『
サイズ5x5の入力画像を、サイズ3x3のフィルタで
畳み込んだ時の出力画像のサイズを答えよ。
なおストライドは2、パディングは1とする。
(3分)
』
→
回答例:
3x3
【考察】
$OutputHeight= \dfrac{height+2padding-FilterHeight}{stride}+1= \dfrac{5+21-3}{2} +1 = 3$
$OutputWidth= \dfrac{width+2padding-FilterWidth}{stride}+1= \dfrac{5+21-3}{2} +1 = 3$
Section1:再帰型ニューラルネットワークの概念
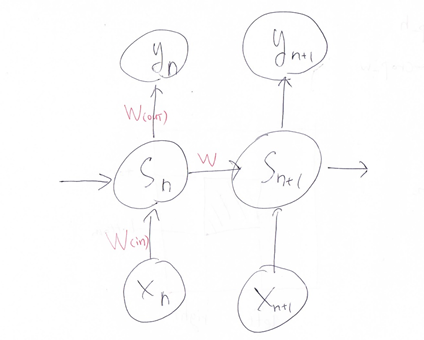
『
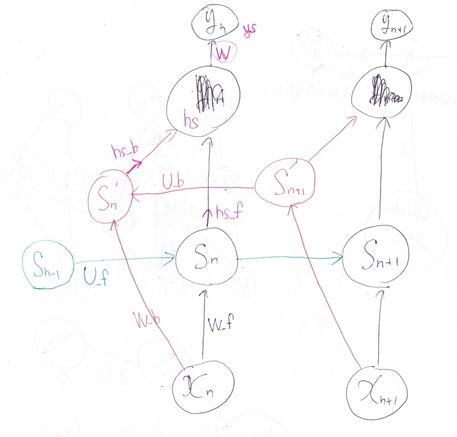
RNNのネットワークには大きくわけて3つの重みが
ある。1つは入力から現在の中間層を定義する際に
かけられる重み、1つは中間層から出力を定義する際に
かけられる重みである。
残り1つの重みについて説明せよ。
(3分)
』
→
回答例:
現在の中間層からの出力値から、次の中間層を定義する際にかけられる重み。
【考察】
下図のWの個所になる。このWがRNNならでは重みになる。
『
連鎖律の原理を使い、dz/dxを求めよ。
(5分)
z=t^2
t=x+y
』
→
回答例:
2(x+y)
【考察】
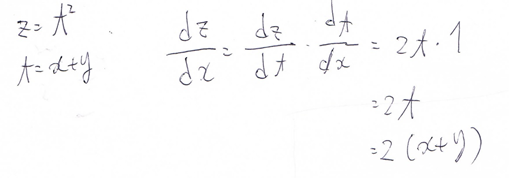
『
下図のy1を、x・s0・s1・win・w・woutを用いて数式で表せ。
※バイアスは任意の文字で定義せよ。
※また中間層の出力にシグモイド関数g(x)を作用させよ。
(7分)
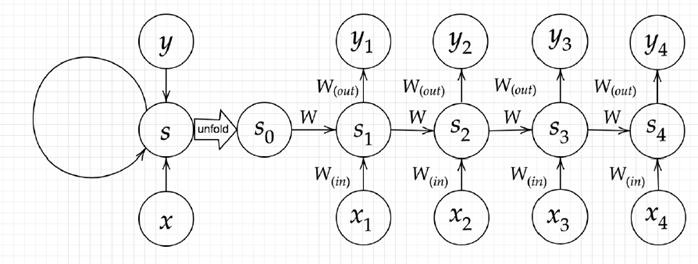
』
→
回答例:
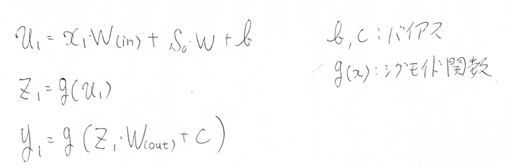
【考察】
通常のNNとの違いは、入力と重みの総和を取る際に、1つ前の層からの出力を、入力として受け取って、それに新たな重みを掛けて総和を取るところ。
『
