pythonでスクレイピングして新着ブログポストのタイトルとURLを取得するツールを作成しました。
作った理由
記事の投稿によって記憶の定着、文章力の向上に努めようということで、友人と2人で刺激しあうために、お互いの記事の新着情報をグループラインに通知するために作りました。
内容
新しく投稿された記事のタイトルとURLを取得します。
既存の投稿一覧のURLが保存されたtxtファイルを使用し、最新の投稿一覧のURLと比較します。
タイトルや内容の変更などは検知しないようにしています。(タイトルを変えただけで通知を送らないように)
Qiitaとはてなで使えるように作っているので、htmlが以下のような形式になっているページで使えると思います
<!-- aタグにclassあり。 aタグの要素としてタイトルが書かれている -->
<a class='articles' href='#'>Title</a>
条件
- 記事の一覧を表示するページがあること
- 各記事の
<a>タグに、共通するselecterが設定されていること - タイトルはaタグの要素として書かれていること
- あらかじめ空の.txtファイルを作成しておくこと
コード全体
import requests, bs4
def new_post_getter(url, selecter, txt):
'''
記事タイトル及びURLのbs4_elementを取得
第1引数 : 投稿一覧のあるページのURL
第2引数 : 各投稿の<a>タグに付与されているセレクター 頭に.をつけて
第3引数 : 記録用txtのpath
'''
res = requests.get(url)
posts = bs4.BeautifulSoup(res.text, 'html.parser').select(selecter)
now_posts_url = [] #1 取得した記事一覧のURLのリスト, 今までの投稿データと比較し、新着投稿を割り出すために使う
now_posts_url_title_set = [] # 取得した記事一覧のURLとタイトルのリスト、
for post in posts:
# URLを抽出
index_first = int(str(post).find('href=')) + 6
index_end = int(str(post).find('">'))
url = (str(post)[index_first : index_end])
# タイトルを抽出
index_first = int(str(post).find('">')) + 2
index_end = int(str(post).find('</a'))
title = (str(post)[index_first : index_end].replace('\u3000', ' ')) # 空白置換
now_posts_url.append(url)
now_posts_url_title_set.append(f"{url}>>>{title}")
old_post_text = open(txt)
old_post = old_post_text.read().split(',') # テキストファイルからリスト型へ
# differences : 投稿済だが一覧画面に表示されていない投稿 + 新しい投稿
differences = list(set(now_posts_url) - set(old_post))
old_post_text.close()
# 記録用txtを上書き all_postsは過去の投稿 + 新しい投稿
all_posts = ",".join(old_post + differences)
f = open(txt, mode='w')
f.writelines(all_posts)
f.close()
new_post_info = []
for new in now_posts_url_title_set:
for incremental in differences:
if incremental in new:
new_post_info.append(new.split(">>>"))
return new_post_info
使い方
記事一覧のページ,各記事のaタグに付与されているセレクタ,投稿状況を保存するtxtファイルのパスを引数に指定します
★使ってみる
url = 'https://qiita.com/takuto_neko_like'
selecter = '.u-link-no-underline'
file = 'neko.txt'
my_posts = new_post_getter(url, selecter, file)
print(my_posts)
上記のようにすることで...
[['/takuto_neko_like/items/93b3751984e5e3fd3670', 'fishが重い'], ['/takuto_neko_like/items/14e92797fa2b23a64adb', '【Python】多重継承で継承するものは何?']]
URLとタイトルをリストにした二重リストを得られます。
[ [ URL, タイトル ], [ URL, タイトル ], [ URL, タイトル ], ....... ]
2重リストをfor文で回して、文字列を整形することで...
for url, title in my_posts:
print(f'{title} : {url}')
みやすく出力↓
fishの動きが遅い : /takuto_neko_like/items/93b3751984e5e3fd3670
【Python】多重継承で継承するものは何? : /takuto_neko_like/items/14e92797fa2b23a64adb
ちなみに
neko.txtの中身はこのようになっています。
/takuto_neko_like/items/93b3751984e5e3fd3670,/takuto_neko_like/items/14e92797fa2b23a64adb,/takuto_neko_like/items/bb8d0957347636b5bf4f,/takuto_neko_like/items/62aeb4271614f6f0347f,/takuto_neko_like/items/c9c80ff453d0c4fad239,/takuto_neko_like/items/aed9dd5619d8457d4894,/takuto_neko_like/items/6cf9bade3d9515a724c0
URLのリストが入ってます。1つ目と最後を削除してみて...
