概要
スタイル変換(Style Transfer)といえば、PyTorchにもTensorflowにも公式のチュートリアルが存在する12ような、DeepLearningの歴史的には割と古くからある問題です。
ここ最近はどうなっているのかなと思って調べていたところ、ちょうどソースコードが公開間近らしいという手法が見つかったので、ちょっと論文を読んでみました。
本論文は、ICCV2019に通っている論文です。提案している主要な新規性は、画像のコンテンツとスタイルの情報を上手く分離できるような損失関数と、それを含めたスタイル変換手法の評価方法にあるようです。
以下に生成結果の一例を示しますが、その他の生成結果の例はプロジェクトページにたくさん載っています。提案した損失関数によってスタイルエンコーディングの空間が滑らかになり、自然なInterpolationもできるよ、ということが動画で示されています。

手法の全体像は以下のようになっています。
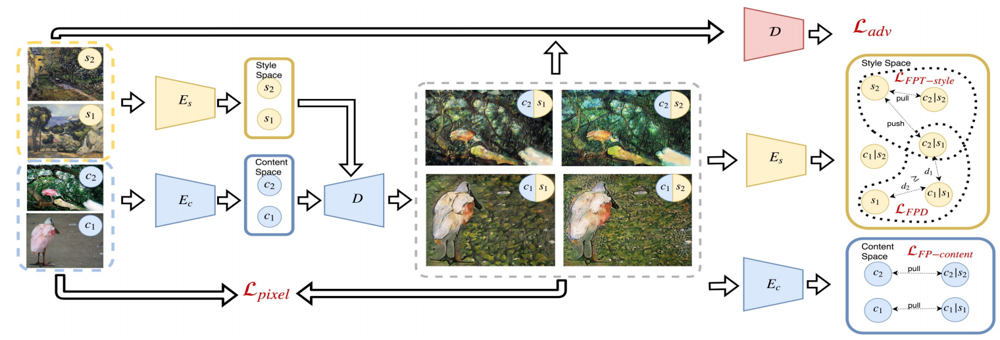
詳細は記事内で説明しますが、損失関数は5つあり、そのうち新規に提案されているのは、$\mathcal{L}_{FPT-style}, \mathcal{L}_{FPD}$の2つです。
記事内では、上記の5つの損失関数と、新たに提案されている評価手法について説明しています。
なお、ネットワーク構造については本記事では説明しません。論文中でも全く記述が無いので、予備的に公開されている公式実装を各自確認してください。
書誌情報
- Kotovenko, Dmytro, et al. "Content and style disentanglement for artistic style transfer." Proceedings of the IEEE International Conference on Computer Vision. 2019.
- プロジェクトページ
損失関数
概要でも述べたように、本手法では5つの損失関数を使用しています。それぞれについて、簡単に説明します。
記述を簡略化するために、以下のような用語を使っていきます。
- コンテンツ画像$x$:ImageNetなどの写真画像。何かしらの物体が写っている。
- スタイル画像$y$:特定の画家によって書かれた絵画の画像。
- スタイル$s$:特定の画家。
- 合成画像$D(E_c(x), E_s(y))$:コンテンツ画像をスタイル変換した画像。
- コンテンツ情報$E_c(x)$:コンテンツ画像から、コンテンツエンコーダー$E_c$によってエンコードされる特徴量
- スタイル情報$E_s(y)$:スタイル画像から、コンテンツエンコーダー$E_s$によってエンコードされる特徴量
Conditional Adversarial Loss
生成した画像が本物らしいかをDiscriminatorによって見極める損失です。このとき、スタイルの条件付きであることに注意しましょう。
$\mathcal{D}$と$D$が出てきてややこしいですが、一方はDiscriminatorで、もう一方はDecoderです。
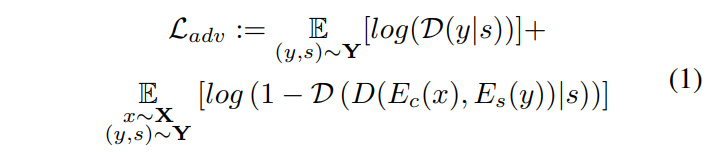
Reconstruction Loss
合成画像はコンテンツ画像と画素値が大幅に離れすぎてはいけないので、それらのL2距離を損失とします。
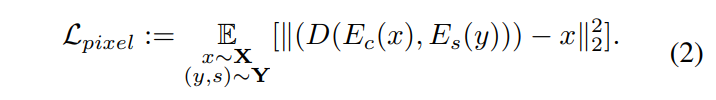
Fixpoint Content Loss
合成画像とコンテンツ画像には同じコンテンツ(物体や背景)が含まれているべきなので、それらのコンテンツ情報は近い必要があります。そのため合成画像とコンテンツ画像それぞれからエンコードされるコンテンツ情報のL2距離を損失とします。
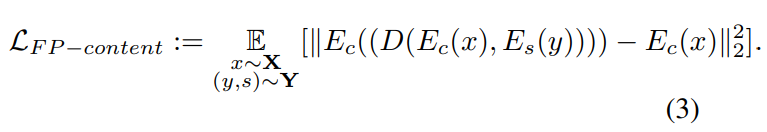
