概要
最近、単眼で撮影した1枚の画像をもとに、3次元風に別視点からの画像を合成するという手法をよく目にします。有名所ではFacebookの3D写真などがあります。
研究的にはどのようなものが出てきているのかと調べてみると、少し調べただけで以下の4つを見つけました。きっと探せていないだけで、他にもいろいろあると思います。これらの手法は、入力と出力は似たようなものですが、少しずつ問題設定が異なっています。
- Single-view view synthesis with multiplane images
- SynSin: End-to-end View Synthesis from a Single Image1
- 3D Ken Burns effect from a single image2
- 3D Photography using Context-aware Layered Depth Inpainting3
この記事では、一番上に上げた"Single-view view synthesis with multiplane images"を紹介します。Google Researchの研究で、CVPR2020に採択されているようです。入力された画像をもとに、Multiplane Image(以下、MPI)という形式に変換し、それをもとに別視点からの合成画像を構築する、というのが基本的な流れです。
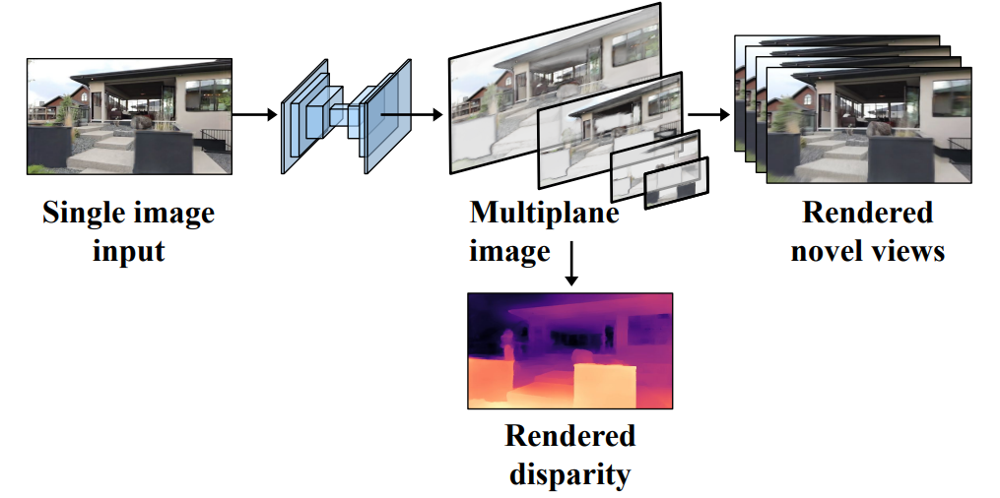
どんな出力結果になるのかがひと目でわかるのは公式のプロジェクトページのInteractive examplesや公式の動画ですので、そちらを見てみてください。
本記事では、MPIについて説明した後、訓練のながれを説明します。最後に簡単にですが、本論文の提案の有効性を確認する実験結果をみています。
書誌情報
- Tucker, Richard, and Noah Snavely. "Single-View View Synthesis with Multiplane Images." arXiv (2020): arXiv-2004.