/takuto_neko_like/items/14e92797fa2b23a64adb,/takuto_neko_like/items/bb8d0957347636b5bf4f,/takuto_neko_like/items/62aeb4271614f6f0347f,/takuto_neko_like/items/c9c80ff453d0c4fad239,/takuto_neko_like/items/aed9dd5619d8457d4894
実行すると...
my_posts = new_post_getter(url, selecter, file)
print(my_posts)
結果↓
[['/takuto_neko_like/items/c5791f267e0964e09d03', '新着記事を取得するツールを作って学んだこと'], ['/takuto_neko_like/items/93b3751984e5e3fd3670', 'fishの動きが遅い'], ['/takuto_neko_like/items/6cf9bade3d9515a724c0', '【Python】@classmethod及びデコレータとは?']]
差分だけを取得します
やっていること
- 記事一覧ページから、表示されているすべての記事の
<a>タグを取得する - 取得した
<a>タグの中からURLを抽出する。又、別でURLとタイトルのセットも抽出。 - 既存の投稿一覧(txt)を使い、2.で得たURLと比較。差分を抽出する。
- 新しい投稿のURLと、既存の投稿記録を1つにして、txtを上書きする
- 2.で取得しておいたURLとタイトルのセットから、差分に該当したモノだけを抽出。整形しやすいように2重リスト型にする
各コード
1. 記事一覧ページから、表示されているすべての記事の<a>タグを取得
import requests, bs4
def new_post_getter(url, selecter, txt):
'''
記事タイトル及びURLのbs4_elementを取得
第1引数 : 投稿一覧のあるページのURL
第2引数 : 各投稿の<a>タグに付与されているセレクター 頭に.をつけて
第3引数 : 記録用txtのpath
'''
res = requests.get(url)
posts = bs4.BeautifulSoup(res.text, 'html.parser').select(selecter)
使用するライブラリ
-
request
WebAPIを使うことができるライブラリ。今回はGETメソッドを使い、レスポンスオブジェクトを取得しています。リクエストオブジェクトには様々な情報が含まれていますが、.textを使うことで文字列にすることが可能。2.のBeautifulSoupではレスポンスとして帰ってきたテキスト化したHTMLを使います。 -