Fixpoint Triplet Loss
ここからが論文の提案している損失関数です。
Fixpoint Content Lossと同様の損失を、スタイル情報に関してもこのような損失を考えます。すなわち、合成画像からエンコードされるスタイル情報とは、合成に使用したスタイルのスタイル情報$E_s(s)$と似ていてほしいというわけです。これを素直に適用すると、以下のような損失になります。
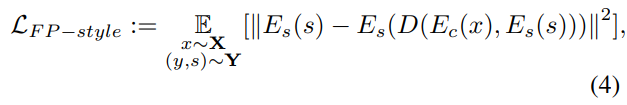
しかし、この損失関数には問題があります。この損失は、同じスタイルでありながら見た目が大幅に異なるスタイル画像$y_1, y_2$があったときに、それぞれを用いた合成画像が同一になるように促す、ということを意味しています。同一の画家であっても、題材や時代によって画風が微妙に変化することを考慮すると、こては少々強すぎる制約です。
同一のスタイルであっても、絵画によってちょっと異なるスタイル情報を持っているはずだ、という直観を反映させるために、「他のスタイルと区別できる程度にスタイル情報が近ければ良い」という緩い制約を導入します。
これによって、以下のようなTriplet損失が提案されています。
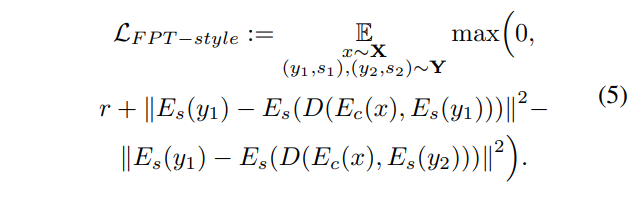
まず、スタイル全体で共有されている$E_s(s)$のようなスタイル情報ではなく、あくまでも合成に使用したスタイル画像$y_1$から得られるスタイル情報$E_s(y_1)$が使用されています。また、合成画像のスタイル情報$E_s(D(E_c(x), E_s(y_1)))$が、別のスタイル$s_2$のスタイル画像$y_2$で合成したときのスタイル情報$E_s(D(E_c(x), E_s(y_2)))$に比べて十分$E_s(y_1)$に近ければ良い、という損失になっています。
Disentanglement Loss
論文のタイトルにもなっているDisentanglmentが関係する損失になっています。
デコーダーが使用するコンテンツ情報とスタイル情報がそれぞれ直交する役割を担いましょう、ということを実現するための損失と考えれば良いでしょう。
具体的には、合成画像に使用するコンテンツ画像が変わったとしても、スタイル画像が一定なら、合成画像から得られるスタイル情報は一定である、ということを満たす以下のような損失が考えられます。コンテンツ画像$x_1, x_2$によらず、合成画像から得られるスタイル情報は同一である、という損失です。
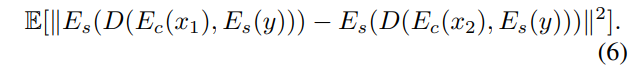
しかし、この損失はやや強すぎる制約で、訓練がうまく進まないそうです。そこで、少しこの制約を緩めて、以下のような損失を提案しています。
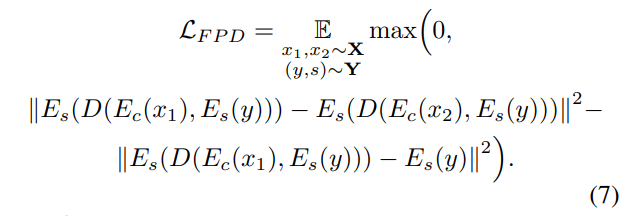
これは、合成画像を作る上でどうしても生じるスタイル情報の変化(上式3行目)は許容したうえで、合成画像同士のスタイル情報の差異をできるだけ小さくしようという制約です。
以下、補足です。
一見すると、このDisentanglement損失には、スタイルとコンテンツの役割を変えたバージョンも有り得そうです。つまり、一定のコンテンツ画像に対して異なるスタイル画像を適用したときでも、同一のコンテンツ情報が得られる、という制約を表す損失関数です。しかし、このような損失関数は、Fixpoint Content Lossとやっていることがほぼ同じになってしまうため、必要ないんだろうな、と思います。
実験
本論文では、実験が論文の半分を占めており、スタイル変換というタスクにおける評価の難しさを克服しようという意志が感じられます。
Stylization Assessment
まずは、合成画像がどれだけ「ぽい」結果になっているのかを評価しています。
以下の表のような結果が得られますが、各列で行っている評価の枠組みが結構異なるので、それぞれについて何をやっているのかを説明していきます。
