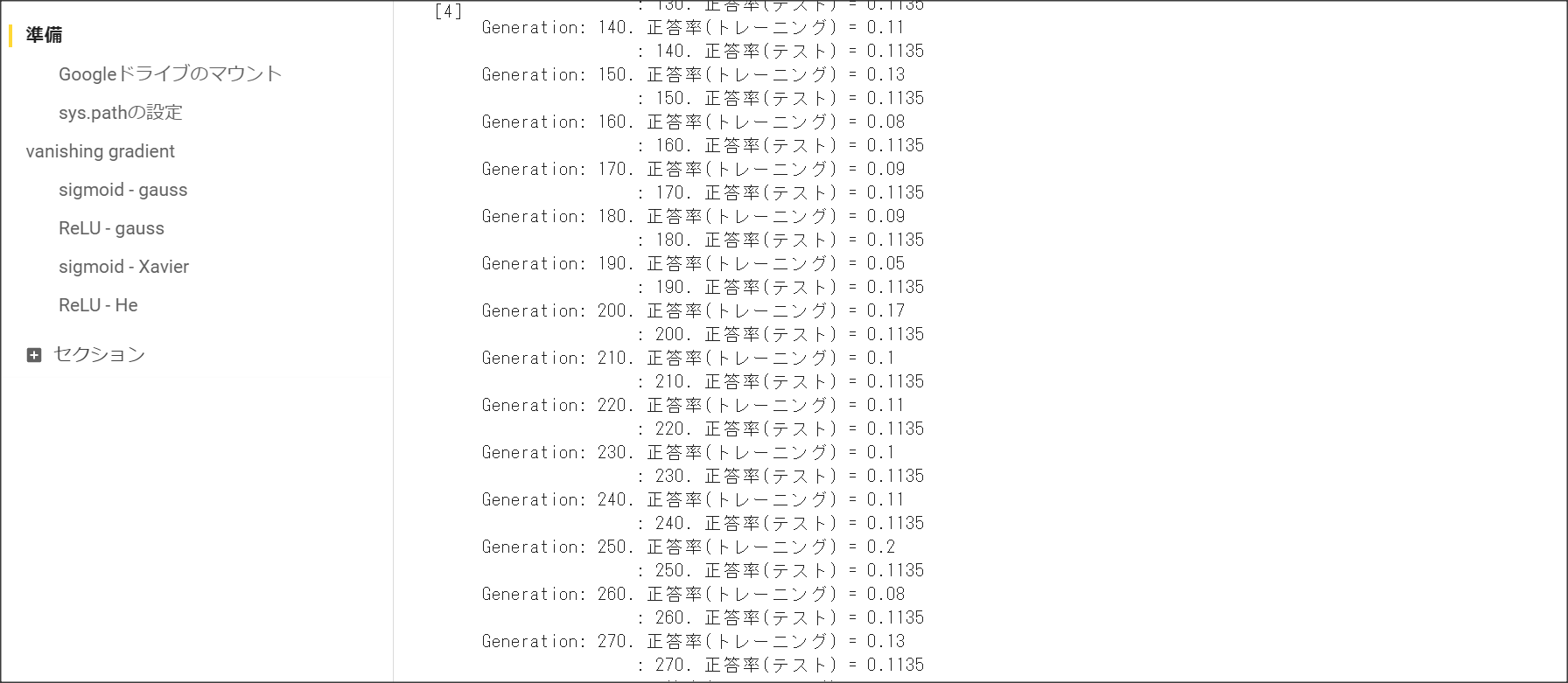
勾配消失問題に対応するには、活性化関数の選択、重みの工夫、バッチ正規化の3つの手法がある。
活性化関数の選択
ReLUを用いる。$f(x) = 0 (x < 0), f(x) = x ( x \ge 0)$
ReLUで勾配消失の問題とスパース化に対応。
重みの工夫
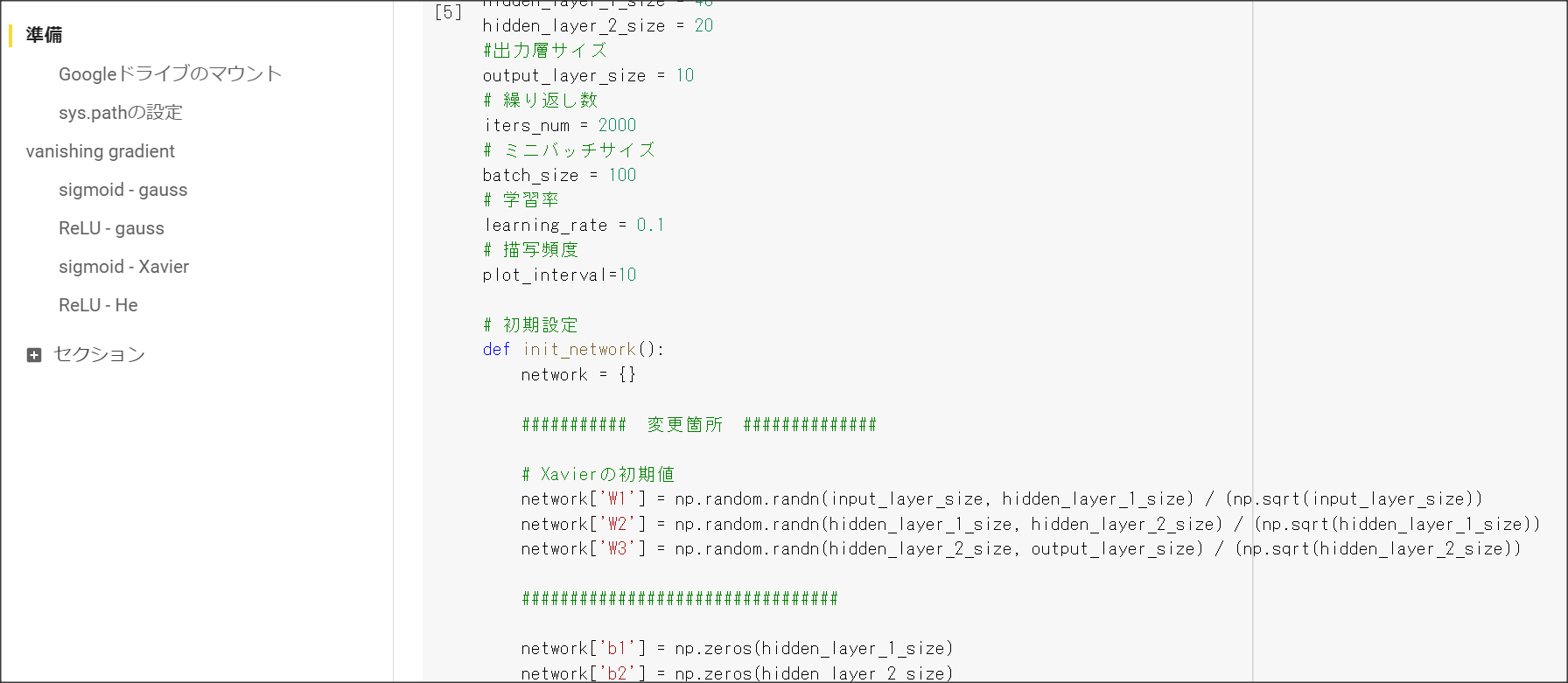
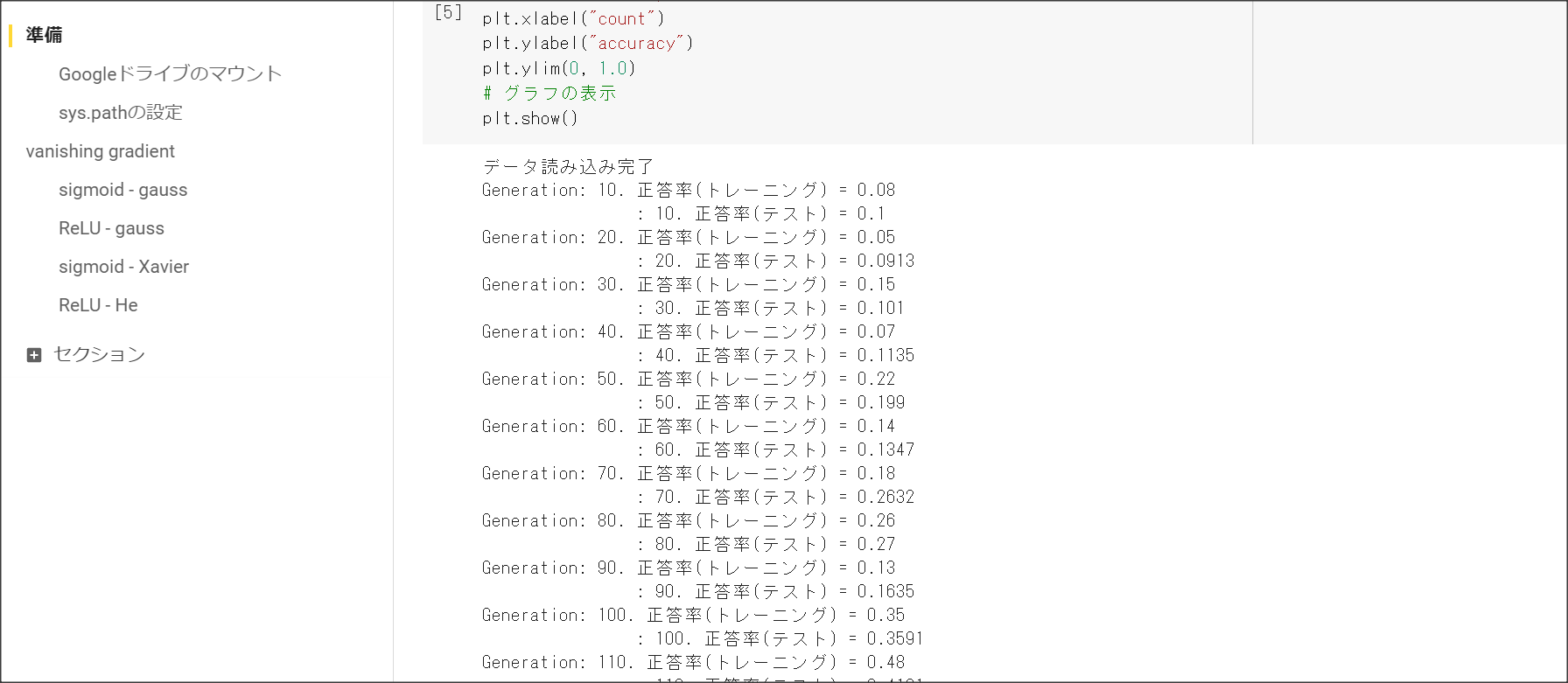
重みを初期化する際の工夫1:Xavier。
正規分布の乱数を前の層のノード数の平方根で割り重みを初期化する
重みを初期化する際の工夫2:He。
ReLUの場合に用いる。
正規分布の乱数を$\sqrt{\frac{2}{n}}$で求める。
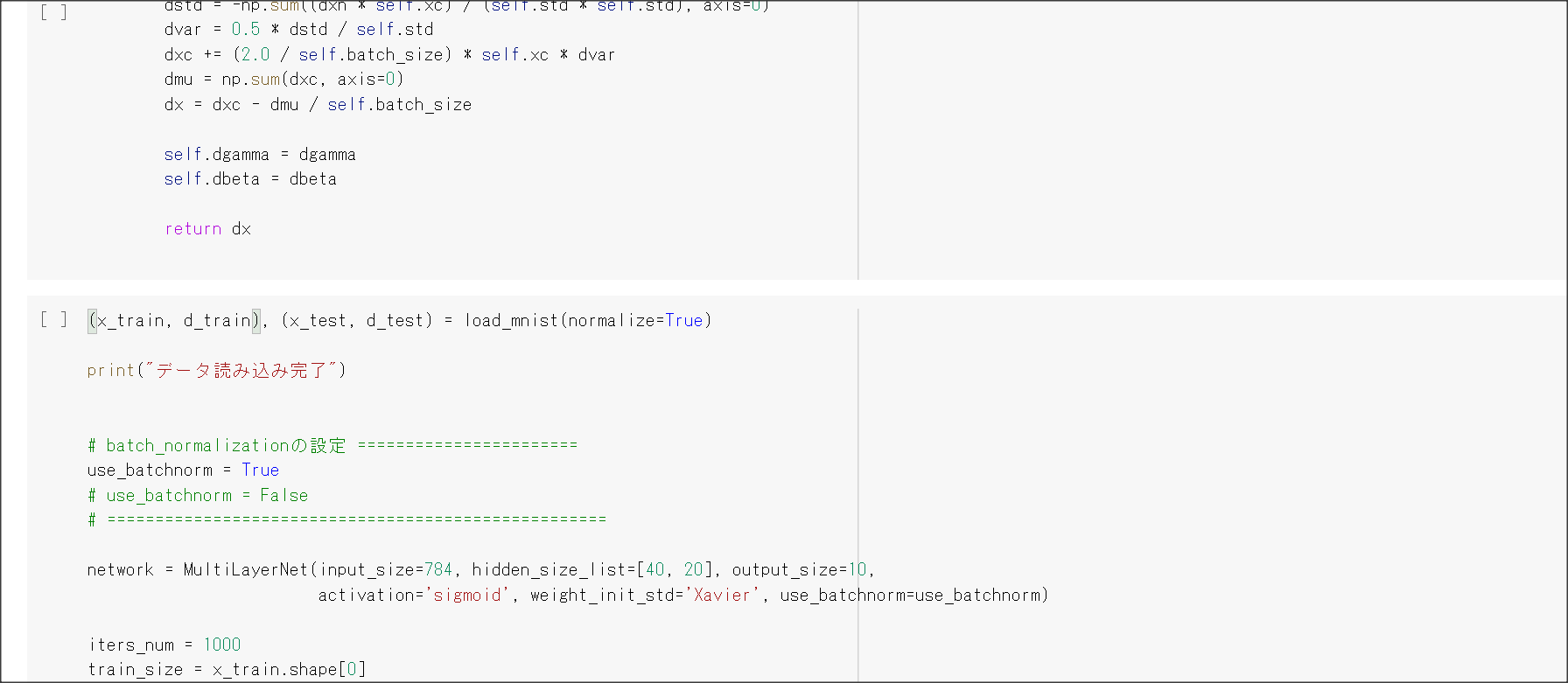
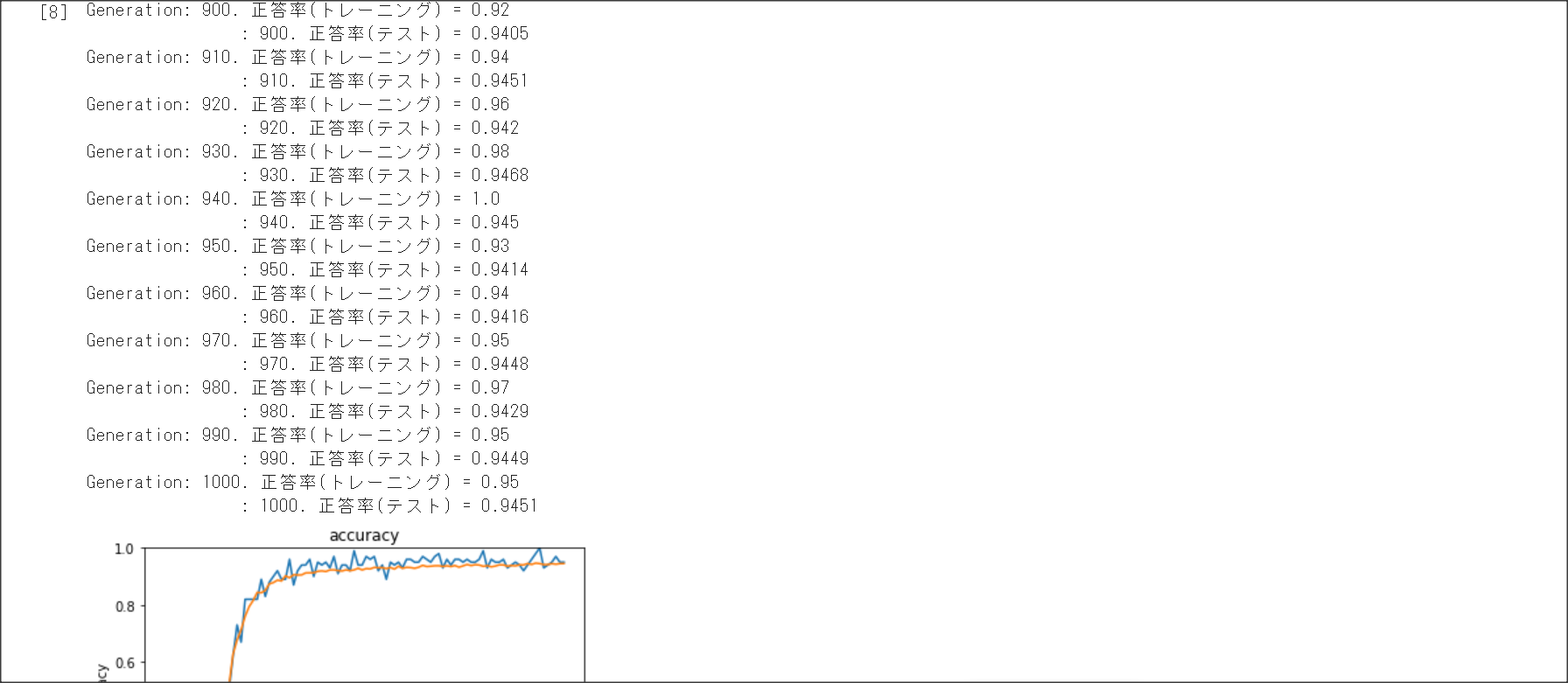
バッチ正規化
バッチ処理の入力で渡すデータの各チャネルへの入力データの分散を1に抑える手法のこと。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
シグモイド関数を微分の値の最大値は?
0.25となる。
全ての重みが0だとどうなるか
全部0だと出力が0となり勾配損失が発生し学習が進まなくなる。
演習問題や参考図書、修了課題など関連記事レポート
Xavier : なぜ√を取る?⇒分散が変わらないようにするため。
出力する分散値が変わらないようにするためには、√をかけてやると良い。
今、$X$を正規分布とすると、$V((\sum^n{X})/\sqrt{n})$ $n * V(X) * \frac{1}{\sqrt{n}^2} = V(X)$
となる。
Section2 学習最適化手法
1点100字以上で要点のまとめ
モメンタム
$V_i = \mu * V_{i-1} - \nabla E$
$w^{(i+1)} = w^{(i)} + V_i$
AdaGrad
$h_0 = \theta$
$h_t = h_{t-1} + (\nabla E)^2$
$w^{(t+1)} = w^{(t)} - \epsilon \frac{1}{\sqrt{h_t} + \theta}\nabla E$
RMSProp
ADAGradを改良したもの。