BeautifulSoup
取得したHTMLのテキストを構文解釈し、その後各種メソッドで属性を取得したり、セレクタを使って複数の要素を取得したり。今回は、テキスト化されたレスポンスをHTMLとして解釈し、その後、.selectメソッドを使い、特定のセレクターを指定しています。これにより、該当したセレクターの要素が複数手に入ります。
上記の★使ってみるで実際に取得したデータは次の白枠部分です
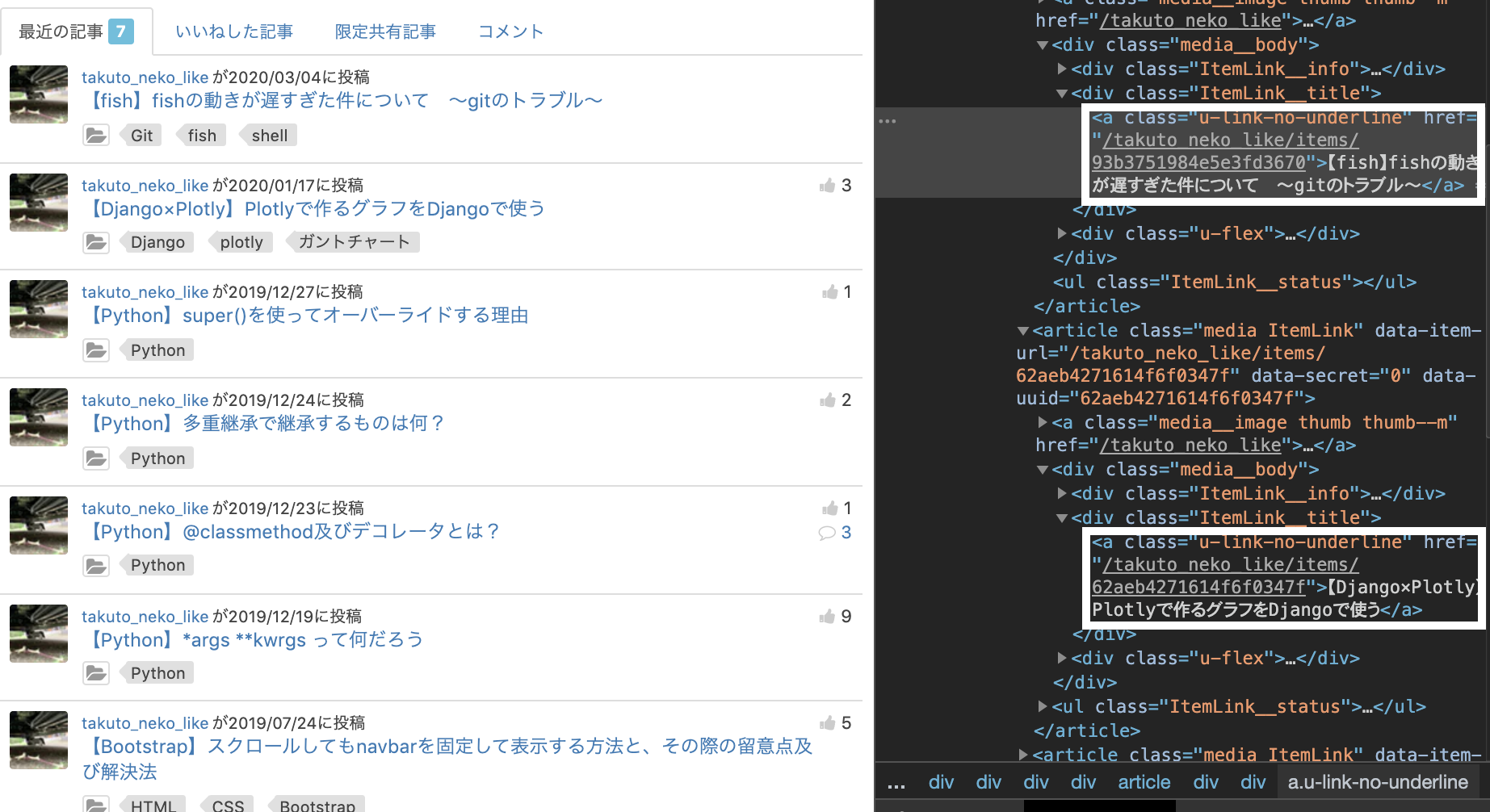
2. 取得した<a>タグの中からURLを抽出する。又、別でURLとタイトルのセットも抽出。
now_posts_url = [] #1 取得した記事一覧のURLのリスト, 今までの投稿データと比較し、新着投稿を割り出すために使う
now_posts_url_title_set = [] # 取得した記事一覧のURLとタイトルのリスト、
for post in posts:
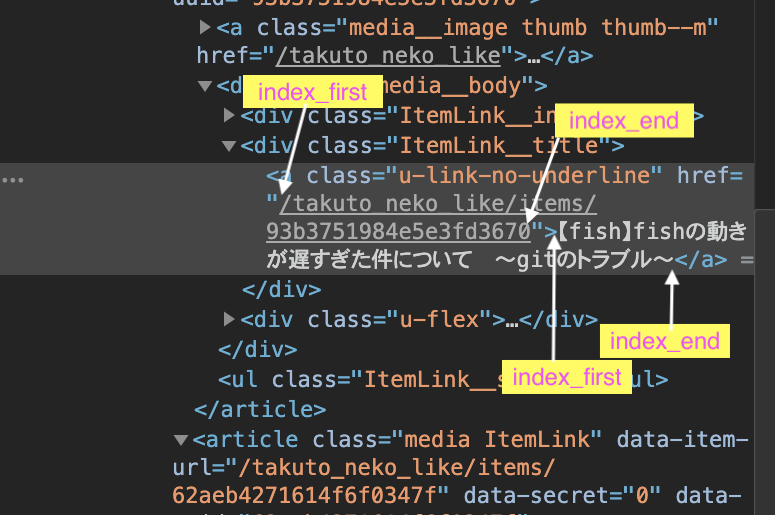
# URLを抽出
index_first = int(str(post).find('href=')) + 6
index_end = int(str(post).find('">'))
url = (str(post)[index_first : index_end])
# タイトルを抽出
index_first = int(str(post).find('">')) + 2
index_end = int(str(post).find('</a'))
title = (str(post)[index_first : index_end].replace('\u3000', ' ')) # 空白置換
now_posts_url.append(url)
now_posts_url_title_set.append(f"{url}>>>{title}")
取得した<a>タグの要素たちをfor文で回します。.find()で文字列を指定することで、その文字列の開始位置のインデックスがわかるため、その値で文字列をスライスすることで、URL部分とタイトル部分を手に入れます。
now_posts_urlは今までの投稿データと比較し、差分(ページネーション等で一覧画面から消えた記事を省く)を取り出すために使うデータです。
今回は、記事の更新があっても変わることがないであろうURLを使って新着を感知しますが、後々タイトルとURLを出力するために、今のうちにURL+タイトルのセットを取っておきたい。そのため、now_posts_urlを使って差分を得ておき、後ほどnow_posts_url_title_setから差分のURLが含まれるデータだけを抽出します。