なお、スタイル画像は10のスタイルに限定し、各スタイルでの結果を出した後に平均しています。また、コンテンツ画像としては、Place365 dataset内の画像を使用しています。
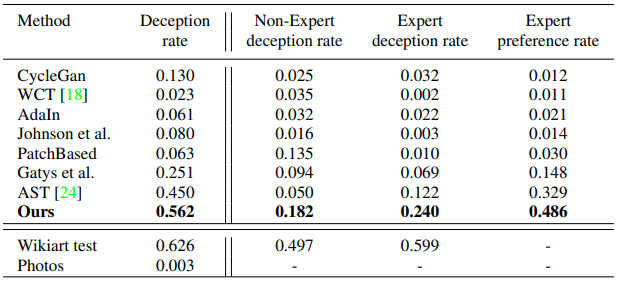
Decception rate
Decception rateは、事前に訓練されたスタイル分類器をどれだけ騙せるか、という確率を示しています。
分類器は、VGG16を用いてWikiartデータセットで訓練されています(先行手法であるAST3では、624ものスタイル=画家を分類する分類器を事前に訓練しているが、本手法ではおそらく330クラス程度の分類器を訓練しています)。
ここで、下段のWikiart testは、訓練に使用していないWikiartの絵画を0.626の精度で分類できているということを表しています。また、最下段のPhotosは、チャンスレートを表しています(論文には明記されていませんが、つまり、この分類器はおおむね330程度のクラスの分類器と考えられます。なぜ先行手法の624クラス分類器を使用していないのかは謎です)。
本手法で生成した合成画像は、このスタイル分類器によって0.562の割合で目的とするスタイルに分類されています。
Non-Expert/Expert deception rate
いくつかの手法で生成した合成画像のパッチの中に、実際の絵画から切り抜いたパッチを混ぜて、どれが本物かを被験者に選んでもらい、どれだけ騙せたかで評価するという枠組みです。表記がかぶっているのでややこしいですが、上記のDeception rateとは全く異なる枠組みです。
この実験は人間に対して行う評価で、美術史の非専門家と専門家に対して行っています。
非専門家は約半分、専門家は6割、本物の絵画のパッチを選んでいるので、まだまだ人の目はごまかせていない、という結果になっています。一方で、既存手法と比べると本手法はそれぞれ0.182, 0.240となっており、実際の絵画のパッチに次いで選択されているという結果となっています。特に専門家のほうが他の手法と比較して明確に多く本手法の合成結果を選んでいるというのは注目に値するところでしょう。
以下、補足です。
下の画像は、ここで行っている評価の枠組みがどのようなものなのかの雰囲気を表しています。ここには、本手法によって生成された合成画像と実際の絵画のパッチが混在しています。各行は、それぞれ、セザンヌ、ゴーギャン、モリゾ、ゴッホ、モネに対応しているそうですが、各パッチが生成されたものなのか、本物なのかを当てられるでしょうか? 解答は論文の8ページ目に記載されています。

Expert preference rate
いくつかの手法で生成した合成画像のパッチを見せて、どれが一番適切にスタイルを反映している、好ましい結果となっているのかを、美術史の専門家に選んでもらい評価するという枠組みです。こちらには、実際の絵画のパッチを混ぜるという意地悪はしません。
本手法は0.486と、専門家から見てもっとも好ましい結果が得られているよ、という結果となっています。
Disentanglement of Style and Content
次に、スタイル情報とコンテンツ情報がうまく役割分担できているのか、を評価しています。
そのために、上で説明したDisentanglement Lossが有効に機能しているのかを評価しています。
以下の2つの事前学習済みの分類器を用意します。
- コンテンツ分類器$\tilde{E}_c$:VGG16によるImageNet分類器
- スタイル分類器$\tilde{E}_s$:VGG16によるWikiart分類器
また、各分類機の全結合層のレスポンスをそれぞれ、コンテンツ特徴 $\tilde{E}_{c}^{fc}$ 、スタイル特徴$\tilde{E}_s^{fc}$とします。
