第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
MeCabはオープンソースの日本語形態素解析エンジンです。
この章を進めていくためには、まず、MeCabの動作環境を設定する必要があります。
ここでは、Google Colaboratoryでの環境構築方法を紹介します。
(参考:ColaboratoryでMeCabを使えようにする)
Google ColaboratoryのOSタイプとバージョンを確認します。
Linuxカーネルバージョンの表示
!cat /proc/version
<出力>
Linux version 4.19.112+ (builder@a12462ca91c8) (Chromium OS 10.0_pre377782_p20200113-r10 clang version 10.0.0 (/var/cache/chromeos-cache/distfiles/host/egit-src/llvm-project 4e8231b5cf0f5f62c7a51a857e29f5be5cb55734)) #1 SMP Thu Jul 23 08:00:38 PDT 2020
インストールOSの確認
!cat /etc/os-release
<出力>
NAME="Ubuntu"
VERSION="18.04.3 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.3 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
OSはUbuntuであるので、普通にUbuntu上で環境構築するのと同じである。
aptitudeのインストール
!apt install aptitude
MeCabと関連ライブラリのインストール
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
PythonからMeCabを使用するためのライブラリをインストール
!pip install mecab-python3==0.7
neko.txtをダウンロードし、MeCabで形態素解析した結果をneko.txt.mecabに保存。
import requests
# neko.txtをダウンロード
url = "https://nlp100.github.io/data/neko.txt"
response = requests.get(url)
#print(response.text[:200])
import MeCab
# MeCabはTaggerインスタンスを作成して解析に使用します。
# "mecabrc:"は、MeCabの標準出力指定です。
target = MeCab.Tagger("mecabrc:")
sentence = response.text.split('。') # 読点で分ごとに分割。
data=[]
for i,line in enumerate(sentence):
#print("line=%d" % i)
data+=target.parse(line) # 行ごとの解析結果をリストに追加
with open("neko.txt.mecab",'w') as f:
f.writelines(data) # MeCab解析結果を保存
!cat "neko.txt.mecab" | wc -l # 出力したファイルの行数表示
!cat "neko.txt.mecab" | head -n 10
<出力>
216328
一 名詞,数,*,*,*,*,一,イチ,イチ
記号,一般,*,*,*,*,*
記号,一般,*,*,*,*,*
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
with open("neko.txt.mecab",'r') as f:
lines = f.readlines()
dicList=[]
for line in lines:
if line[:3]=="EOS":
continue
wgrp = line.split('\t')
if len(wgrp)<2:
continue
w = wgrp[1].split(",")
dict = {"surface":wgrp[0], "base":w[6], "pos":w[0], "pos1":w[1]}
dicList.append(dict)
[print(dicList[i]) for i in range(3)]
<出力>
{'surface': '一', 'base': '一', 'pos': '名詞', 'pos1': '数'}
{'surface': '', 'base': '*\n', 'pos': '記号', 'pos1': '一般'}
{'surface': '', 'base': '*\n', 'pos': '記号', 'pos1': '一般'}
[None, None, None]
31. 動詞
動詞の表層形をすべて抽出せよ.
# 30のつづき
for w in dicList:
if w["pos"]=="動詞":
print(w["surface"])
<出力>
・・・(省略)・・・
死ぬ
死ん
得る
死な
得
られ
32. 動詞の原形
動詞の原形をすべて抽出せよ.
# 30のつづき
for w in dicList:
if w["pos"]=="動詞":
print(w["base"])
<出力>
・・・(省略)・・・
死ぬ
得る
死ぬ
得る
られる
3. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
s=""
f=0
for w in dicList:
if f==1:
if w["surface"]=="の": # 名詞の次に「の」が出現したとき
s+=w["surface"]
f=2
else:
f=0
s=""
elif f==2: # 名詞+「の」の次に名詞が出現したとき
if w["pos"]=="名詞":
s+=w["surface"]
print(s)
f=0
s=""
if w["pos"]=="名詞":
s = w["surface"]
f=1
<出力>
・・・(省略)・・・
年の間
自然の力
水の中
座敷の上
不可思議の太平
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
s=""
f=0
ma=0
for w in dicList:
if w["pos"]=="名詞":
s += w["surface"]
f+=1 # 名詞が連続した回数をカウント
else:
if f>ma: # 名詞の連接数の最大値と比較
print(s)
ma=f
f=0
s=""
<出力>
一
人間中
四五遍
我等猫族
壱円五十銭
一杯一杯一杯
三毛子さん三毛子さん
manyaslip'twixtthecupandthelip
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
map1={}
for w in dicList:
if w["base"] in map1:
map1[w["base"]]+=1 # 辞書に登録済みなら1カウントアップする。
else:
if w['pos']!="記号":
map1[w["base"]]=1 # 辞書に未登録ならカウント数1で登録
# 辞書の出現数で降順にソート
sortlist = sorted(map1.items(), key=lambda x:x[1], reverse=True)
print(sortlist)
[('*\n', 12148), ('の', 9194), ('て', 6841), ('は', 6423), ('に', 6265), ・・・
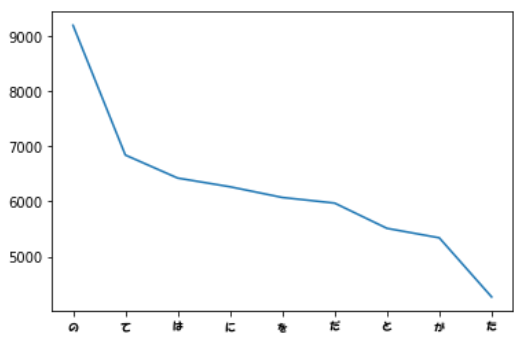
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
matplotlibを使用しますが、日本語フォントはフォントファイルを指定する必要があります。
ここでは、Google Colaboratory環境にフォントファイルをアップロードして使用していますが、
以下のサイトを参考にしてもよいかもしれません。
Googleコラボのグラフ(matplotlib)を日本語化する方法!
