概要
画像認識系のデータ拡張手法RandAugmentについての論文を読んだので紹介してみます。
ひとことでいえば、$K=14$種類のデータ拡張操作からランダムに$N$個サンプルし、それぞれを強さ$M$で順番に適用する、というデータ拡張ポリシーです。$K=14$はあまり変えることはないので固定値とし、チューニングするパラメータは$N, M$の2つの整数値(いずれも$[0,10]$)だけになるので、単純なグリッドサーチによって最適なデータ拡張ポリシーが得られる、というものです。
本論文は2019年9月が初出ですが、ImageNetのTop1精度を当時の84.4(EfficientNet-B7 + AutoAugment)から85.0(EfficientNet-B7 + RandAugment)に塗り替えたという実績があります。本手法が登場するまでのデータ拡張の研究といえば、AutoAugmentから派生した、事前に時間をかけて最適なデータ拡張ポリシーを探索したうえで最終的な訓練に臨むというタイプの手法が多かったように思います。しかし、本手法では、たった2つのハイパーパラメータをグリッドサーチするだけでそれらと同等以上の結果が得られています。
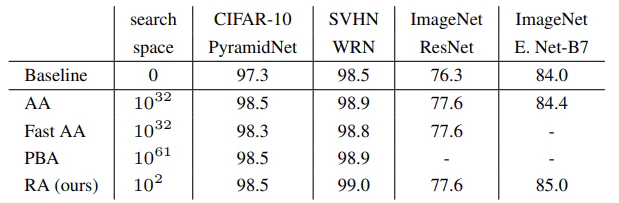
非常に単純な手法なので何をやっているかは簡単にわかるわけですが、どういう考えからこの手法が編み出されたのかを、論文で確認します。
書誌情報
- Cubuk, Ekin D., et al. "Randaugment: Practical automated data augmentation with a reduced search space." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020.
- 公式実装(TensorFlow)
データ拡張操作とmagnitude
個々のデータ拡張操作の基本的な画像処理なので、ある非公式のPyTorch向け実装では、PILの基本的な処理のみで実現しています。なお、この実装では、以下のように既存のtransforms.Composeに追加するだけで簡単に適用できます。
# https://github.com/ildoonet/pytorch-randaugment
from torchvision.transforms import transforms
from RandAugment import RandAugment
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(_CIFAR_MEAN, _CIFAR_STD),
])
# Add RandAugment with N, M(hyperparameter)
transform_train.transforms.insert(0, RandAugment(N, M))
本手法では、AutoAugmentで行われた、各データ拡張操作の強さをmagnitudeというパラメータでコントロールするという発想を継承しています。以下はAutoAugmentで使われていたデータ拡張操作とその強さをコントロールするmagnitudeのリストです。