3.既存の投稿一覧(txt)を使い、2.で得たURLと比較。差分を抽出する。
old_post_text = open(txt)
old_post = old_post_text.read().split(',') # テキストファイルからリスト型へ
# differences : 投稿済だが一覧画面に表示されていない投稿 + 新しい投稿
differences = list(set(now_posts_url) - set(old_post))
old_post_text.close()
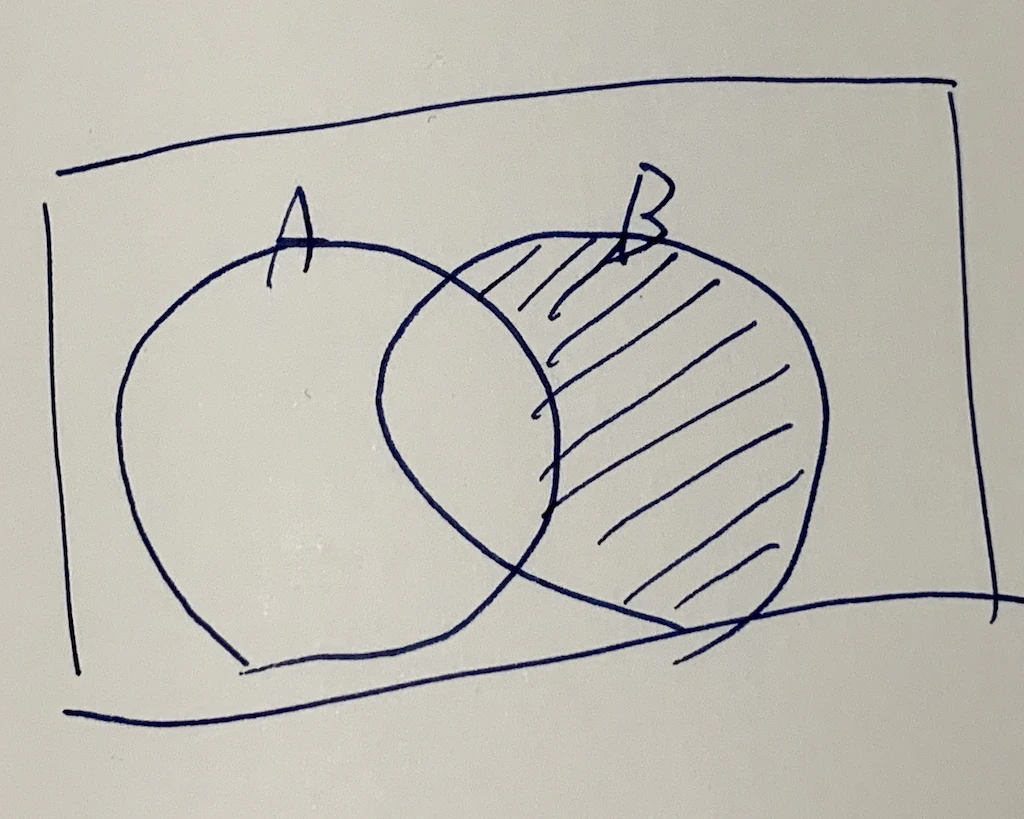
今までの投稿記録が保存してあるtxtファイルと比較し、新しく取得した最新の投稿一覧から、差分を抽出したいです。
以下でいうと
Aが過去の投稿一覧
Bが最新の投稿一覧
そして、斜線を引いている部分が差分で、全く新しい投稿。
計算対象をset型のオブジェクトにすることで集合演算が行なえるため、
今回は、txtファイルに記録してあるリスト型の文字列([ URL1, URL2, URL3 ])をsplit()でlist型に。
2.で取得した最新の投稿一覧と一緒にset型に変換しつつ、差を求めています。
4.新しい投稿のURLと、既存の投稿記録を1つにして、txtを上書きする
# 記録用txtを上書き all_postsは過去の投稿 + 新しい投稿
all_posts = ",".join(old_post + differences)
f = open(txt, mode='w')
f.writelines(all_posts)
f.close()
txtファイルも最新情報を追加して、次回に使えるようにしておかなければいけません。
今までの投稿に差分(新しい投稿)をプラスしてtxtファイルを上書きします。
5.2.で取得しておいたURLとタイトルのセットから、差分に該当したモノだけを抽出。整形しやすいように2重リスト型にする
new_post_info = []
for new in now_posts_url_title_set:
for incremental in differences:
if incremental in new:
new_post_info.append(new.split(">>>"))
return new_post_info
あらかじめ2.で取得しておいた"URL>>>タイトル"という文字列のデータから、差分と一致するURL(の文字列)を含むものだけを、得ます。

文字列なのでin演算子で、文字列内に同じ文字が含まれていればOK。
これにより、新着の記事のURLとタイトルをGETできました。
LINEで通知したい
Line notifyを使いました。