スタイル特徴とコンテンツ特徴、それぞれについて確認していきます。
なお、以降の実験では、コンテンツ画像としてImageNetの画像を使用しています。
Style Discrepancy
まず、スタイル特徴の側から確認しましょう。
どんなコンテンツ画像を合成に使おうが、スタイル特徴には影響を与えない、ということを確認していきます。
本実験は、ある1つのスタイルを選んで行っており、下図のような結果が得られています。それぞれの分布について説明します。
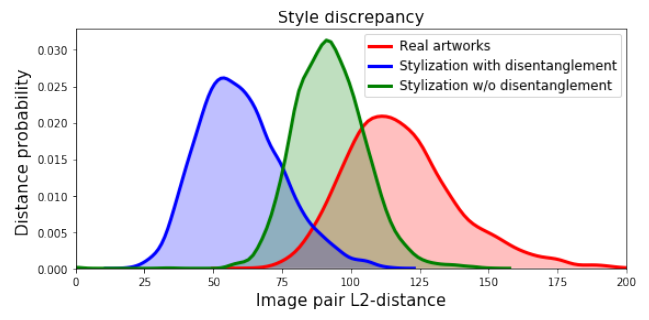
Real artworks
スタイル内でランダムにサンプルした異なる絵画について、スタイル特徴間の距離を算出し、その分布を求めたのが、上図の赤い分布に対応しています。つまり、同じ画家でも異なる絵画、つまりコンテンツが違えばこれくらいのスタイル情報の違いはあるよ、ということを表す分布で、これよりも大きい位置に分布していると話にならない、というベースラインを表しています。
スタイル特徴間の距離は、下式のように求められます。
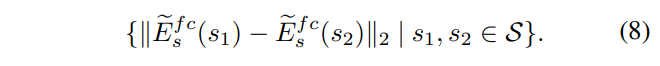
Stylization with disentanglement, Stylization w/o disentanglement
Disentanglment Lossの有無によって以下の距離がどのような分布になるのかをそれぞれ青と緑で表しています。この距離は、コンテンツが$x_1, x_2$であるときにどのくらいスタイル特徴が離れてしまうのか、を表しています。
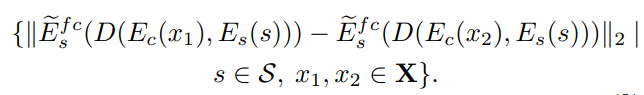
この距離は、小さいほど良い指標です。
以上を踏まえて、先に示した3つの分布を比較すると、本手法で提案したDisentangle Lossがある方が0に近づいた分布になっていることがわかります。
Content Discrepancy
続けて、コンテンツ特徴の側から確認しましょう。
こちらでは、コンテンツ画像が同一であれば、合成時に与えられたスタイルが異なる場合でも、合成画像のコンテンツ特徴はできるだけ似ていることが求められます。
先に分布を示し、各分布が何を表しているのかを説明します。
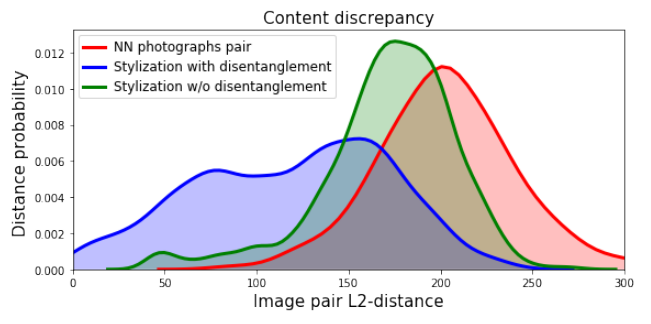
NN photographs pair
上図の赤い分布は、ランダムに選択されたコンテンツ画像である写真をもとに算出される指標の分布となっています。同じクラスとはいえコンテンツが異なる画像同士の特徴ですので、これよりも大きい位置に分布していると話にならない、というベースラインです。
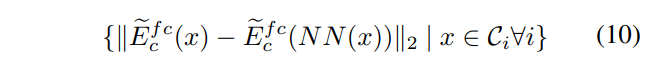
上式で$NN(x)$は、コンテンツ特徴空間内でもっとも近い、同一クラスの別画像を表しています。つまり、同じクラスであっても、別画像であればこれだけ異なったコンテンツ特徴を持っているよ、ということを示しています。
Stylization with disentanglement, Stylization w/o disentanglement
Disentanglment Lossの有無によって以下の距離がどのような分布になるのかをそれぞれ青と緑で表しています。
同一のコンテンツ画像のもと、別のスタイル画像を与えられた合成画像同士のコンテンツ特徴がどれだけ離れているかを表しています。
$\left|\widetilde{E}_{c}^{f c}\left(D\left(E_{c}\left(x\right), E_{s}(s_1)\right)\right)-\widetilde{E}_{c}^{f c}\left(D\left(E_{c}\left(x\right), E_{s}(s_2)\right)\right)\right|_{2}$