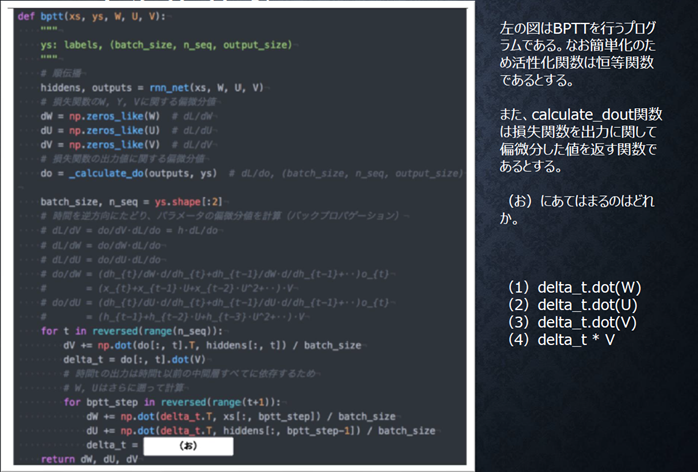
』
→
回答例:
(2)
【考察】

Section2:LSTM
『
シグモイド関数を微分した時、入力値が0の時に最大値
をとる。その値として正しいものを選択肢から選べ。
(1分)
(1) 0.15
(2) 0.25
(3) 0.35
(4) 0.45
』
→
回答例:
(2)
【考察】
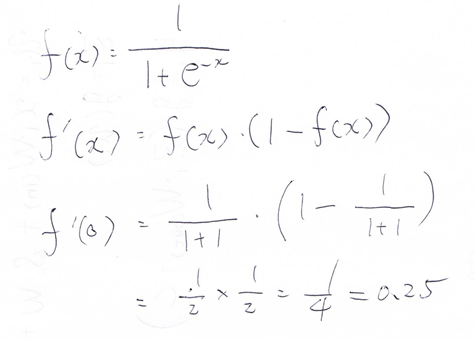
『
RNNや深いモデルでは勾配の消失または爆発が起こる傾向がある。勾配爆発を防ぐために勾配のクリッピングを行うという手法がある。具体的には勾配のノルムがしきい値を超えたら、勾配のノルムをしきい値に正規化するというものである。以下は勾配のクリッピングを行う関数である。
(さ)にあてはまるのはどれか。
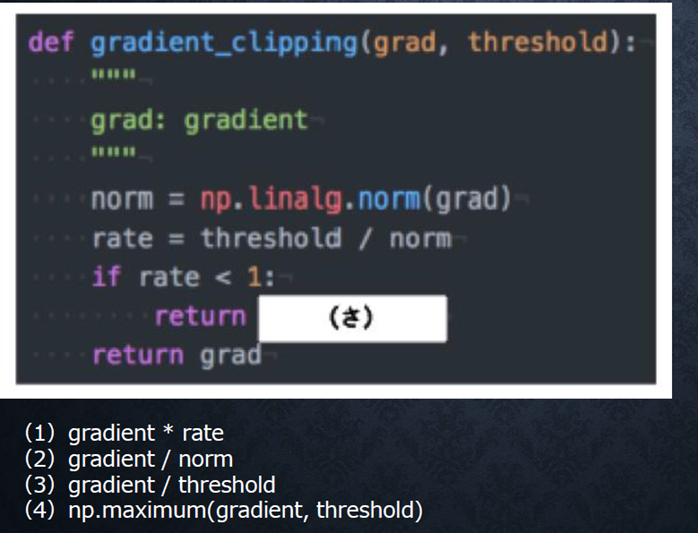
』
→
回答例:
(1)
【考察】
thresholdがしきい値。つまり、rate = threshold / norm が1以上の場合は、しきい値を超えていない事になるので、そのままreturn する。
rateが1未満の場合は、勾配gradient にrateを掛ける事で、gradientのサイズをしきい値にしてreturnしている。
『
以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。
文中の「とても」という言葉は、空欄の予測において
なくなっても影響を及ぼさないと考えらる。
このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か___。」
(3分)
』
→
回答例:
忘却ゲート
【考察】
入力ゲート、出力ゲートは、重みを一律にしないための処理なので、情報の必要/不要を判断する訳ではない。
過去の情報が不要になった場合は、忘却ゲートで忘れさせる必要がある。
『
以下のプログラムはLSTMの順伝播を行うプログラムである。ただし_sigmoid関数は要素ごとにシグモイド関数を作用させる関数である。
(け)にあてはまるのはどれか。