- Project Page
Multiplane Image
本手法では、入力された画像をMPIという形式に変換してから別視点の画像を合成します。このMPIは、以下のように表現されます。あるカメラから見える映像は、RGBAの複数のレイヤーが重ね合わされたものである、という表現方法です。これは厳密な3次元形状の復元ではありませんが、別視点からの画像を合成するというタスクでは、ある程度まで機能します。
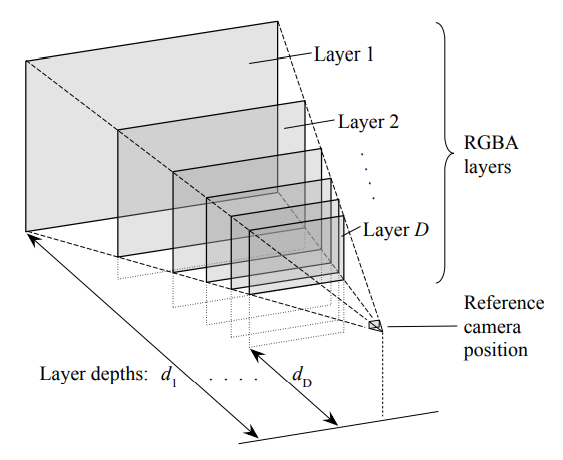
数式的には以下のように表現されます。まず、入力画像$\mathbf{I}_s$から、関数$f$をとおして、MPIに変換します。
\left\{\left(c_{1}, \alpha_{1}\right), \ldots,\left(c_{D}, \alpha_{D}\right)\right\}=f\left(\mathbf{I}_{s}\right)
$c_i, \alpha_i$は、それぞれ$i$番目のRGB画像とアルファ画像を表します。基本的には、$c_i$は$I_s$と同じ画像としても問題ありません(のちほど$c_i$の決め方に関する工夫が出てきます)。これに対して、入力画像のカメラから別のカメラへと移動させる変換$\mathcal{W}_{v_{s}, v_{t}}$と、固定で与えられている各レイヤーの深度$d_i (i=1, 2, ..., D)$、および深度のスケールを定める$\sigma$を用いると、出力に使われるMPIレイヤーのRGB画像$c_{i}^{\prime}$とアルファ画像$\alpha_{i}^{\prime}$は以下のように表現されます。この変換は、レイヤーごとに行われます。
c_{i}^{\prime}=\mathcal{W}_{v_{s}, v_{t}}\left(\sigma d_{i}, c_{i}\right), \quad \alpha_{i}^{\prime}=\mathcal{W}_{v_{s}, v_{t}}\left(\sigma d_{i}, \alpha_{i}\right)
得られた複数のレイヤーをもとに、最終的な合成画像 $\hat{\mathbf{I}}_{t}$ を作ります。より手前にあるレイヤーのほうが優先して描画されるので、$\alpha_{i}^{\prime}\prod_{j=i+1}^{D}\left(1-\alpha_{j}^{\prime}\right)$によってどの程度そのレイヤーのRGB画像$c_{i}^{\prime}$を反映させるかを決定します。手前側に完全に不透明な領域があるのであれば、それより広報にあるレイヤーのその領域は描画されない、ということです。
\hat{\mathbf{I}}_{t}=\sum_{i=1}^{D}\left(c_{i}^{\prime} \alpha_{i}^{\prime} \prod_{j=i+1}^{D}\left(1-\alpha_{j}^{\prime}\right)\right)
なお、複数枚のレイヤーは深さにそのまま対応しているので、MPIからdisparity map $\hat{\mathbf{D}}_s$(入力画像に対する視差≒深度マップ)を求めることができます。有限のレイヤーを使って表現するので離散値になりそうですが、$\alpha$が組み合わされることで連続値で表現できます。
\hat{\mathbf{D}}_{s}=\sum_{i=1}^{D}\left(d_{i}^{-1} \alpha_{i} \prod_{j=i+1}^{D}\left(1-\alpha_{j}\right)\right)
以上がMPIについての説明ですが、いくつかの疑問が生じます。
- 画像からMPIを求める関数$f$はどのようにして得られるのか
- 深度をスケールする$\sigma$はどのように求められるか
以下、本手法の流れを見ていくことでこれらの疑問を明らかにします。
手法の流れ
以下に本手法の流れを示します。