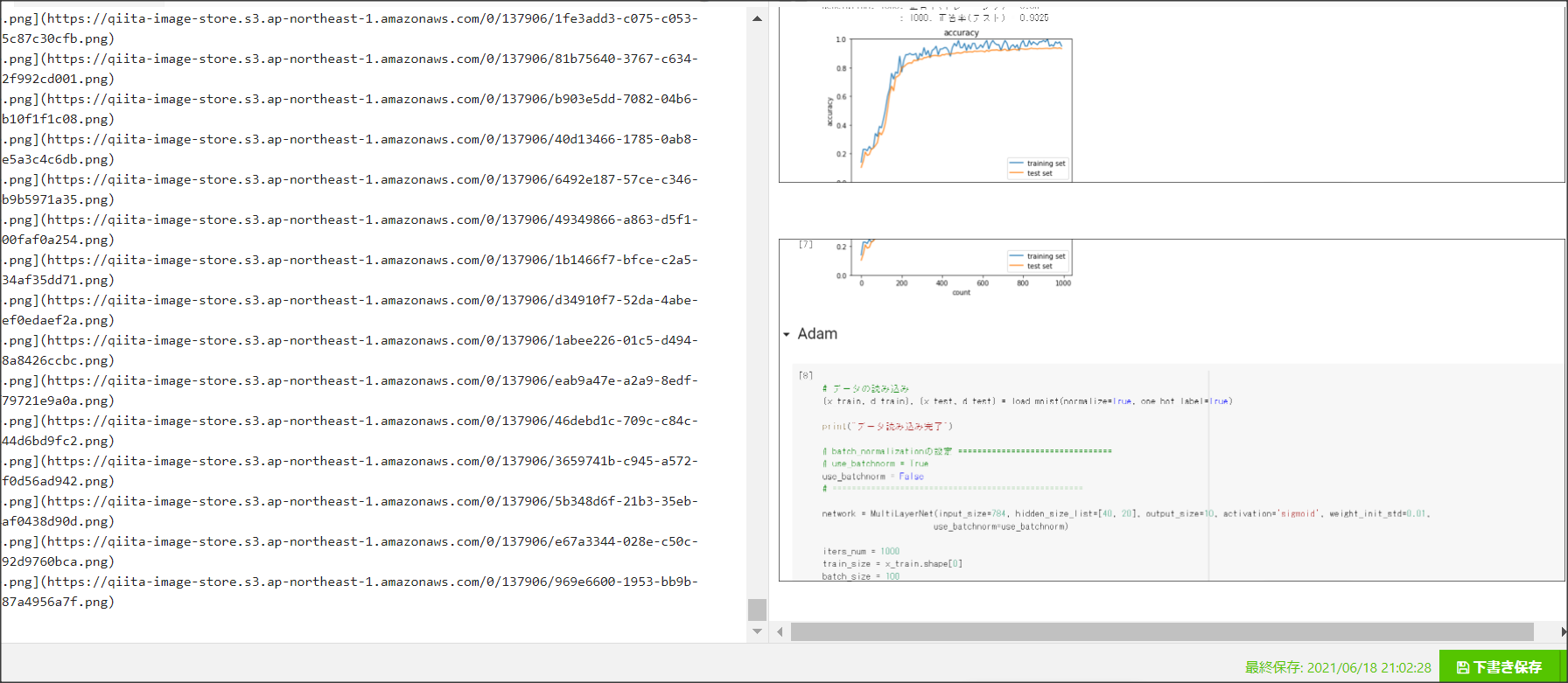
Adam
RMSPropとモメンタムのいいところを取り入れたアルゴリズム
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
確認テストは特になし。
演習問題や参考図書、修了課題など関連記事レポート
Section3 過学習
1点100字以上で要点のまとめ
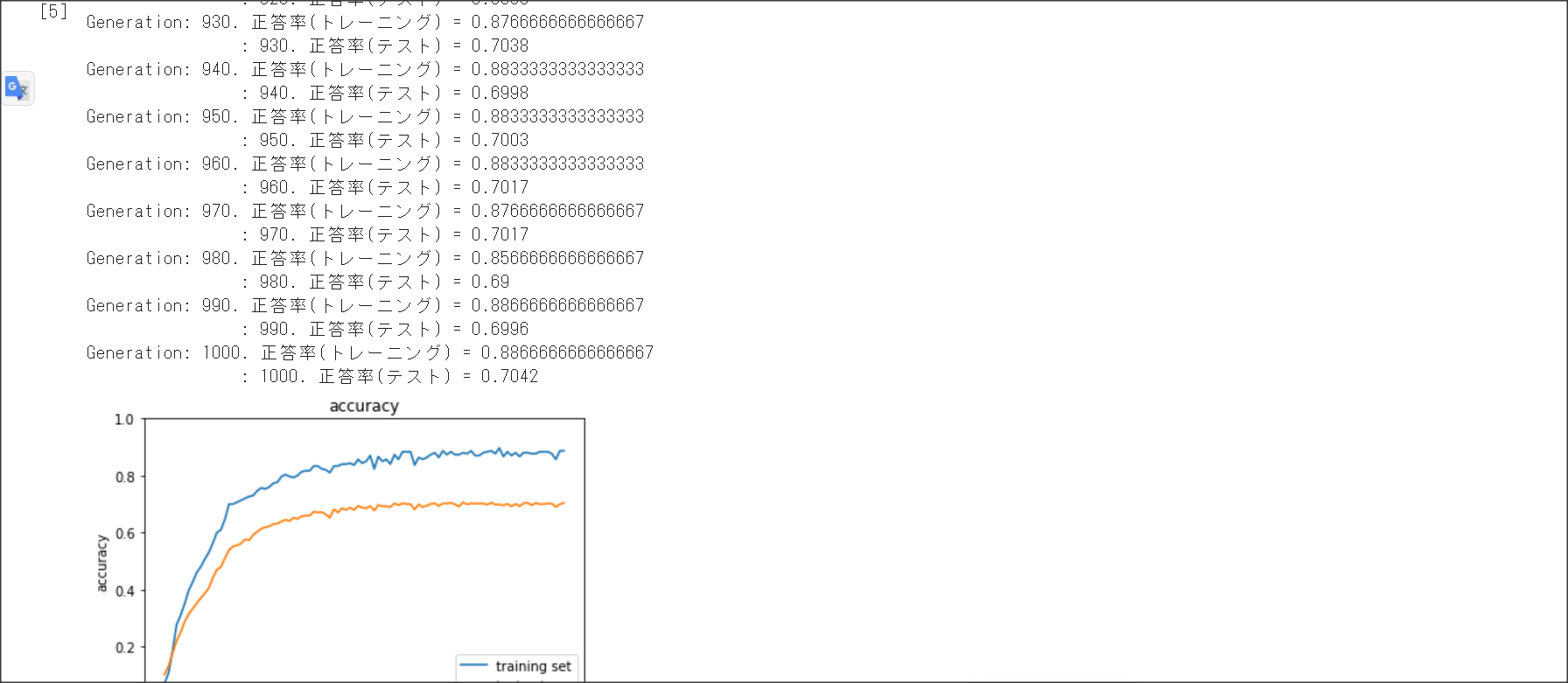
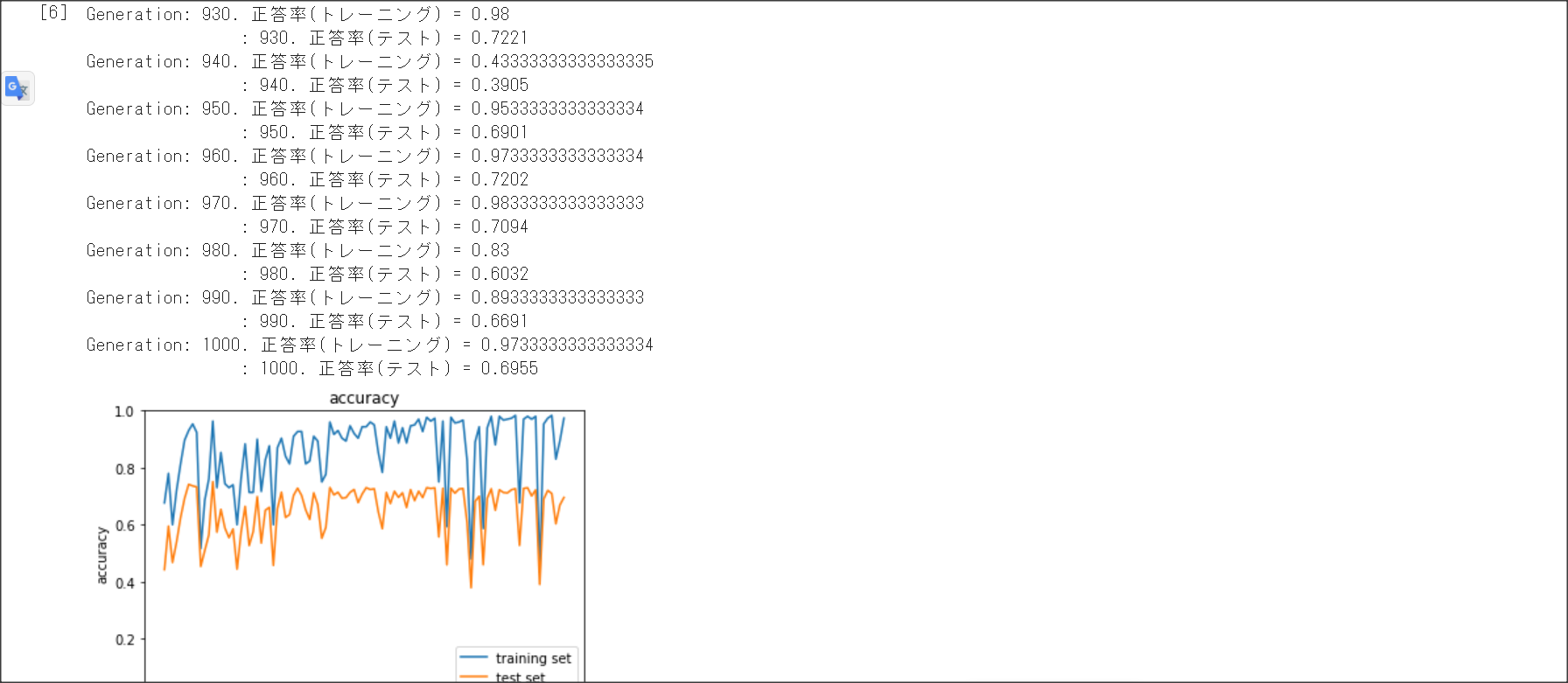
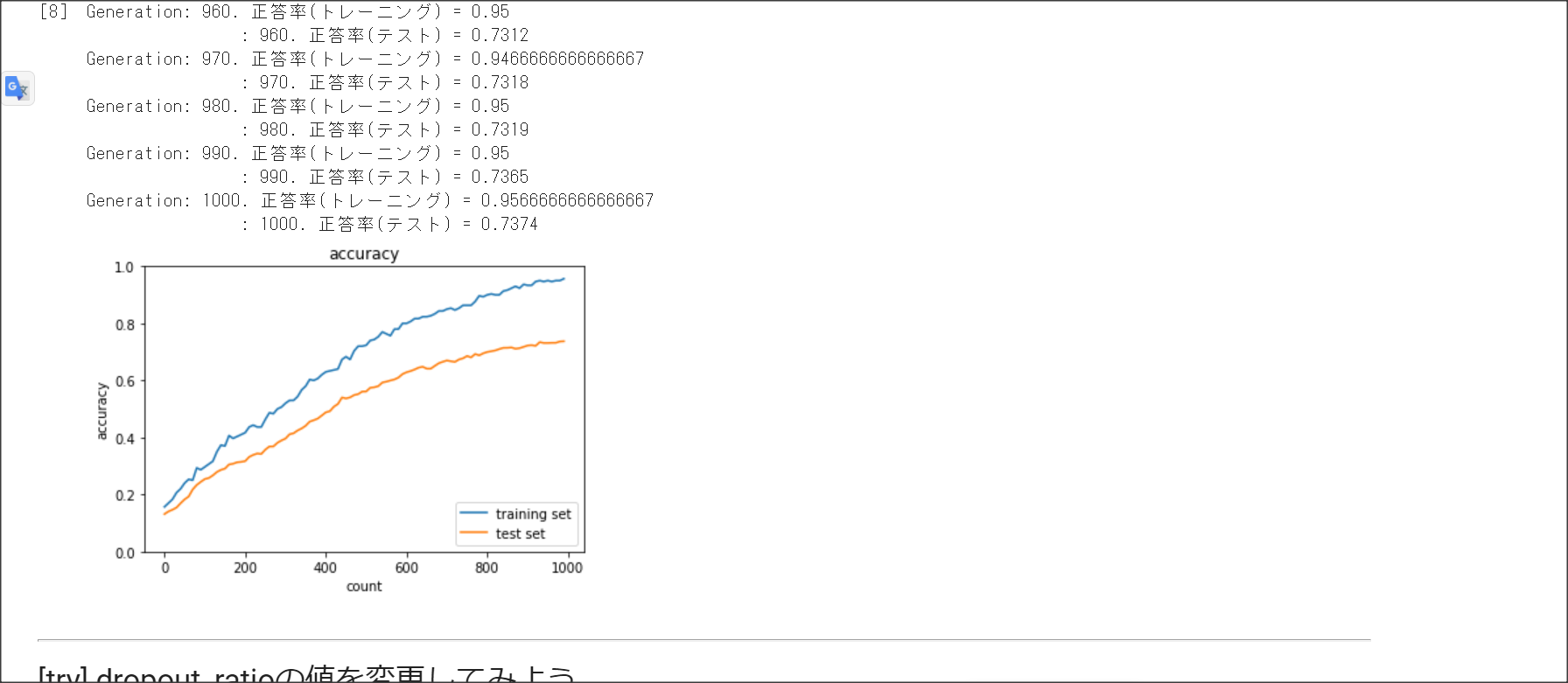
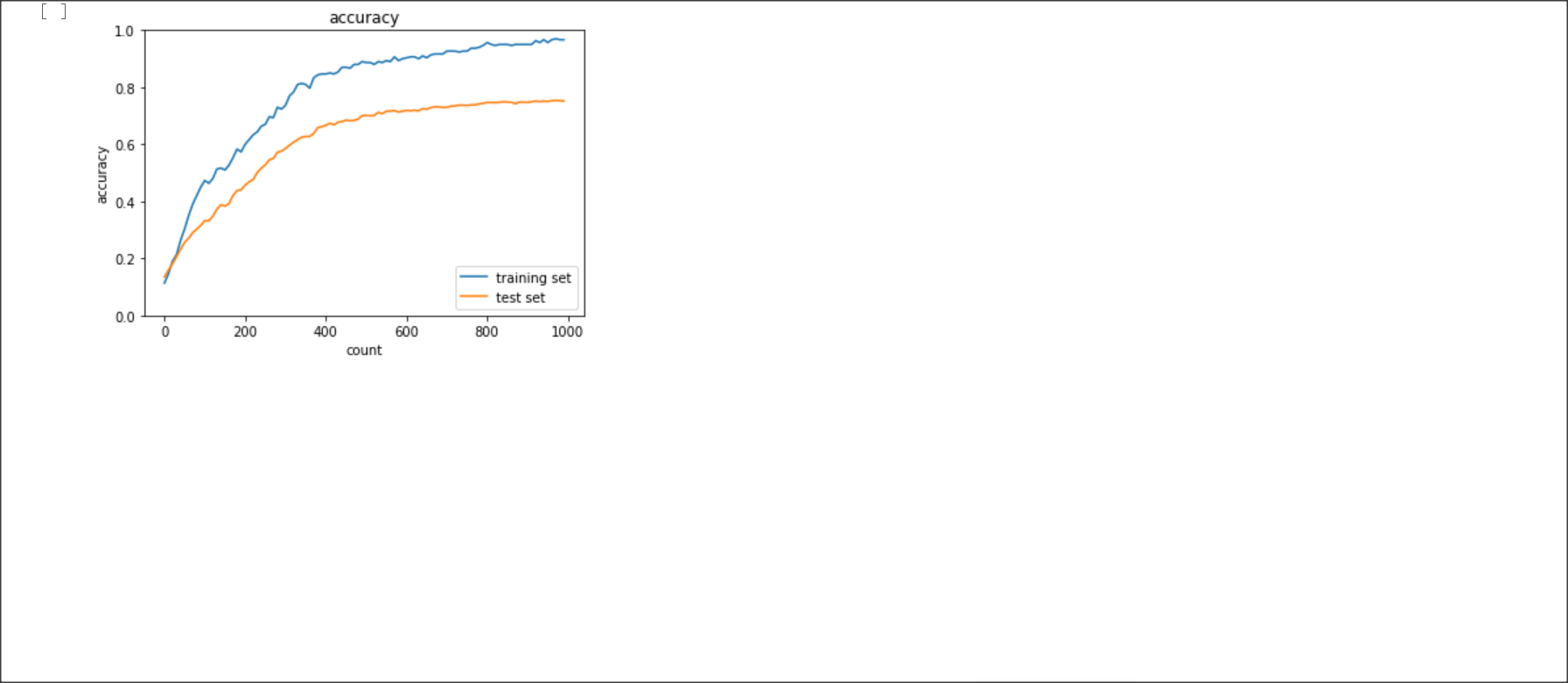
学習データと検証データで正解率に乖離があることを過学習という。過学習の原因はネットワークの自由度が高いこと
なので、それを対策することが必要。
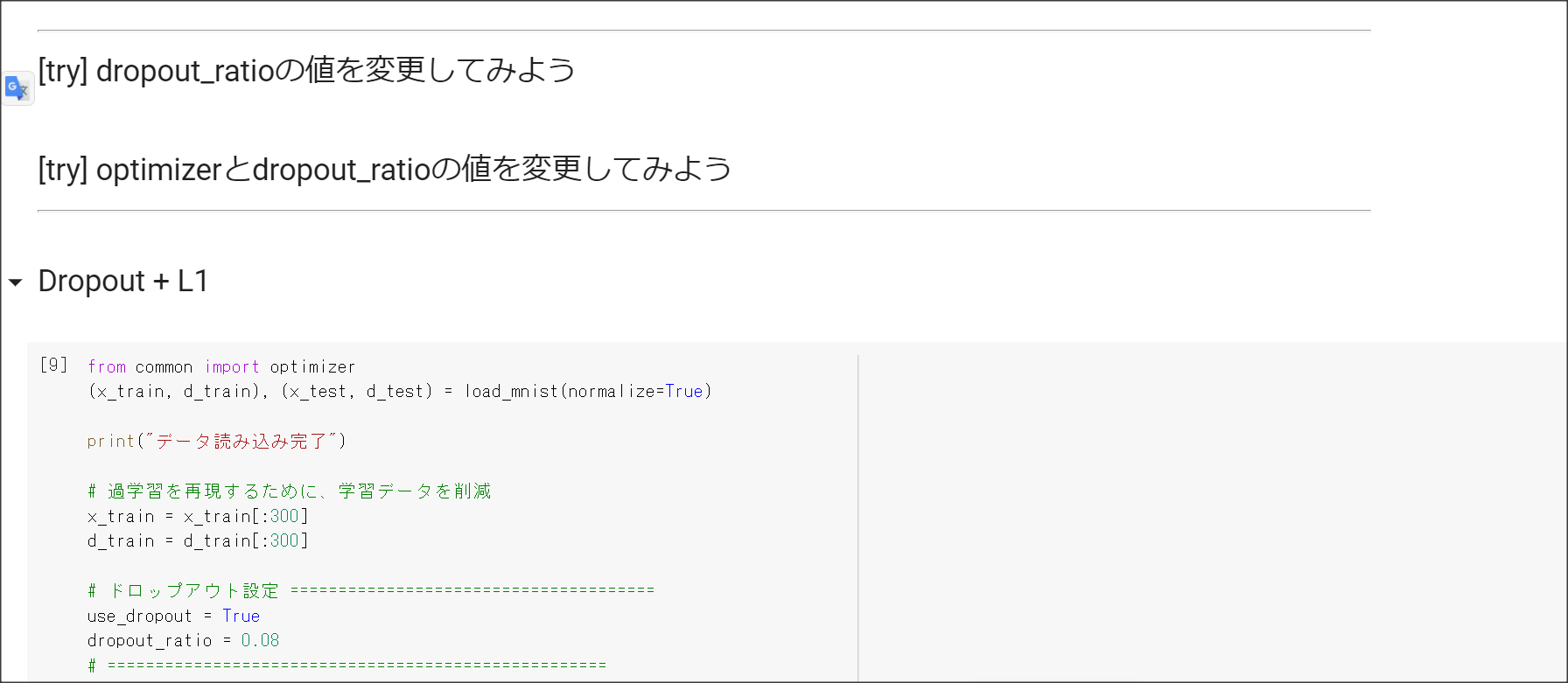
その方法として、正則化、ドロップアウトがある。
正則化はL1正則化、L2正則化がある。
過学習の原因として、重みが大きい値をとることがある。
そのため、誤差に対して正則化項を加算することで、重みを抑制する。
$E_n(w) + \frac{1}{p}\lambda|w|_p$
p=1のときラッソ正則化、p=2のときリッジ正則化という。
ドロップアウトとは、中間層のノードの一部を学習時に無効化して過学習を防ぐ方法。
ドロップアウトは、データを疑似的に増やしていることになるので、過学習が起きにくい。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
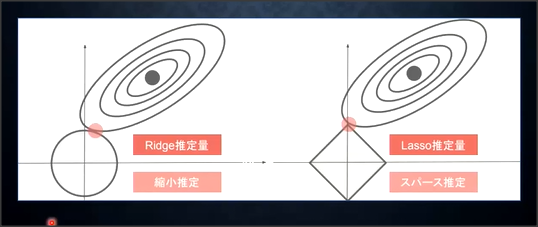
右側がL1正則化。
演習問題や参考図書、修了課題など関連記事レポート
リッジ正則化とラッソ正則化の違い
リッジ正則化は一部のパラメータを0にする。特徴量のうち、重要なものは少ないときに選ぶ。また、パラメータが0になるので解釈しやすいモデルとなる。
ラッソ正則化はパラメータを0に近づける。過学習を防ぐには少し弱い。
Section4
1点100字以上で要点のまとめ
CNNは次元でつながりのあるデータを取り扱う。
CNNは入力層、畳み込み層、ブーリング層、全結合層からなる。
畳み込みの代表例としてLeNet(ルネット)がある。
入力は32×32で出力は10種類。
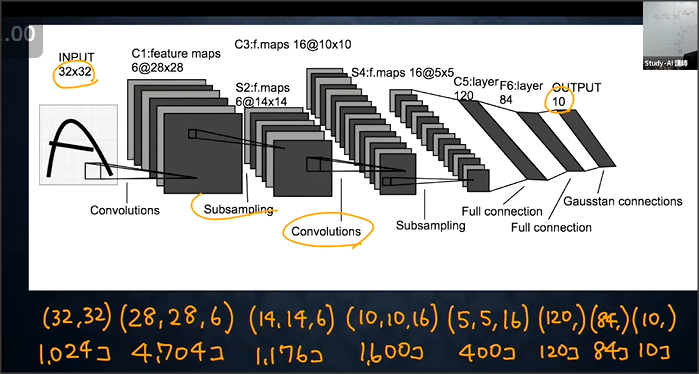
畳み込み層は入力値に対し、以下の処理をする
(1)フィルターをかける
(2)フィルターをかけた値にバイアスを足す
(3)活性化関数で出力する
畳み込み層のフィルターの重みやバイアスを学習することで学習を行う。
畳み込み演算をすると、入力画像に対し出力は小さくなるため、何度も畳み込み演算を行うと、
出力サイズが小さくなってしまい問題となる。
画像の周りを特定の値(0等)で埋め、
入力画像と出力のサイズを同一にする手法のことをパディングという。
ストライド:フィルタをかける際に、いくつずらすかの値。
チャンネル:入力に対して、何個分のフィルタをかけるかを表した概念。
全結合で画像を学習した際の課題は、縦横チャンネルの3次元データが、
1次元で処理されるため、関連性が学習に反映されない。
プーリング層は、畳み込み層と同じように、一定のサイズを読み取ったうえで、
Max値もしくは平均値をとる。
Max値をMax Pooling、平均値の場合をAvg. Poolingという。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
サイズ6×6の入力画像を、サイズ2×2のフィルタで畳み込んだときの出力画像のサイズを答えよ
(6+2×1-2)/1 + 1 = 7
7×7
サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだときの出力画像のサイズを答えよ。
(5 + 2×1-3)/2+1 = 3
3×3の画像
演習問題や参考図書、修了課題など関連記事レポート
Section5 最新のRNN
1点100字以上で要点のまとめ
AlexNetのモデル。ImageNetを解くための問題。
(1) 入力層:224×224の画像
(2) 畳み込み層:11×11のフィルタで96個のチャネル
(3) プーリング層 : 5×5のMaxPoolingで256のチャネルにする。
(4) プーリング層: 3×3のMaxPoolingで384のチャネルにする。
(5) 畳み込み層: 3×3のフィルタ
(6) 畳み込み層: 3×3のフィルタ
(7) 全結合層: Flatten
全結合層にドロップアウトを用いる
Flatten、GlobalMaxPooling、GlobalAvgPooling
GlobalMaxPoolingやGlobalAvgPoolingの方が成績良い。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
AlexNetはSigmoid関数ではなくReLUを使って勾配消失に対応しているのが新しいようだ。
演習問題や参考図書、修了課題など関連記事レポート
実装演習結果キャプチャー
2_1_network_modified.ipynb




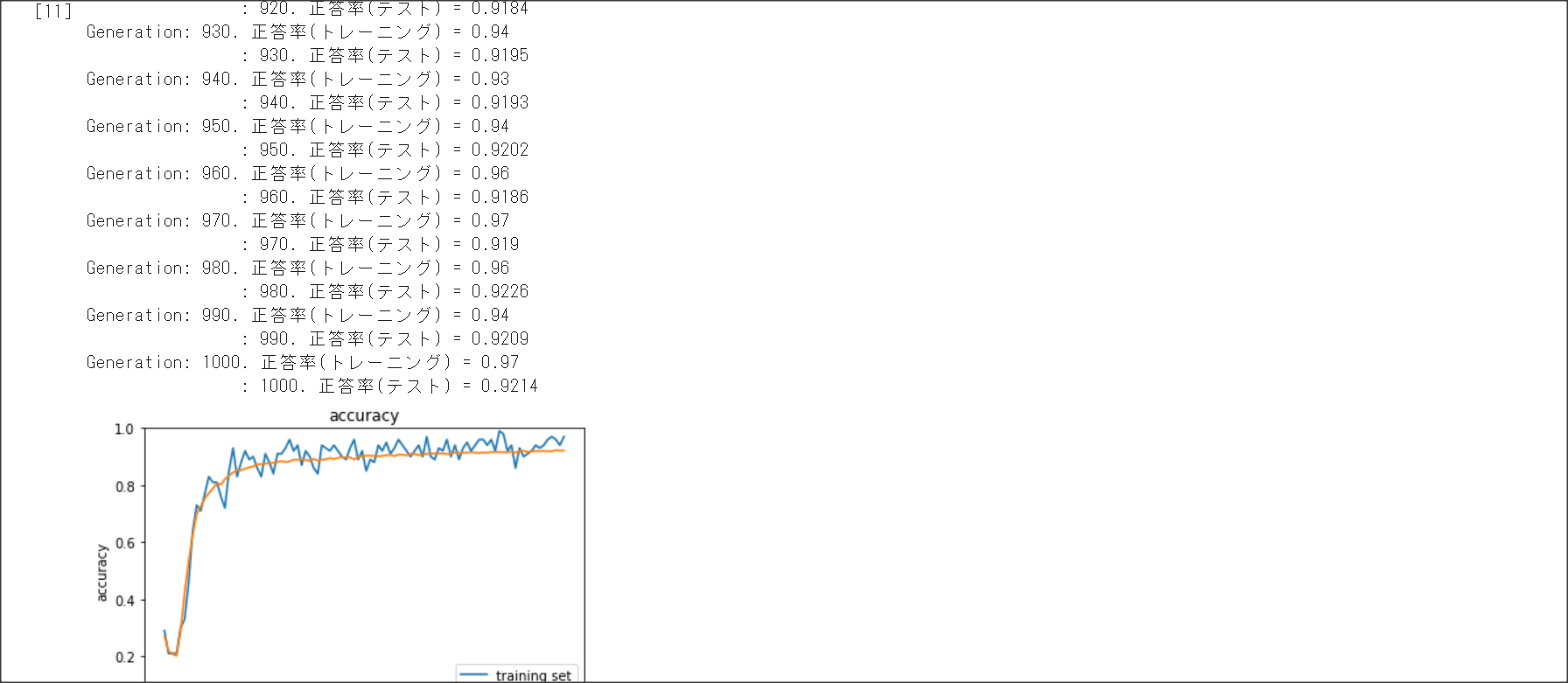

2_2_1_vanishing_gradient.ipynb












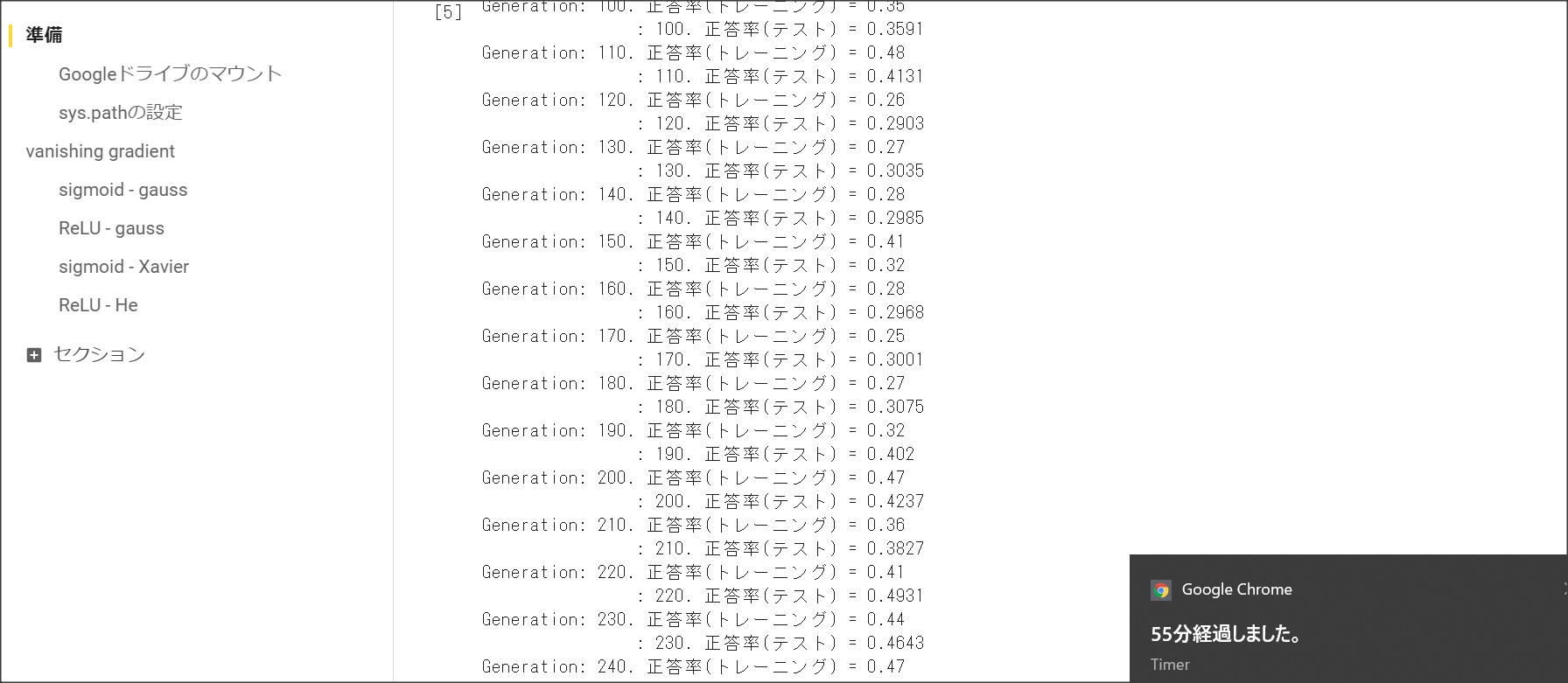
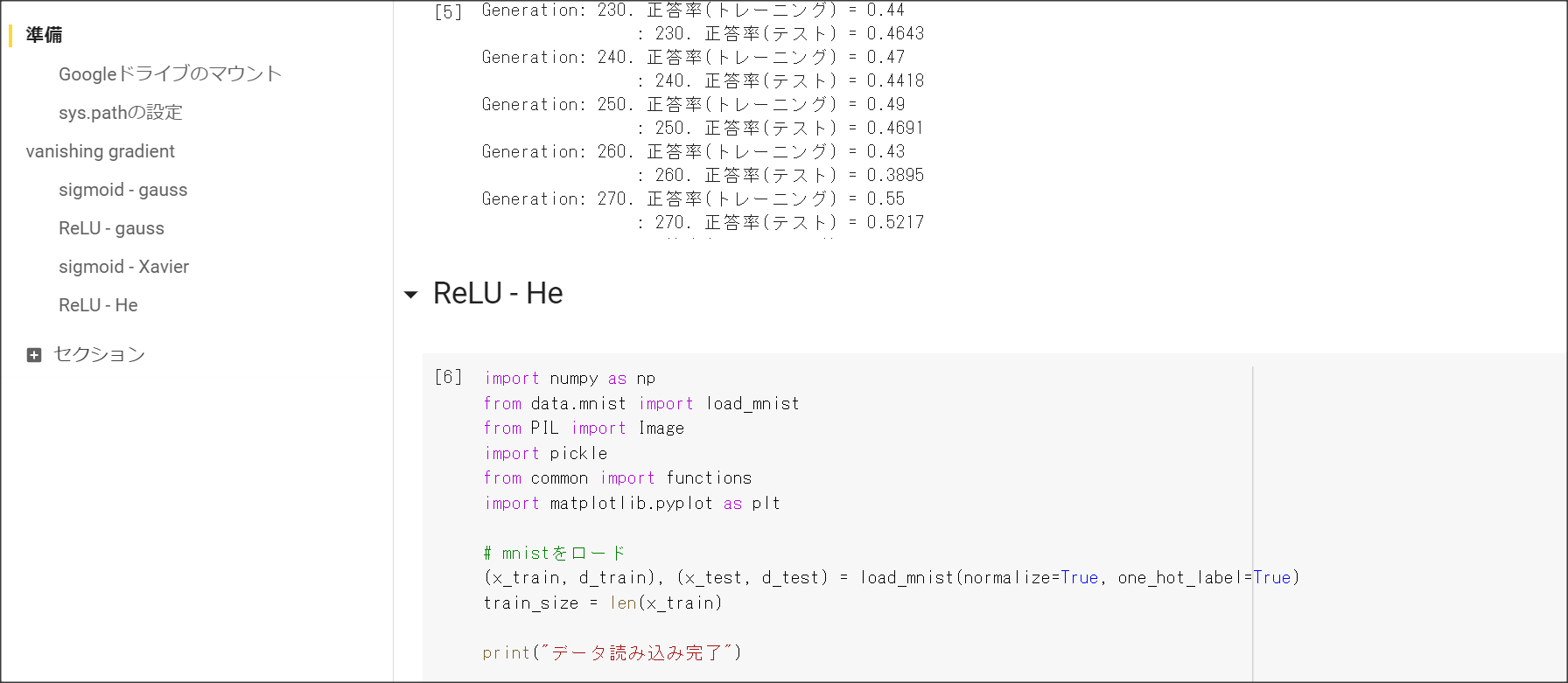