$s_{1} \in \mathcal{S}_{1}, s_{2} \in \mathcal{S}_{2}, x \in \mathcal{C}_{i} \forall i$
なお、上の数式は論文中の式(11)に対応しますが、論文では添字にミスがあったので修正しています。
改めて分布のグラフに戻ると、青い分布は緑の分布よりも低い値にも分布しているため、Disentanglment Lossの効果が確認できます。
Distribution Divergence
最後に、提案したFixpoint Triplet Lossの効果を確認します。
おさらいしておくと、Fixpoint Triplet Lossは、同一のスタイルであっても、題材や時代によってちょっと異なるスタイル情報を持っているはずだ、という直観を反映させたものでした。
以下はスタイルを2つに絞って確認します。また、スタイル特徴は、Disentanglement of Style and Contentで示したスタイル分類器から得られるものです。
KL Divergence
実際の絵画のスタイル特徴の分布$\mathbb{P}_s^{art}$と合成画像のスタイル特徴$\mathbb{P}_s^{stylized}$の差異をKL Divergence$D_{KL}(\mathbb{P}_s^{stilized} || \mathbb{P}_s^{art})$で評価します。また、Fixpoint Triplet Lossを使用しない場合も$D_{KL}(\mathbb{P}_s^{no \mathcal{L}_{FPT-style}} || \mathbb{P}_s^{art})$として算出しています。
結果は以下の表の一番右の列にある通り、損失の有無によってKL Divergenceは0.21, 1.14となり、Fixpoint Triplet Lossの導入によってより実際のスタイル特徴の分布に近い合成画像が得られることがわかります。
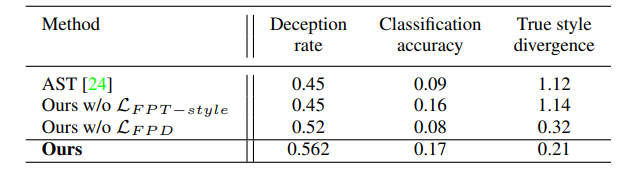
主成分の可視化
もう少し、ひと目でわかる結果を見てみましょう。
実際の絵画のスタイル特徴に対して主成分分析を行い、第一主成分を取り出してその分布を可視化すると以下のグラフの赤い分布になります。
上記の主成分が、合成画像ではどのように含まれているのかを、損失ありのモデル(青)、損失なしのモデル(緑)で比較しています。
損失ありのモデルのほうが、無いよりも実際の絵画の分布に近いという結果がわかります。
まとめ
スタイル変換手法についての論文Content and Style Disentanglement for Artistic Style Transferを紹介しました。
個人的には、Fixpoint Triplet Lossは目からウロコで、たしかに同じ画家が描いたからといって、個別の絵画が同一のスタイル情報を持っているということは考えにくいので、それをうまく捉えた損失になっていると思いました。
また、評価の方法が非常に参考になりました。乱数を入力とした画像生成モデルでは、FIDのような指標がよく使われますが、本手法が対象としているような条件付き画像生成結果の評価ってどうすれば良いのか、一例がわかってよかったです。
-
https://pytorch.org/tutorials/advanced/neural_style_tutorial.html ↩
-
https://www.tensorflow.org/tutorials/generative/style_transfer ↩
-
Sanakoyeu, Artsiom, et al. "A style-aware content loss for real-time hd style transfer." Proceedings of the European Conference on Computer Vision (ECCV). 2018. ↩