まず、動画に対してSfM(Structure from Motion)を適用し、Point cloud及び、各フレームにおけるカメラの姿勢・位置(外部パラメータ)とカメラの内部パラメータを求めます。SfMについては、具体的にどの手法を使ったという記述はありませんが、本手法の先行研究4では、ORB-SLAM25を用いているそうです。
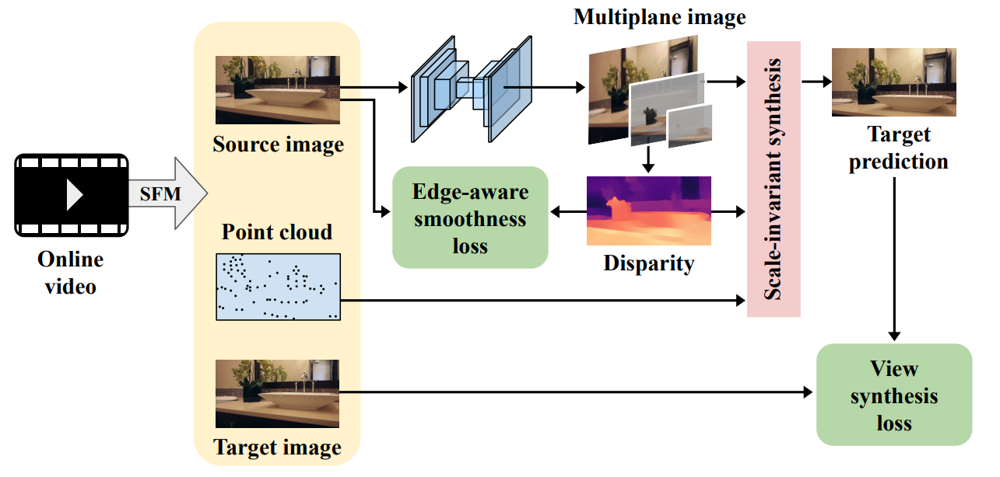
次に、動画のフレームの中からSource画像とTarget画像が選択されます。Source画像をDispNet6風のネットワークに入力し、得られたアルファ画像を加工することで、MPIを得ます。前述の通り、MPIからDisparityマップを作ることができます。また、Source画像からTarget画像へのカメラの変換$\mathcal{W}_{v_{s}, v_{t}}$を用いて、予測画像を得ることができます。
訓練は、予測画像とターゲット画像の差異などを損失関数とすることで行います。
DispNet風ネットワークと背景予測
唯一の訓練対象であるDispNet風ネットワークは、MPIへの変換関数$f$そのものではありません。実際には、DispNet風ネットワークは、MPIのレイヤーごとのアルファ画像のみを予測します。
この内、もっとも遠い位置にあるアルファ画像$\alpha_1$は完全に不透明な背景画像に対応しているため、$\alpha_1 = 1$となる固定値です。
ここで、各レイヤーのRGB画像$c_i$について考えていきます。$c_i$は、どうせ$\alpha_i$によっていらない部分は見えなくなるため、$c_i = \mathbf{I}_s$としても良いように思えます。しかし、別視点からの画像合成時には、いままで見えていなかった領域が見える(disocculusion)ようになるため、何らかの形でその領域を補完したいと考えます。
やり方はいろいろあるとは思いますが、本手法ではDispNet風ネットワークのもう一つの出力として、$\hat{\mathbf{I}}_{bg}$を考えます。この$\hat{\mathbf{I}}_{bg} \neq \mathbf{I}_s$によって、新しい視点から見たときに生じる空白を補完することができます。このやり方を本稿では背景予測と呼びます。
背景予測を用いると、$\mathbf{I}_s$と$\hat{\mathbf{I}}_{bg}$の重み付け和として$c_i$を得ることができます。
\begin{aligned}
w_{i} &=\prod_{j>i}\left(1-\alpha_{j}\right) \\
c_{i} &=w_{i} \mathbf{I}_{s}+\left(1-w_{i}\right) \hat{\mathbf{I}}_{b g}
\end{aligned}
以下は、論文の図4からの抜粋です。(c)はこの背景予測ありのときの合成結果、(d)は背景予測によって補完された領域をピンクで示したもの、(e)は背景予測なしのときの結果です。(e)だとガタガタな結果になっている領域が、ややぼやけていますが補完できていることがわかります。

なお、訓練の初期では、$\hat{\mathbf{I}}_{b g}$はネットワークの出力結果と$\mathbf{I}_{s}$との線形補間とすることで訓練を安定にする必要があるそうです。
深度スケールの求め方
一般に、単眼画像で撮影された動画からのSfMでは、スケールを求めることができません。これは、あるフレームを撮影した視点と別フレームを撮影したの視点の本当の距離がわからないことに起因します。逆に言うと、ステレオカメラでは、少なくとも同一デバイスについている2つの視点の距離は事前にわかっているので、スケールは一意に定まります。
本手法では、スケールを以下のように定めることにしています。これは、異なるフレームのカメラ間の距離や動画から得られるPoint cloudのスケールは、どの訓練サンプルでも一定であるという仮定をおいています。この仮定は一見乱暴なように見えますが、訓練に使用するデータセット内でのカメラの移動速度がそこまで極端に違わないという前提を置けば、そこまで乱暴ではありません。なお、$\mathbf{P}_s$はSource画像の視点から見たときのPoint cloudの座標の集合を表しています。