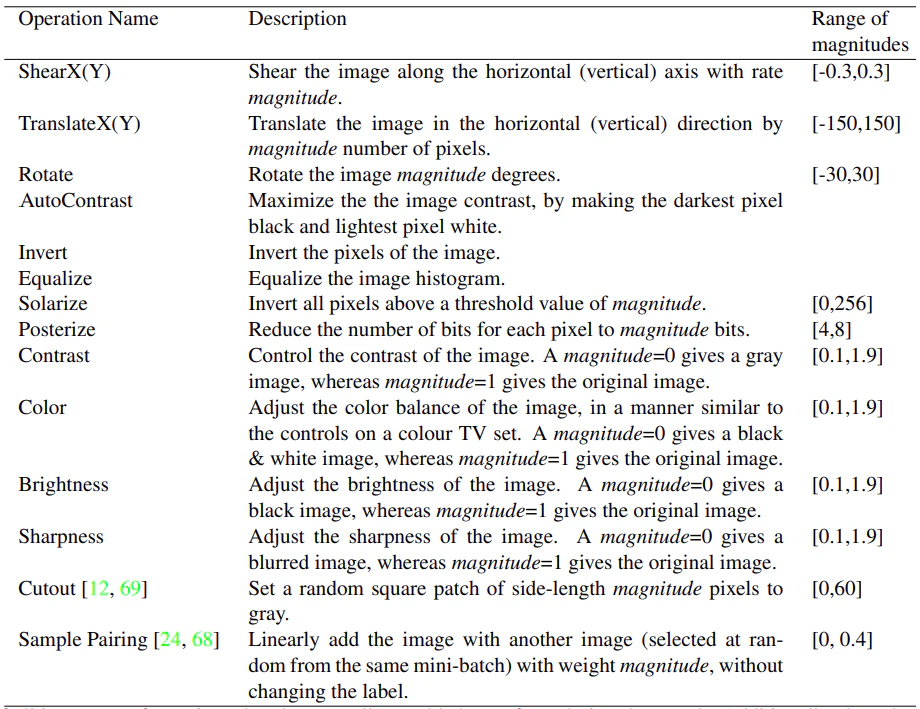
本手法では、以下の14の操作を対象としています。
- identity
- autoContrast
- equalize
- rotate
- solarize
- color
- posterize
- contrast
- brightness
- sharpness
- shear-x
- shear-y
- translate-x
- translate-y
どんな操作なのか想像がつかない方は、これらの操作を確認できるColabNotebookを作ったので、確認してみてください。なお、公式実装を確認すると、InvertとSolarizeAddという変換も加えられているようです。
本手法の面白い点として、すべての操作のmagnitudeを$M$という単一のパラメータで指定する点にあります。これにより、探索空間を大幅に削減しています。また、$K$個のデータ拡張操作は、それぞれ均等にサンプルされます。AutoAugmentなどでは、このサンプル確率も最適化の対象だったので、この点においても探索空間が削減されています。
問題意識
本論文の問題意識は、「proxyタスクで有効なデータ拡張ポリシーは、必ずしもlargeタスクで最適ではないのではないか」という素朴なものです。
proxyタスクとは、データ拡張ポリシーの最適化をする過程で行われる小さいデータセットや小さいネットワークで行われる訓練と評価を意味します。largeタスクとは本来使いたい大きいデータセットやネットワークによる訓練と評価です。
多くの学習ベースのデータ拡張ポリシーの最適化手法では、最適化の過程で訓練と評価を繰り返す必要があるため、largeタスクよりも短時間で行えるproxyタスクで最適化を行って、そのあとlargeタスクの訓練に入ります。これにより、最初からすべてをlargeタスクで最適化しようとするよりも効率的に最適なデータ拡張ポリシーを得ることができる、としています。
しかし、本研究の疑念はまさにこの点にあります。つまり、proxyタスクで最適だったからってlargeタスクにそのまま適用していいの、というわけです。
実験
CIFAR-10による簡単な実験を通じて、proxyタスクとlargeタスクで、最適なデータ拡張ポリシーが一致しているのか、を調査しています。ベースラインのデータ拡張方法として、左右反転とランダムな平行移動が使われています。
$K=14, N=1$は固定し、$M$は$[0,30]$の範囲としています。この$M$は実験のためにかなり強めのmagnitudeも選択できるようにしていますが、本来は$M=10$が最大値で、先に掲載したAutoAugmentのmagnitudeの範囲と合致します。
以下の2点を変えながら実験をしています。
- Wide-ResNet-28のwideningパラメータを増減させる
- 教師データのサイズを変える
実験結果のグラフを確認してきます。
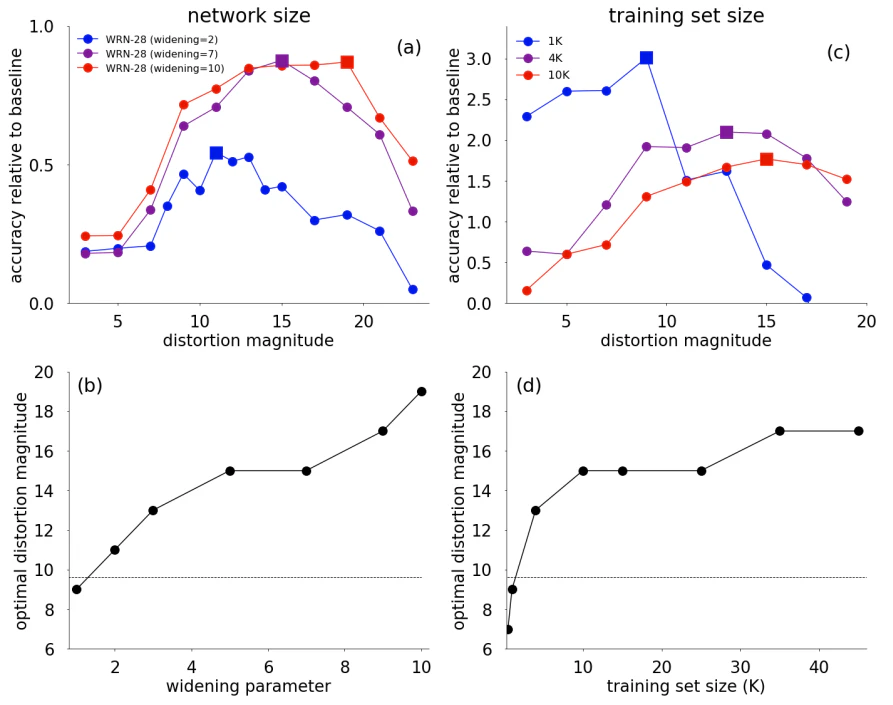