2_2_2_vanishing_gradient_modified.ipynb




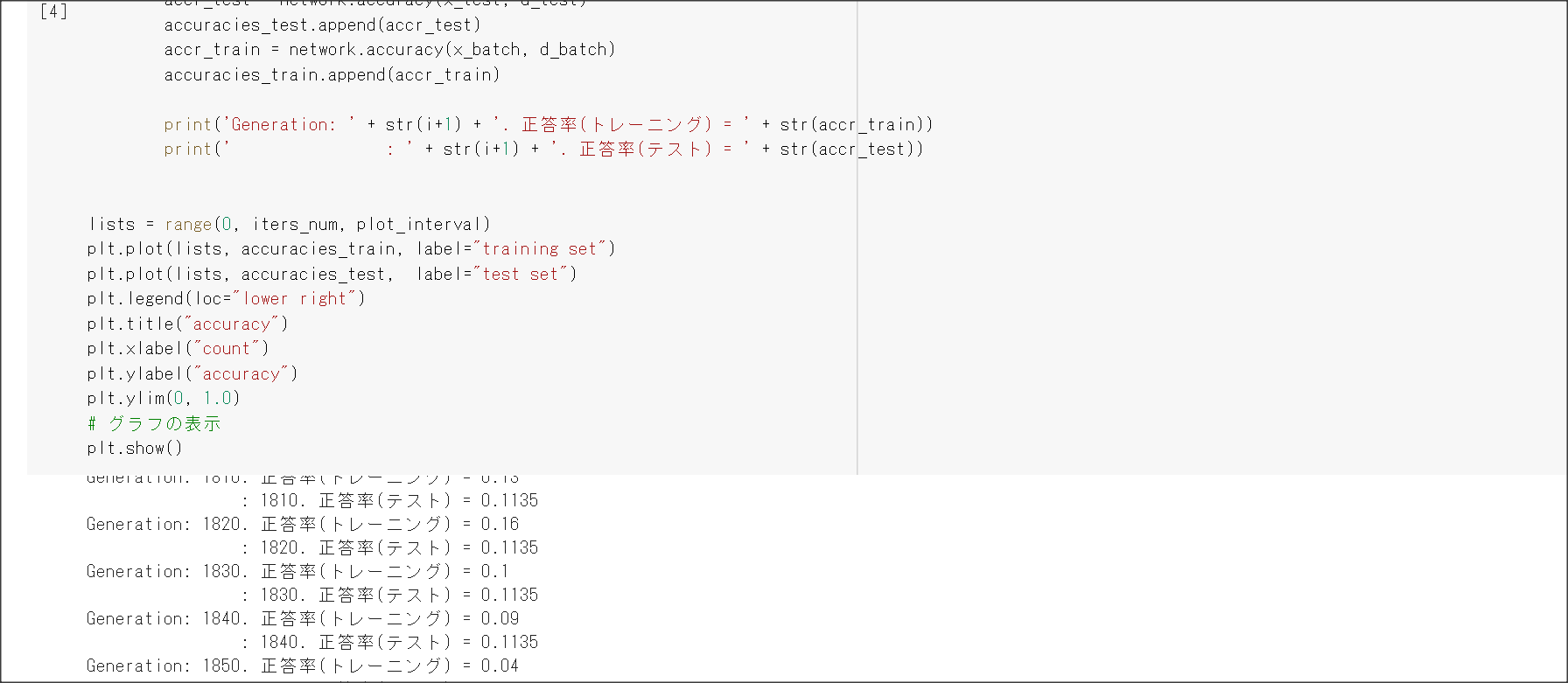

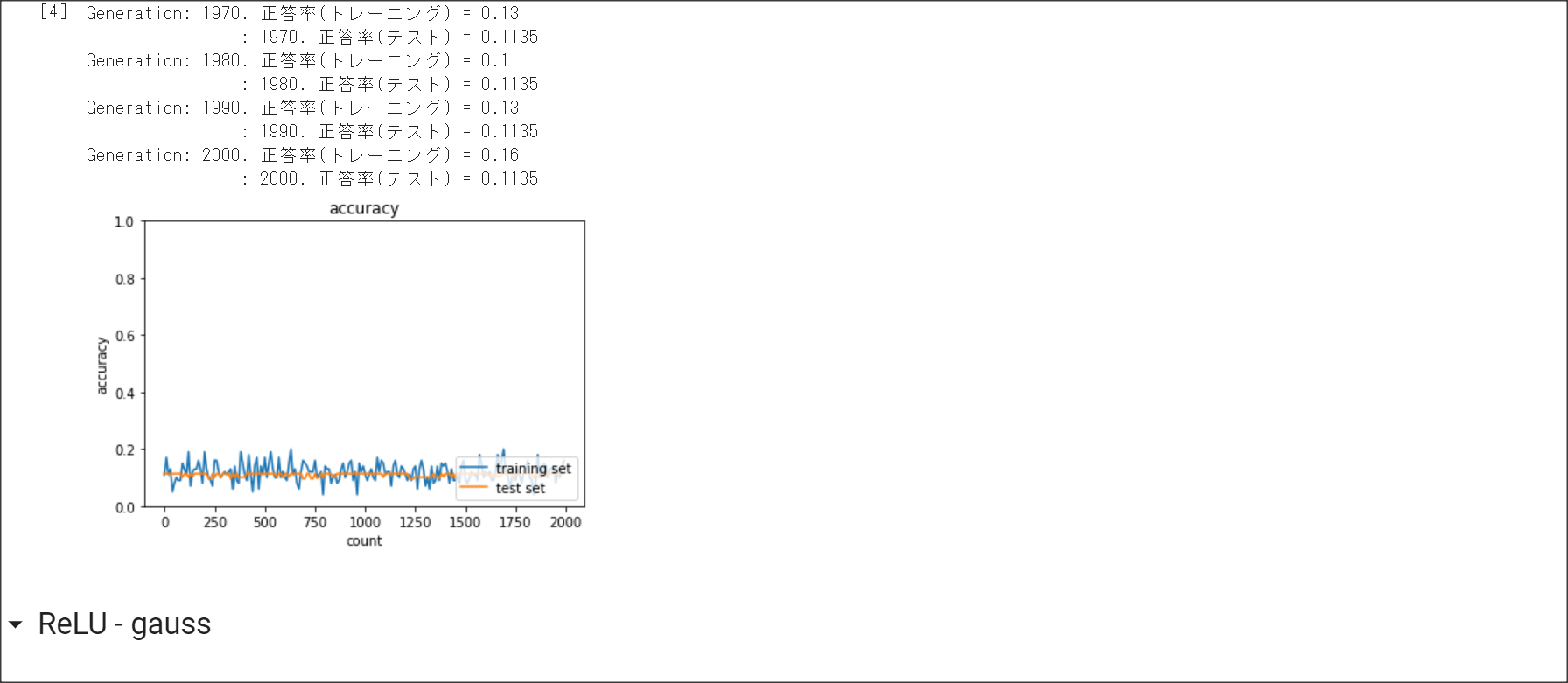

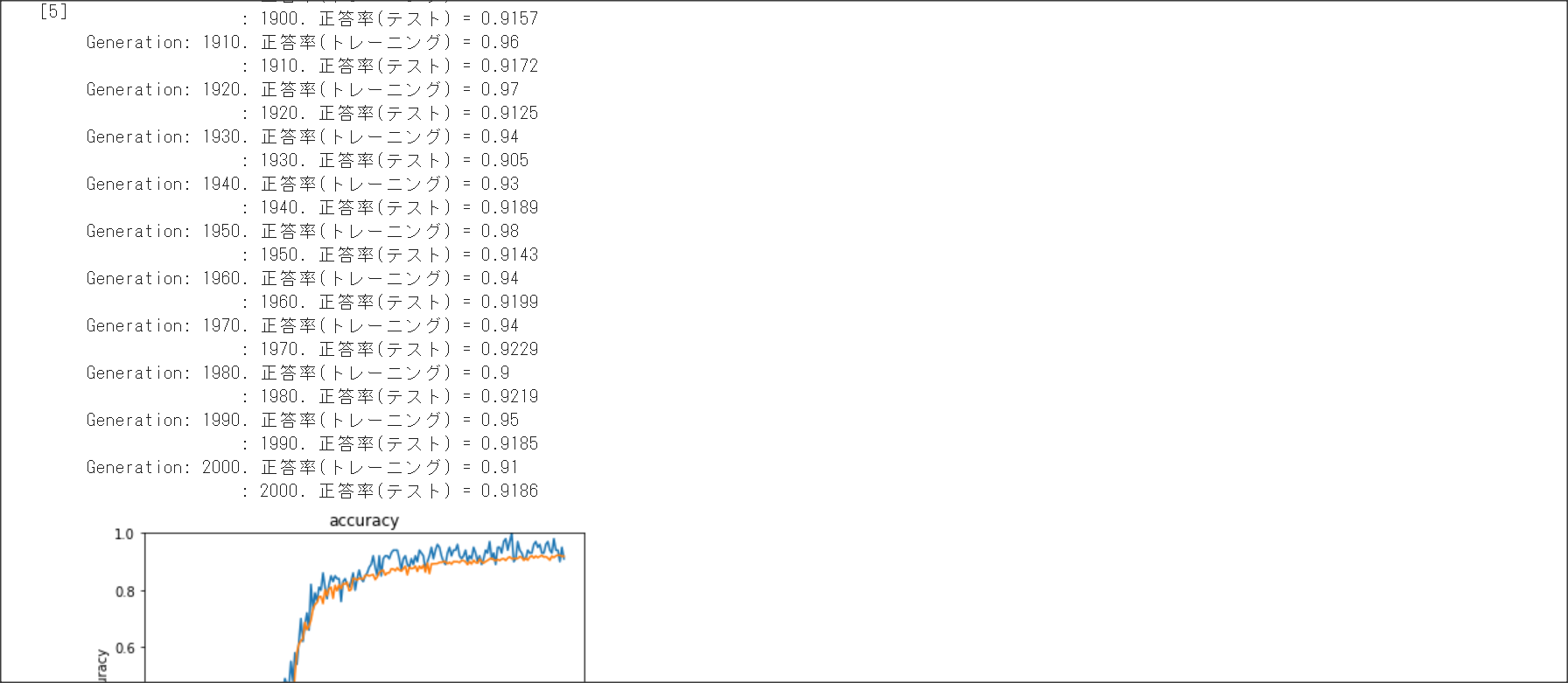
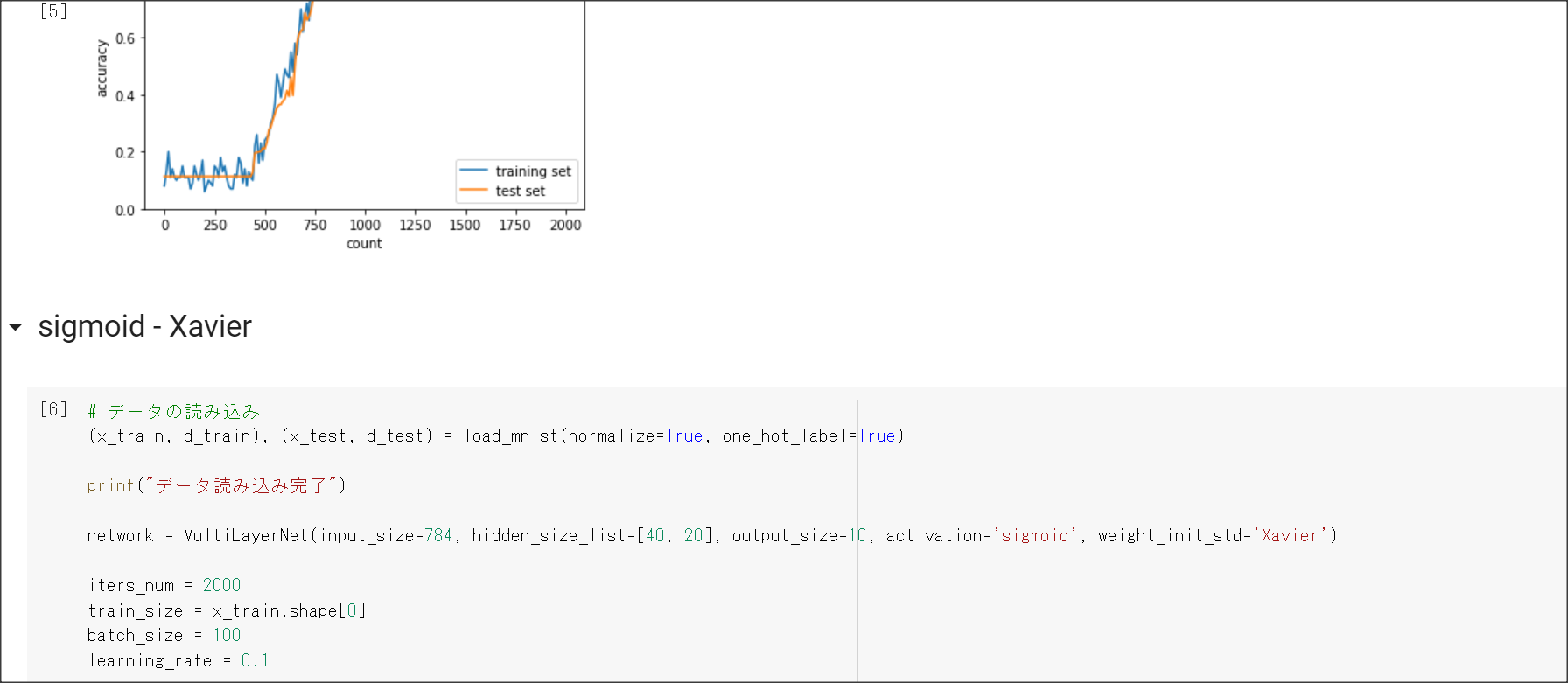


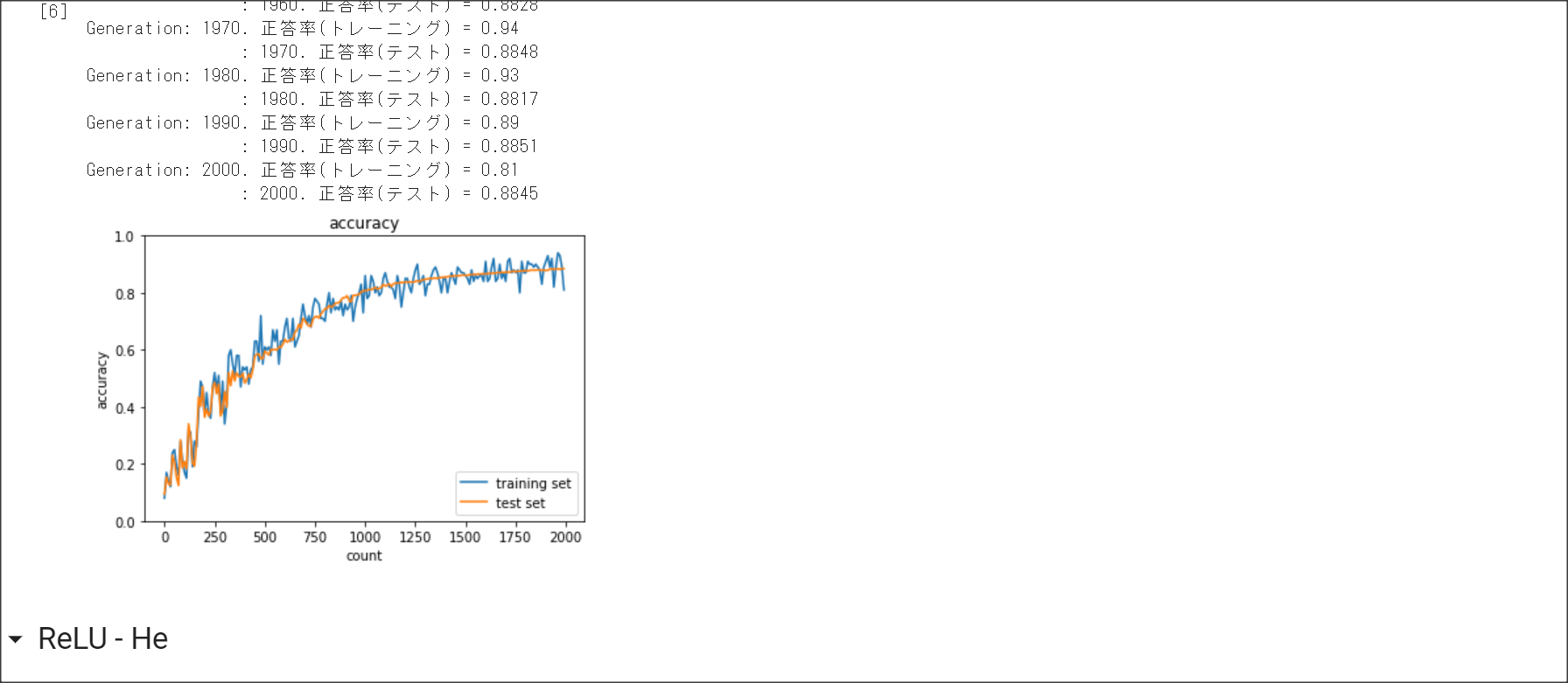

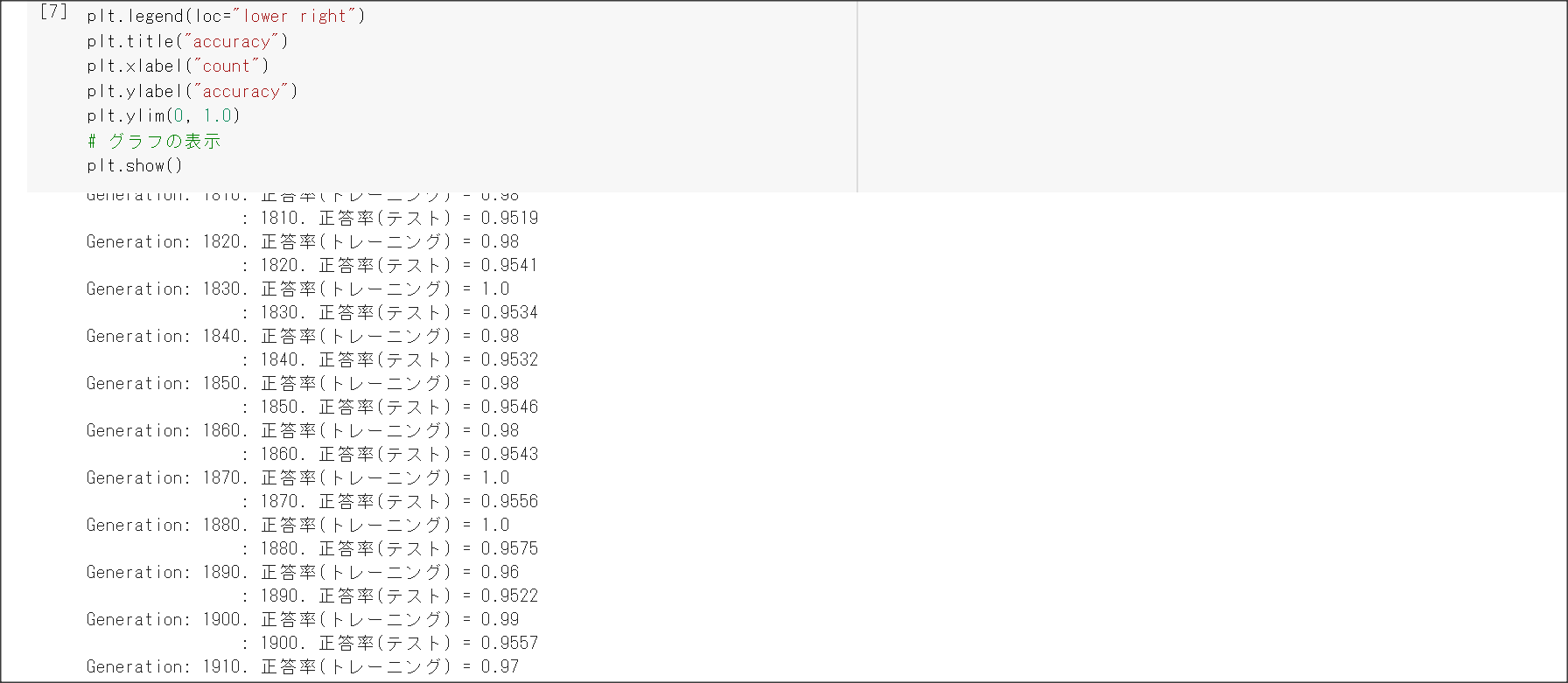
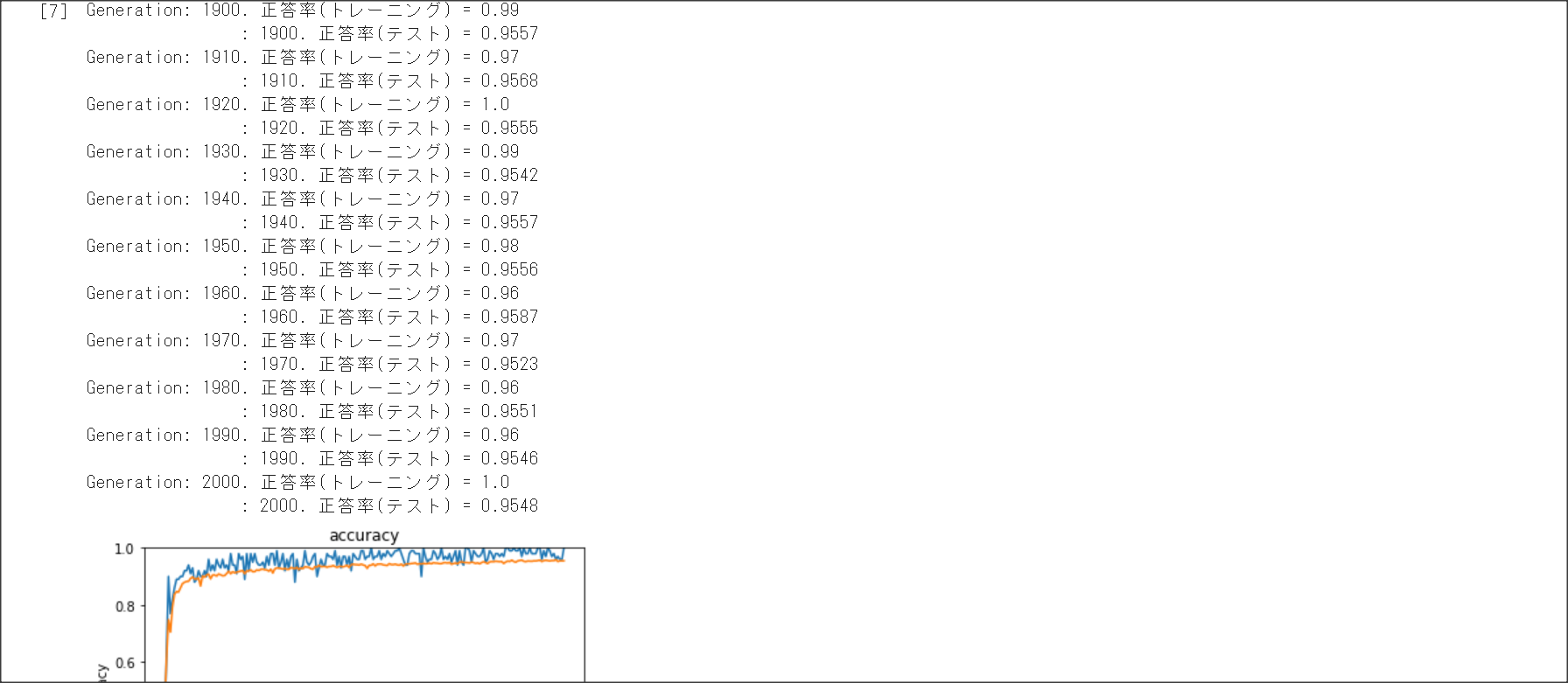

