概要
画像分類タスクの補助タスクとして、分割されシャッフルされた画像を整序するタスク(ジグソーパズル)も解くことでDomain Generalizationを実現する手法JiGenを提案。
Domain Generalization(以下、DG)とは、写真の馬もイラストの馬もhorseと分類できるようにするために、複数のドメイン(写真、イラスト、線画, etc.)の間で不変な特徴を学ぶこと。Domain Adaptationが対象ドメインでの動作を優先するのに対して、DGは複数のドメインで動作することを目的とする。
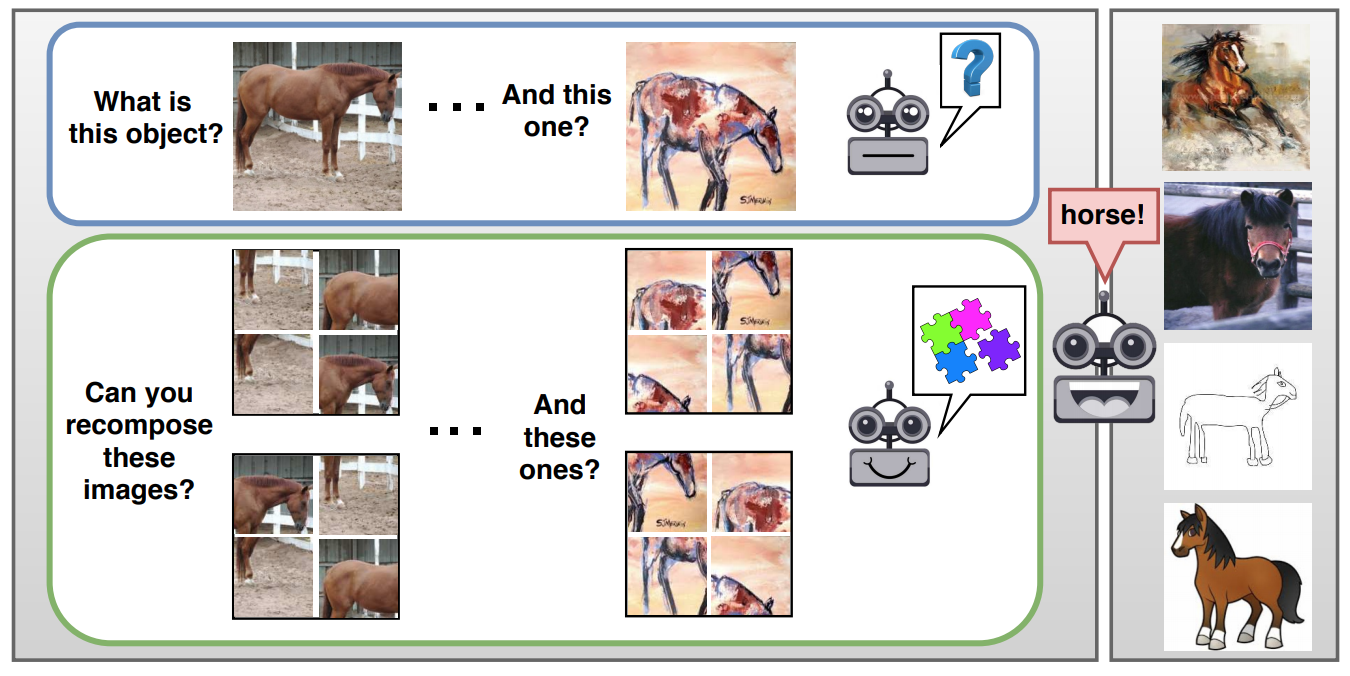
ジグソーパズルのタスクは入力画像そのものから生成できるので、自己教師あり(self-supervised)学習ができる。
注意:この文書はざっくりとしたメモです。細かい内容に関しては元論文や他の解説記事に当たってください。
論文情報
- Carlucci, Fabio M., et al. "Domain Generalization by Solving Jigsaw Puzzles." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- CVPR2019(Oral)
手法
ネットワークの構造
以下にネットワーク構造の略図を示す。通常の画像分類のネットワーク(図中のConvnetとObject Classifier)のヘッド部分にJigsaw Classifierが付いているというシンプルな構造になっている。
Object Classifierの方では物体分類タスクを解けるように、Jigsaw Classifierの方では画像に対してどのようなシャッフルが施されたのかを分類できるようにしたい。
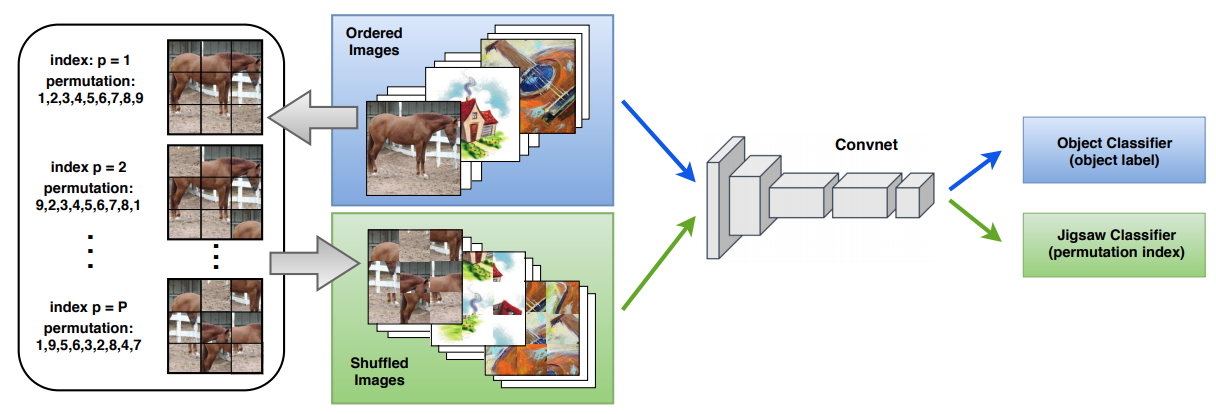
図の例では、入力画像は3x3の9分割されており、それらに対して「そのまま」というパターンを含むP通りのシャッフルパターンが適用されている。このP通りのシャッフルパターンは固定であり、Jigsaw Classifierは、Pクラス分類問題を解ければよい。
シャッフルパターンの作り方
P個のシャッフルパターンは、参考文献1に従って、シャッフルパターン間のハミング距離ができるだけ大きくなるように作成される。以下は参考文献に記載されているアルゴリズムである。

損失関数
損失関数は以下のようになる。
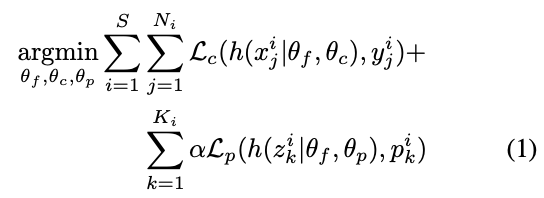