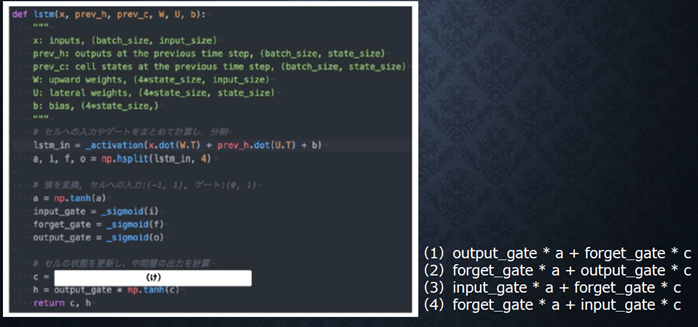
』
→
回答例:
(3)
【考察】
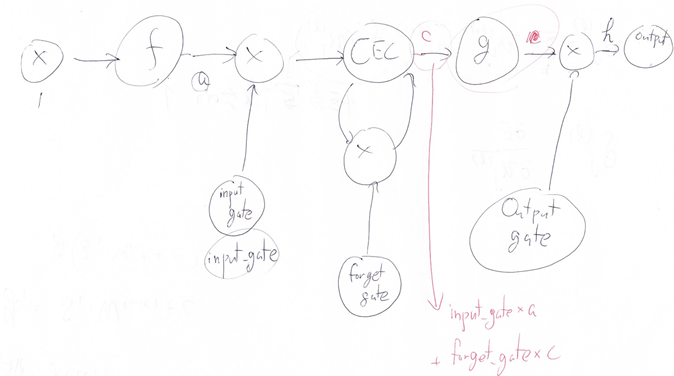
Section3:GRU
『
LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
(3分)
』
→
回答例:
・LSTM:パラメータ数が多く、計算負荷が掛かる。
・CEC:入力データについて、時間の依存度に関係なく、重みが一律なので、そもそも学習が行われない。
【考察】
LSTMに対してはGRU、CECに対しては、忘却ゲートや覗き穴結合などの解決策がある。
『
GRU(Gated Recurrent Unit)もLSTMと同様にRNNの一種であり、単純なRNNにおいて問題となる勾配消失問題を解決し、長期的な依存関係を学習することができる。LSTMに比べ変数の数やゲート数が少なく、より単純なモデルであるが、タスクによってはLSTMより良い性能を発揮する。以下のプログラムはGRUの順伝播を行うプログラムである。ただし_sigmoid関数は要素ごとにシグモイド関数を作用させる関数である。
(こ)にあてはまるのはどれか。
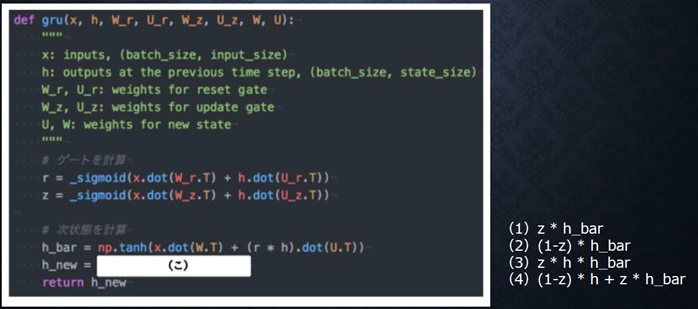
』
→
回答例:
(4)
【考察】
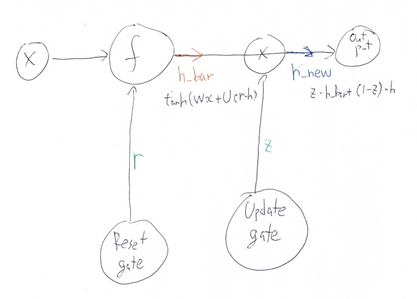
『
LSTMとGRUの違いを簡潔に述べよ。
(5分)
』
→
回答例:
どちらもRNNだが、LSTMとGRUはその構造が異なる。
GRUは、LSTMに比べてパラメータ数、ゲート数が少なく、計算負荷が少ない。
【考察】
精度については、アカデミックな論文では、GRUはLSTMと同等かそれ以上の精度がある。というものもあるが、実務において、タスクによっては、LSTMの方が精度が出る場合もある。
Section4:双方向RNN
『