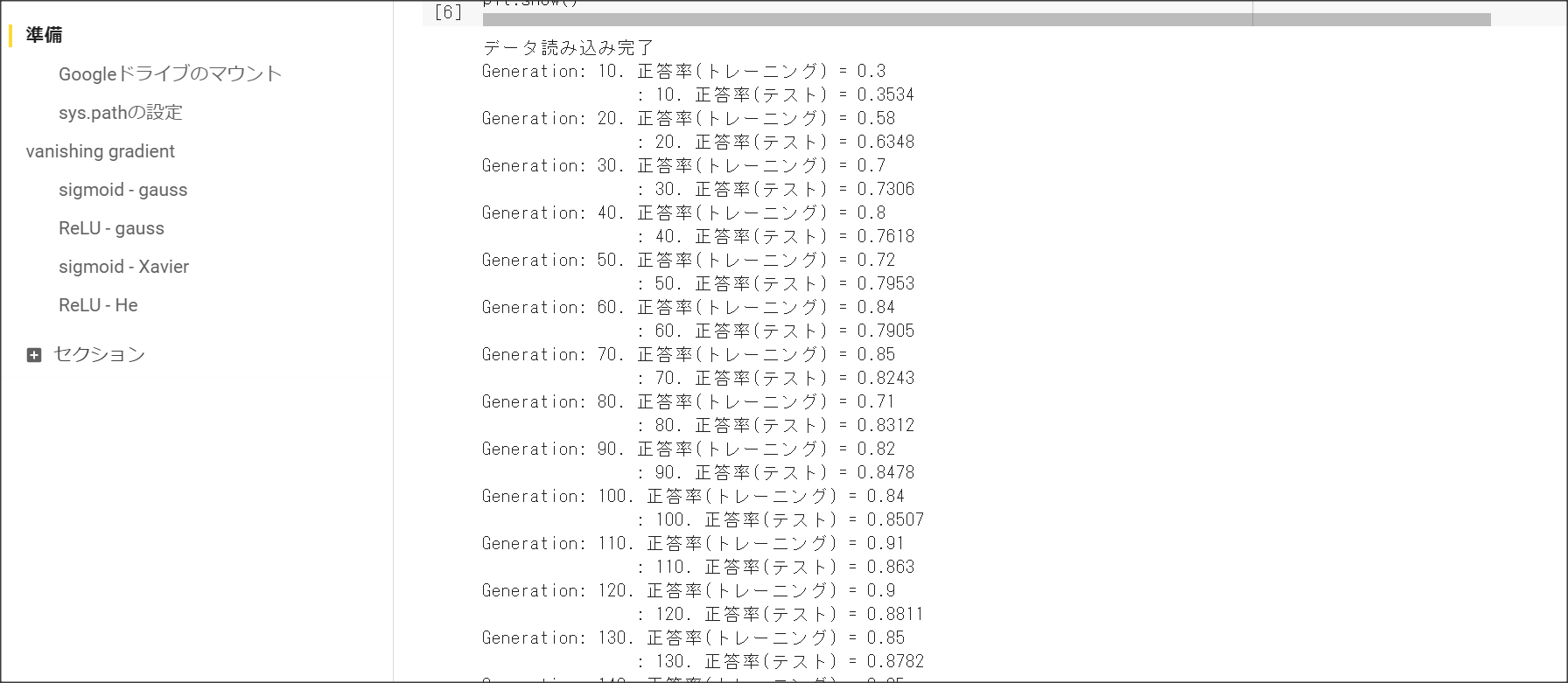
2_3_batch_normalization.ipynb



良い記事を書くには
採点対象範囲
プロローグ1
要約
機械学習は識別と生成が存在する。
識別器は三つのアプローチがある。
- 生成モデル
- 識別モデル
識別したいものかを0から1の確率で出力する。 - 識別関数
識別したいものに合致するかどうかを0か1で出力する。
万能近似定理により、ある深さのニューラルネットワークで関数が近似できる。
ニューラルネットワークの全体像
要約
深層学習は回帰と分類問題が解ける。
自動売買やチャットボット、翻訳、音声解釈、囲碁・将棋AIなどで使われている。
Session1:入力層~中間層
1点100字以上で要点のまとめ
入力$x=(x_1, ... , x_n)$に対し、$W^{(i)}=(w_1^{(i)}, ..., W_n^{(i)}) i=1, ..., k$、$W = (W^{(1)}, ..., W^{(k)}), b = (b_1, ..., b_n)$と置くことで、中間層$u = (u_1, ..., u_k)$が下記のように計算できる。
$$ u = Wx + b$$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
確認テスト この図式動物分類の実例を入れてみよう。
確認テスト $u = W * x + b$をpythonで計算する
確認テスト 中間層を抜き出す
演習問題や参考図書、修了課題など関連記事レポート
考察:ニューラルネットワークの万能近似定理
(https://qiita.com/mochimochidog/items/ca04bf3df7071041561aより抜粋)
これによると、連続関数は、それを近似するような中間層を持つニューラルネットワークが必ず存在する
(より正確に言えば、どんな$ε>0$であっても、誤差が$ε$より小さくなるニューラルネットワークが存在する)。
これはニューラルネットワークでどんな関数でも学習できる十分条件にはならないが、必要条件ではある。
逆にこれを満たせない識別器は、ある種の関数に近づけるよう学習ができないということとなる。
Session2: 活性化関数
1点100字以上で要点のまとめ
活性化関数は、$u=wx+b$に対し、その値を変換する関数$f(u)$のこと。中間層に使う活性化関数と出力層に使う
活性化関数がある。活性化関数は10種類ある。
ReLU関数、シグモイド関数、ステップ関数
(1) ステップ関数 (現在は使われない)
$f(x) = 0 (x < 0), f(x) = 1 (x \ge 0)$
線形分離可能な関数しか学習できない。
(2) シグモイド関数
$f(u) = \frac{1}{1 + e^{-u}}$
勾配がなだらかなところでは、勾配消失問題が発生した。
(3) ReLU関数
$f(u) = 0 (u < 0), f(u) = u (u \ge 0)$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
確認テスト 線形と非線形の違いを図にかいて説明せよ
線形な関数は、$f(x + y) = f(x) + f(y)$、$f(kx)=kf(x)$が成り立つ。非線形は線形でない関数。
確認テスト 活性化関数が使われているところを探せ
演習問題や参考図書、修了課題など関連記事レポート
Session3: 出力層
1点100字以上で要点のまとめ
誤差関数
出力層の役割:人間が欲しいデータを出す。分類の問題であれば、犬の確率、猫の確率など。
誤差関数:ニューラルネットワークと訓練データのデータ差異を表す。
$(x, y) \in \mathbb{R}^k \times \in \mathbb{R}^l$という訓練データが与えられたときに、
ニューラルネットワークfに$x$を与えると、$\hat{y} = f(x)$が返ってきたとする。
この場合に、
$E(x) =\frac{1}{2}\sum{(\hat{y}_i - y_i)^2}$を二乗平方誤差関数という。
分類はクロスエントロピー誤差関数、回帰は平均二乗誤差関数を用いることが多い。
活性化関数
出力層の活性化関数は、データを使いやすいよう加工するのが目的。
||回帰|二値分類|多値分類|
|活性化関数|恒等関数|シグモイド関数|softmax関数|
|誤差関数|二乗誤差|交差エントロピー|交差エントロピー|
交差エントロピー$E=-\sum{d_i\log{y_i}}$
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
なぜ誤差関数は二乗し、$\frac{1}{2}$をかけるのか。
二乗することで、誤差の大きさを足し合わせている。二乗しないと、誤差が打ち消しあう可能性がある。
微分したとき、$\frac{df(x)^2}{dx}=2f(x)\frac{df}{dx}$となり、$2$と$\frac{1}{2}$が打ち消しあうため、
$\frac{1}{2}$倍する。
ソフトマックス関数の処理を1行ずつ説明しろ
def softmax(x):
if x.ndim == 2:
# ミニバッチの場合
x = x.T
# オーバーフロー対策で、最大値を0にする
x = x - np.max(x, axis=0)
# Softmaxの値の計算。全体を合計すると1になるように、合計値で割っている。
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
# オーバーフロー対策で、最大値を0にする
x = x - np.max(x) # オーバーフロー対策
# Softmaxの値の計算。全体を合計すると1になるように、合計値で割っている。
return np.exp(x) / np.sum(np.exp(x))
クロスエントロピーの処理を説明せよ
def cross_entropy_error(d, y):
# ミニバッチの時の処理
if y.ndim == 1:
# dを(1, d.size)の形に変更する
d = d.reshape(1, d.size)
# dを(1, y.size)の形に変更する
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
# バッチサイズはyの大きさとなる。
batch_size = y.shape[0]
# クロスエントロピーを求める。1e-7を足すことで、値が0に落ちないよう工夫している。
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
演習問題や参考図書、修了課題など関連記事レポート
Session4: 勾配降下法
1点100字以上で要点のまとめ
確率勾配法
誤差関数を最小にする$\omega$を見つけていくのが勾配降下法。
$\omega^{t+1}=\omega^{t} - \epsilon \nabla E$
学習率$\epsilon$が小さいと収束するのが遅くなる。また、局所最適解に陥ってしまう可能性もある。
勾配降下法の$\epsilon$を選ぶためのアルゴリズムが4つある。
Momentum
AdaGrad
AdaDelta
Adam
1回のデータに対し誤差関数を計算し、勾配降下法で重みを更新するサイクルをエポックという。
確率的勾配降下法
確率的勾配降下法は、全データで学習するのではなく、データの中からランダムに一データを選んで、
そのデータを用いて学習する。
勾配降下法は、全データを用いるため、データが増えるとメモリに乗らない。
ミニバッチ勾配降下法
ミニバッチ勾配降下法は、全データで学習するのではなく、データをランダムに分割して、
分割したデータを用いて学習する。オンライン勾配降下法より計算資源を有効に活用できるため、
学習効率が良い。
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
∇Eが出現するコードを特定する
オンライン学習とは何か
学習データが1データだけで学習する。
w_t+1 <- w_t - ε∇Eを図解せよ。
演習問題や参考図書、修了課題など関連記事レポート
Session5: 誤差逆伝搬法
1点100字以上で要点のまとめ
誤差勾配の計算
$\nabla E$の計算方法は実際に微分を用いる。
数値微分を用いる方法…$\frac{E(w_m +h) - E(w_m - h)}/2h$を計算する。
この方法は、それぞれの重み$w_1,...,w_k$で$\frac{E(w_m +h) - E(w_m - h)}/2h$を計算しなければならないため計算量が多い。
これは計算量が多いため、誤差逆伝搬法を用いる。
誤差逆伝搬法
$\nabla E = [\frac{\partial E}{\partial w_m}]$
を求めるために、誤差逆伝搬法を用いる。
誤差を後ろから計算して後ろの重みから更新し、前の重みを再帰的に更新する。
後ろの重みを計算したときの微分値を使えるため、計算量が少なくて済む。
実装演習結果キャプチャーまたはサマリーと考察
Sessionごとに実装演習が分けられていなかったため、最下部の「実装演習キャプチャー」に
画面キャプチャを張り付けているので、そちらを参照すること。
「確認テスト」など、自身の考察結果
誤差逆伝搬法のコード
def backward(x, d, z1, y):
# print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
#delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
## 試してみよう
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
delta1 = delta1[np.newaxis, :]
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
x = x[np.newaxis, :]
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
# print_vec("偏微分_重み1", grad["W1"])
# print_vec("偏微分_重み2", grad["W2"])
# print_vec("偏微分_バイアス1", grad["b1"])
# print_vec("偏微分_バイアス2", grad["b2"])
return grad
空欄を埋めろ
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
grad['W1'] = np.dot(x.T, delta1)
演習問題や参考図書、修了課題など関連記事レポート
その他
ディープラーニングの開発環境
クラウドであればAWS、GCPで開発できる。
ディープラーニングを行うためのH/W:CPU、GPU、FPGA、ASIC(TPU)
入力層の設計
欠損値が多いとダメ。異なるクラスが同じ値を示している場合も正しく分類できない。
過学習
教師データでは良い成績を残すが、検証データではいい成績が得られない状態。
学習のノードが多いと、発生する場合がある。ドロップアウトという手法で防ぐ方法がある。
データ拡張
画像データの分類で使える手法。
画像を拡大・縮小したり、一部を隠したり、などの手法を使うことで、画像を大量に水増しして
教師データを増やす手法。
ディープラーニングの中間層にノイズを入れる手法もある。
CNN
次元方向につながりのあるデータを扱う。
転移学習
画像認識の層が浅いところは基本的な特徴を捉えているはずなので、すでに学習済みの層が浅いところを
別の学習に用いることができる。このように、学習モデルを他で使うことを転移学習という。
実装演習結果キャプチャ
1_1_forward_propagation_after.ipynb
1_1_forward_propagation.ipynb
1_2_back_propagation.ipynb
1_3_stochastic_gradient_descent.ipynb
1_4_1_mnist_sample.ipynb
MNISTのデータをダウンロードするコードで、HTTP Error 503: Service Unavailableが出て学習できない。
実装演習結果としては問題ないと判断し、画面キャプチャは割愛。
[Days2]
Section1 勾配消失問題
1点100字以上で要点のまとめ
勾配消失問題とは、層が深い場合に、誤差逆伝搬法で、手前の関数の微分の勾配が小さいと、
勾配が消失していき、層が手前の方が学習しなくなってしまう問題を表す。
シグモイド関数の微分の絶対値の最大は0.25のため、層が深くなると勾配が消失してしまう。
勾配消失問題に対応するには、活性化関数の選択、重みの工夫、バッチ正規化の3つの手法がある。
活性化関数の選択
ReLUを用いる。$f(x) = 0 (x < 0), f(x) = x ( x \ge 0)$
ReLUで勾配消失の問題とスパース化に対応。
重みの工夫
重みを初期化する際の工夫1:Xavier。
正規分布の乱数を前の層のノード数の平方根で割り重みを初期化する
重みを初期化する際の工夫2:He。
ReLUの場合に用いる。
正規分布の乱数を$\sqrt{\frac{2}{n}}$で求める。
バッチ正規化
バッチ処理の入力で渡すデータの各チャネルへの入力データの分散を1に抑える手法のこと。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
シグモイド関数を微分の値の最大値は?
0.25となる。
全ての重みが0だとどうなるか
全部0だと出力が0となり勾配損失が発生し学習が進まなくなる。
演習問題や参考図書、修了課題など関連記事レポート
Xavier : なぜ√を取る?⇒分散が変わらないようにするため。
出力する分散値が変わらないようにするためには、√をかけてやると良い。
今、$X$を正規分布とすると、$V((\sum^n{X})/\sqrt{n})$ $n * V(X) * \frac{1}{\sqrt{n}^2} = V(X)$
となる。
Section2 学習最適化手法
1点100字以上で要点のまとめ
モメンタム
$V_i = \mu * V_{i-1} - \nabla E$
$w^{(i+1)} = w^{(i)} + V_i$
AdaGrad
$h_0 = \theta$
$h_t = h_{t-1} + (\nabla E)^2$
$w^{(t+1)} = w^{(t)} - \epsilon \frac{1}{\sqrt{h_t} + \theta}\nabla E$
RMSProp
ADAGradを改良したもの。
Adam
RMSPropとモメンタムのいいところを取り入れたアルゴリズム
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
確認テストは特になし。
演習問題や参考図書、修了課題など関連記事レポート
Section3 過学習
1点100字以上で要点のまとめ
学習データと検証データで正解率に乖離があることを過学習という。過学習の原因はネットワークの自由度が高いこと
なので、それを対策することが必要。
その方法として、正則化、ドロップアウトがある。
正則化はL1正則化、L2正則化がある。
過学習の原因として、重みが大きい値をとることがある。
そのため、誤差に対して正則化項を加算することで、重みを抑制する。
$E_n(w) + \frac{1}{p}\lambda|w|_p$
p=1のときラッソ正則化、p=2のときリッジ正則化という。
ドロップアウトとは、中間層のノードの一部を学習時に無効化して過学習を防ぐ方法。
ドロップアウトは、データを疑似的に増やしていることになるので、過学習が起きにくい。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
右側がL1正則化。
演習問題や参考図書、修了課題など関連記事レポート
リッジ正則化とラッソ正則化の違い
リッジ正則化は一部のパラメータを0にする。特徴量のうち、重要なものは少ないときに選ぶ。また、パラメータが0になるので解釈しやすいモデルとなる。
ラッソ正則化はパラメータを0に近づける。過学習を防ぐには少し弱い。
Section4
1点100字以上で要点のまとめ
CNNは次元でつながりのあるデータを取り扱う。
CNNは入力層、畳み込み層、ブーリング層、全結合層からなる。
畳み込みの代表例としてLeNet(ルネット)がある。
入力は32×32で出力は10種類。
畳み込み層は入力値に対し、以下の処理をする
(1)フィルターをかける
(2)フィルターをかけた値にバイアスを足す
(3)活性化関数で出力する
畳み込み層のフィルターの重みやバイアスを学習することで学習を行う。
畳み込み演算をすると、入力画像に対し出力は小さくなるため、何度も畳み込み演算を行うと、
出力サイズが小さくなってしまい問題となる。
画像の周りを特定の値(0等)で埋め、
入力画像と出力のサイズを同一にする手法のことをパディングという。
ストライド:フィルタをかける際に、いくつずらすかの値。
チャンネル:入力に対して、何個分のフィルタをかけるかを表した概念。
全結合で画像を学習した際の課題は、縦横チャンネルの3次元データが、
1次元で処理されるため、関連性が学習に反映されない。
プーリング層は、畳み込み層と同じように、一定のサイズを読み取ったうえで、
Max値もしくは平均値をとる。
Max値をMax Pooling、平均値の場合をAvg. Poolingという。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
サイズ6×6の入力画像を、サイズ2×2のフィルタで畳み込んだときの出力画像のサイズを答えよ
(6+2×1-2)/1 + 1 = 7
7×7
サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだときの出力画像のサイズを答えよ。
(5 + 2×1-3)/2+1 = 3
3×3の画像
演習問題や参考図書、修了課題など関連記事レポート
Section5 最新のRNN
1点100字以上で要点のまとめ
AlexNetのモデル。ImageNetを解くための問題。
(1) 入力層:224×224の画像
(2) 畳み込み層:11×11のフィルタで96個のチャネル
(3) プーリング層 : 5×5のMaxPoolingで256のチャネルにする。
(4) プーリング層: 3×3のMaxPoolingで384のチャネルにする。
(5) 畳み込み層: 3×3のフィルタ
(6) 畳み込み層: 3×3のフィルタ
(7) 全結合層: Flatten
全結合層にドロップアウトを用いる
Flatten、GlobalMaxPooling、GlobalAvgPooling
GlobalMaxPoolingやGlobalAvgPoolingの方が成績良い。
実装演習結果キャプチャーまたはサマリーと考察
一番最後の実装演習結果キャプチャーにて記載
「確認テスト」など、自身の考察結果
AlexNetはSigmoid関数ではなくReLUを使って勾配消失に対応しているのが新しいようだ。
演習問題や参考図書、修了課題など関連記事レポート
実装演習結果キャプチャー
2_1_network_modified.ipynb
2_2_1_vanishing_gradient.ipynb
2_2_2_vanishing_gradient_modified.ipynb
2_3_batch_normalization.ipynb
2_4_optimizer_after.ipynb


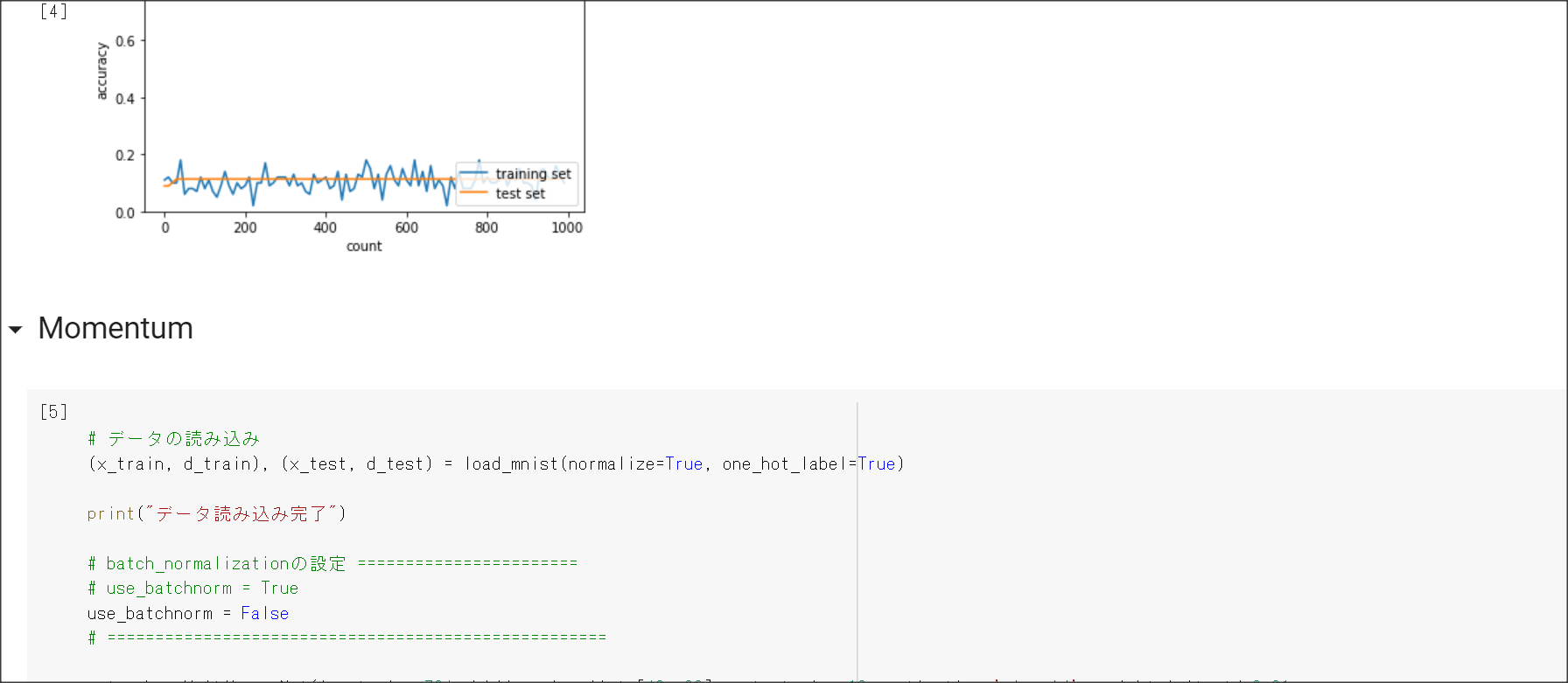

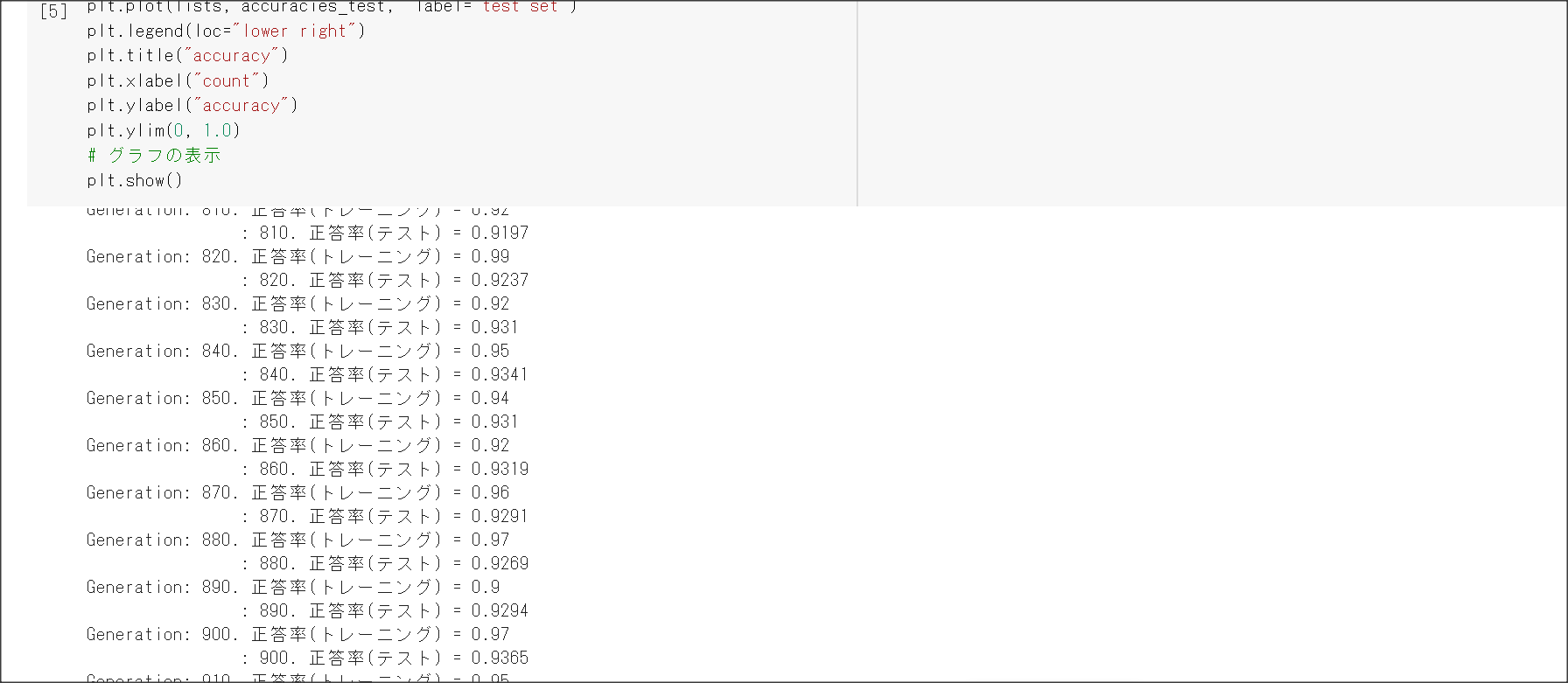
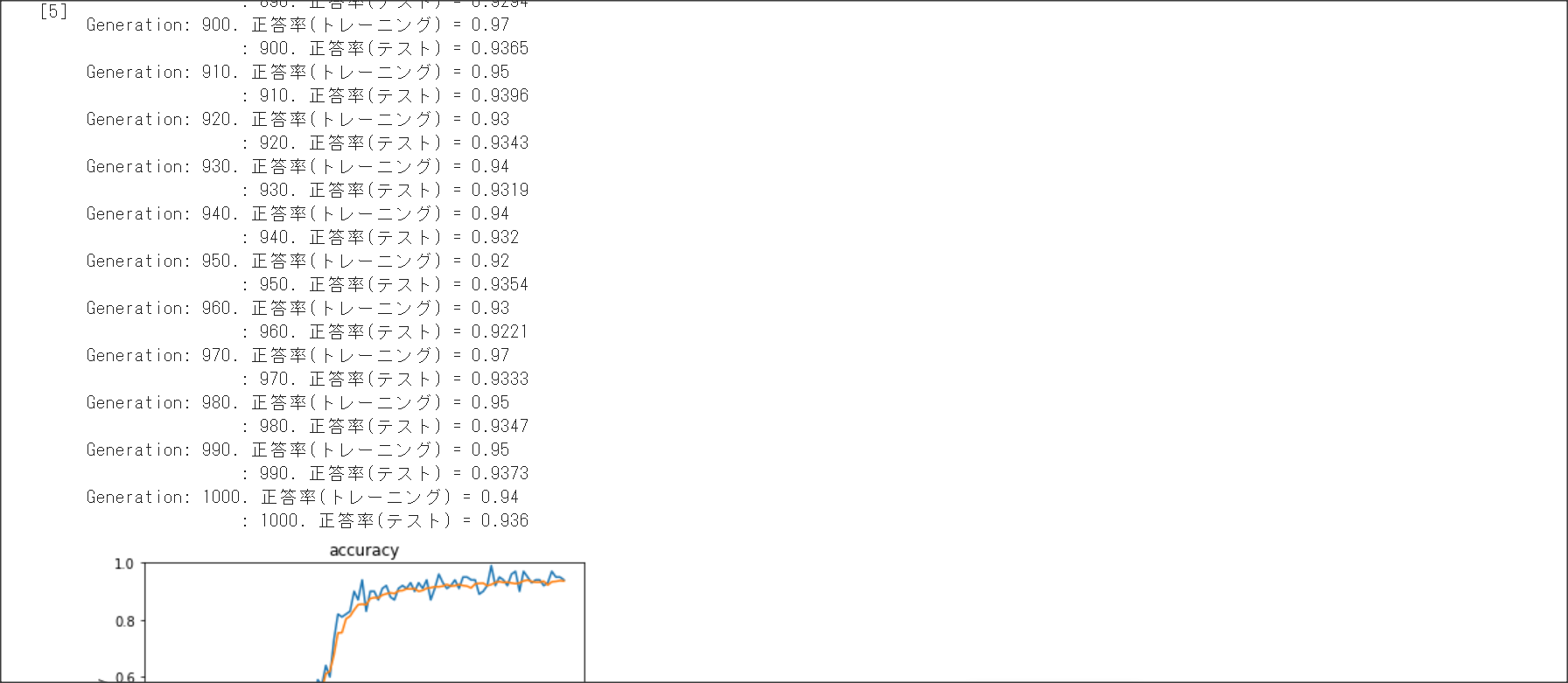
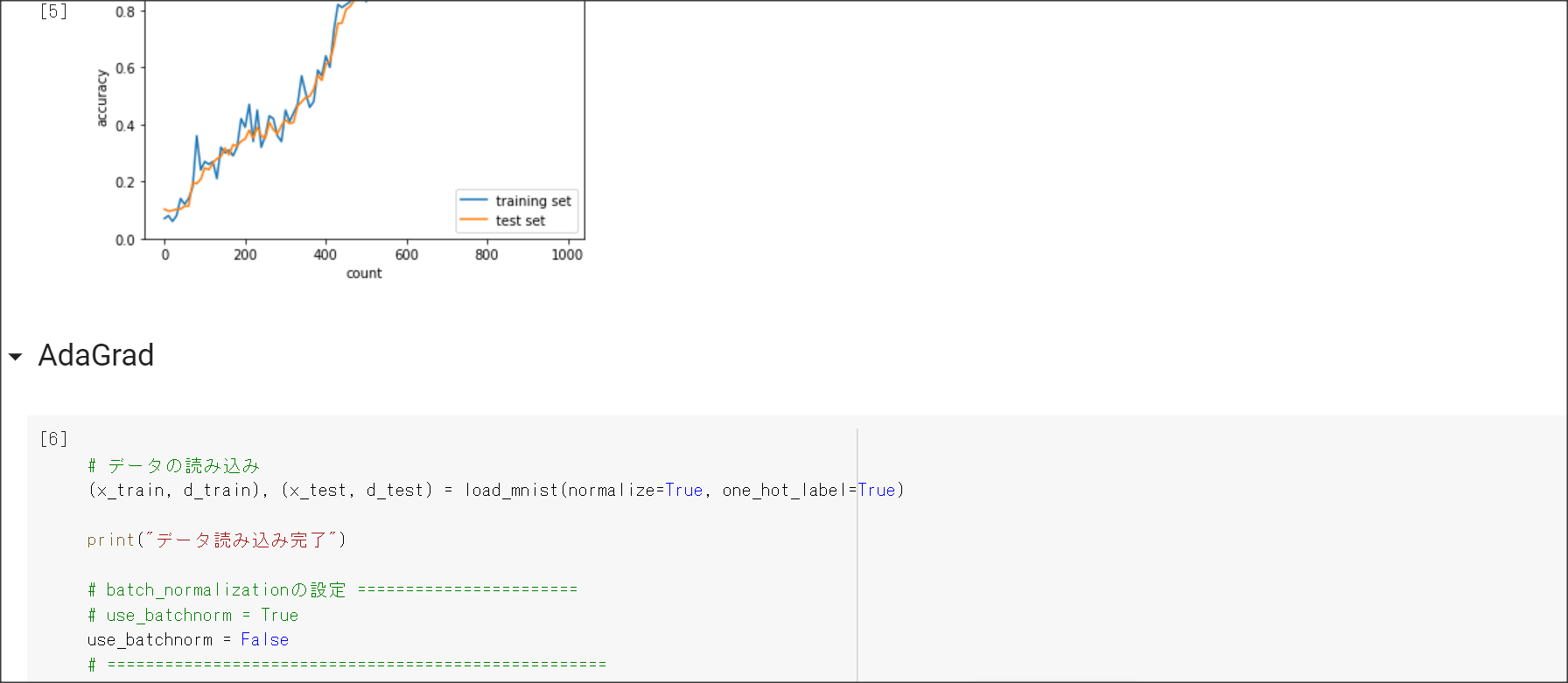

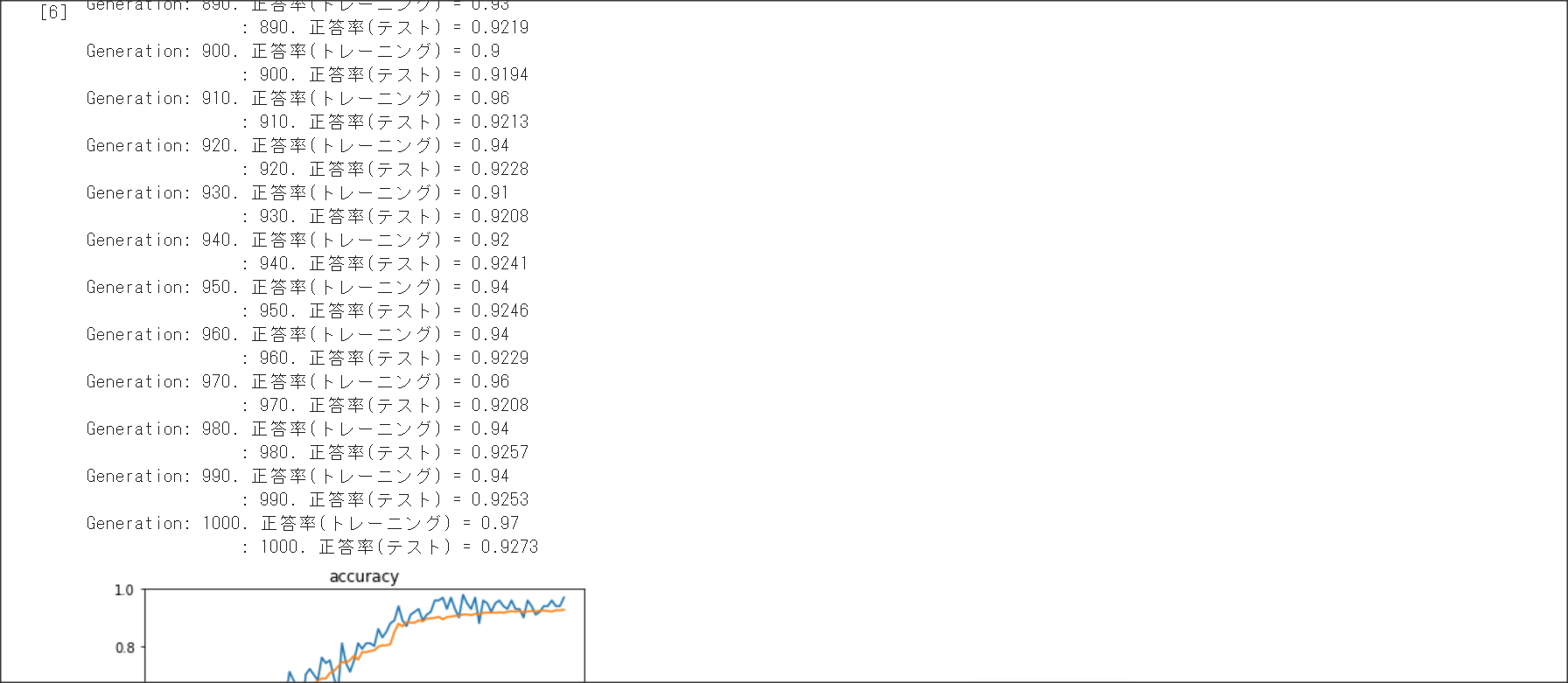
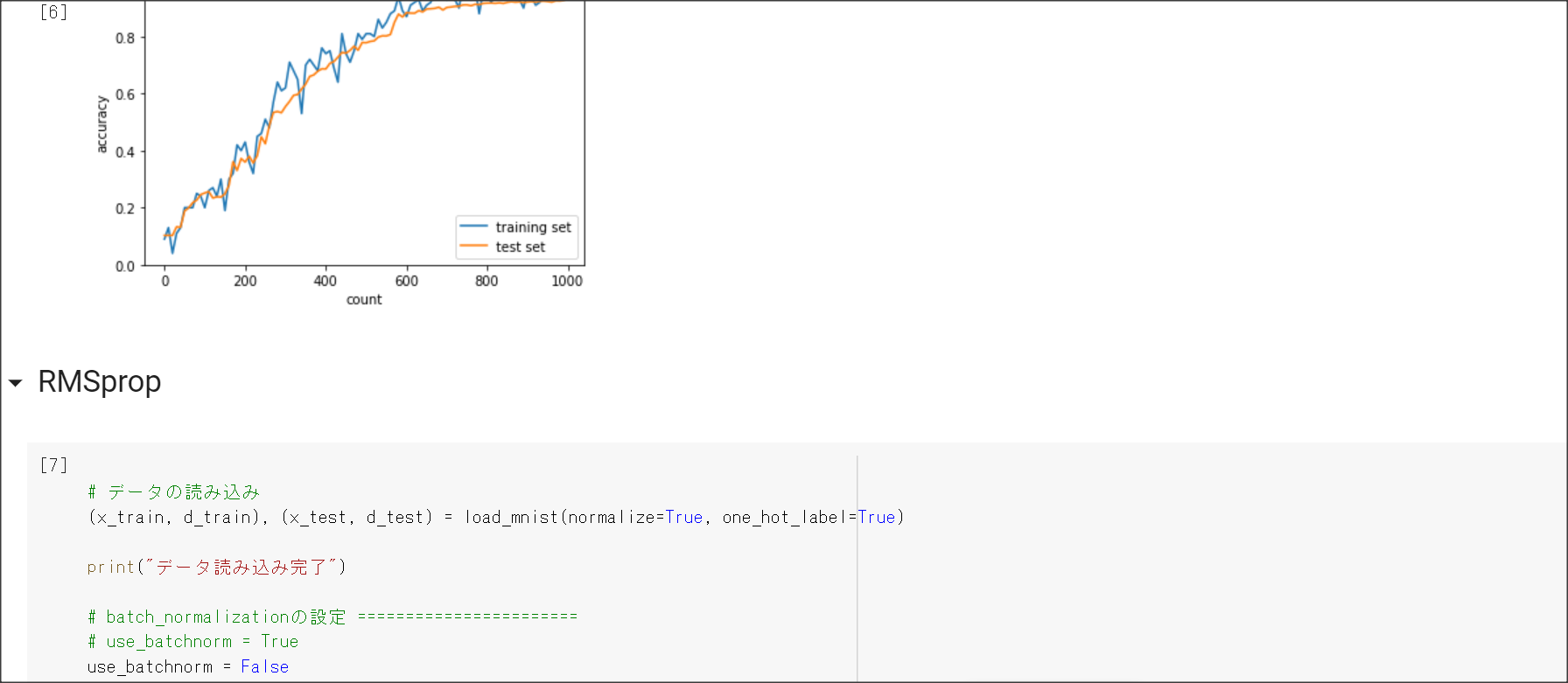