(a)は、3つのwideningパラメータをもつ別々のネットワークが、ベースラインのデータ拡張をどれだけ上回ることができるのかを示しています。横軸は$M$の大きさ、縦軸が精度の向上です。精度向上のピークを確認すると、大きな容量のネットワークでは、より大きい$M$にピークがあるという傾向が確認できます。
(b)を見るとより明確です。(b)では、様々なwideningパラメータにおいて、どの強さの$M$で最も精度向上が得られたのか、ということを示しています。より容量の大きいモデルほど、より強い$M$によって精度向上がもたらされるということが確認できます。
一方(c)は、3種類の教師データのサイズにおいて、ベースラインのデータ拡張をどれだけ上回ることができるのかを示しています。横軸は$M$の大きさ、縦軸が精度の向上です。精度向上のピークは、教師データが大きいほど$M$が大きい位置にあることがわかります。
(d)はより細かく、教師データのサイズが大きければ大きいほど、最適な$M$は大きくなる、という傾向を示しています。これは非常に驚くべき結果で、小さい教師データほど足りない分布を補うために強めのデータ拡張が必要だ、という直感が実験的に否定されていることになります。
これらの結果から、proxyタスクに対して最適なデータ拡張ポリシーが必ずしもlargeタスクに対して最適ではない、という結論が導かれます。
具体的なmagnitudeの適用方法
$M$を決めることでデータ拡張の強さを決める、という点について補足しておきます。本手法では、一度決められた$M$が、毎回magnitudeとして採用されます。例えば、rotation操作のmagnitudeを$M=10$(±30度)と決めたら、それ以外の値は使われません。-30度から30度の間からランダムに使う、というわけではないわけです。
このあまりにも単純なmagnitudeの適用方法は、実験の結果選ばれています。指定された$M$に対して使用するmagnitudeを決める方法として、以下の用な4パターンを比較しています。
- Random Magnitude: $M$以内のmagnitudeをランダムに選択。
- Constant Magnitude $M$に対応するmagnitudeのみを選択。
- Linear Increasing Magnitude: magnitudeを$M$に徐々に近づける。
- Random Magnitude with Incresing Upper Bound: 徐々に$M$に近づくUpperBoundを設けて、UpperBound以内のmagnitudeをランダムに選択。
CIFAR-10、Wide-ResNet-28-10による実験結果が以下のとおりで、いずれの方法もほとんど変わらない結果となっています。ハイパーパラメータを削減できるため、Constant Magnitudeを最終的な方法として採用しています。

まとめ
最近いろいろな画像分類の論文で当たり前のようにRandAugmentが使われているので、確認のために読んでみました。
proxyタスクの有効性への疑念から出発し、magnitudeを全データ拡張操作で共通にして検索空間を極限まで減らしても大丈夫というところまで示しているのが面白いです。