以下は双方向RNNの順伝播を行うプログラムである。順方向については、入力から中間層への重みW_f、一ステップ前の中間層出力から中間層への重みをU_f、逆方向に関しては、同様にパラメータW_b、U_bを持ち、両者の中間層表現を合わせた特徴から出力層への重みはVである。_rnn関数はRNNの順伝播を表し中間層の系列を返す関数であるとする。(か)にあてはまるのはどれか。
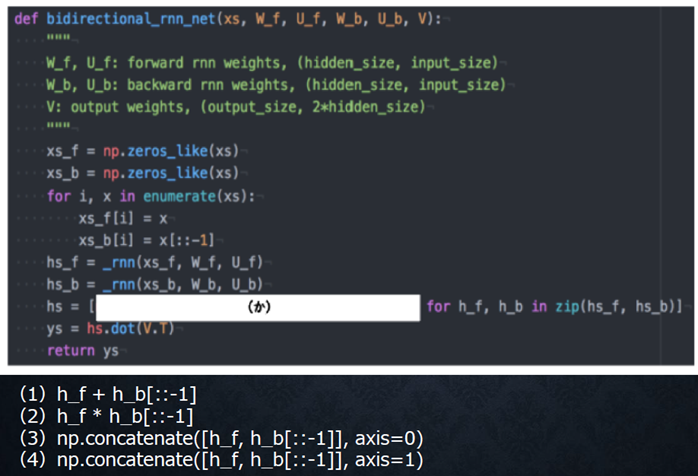
』
→
回答例:
(4)
【考察】
Section5:Seq2Seq
『
下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECゲートの概念を導入することで解決したものである。
』
→
回答例:
(2)
【考察】
(1)双方向RNN
(3)Socher RNN
(4)LSTM。
『
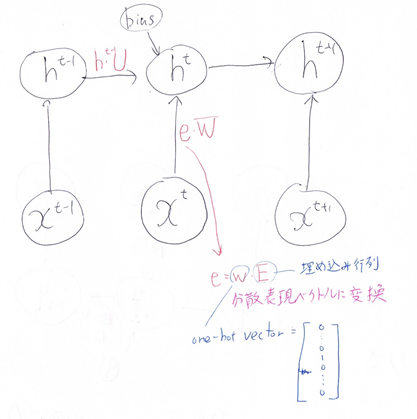
機械翻訳タスクにおいて、入力は複数の単語から成る文(文章)であり、それぞれの単語はone hot ベクトルで表現されている。 Encoder において、それらの単語は単語埋め込みにより特徴量に変換され、そこから RNN によって(一般には LSTM を使うことが多い)時系列の情報をもつ特徴へとエンコードされる。以下は、入力である文(文章)を時系列の情報をもつ特徴量へとエンコードする関数である。ただし _activation 関数はなんらかの活性化関数を表すとする。
(き)にあてはまるのはどれか。
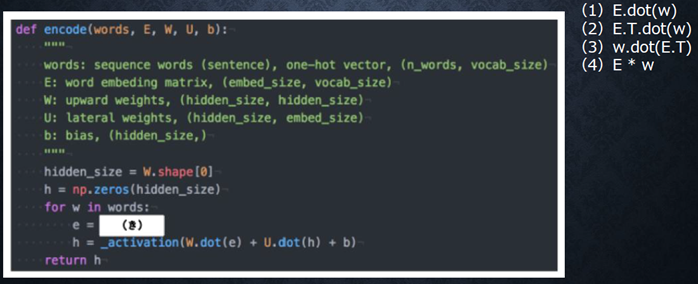
』
→
回答例:
(1)
【考察】
『
seq2SeqとHRED、HREDとVHREDの違いを簡潔に述べよ。
(5分)
』
→
回答例:
seq2SeqとHRED:seq2seqは一問一答のような事しか対応出来ないが、HREDは過去の文脈を加味した応答を行う。
HREDとVHRED:HREDは毎回同じ文脈に対して、毎回同じ反応をするが、VHREDは異なる反応をする。
【考察】
seq2seqの課題を解決したものがHRED。
HREDの課題を解決したものがVHRED。
『
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