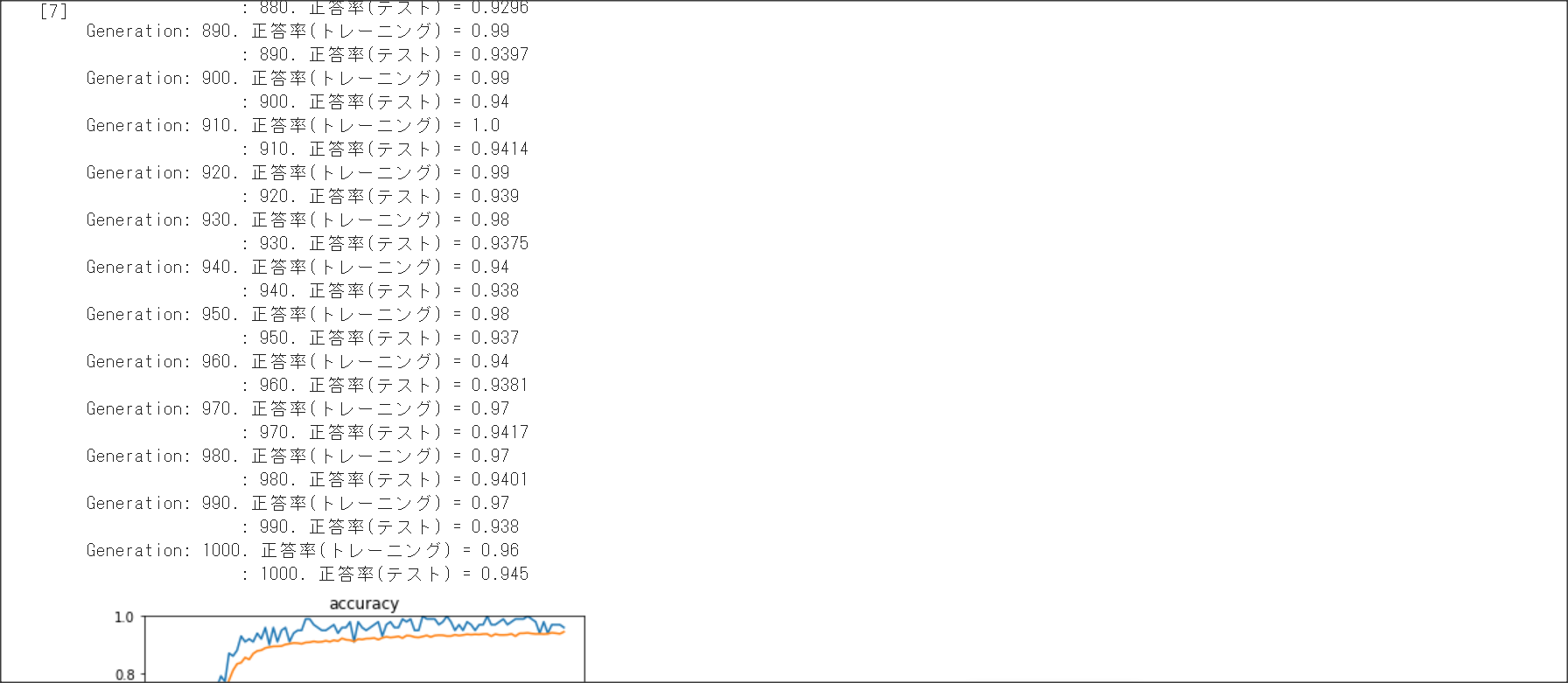
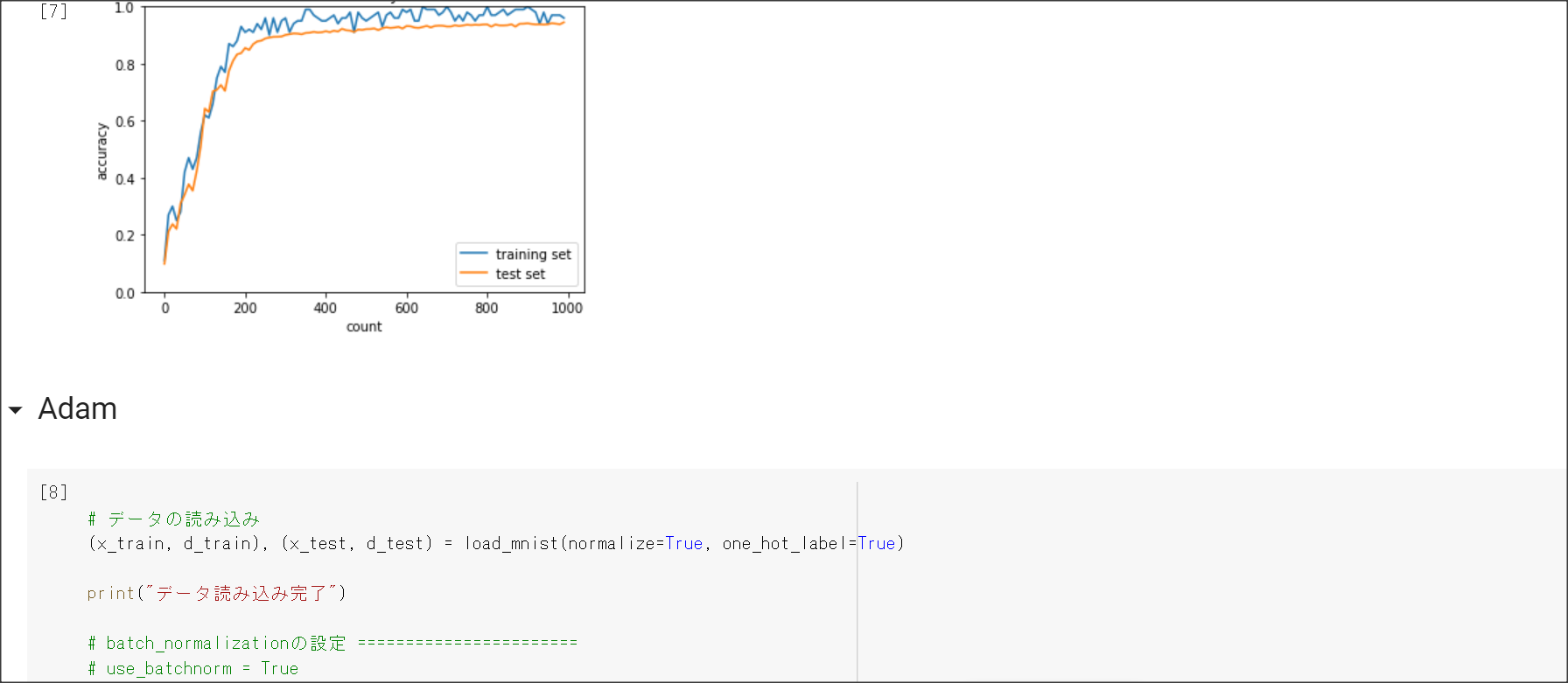


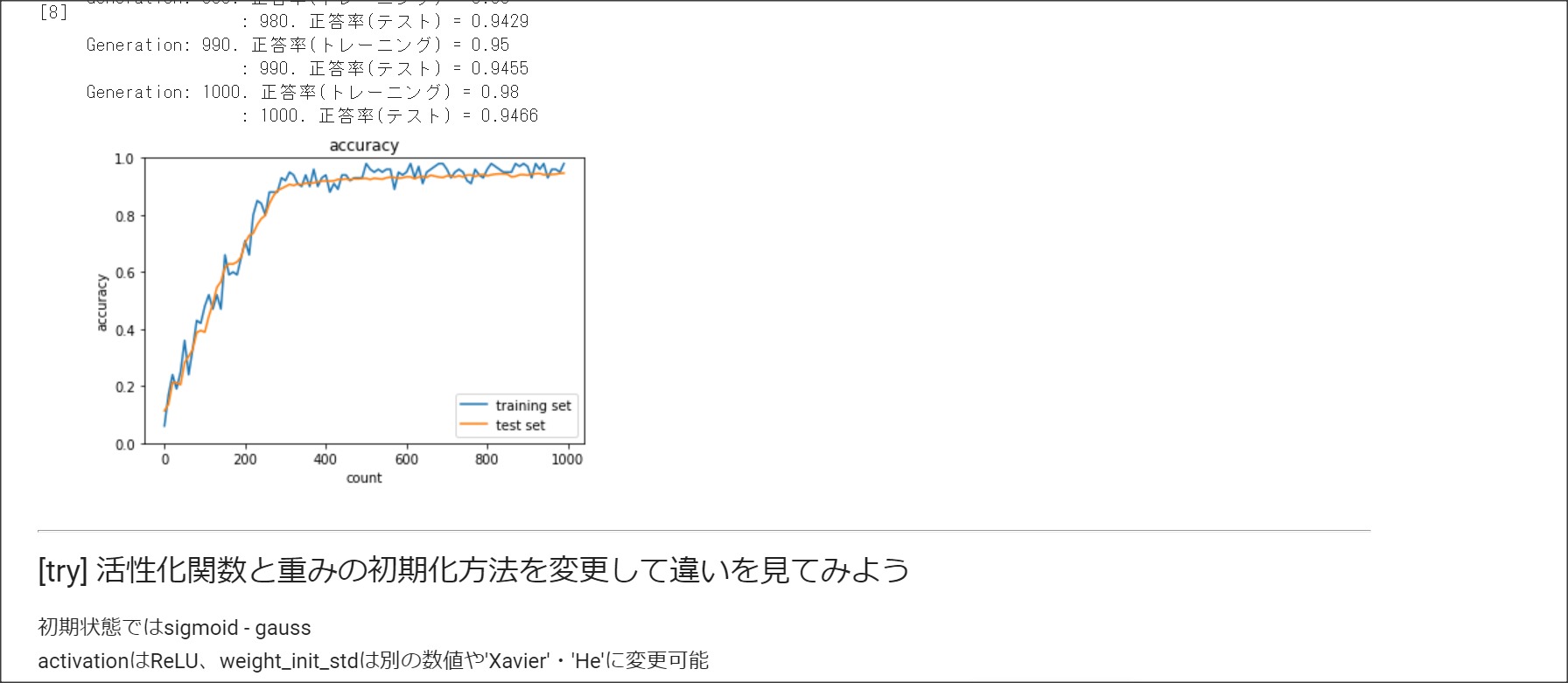

2_4_optimizer.ipynb

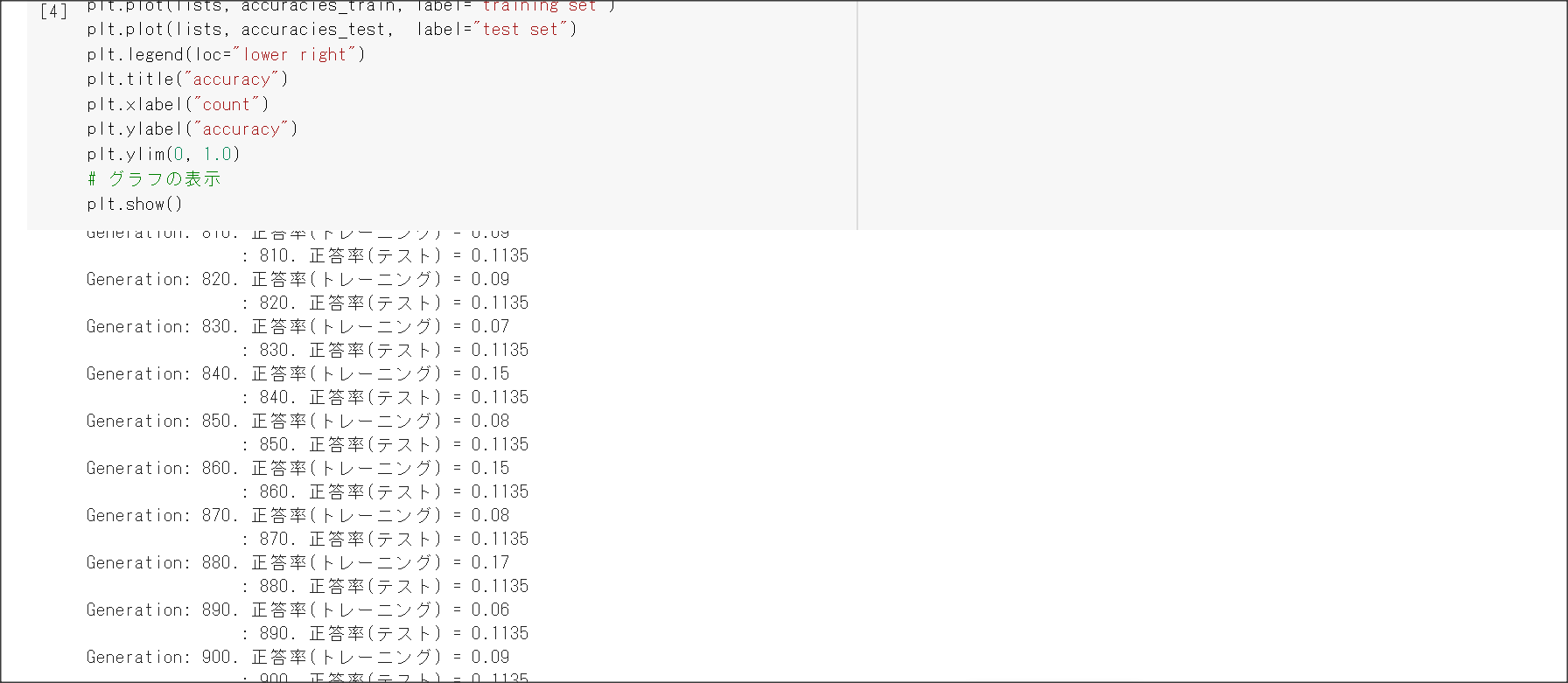

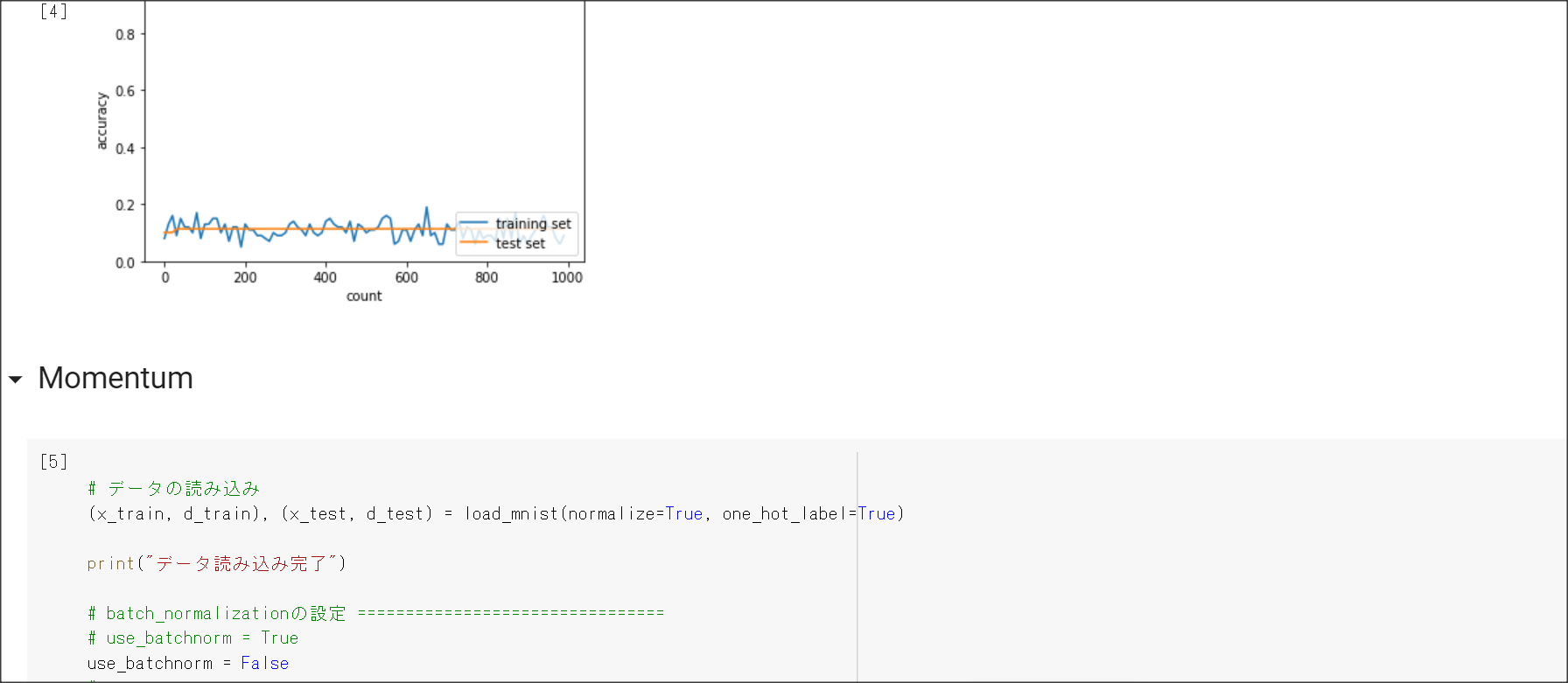
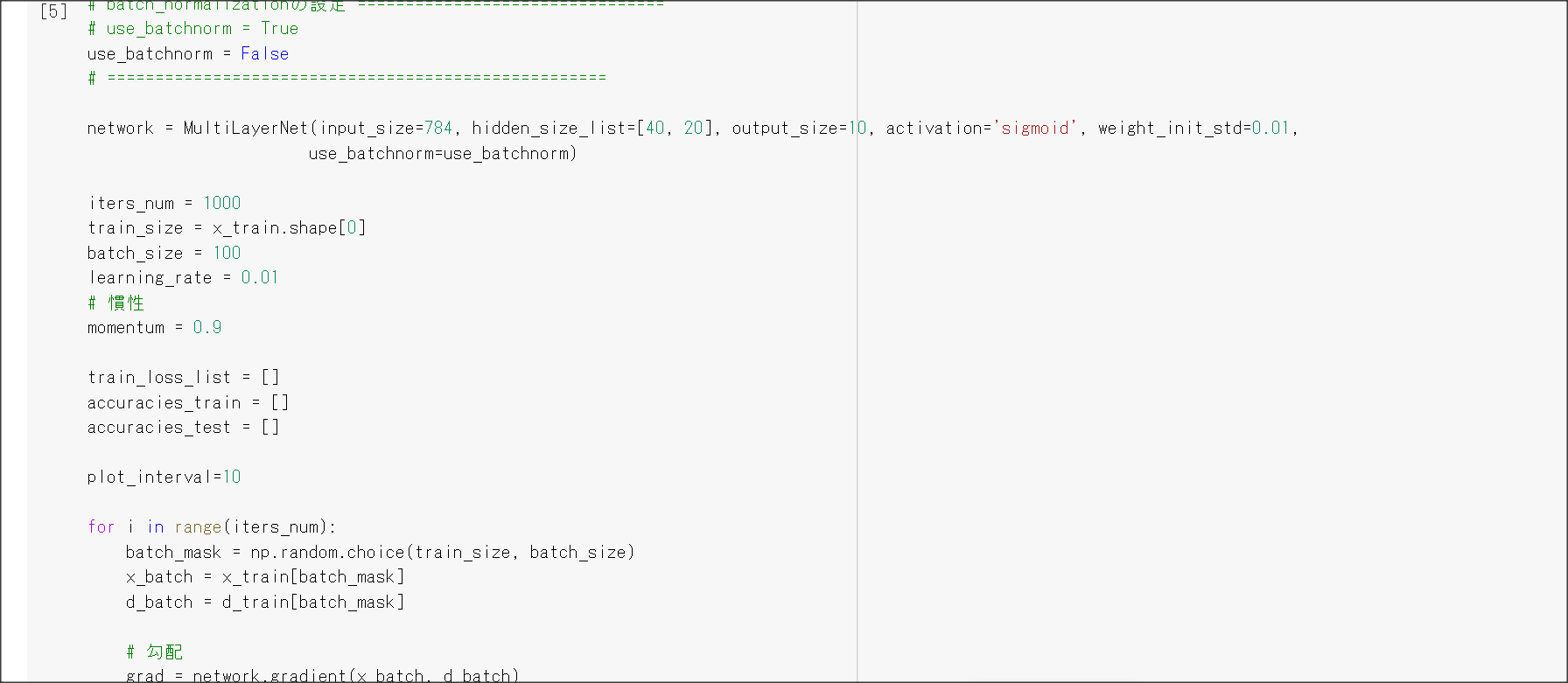