\sigma=\exp \left[\frac{1}{\left|\mathbf{P}_{s}\right|} \sum_{(x, y, d) \in \mathbf{P}_{s}}\left(\ln \hat{\mathbf{D}}_{s}(x, y)-\ln \left(d^{-1}\right)\right)\right]
損失関数
訓練に使用される損失関数は、以下の3つの要素からなっています。
\mathcal{L}=\lambda_{\mathrm{p}} \mathcal{L}^{\mathrm{pixel}}+\lambda_{\mathrm{s}} \mathcal{L}^{\mathrm{smooth}}+\lambda_{\mathrm{d}} \mathcal{L}^{\mathrm{depth}}
これらの損失関数を細かく見ていきましょう
ターゲット画像の予測損失(pixel)
予測画像は、ターゲット画像に近い必要があります。この要求を、ピクセルレベルのL1損失を用いて、以下のように定めます。
\mathcal{L}^{\text {pixel }}=\sum_{\text {channels }} \frac{1}{N} \sum_{(x, y)}\left|\hat{\mathbf{I}}_{t}-\mathbf{I}_{t}\right|
Disparityマップの滑らかさ(smooth)
Disparityマップは、同一物体の中ではだいたい等しいという性質を持っている必要があります。しかし、物体の境界に当たる部分は、その限りではありません。
この性質を満たす損失を、入力画像にSobelフィルターを適用して得られるエッジ画像$\mathbf{E}_{s}$を用いて、以下のように表現します。
\mathcal{L}^{\mathrm{smooth}}=\frac{1}{N} \sum_{(x, y)}\left(\max \left(\mathbf{G}\left(\hat{\mathbf{D}}_{s}\right)-g_{min}, 0\right) \odot\left(1-\mathbf{E}_{s}\right)\right)
なお、$\mathbf{G}$は入力の各チャネルに対してSobelフィルターを適用した後足し合わせることで勾配を算出するもので、エッジ画像$\mathbf{E}{s}$は入力画像に対して$\mathbf{G}$を適用した後にスケールを調整することで得られます。$g{min}$は、ある程度までの勾配の変化までは許容し、損失としないためのパラメータです。
\mathbf{G}(\mathbf{I})=\sum_{\text {channels }}\|\nabla \mathbf{I}\|_{1}
\mathbf{E}_{s}=\min \left(\frac{\mathbf{G}\left(\mathbf{I}_{s}\right)}{e_{\min } \times \max _{(x, y)} \mathbf{G}\left(\mathbf{I}_{s}\right)}, 1\right)
疎な深度信号
Point cloudが事前に得られているので、Disparityマップに対して疎な点レベルであれば、教師信号を与えることができます。
\mathcal{L}^{\text {depth }}=\frac{1}{\left|\mathbf{P}_{s}\right|} \sum_{(x, y, d) \in \mathbf{P}_{s}}\left(\ln \frac{\hat{\mathbf{D}}_{s}(x, y)}{\sigma}-\ln \left(d^{-1}\right)\right)^{2}
実験
以上が本手法で提案されていることですが、提案されている損失などが有効だったのかを実験結果を通して確認していきましょう。