$S$はドメインの数、$N_i$は$i$番目のドメインのインスタンスの数、$x_j^i, y_j^i$は、元画像とその物体クラス、$K$は1枚の画像に対して適用されたシャッフル画像の数、$z_k^i, p_k^i$はシャッフルされた画像とそのシャッフルパターンを表し、$f, g, h$はそれぞれ、共通のConvNet、Object Classifier、Jigsaw Classifierを表す。
$L_c, L_p$は共に通常のCross Entropy損失である。
注意すべき点として、$x$は元画像のみで、シャッフルされた画像を含んでいない、ということが挙げられる。つまり、シャッフル画像$z$にたいする物体分類誤差は発生しない。一方で、シャッフルパターンの中には「元画像から何もシャッフルしない」というパターンも含まれているので、$z$には$x$が含まれている。
(オプション)Domain Adaptationへの適用
本手法はDomain Generalizationのための手法ではあるが、Domain Adaptationにも適用可能である。
適用先ドメインのデータに対して、以下のように実施する。
- Object損失は存在しない(ターゲットとなるラベルが存在しないため)
- Jigsaw損失はself-supervisedなので、そのまま適用する。
- 物体分類結果の不確実性をなくすため、下式のような経験エントロピー損失を最小化する。
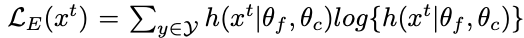
ハイパーパラメータ
本手法では、2つのタスク定義のためのパラメータと、3つの学習プロセスに関するパラメータが存在する。
タスクの定義に関するものとしては、以下の2つ。
- グリッドサイズ $n\times n$: $n = 3$で固定。
- シャッフルパータン数 $P$: $P = 30$で固定。
学習プロセスに関するものとしては、以下の3つ。
- 損失関数にある、Jigsaw損失の重み$\alpha$
- (オプション)Domain Adaptation時の経験エントロピー損失の重み$\eta$
- ミニバッチ中に含まれる元画像の割合$\beta$: 交差検証の結果0.1(正常), 0.9(シャッフル)が適切とわかった。
実験
いくつかの実験を行なっているが、一つだけ取り上げる。
PACS2データセットは4つのドメイン(Photo, Art Paintings, Cartoon, Sketches)、7つの物体クラス(dog, elephant, giraffe. guitar, horse, house, person)からなるデータセットである。