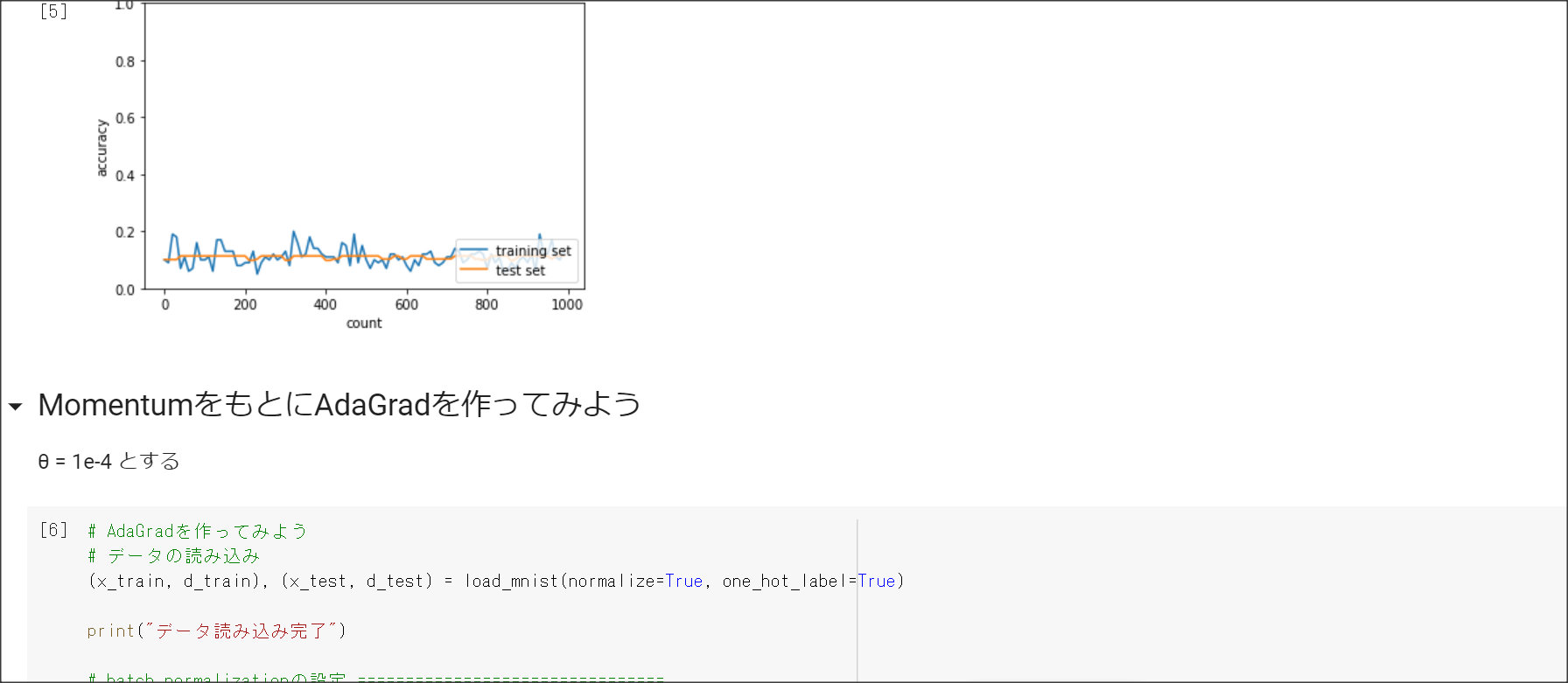


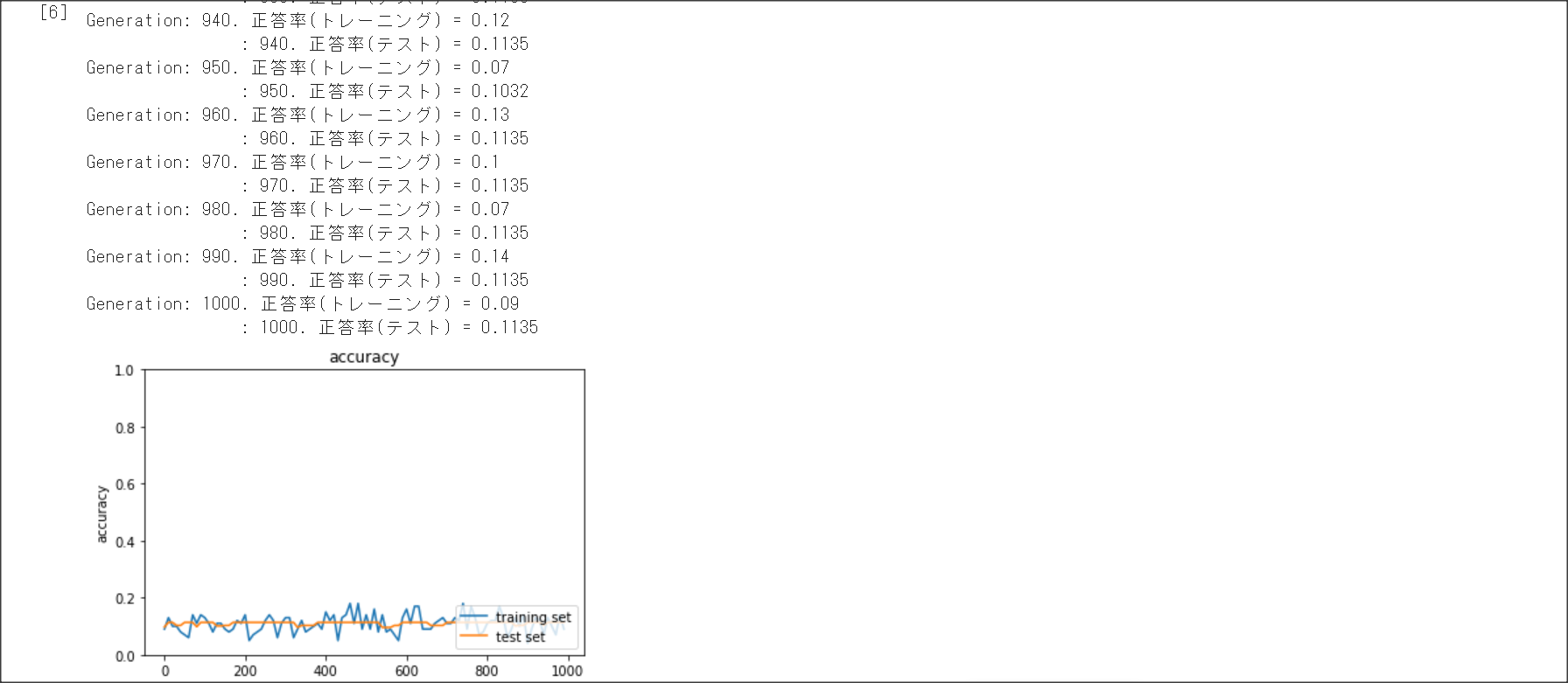

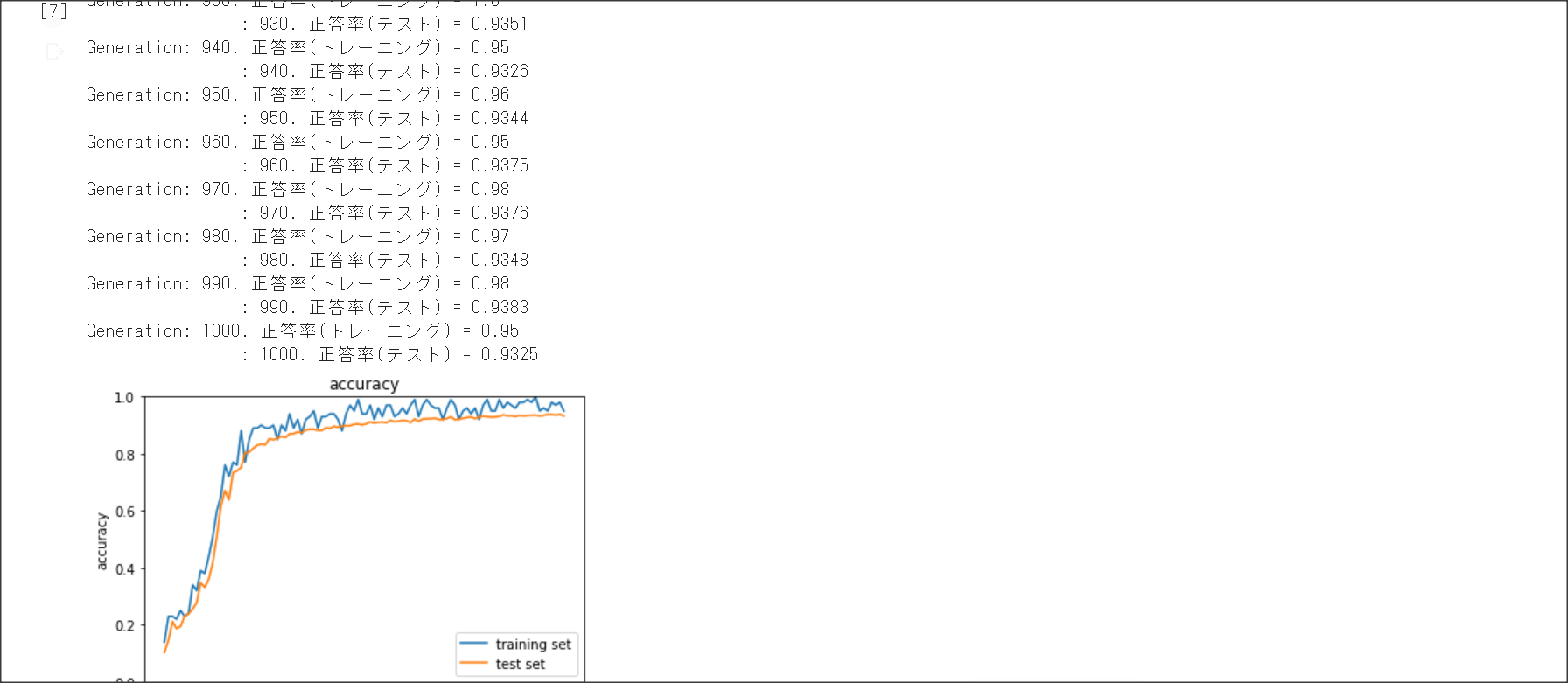

2_5_overfiting.ipynb

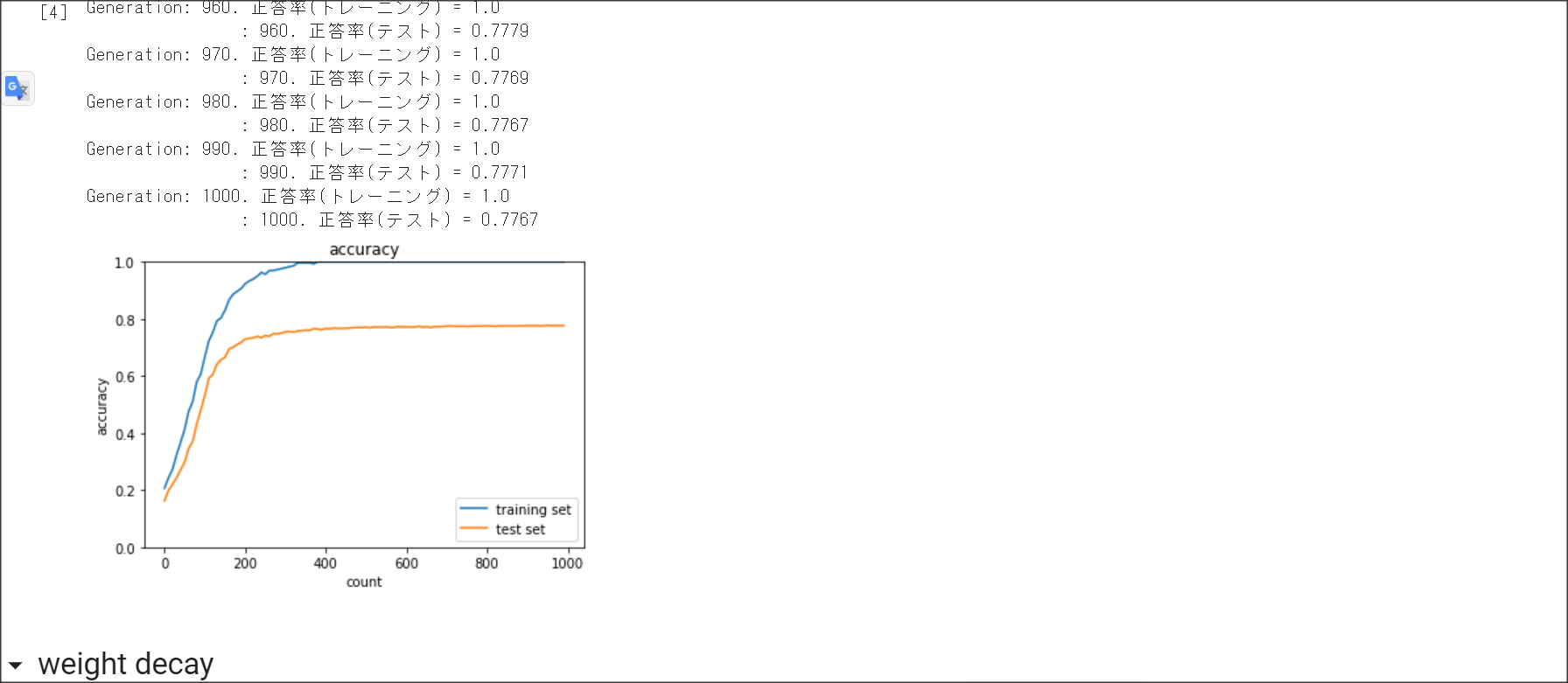

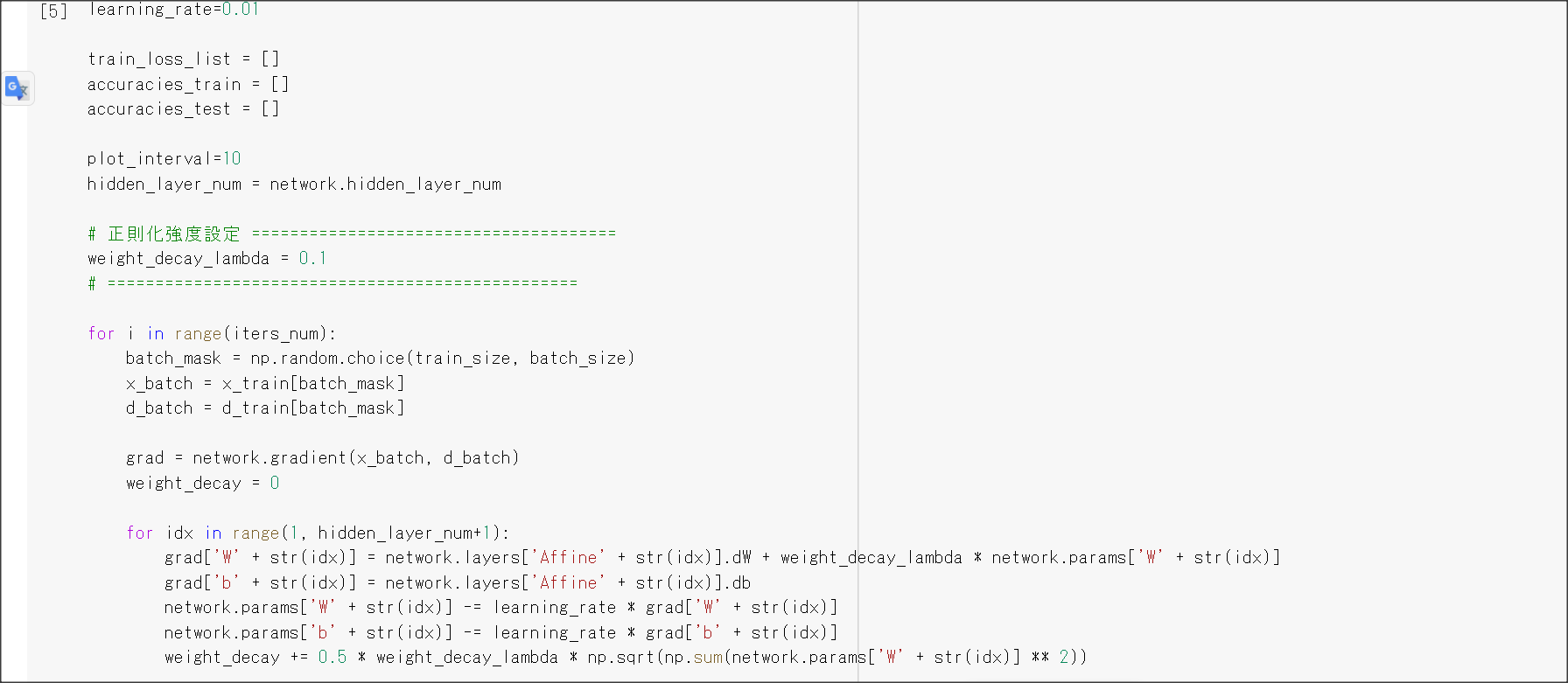





2_6_simple_convolution_network_after.ipynb

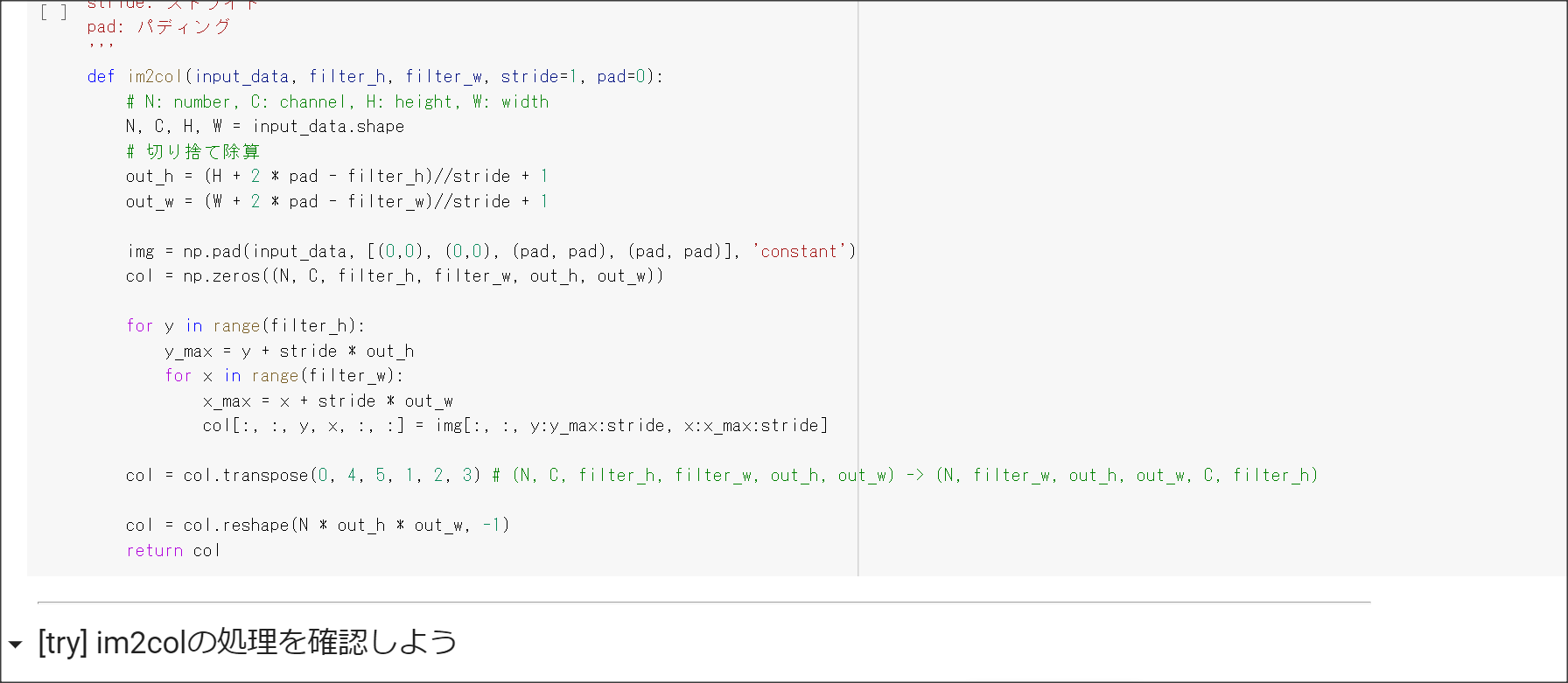
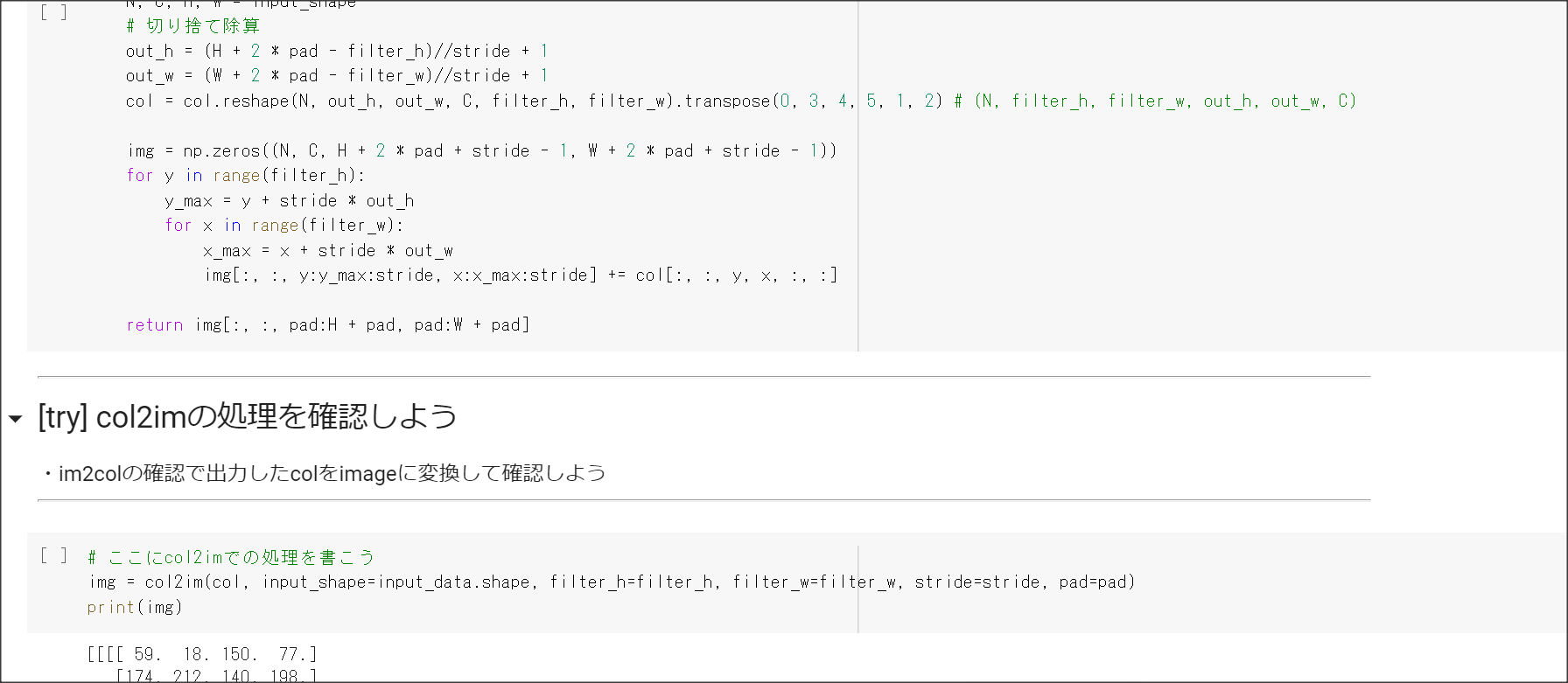
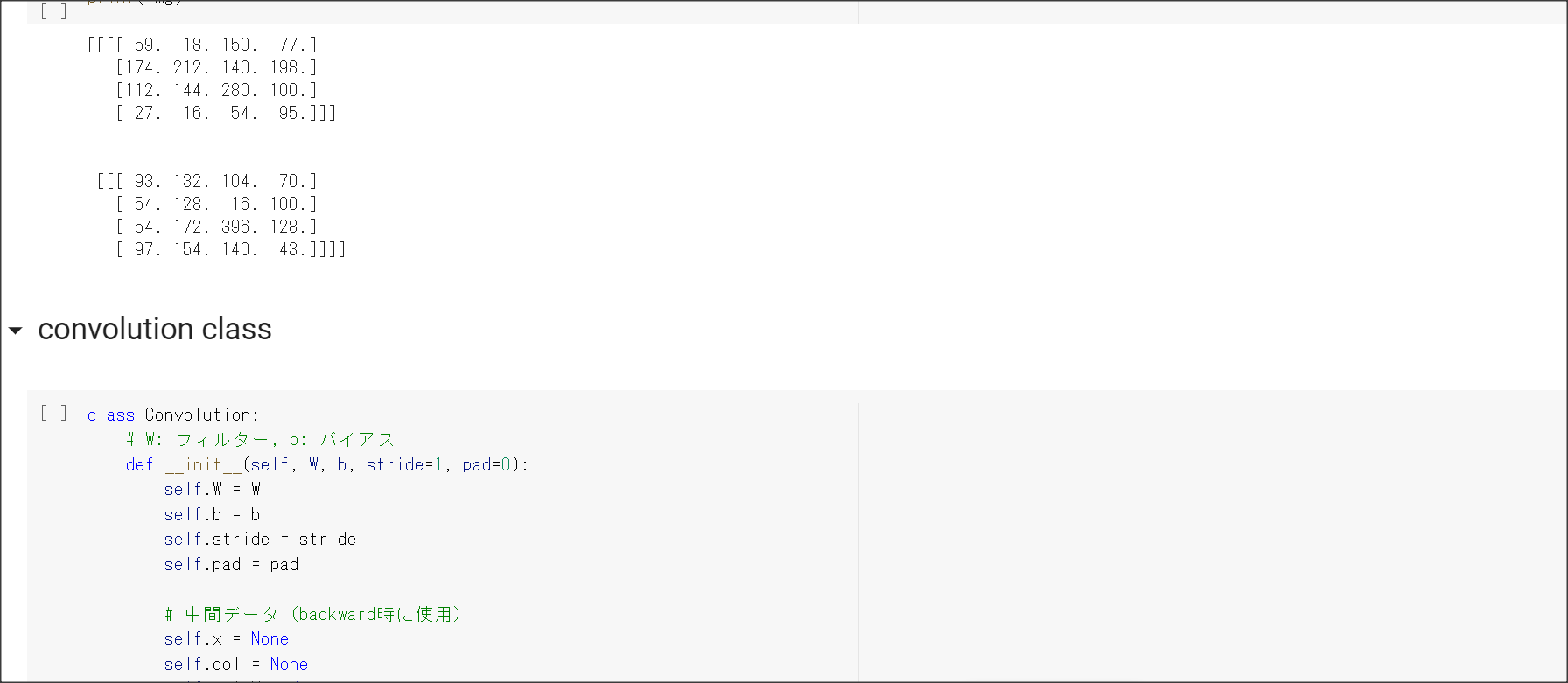

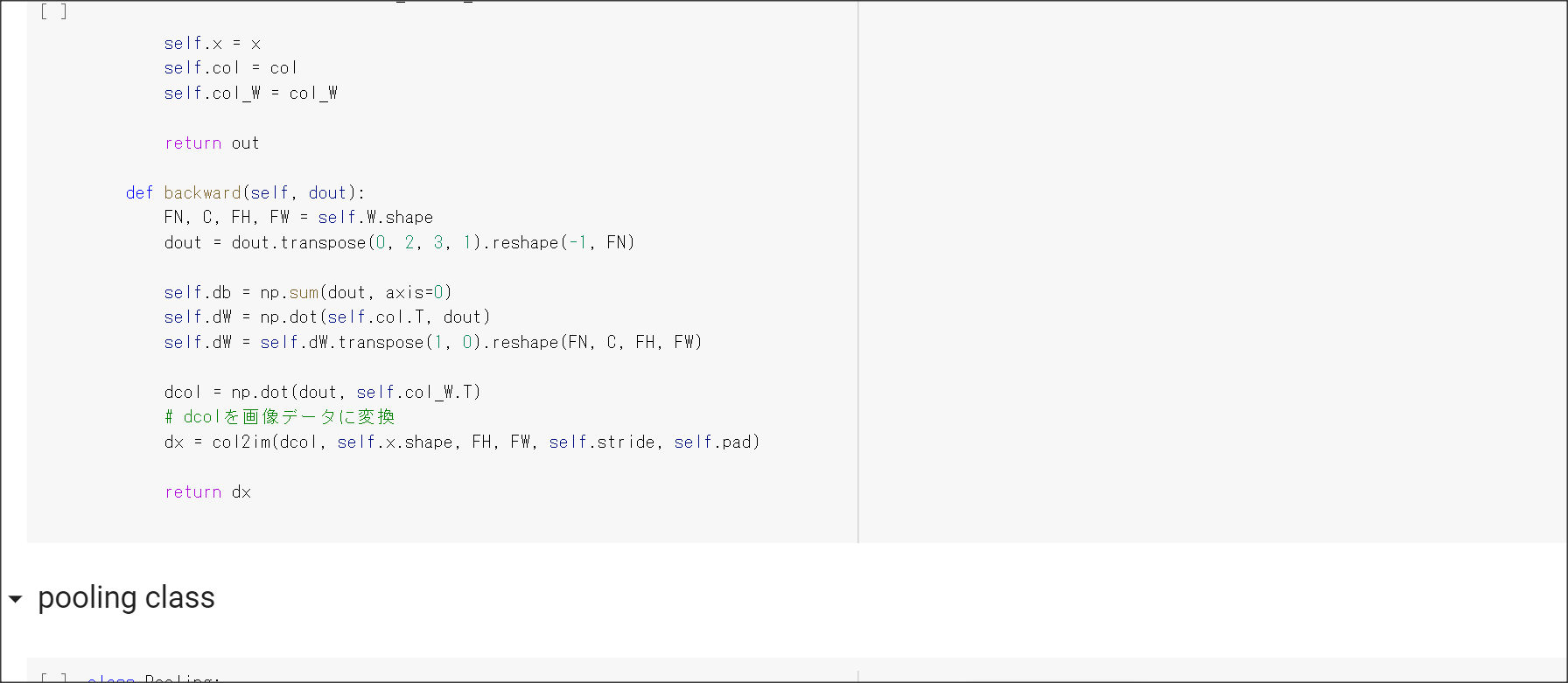
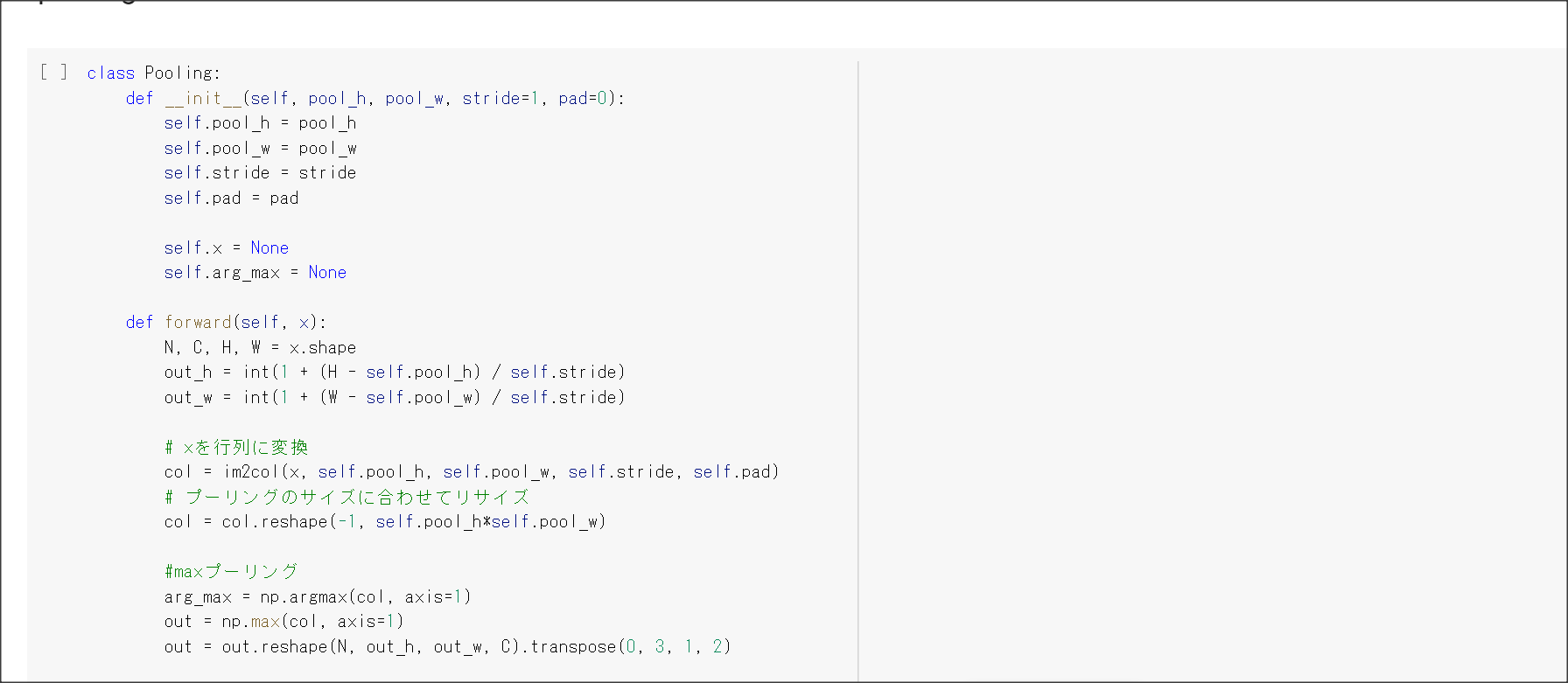