RealEstate10Kというデータセットを使って、以下のようなバリエーションで比較して評価しています。
- full: 提案手法全部盛り。
- nodepth: $\mathcal{L}^{\text {depth }}$を使用しない。
- noscale: $\sigma=1$で固定とし、$\sigma$を使用する損失$\mathcal{L}^{\text {depth }}$も使用しない。
- nosmooth: $\mathcal{L}^{\mathrm{smooth}}$を使用しない。
- nobackground: 背景予測をせず、$c_i = \mathbf{I}_s$とする。
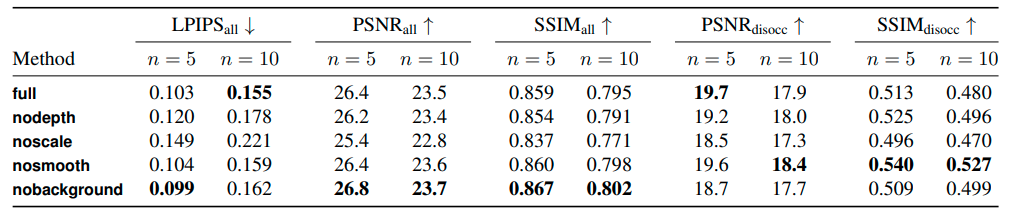
意外にも、fullが最も良い結果であるというわけではないのですが、すべての評価指標で安定した結果が得られていると言えます。なお、$n$は、ソース画像とターゲット画像の間のフレーム数です。全体的に、フレーム数が大きいほど評価指標は悪化します。これはこの手の合成手法では当たり前の結果です。また、評価指標の下付き文字にdisoccという記載があるのは、視点の変更によって初めて見えた領域のみで評価するとどうだったかという指標です。
まず、noscaleの精度が一貫して悪いことから、深度スケールの決定方法が大きな改善をもたらしている、と言うことができます。
一方、fullとnosmoothと比較すると、おおむね同一の精度で${SSIM}_{disocc}$が群を抜いて良い結果になっていることを考えると、$\mathcal{L}^{\mathrm{smooth}}$は無理に使用しなくても良いのかもしれません。とはいえ、下図に示すように単純な見た目で言えば、Disparityマップの結果がきれいになるのはfullの方みたいです。

まとめ
MPIを用いた新視点画像の合成手法を提案した論文について説明しました。公式のプロジェクトページでInteractive demoを動かしてみると、いろいろと粗はありそうですが全体的にかなり整合性のとれた結果が得られていることがわかります。
冒頭に挙げた別の手法では、Point cloudから直接レンダリングできる微分可能なレンダラーを提案していたり、深度推定の後処理を洗練させることで高精度な結果を得ていたりと、それぞれ全く異なるアプローチで合成画像生成に取り組んでいるようなので、機会があればちゃんと読んでみようと思います。
-
Wiles, Olivia, et al. "SynSin: End-to-end View Synthesis from a Single Image." arXiv preprint arXiv:1912.08804 (2019). https://github.com/facebookresearch/synsin ↩
-
Niklaus, Simon, et al. "3D Ken Burns effect from a single image." ACM Transactions on Graphics (TOG) 38.6 (2019): 1-15. ↩
-
Shih, Meng-Li, et al. "3D Photography using Context-aware Layered Depth Inpainting." arXiv preprint arXiv:2004.04727 (2020). https://shihmengli.github.io/3D-Photo-Inpainting/ ↩
-
Zhou, Tinghui, et al. "Stereo magnification: Learning view synthesis using multiplane images." arXiv preprint arXiv:1805.09817 (2018). ↩
-
Mayer, Nikolaus, et al. "A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. ↩