自己符号化器の潜在変数に___を導入したもの。
(1分)
』
→
回答例:
確率分布
【考察】
確率分布を導入した事で、VHREDでは、毎回同じ文脈が与えられても、違った反応をする事が出来るようになっている。
Section7:Attention Mechanism
『
RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
(5分)
』
→
回答例:
RNNとword2vec:
RNNは、(ボキャブラリ)x(ボキャブラリ)の重みが生成されるため、膨大な計算量と計算時間が掛かる。
word2vecは、重みの生成ロジックが、現実的な計算速度と計算消費量で出来る。
seq2seqとAttention:
seq2seq:固定次元ベクトルのものしか学習出来ない。
seq2se2 + Attention:重要度と言う概念を用いて、長い文章を入れた時でも、翻訳が成り立つ。
【考察】
RNNでは、単語のような可変長の文字列をNNに与える事は出来ないが、word2vecでは可変長で与える事が出来る。
seq2seqは長い文章に対応出来ないが、Attentionは長い文章でも対応が出来る。
基本となるRNNのモデルが最初に考えられ、出てきた課題に対して、word2vecやseq2seqなどの解決モデルが誕生し、そのseq2seqの課題に対して更に、Attention Mechanismが考えられたりしていて、課題に対して次々に新しいモデルや解決策が生み出されている。
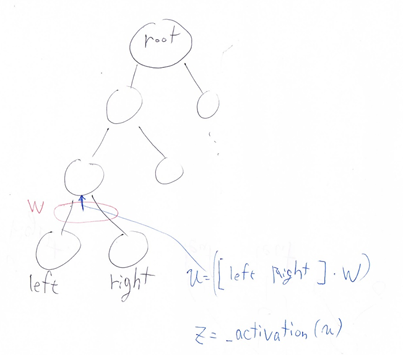
『
以下は再帰型ニューラルネットワークにおいて構文木を入力として再帰的に文全体の表現ベクトルを得るプログラムである。
ただしニューラルネットワークの重みパラメータはグローバル変数として定義してあるものとし、_activation関数はなんらかの活性化関数であるとする。木構造は再帰的な辞書で定義してあり、rootが最も外側の辞書であると仮定する。
(く)にあてはまるのはどれか。
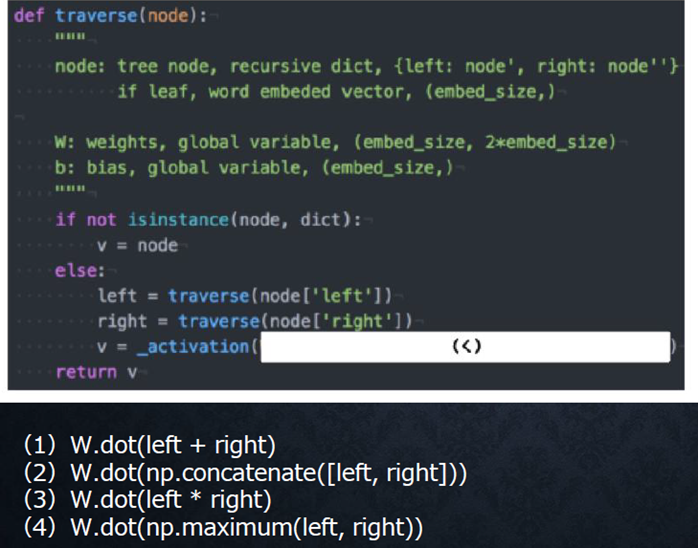
』
→
回答例:
(2)
【考察】