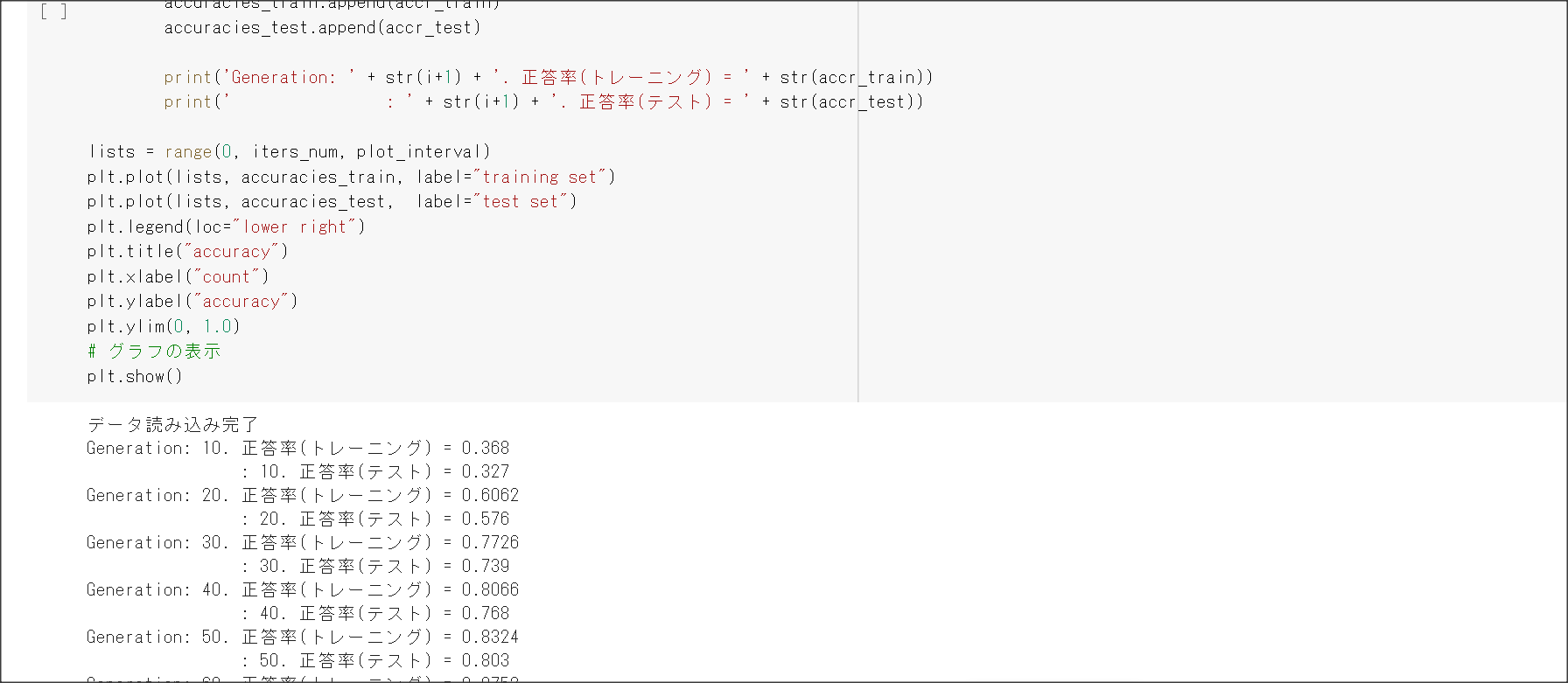



2_6_simple_convolution_network.ipynb

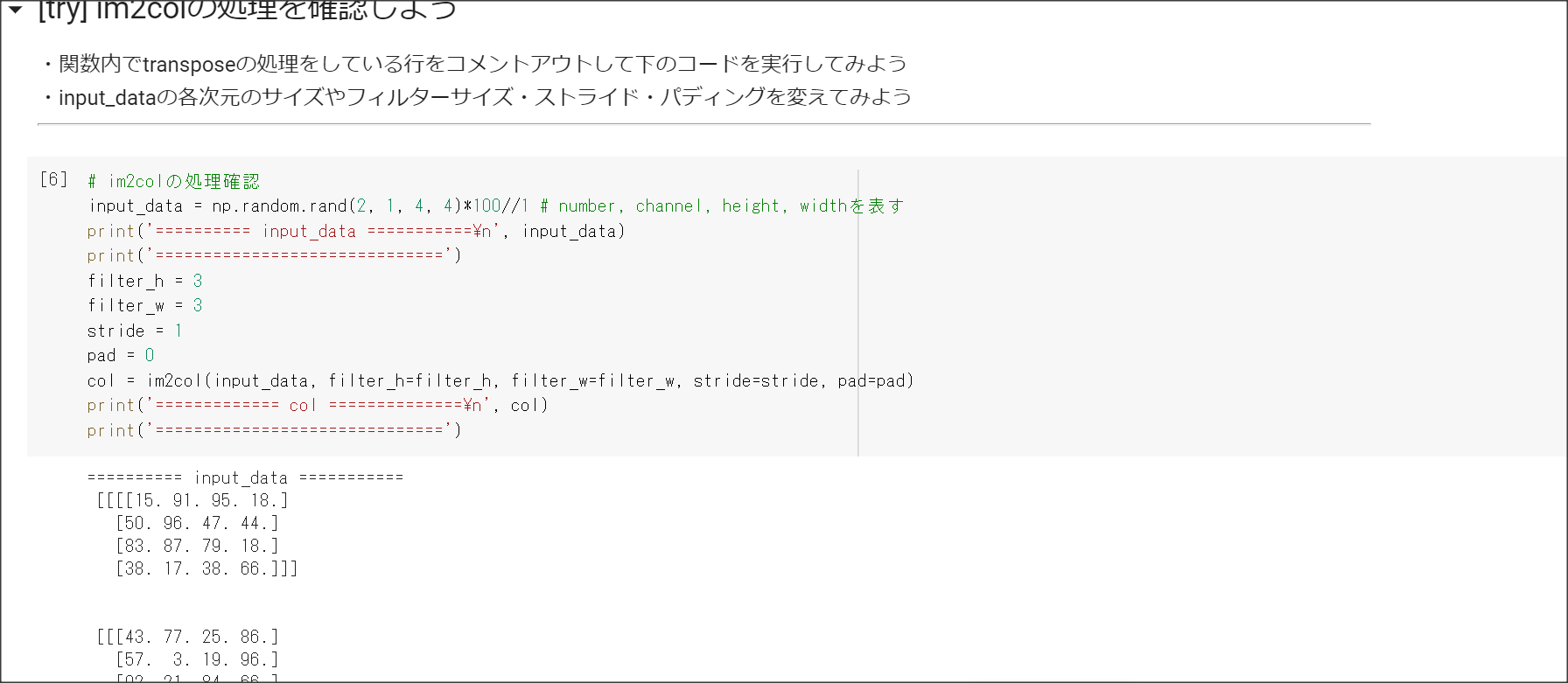
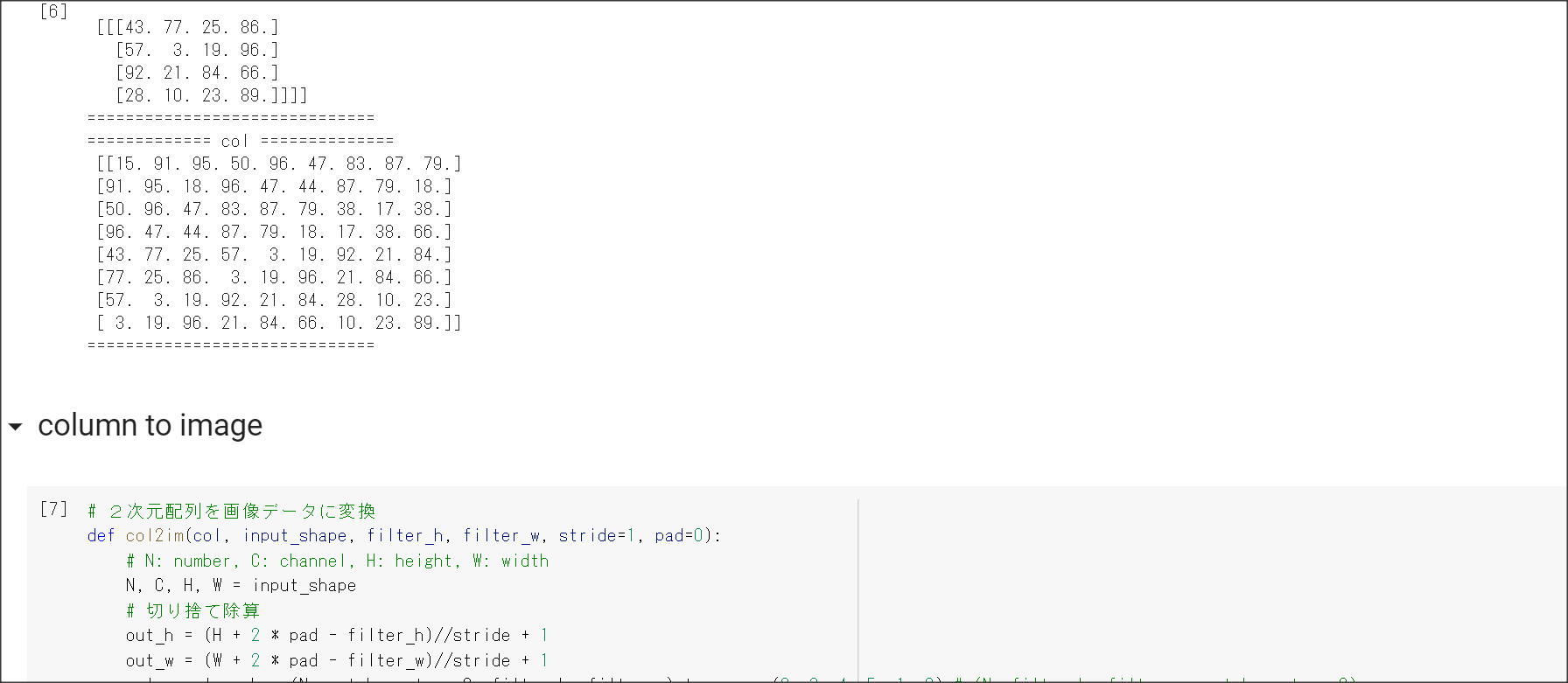
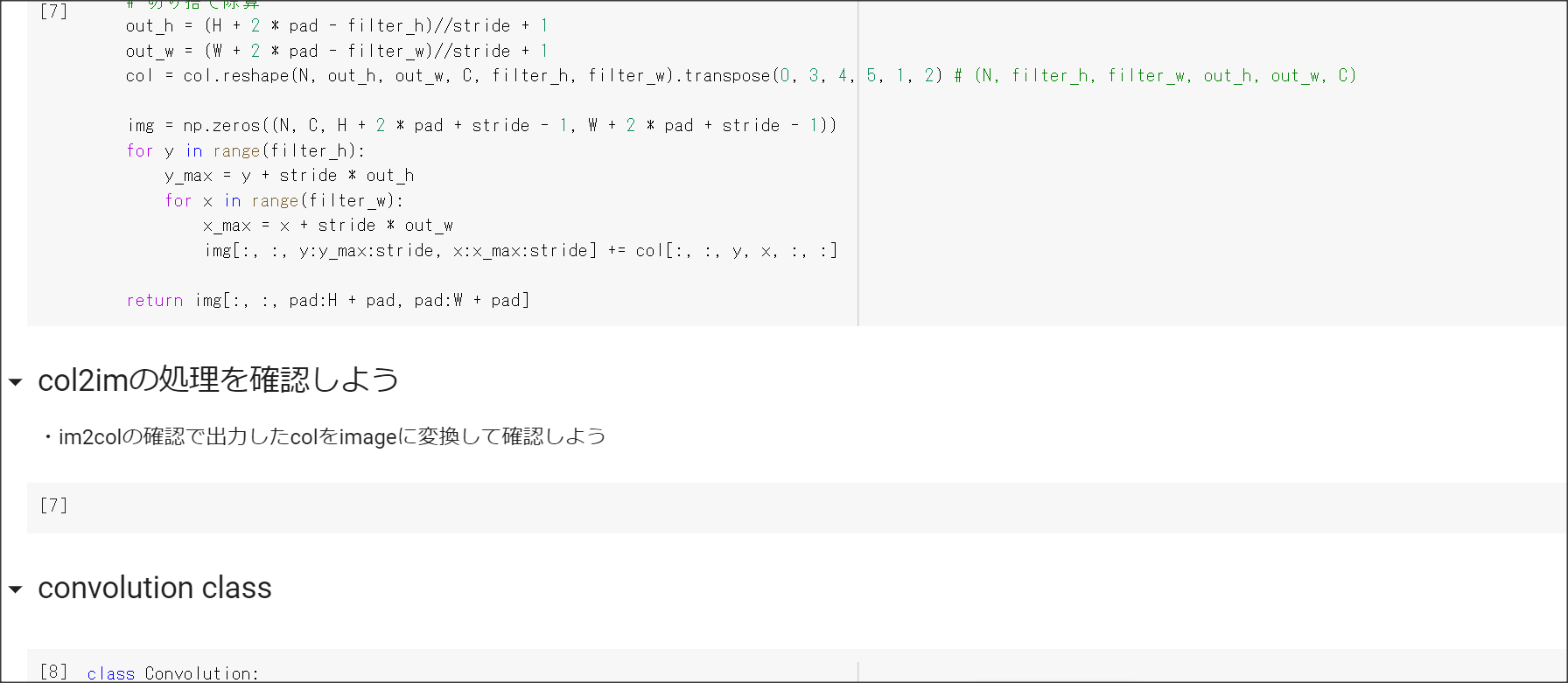
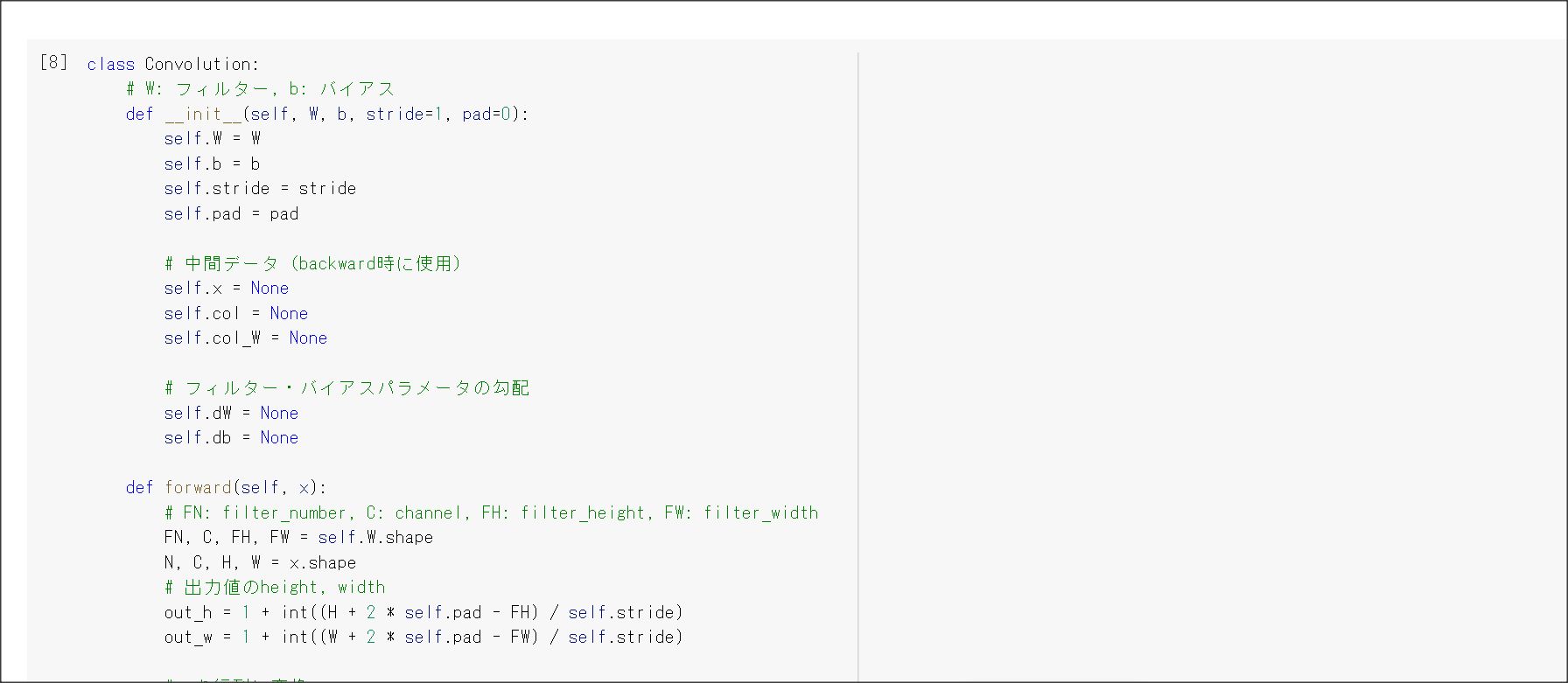
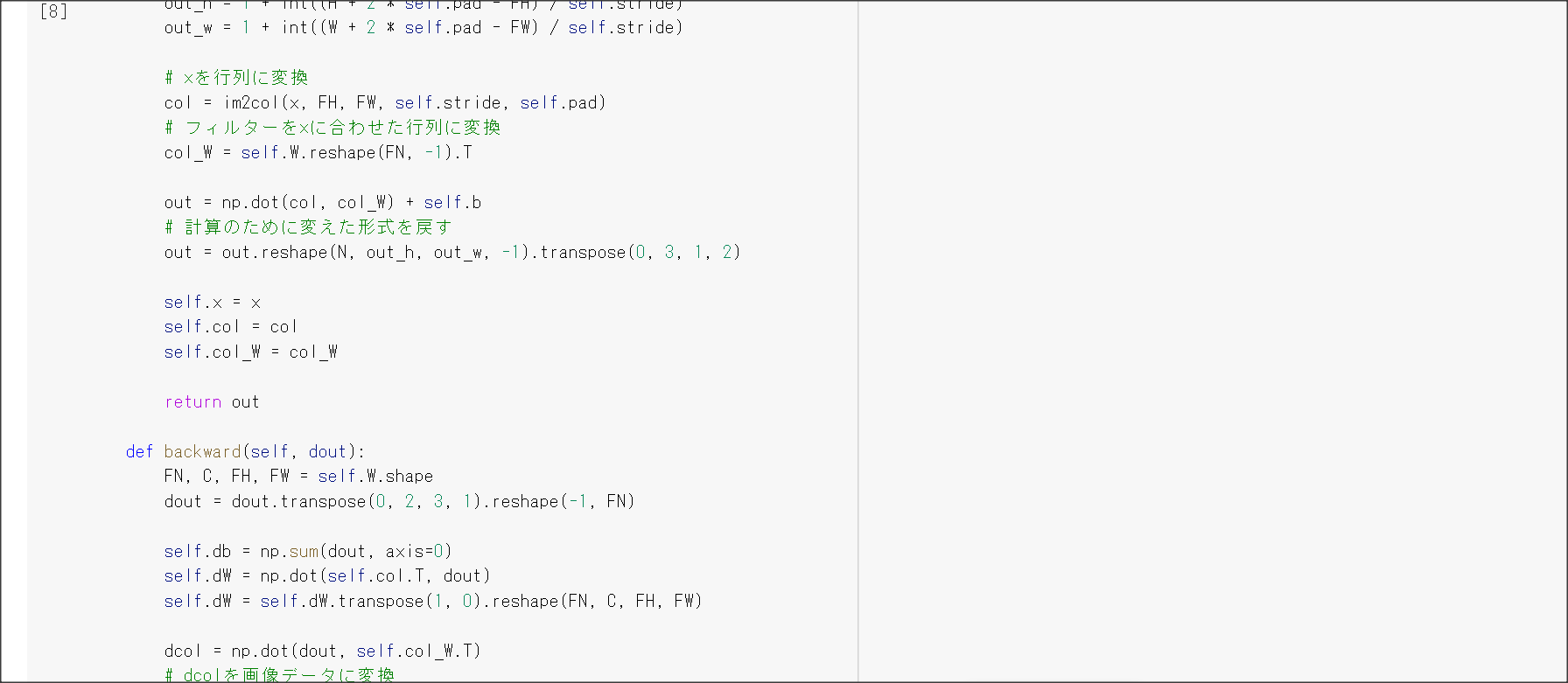

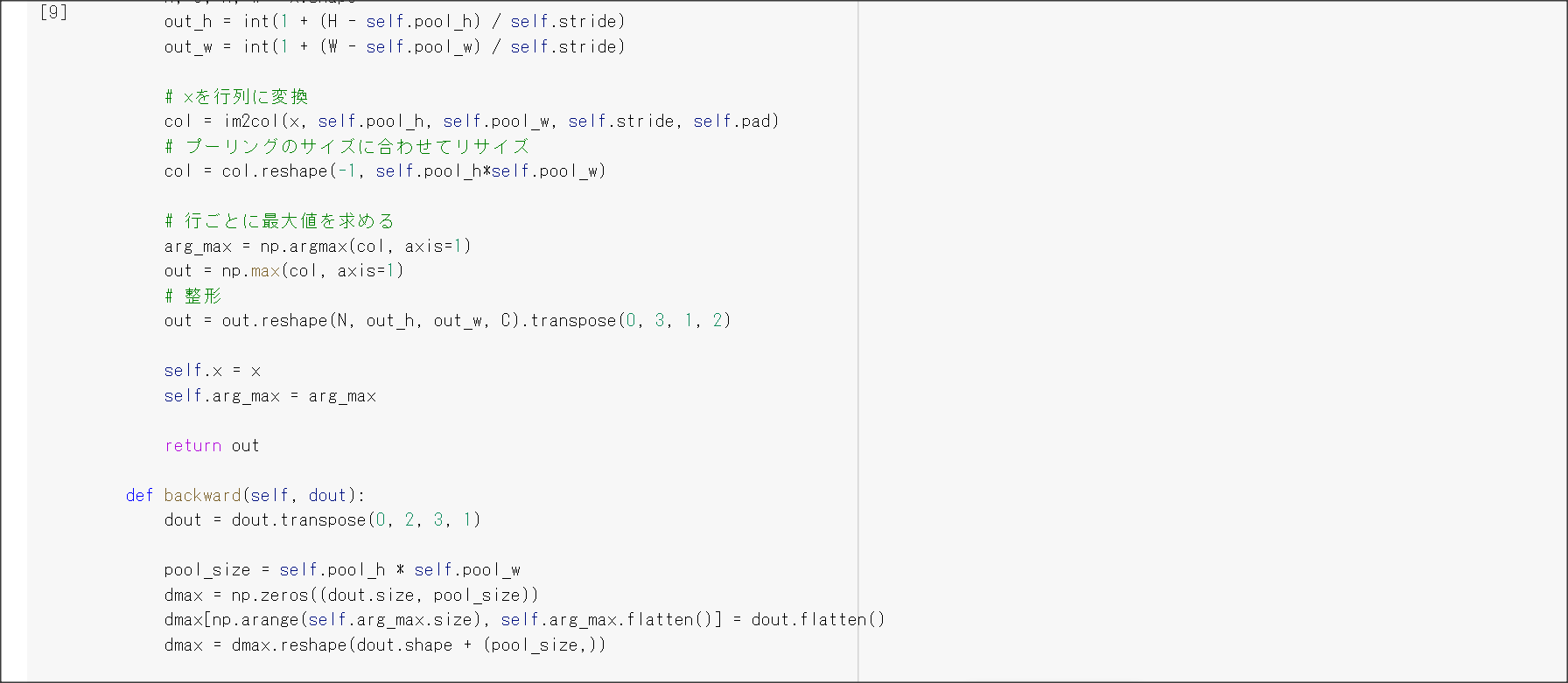
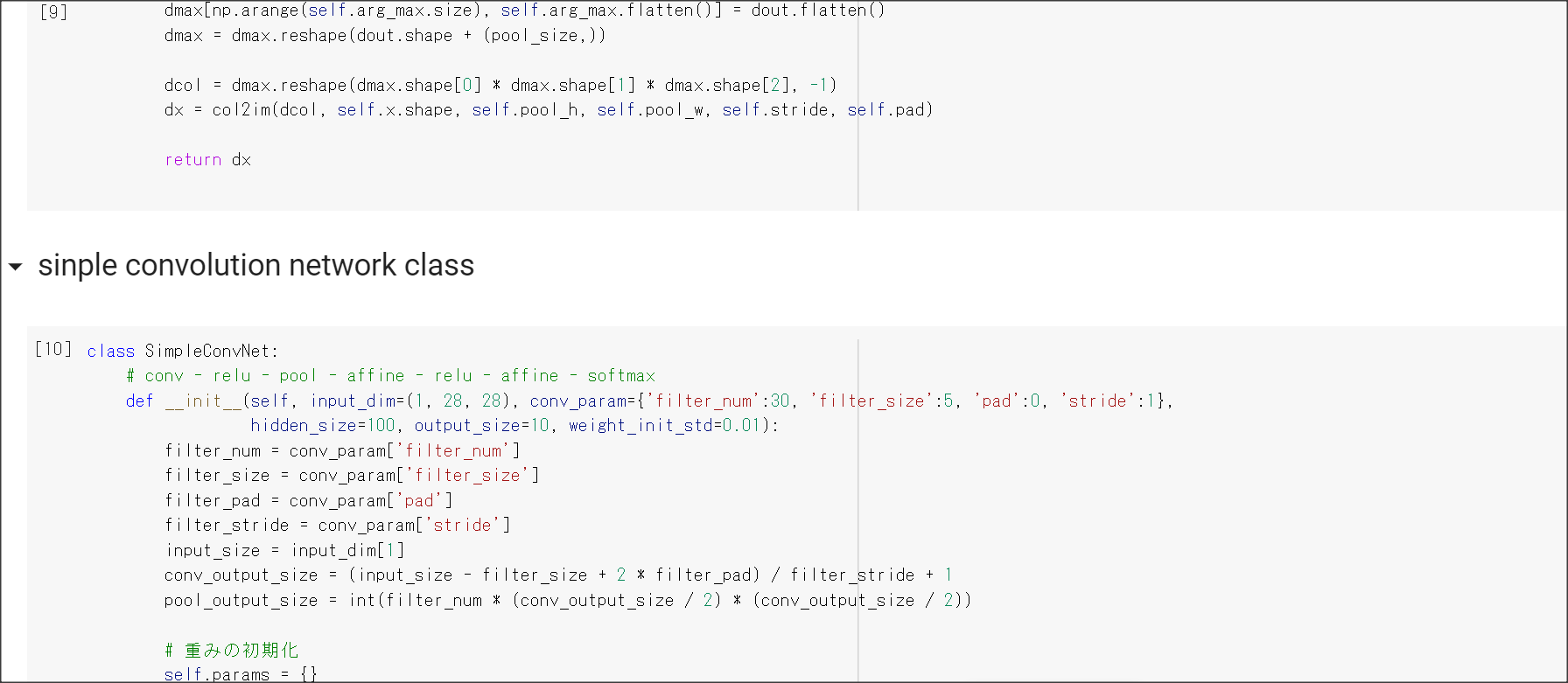