def send_line_notify(posts, token):
'''
# new_post_getterの返り値を引数に
'''
notice_url = "https://notify-api.line.me/api/notify"
headers = {"Authorization" : "Bearer "+ token}
for url, title in posts:
if 'http' not in url:
url = 'https://qiita.com/' + url
message = f'{title}:{url}'
payload = {'message': message}
r = requests.post(notice_url, headers=headers, params=payload,)
token = '########'
neko_post = new_post_getter(neko_url, neko_selecter, neko_txt)
send_line_notify(neko_post, token)
new_post_getter関数の返り値とトークンを引数に指定すれば、LINE Notifyに送信してくれます。
こちらを参考にさせていただきました
定期的に実行したい
pythonanywhereに各ファイルをコピーし、以下のとおり.shを作成
source /home/<アカウント>/blog_post_notice/venv/bin/activate
python3 /home/<アカウント>/blog_post_notice/send.py ##
続いて、cronの設定の前に.shを実行してみると...
requests.exceptions.ProxyError: HTTPSConnectionPool(host='qiita.com', port=443): Max retries exceeded with url: /takuto_neko_like (Caused by ProxyError('Canno
t connect to proxy.', OSError('Tunnel connection failed: 403 Forbidden')))
調べてみると、Pythonanywhereでは無料アカウントの場合、不正なアクセスを防ぐ目的で、ホワイトリストに該当する外部サイトにのみアクセスできるようです。
ということで、pythonanywhereは諦めて...
Herokuにデプロイしてみました。
が、Herokuではファイルの保存などができないため、自分のPC上でcronを設定し、定期的に実行してみます。
crontab -eとして...
0 * * * * sh /Users/ユーザ名/dir1/post_notice/notice.sh