以下に既存手法との比較を示す。
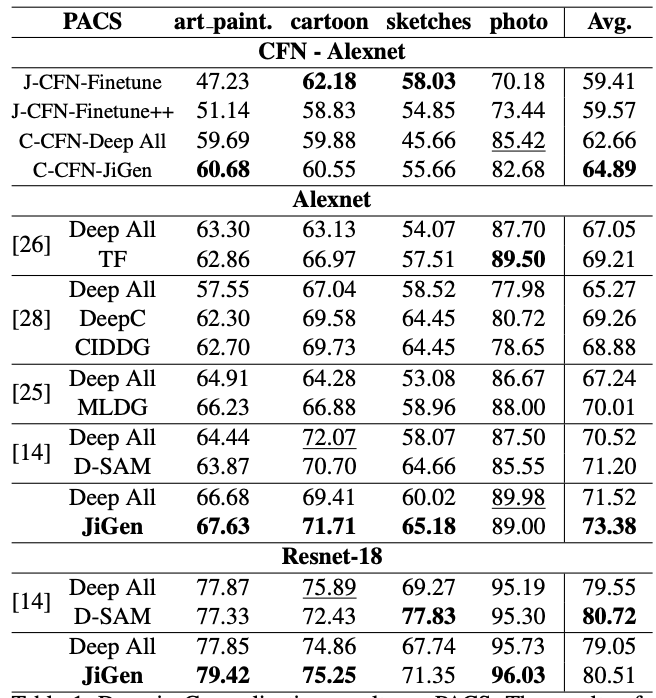
各ドメインでの1位は色々と変動しているが、全ドメインの平均では概ねもっとも良い精度が得られている。
D-SAM3は、一部で本手法よりも良い結果となっている。しかし、論文をちらっと見た限りでは、タスクの設計がなかなか複雑で、本手法の方が簡単に高精度を達成できるという点で好ましいと言える。
議論
JiGenによって、Domain Generalization/Adaptationの新しい道がひらけたと言えるが、本手法で達成できるドメイン不変性は、特定の種類の不変性でしかなく、より強力な正則化手法があるかもしれない。
また、今回は画像分類タスクへの適用を前提にしているが、セマンティックセグメンテーションやPerson Re-Identificationへの適用も考えられる。
感想
Abstractを読んで、シンプルで面白そうと思ったので読んでみた。
ジグソーパズルを解くというサブタスクをどんな風に設計しているのかが気になっていたが、固定のシャッフルパターンを分類するというシンプルな設計で、「こんな私にもできるかも!」と思わせてくれて楽しめた。
また、Domain Generalizationという問題設定は恥ずかしながら初耳だったので、それ自体が面白かった。
-
Noroozi, Mehdi, and Paolo Favaro. "Unsupervised learning of visual representations by solving jigsaw puzzles." European Conference on Computer Vision. Springer, Cham, 2016. ↩
-
Li, Da, et al. "Deeper, broader and artier domain generalization." Proceedings of the IEEE International Conference on Computer Vision. 2017. ↩
-
D’Innocente, Antonio, and Barbara Caputo. "Domain generalization with domain-specific aggregation modules." German Conference on Pattern Recognition. Springer, Cham, 2018. ↩