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
fp = FontProperties(fname='HGRPP1.TTC', size=8) # matplotlibのフォント指定
%matplotlib inline
li=sortlist[1:10]
x=[]
y=[]
for w in li:
x.append(w[0])
y.append(w[1])
plt.xticks(fontproperties=fp)
plt.plot(x,y)
plt.show()
<出力>
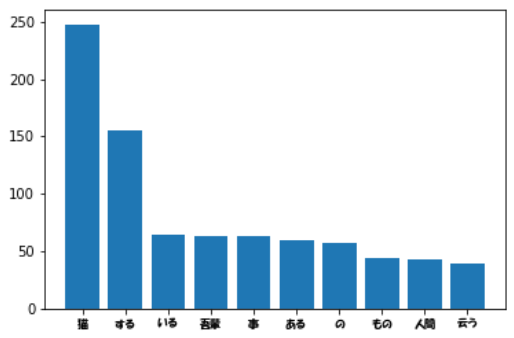
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
import MeCab
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
fp = FontProperties(fname='HGRPP1.TTC', size=8)
%matplotlib inline
nekolist=[]
# ”猫”が出現する文を抽出
for line in sentence:
if line.find("猫")>=0:
nekolist.append(line)
#print(str(len(nekolist)))
target = MeCab.Tagger("mecabrc:")
wordInfo={}
for line in nekolist:
data = target.parse(line)
wlist = data.split('\n')
if wlist[:3]=="EOS":
continue
for wtb in wlist:
wdl = wtb.split('\t')
if len(wdl)>=2:
w = wdl[1].split(',')
# 名詞と動詞で基本形のあるものを出力対象にする。
if w[0]=="名詞" or w[0]=="動詞":
if w[6]=="*":
#print(w)
continue
if w[6] in wordInfo:
wordInfo[w[6]] += 1 # 単語が登録済みならカウントアップ
else:
wordInfo[w[6]] = 1 # 単語が未登録ならカウント1で登録
#print(str(len(wordInfo)))
wordInfo = sorted(wordInfo.items(), key=lambda x:x[1], reverse=True)
#print(wordInfo[0:10])
x=[x[0] for x in wordInfo[0:10]]
y=[x[1] for x in wordInfo[0:10]]
plt.xticks(fontproperties=fp)
plt.bar(x,y)
plt.show()
<出力>
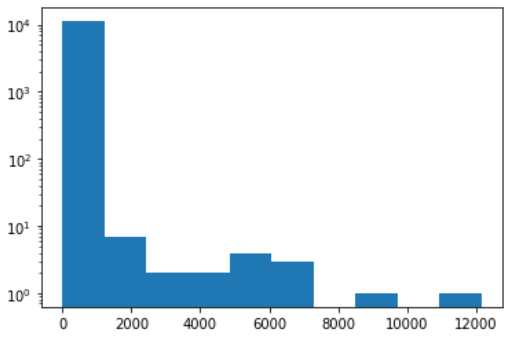
38. ヒストグラム
単語の出現頻度のヒストグラムを描け.ただし,横軸は出現頻度を表し,1から単語の出現頻度の最大値までの線形目盛とする.縦軸はx軸で示される出現頻度となった単語の異なり数(種類数)である.
# 35のつづき
import MeCab
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
X=[x[1] for x in sortlist]
_max = max(X)
#print(str(_max))
#print(X[0:10])
plt.hist(X , log=True)
<出力>
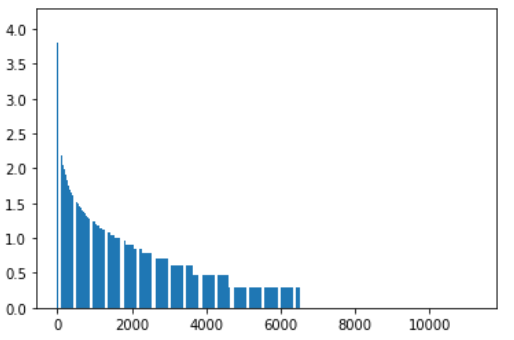
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
Y=[np.log10(x[1]) for x in sortlist] # 出現回数の対数をとる
X = np.arange(1,len(sortlist)+1)
plt.bar(X,Y)
<出力>