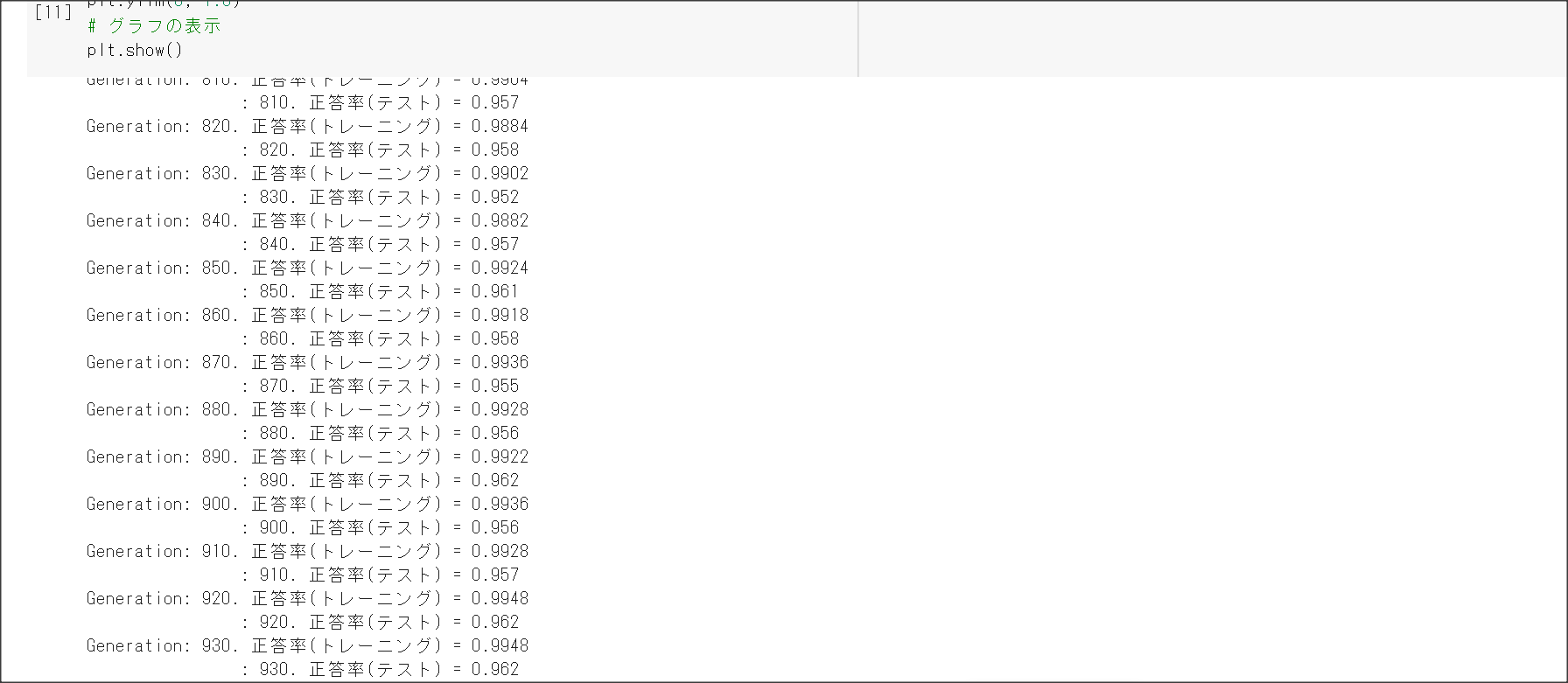
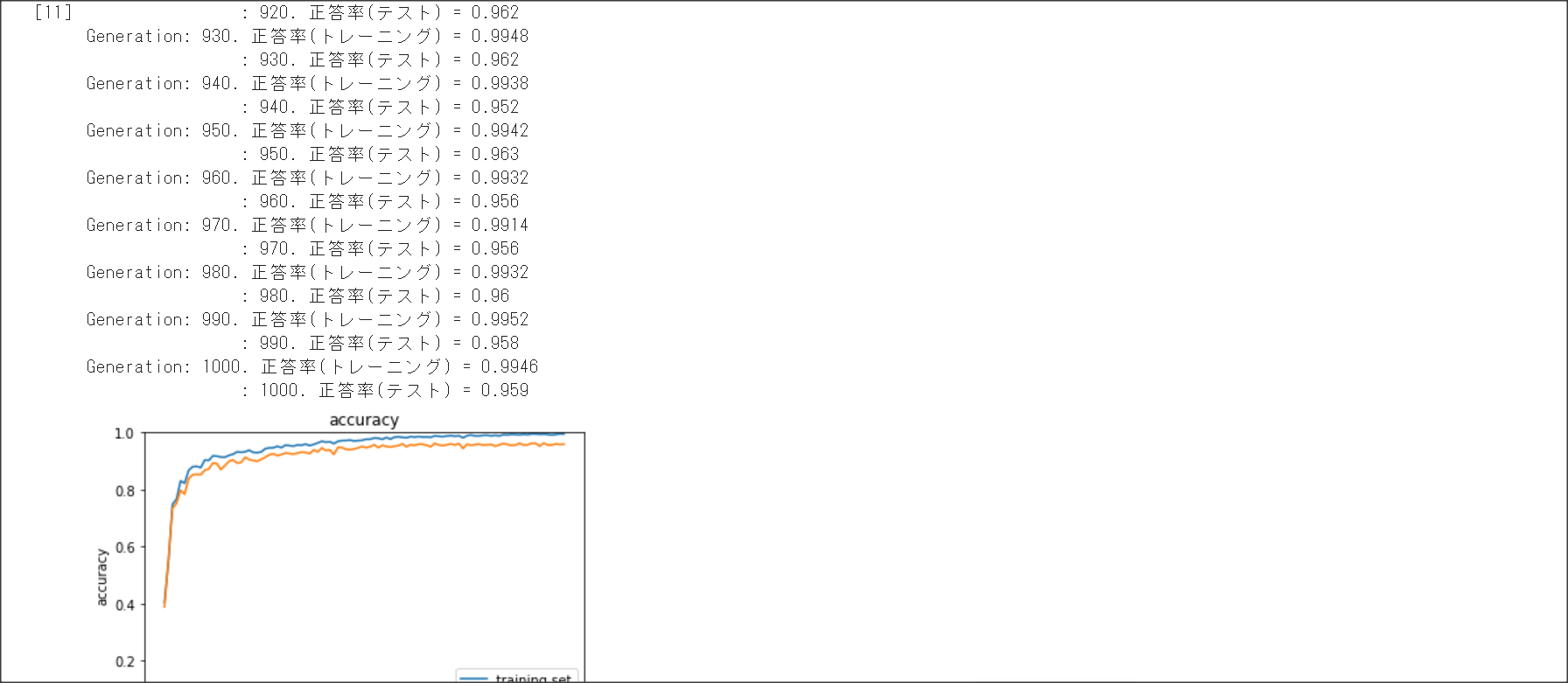
2_7_double_comvolution_network_after.ipynb
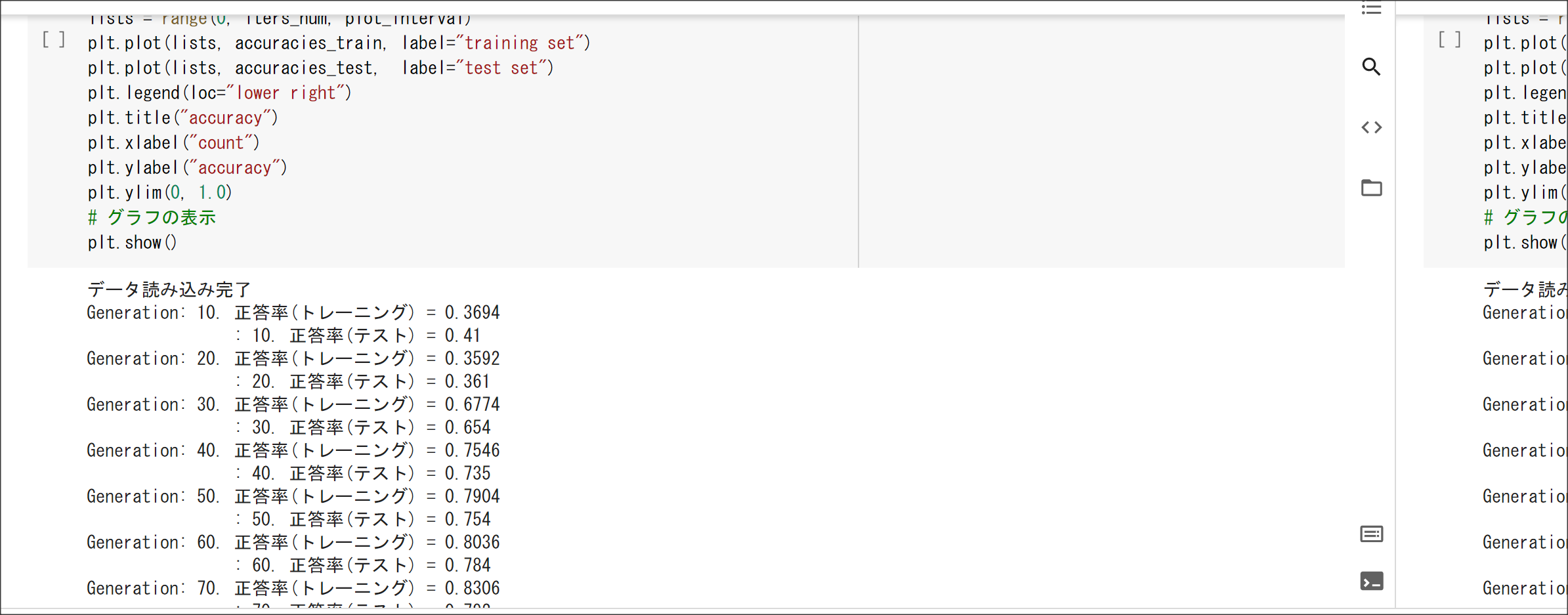
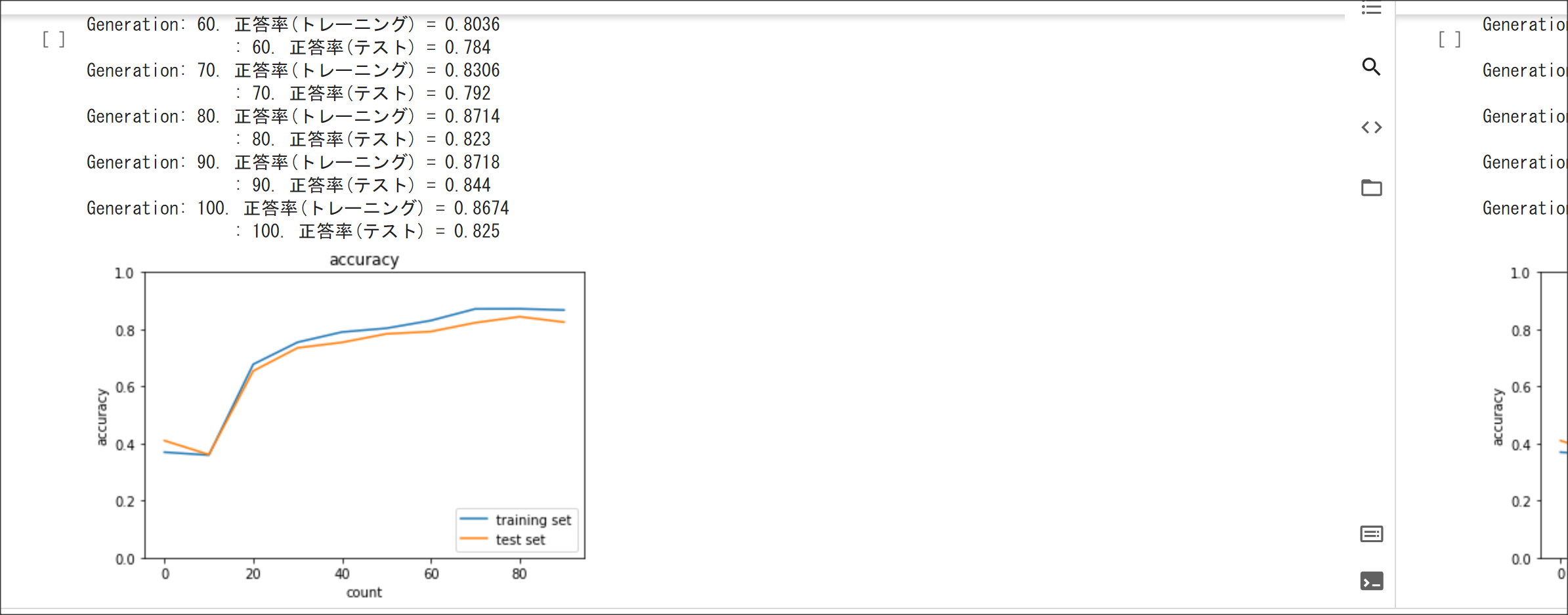
2_7_double_comvolution_network.ipynb
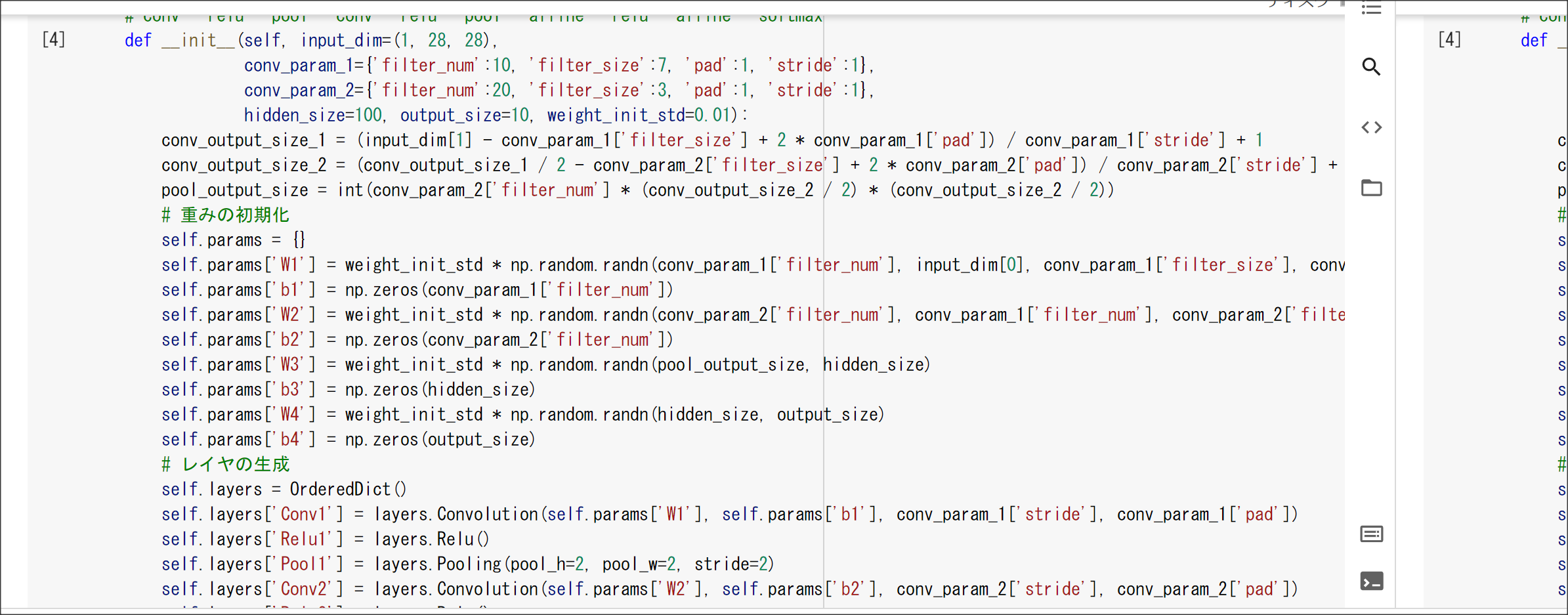
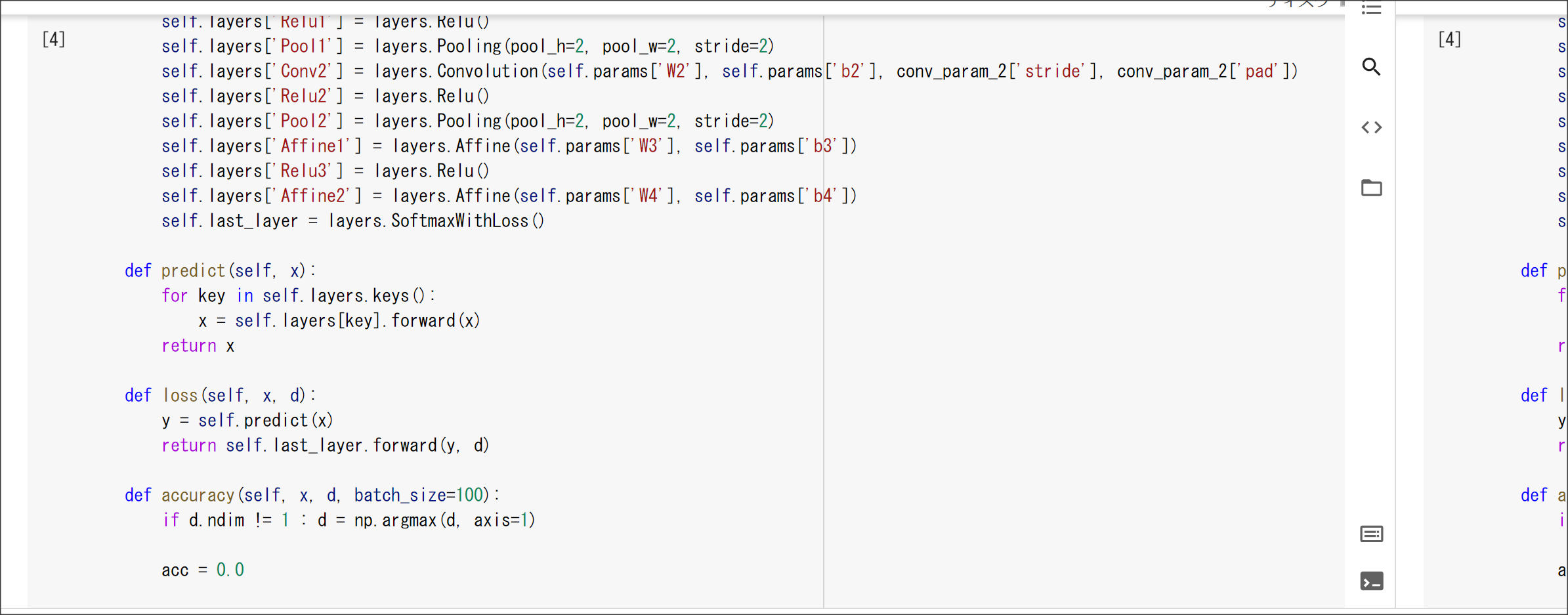
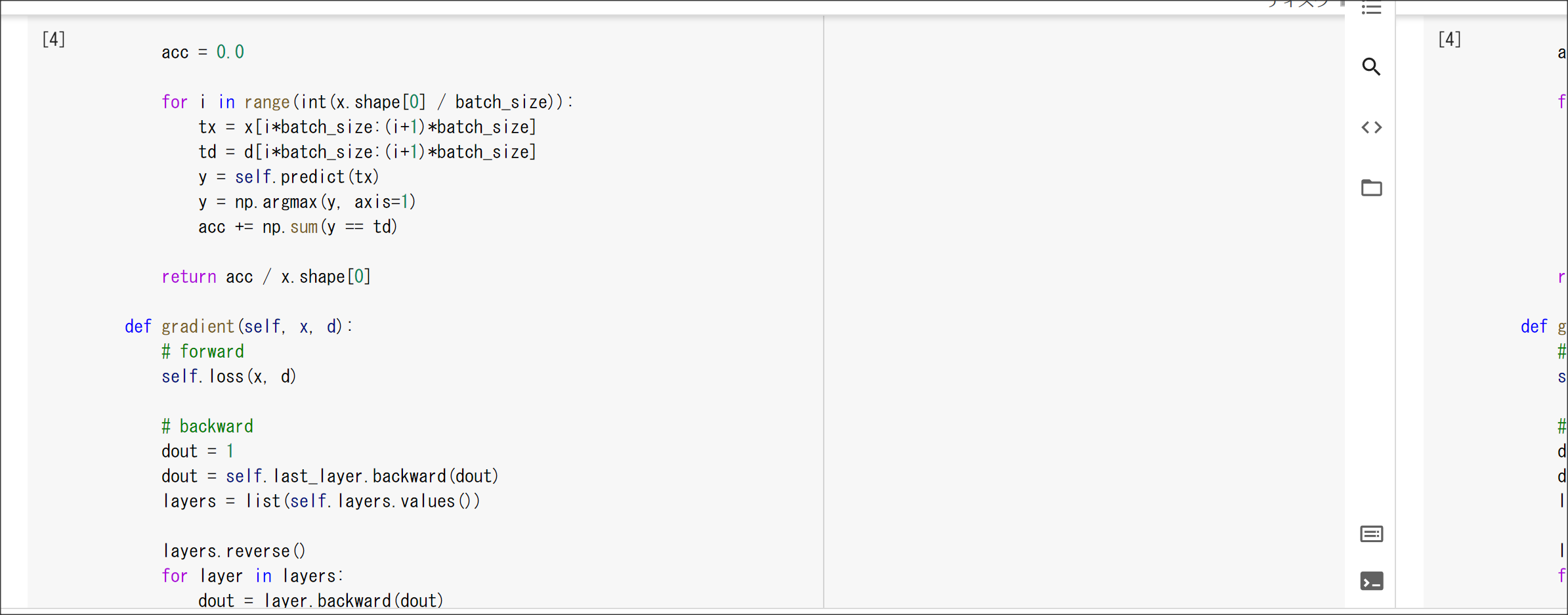
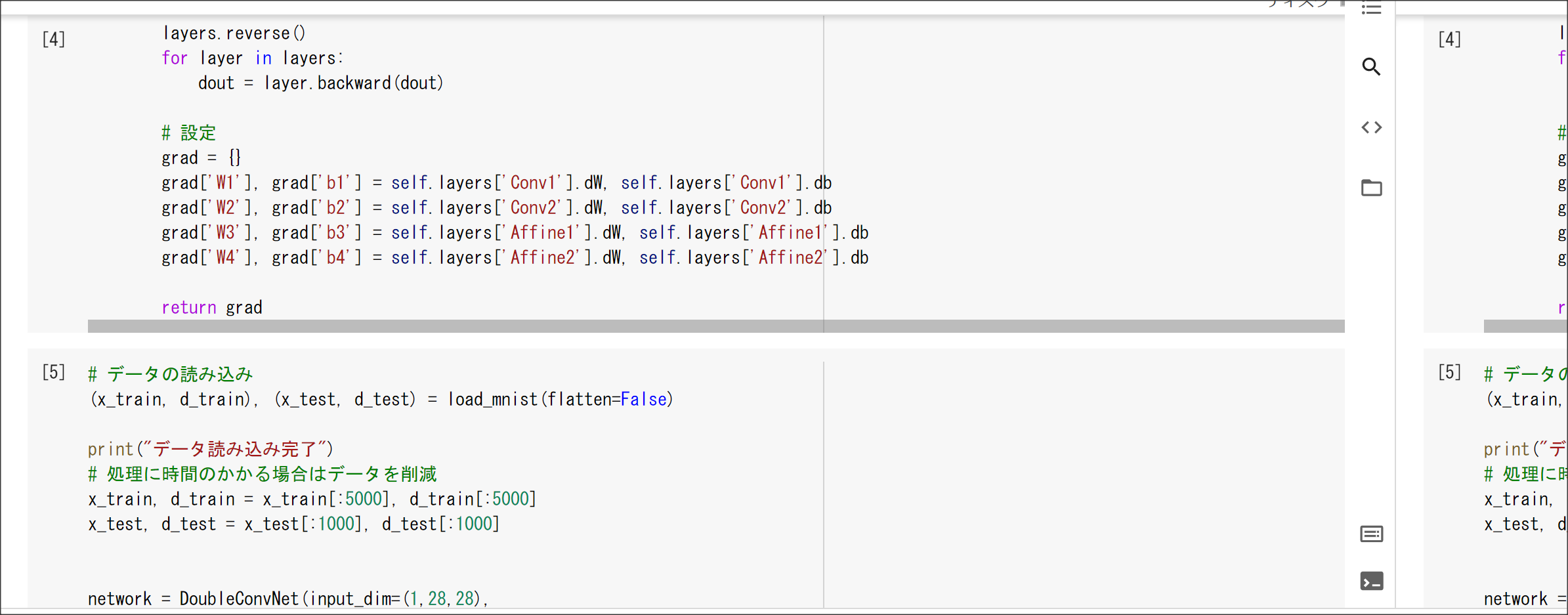
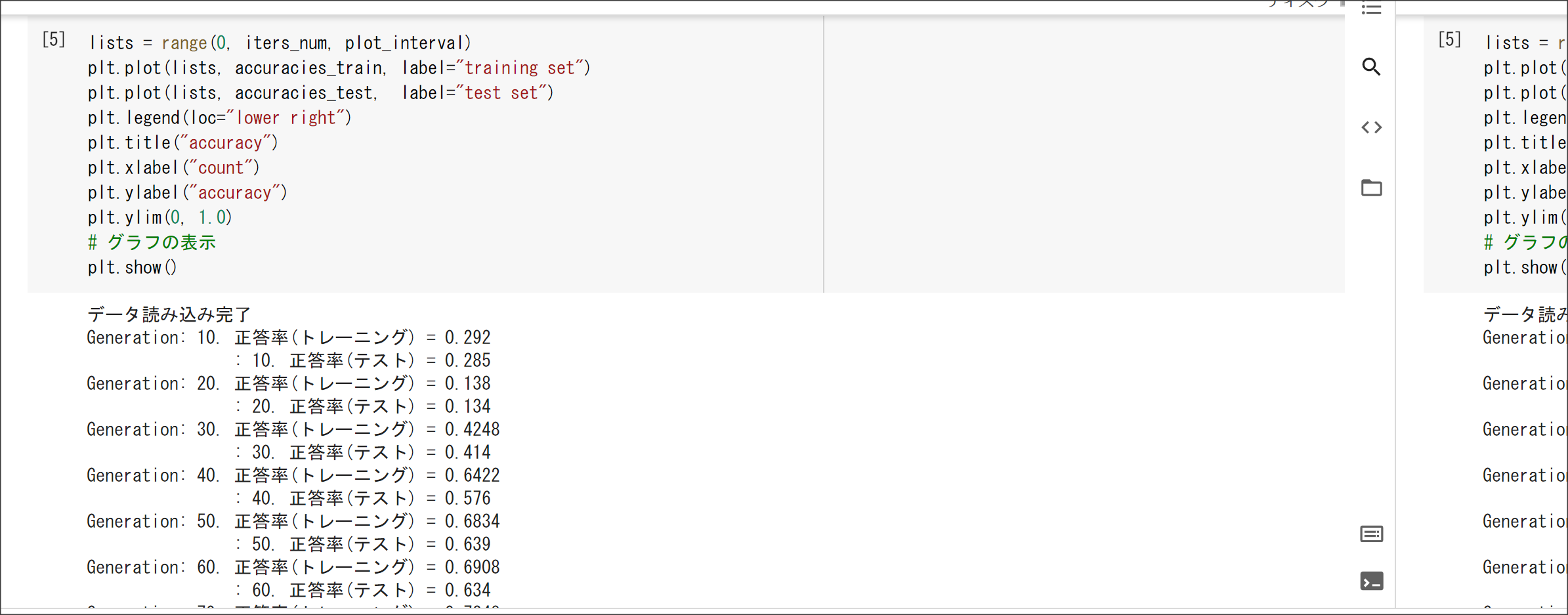
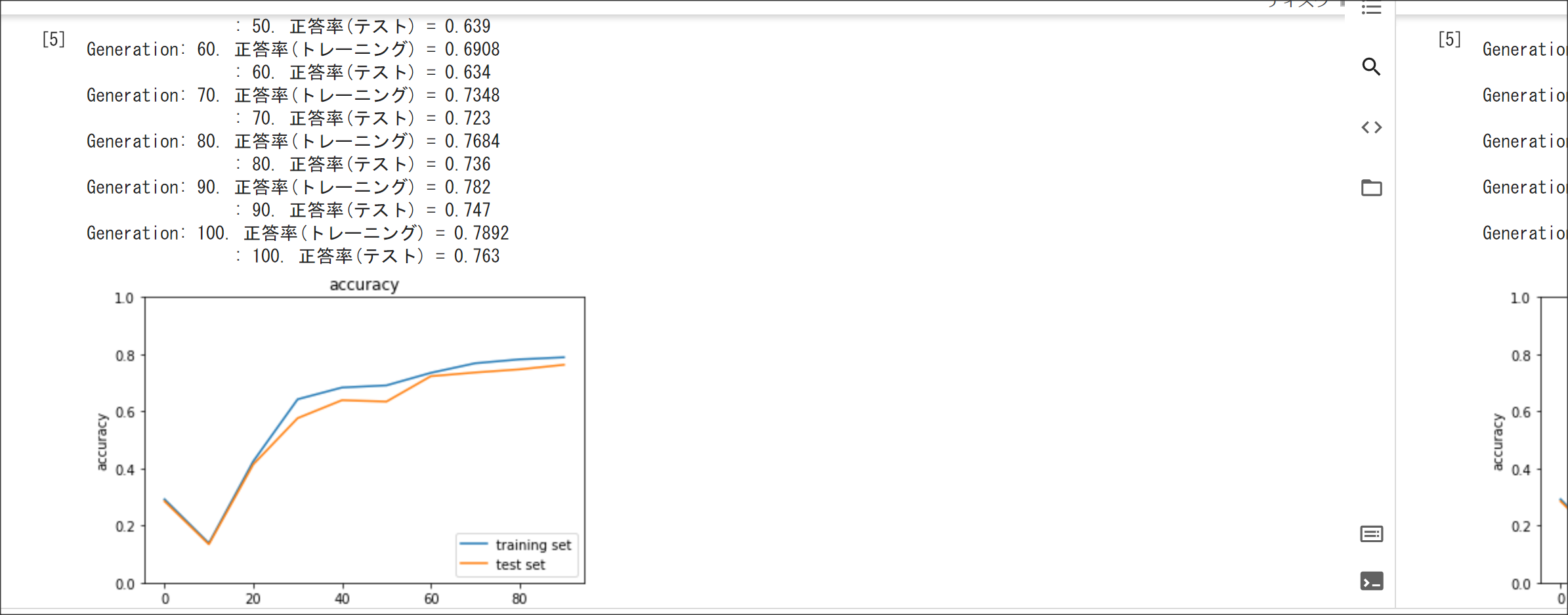
2_8_deep_convolution_net.ipynb