概要
自然画像中の文字検出タスク、いわゆるシーンテキストのための合成データ作成手法であるSynthTextを提案している論文を紹介します。本論文では合成データの作成手法と、シーンテキストのための新たなモデルを提案していますが、この記事では前者のみ取りあげます。
SynthTextは、様々なシーンテキスト手法における追加データとして使われており、メインのデータセットの不足を補うことに使われたり、合成データであるために文字レベルでのアノテーションが必要な際に使われるようです。
以下の画像はその一例です。空中や鳥に文字が書いてあることはもちろんあり得ないのですが、実際にそこにテキストが存在していてもおかしくないような「面」を見つけ出し、自然な合成画像を生成できていることが確認できます。

書誌情報
- Gupta, Ankush, Andrea Vedaldi, and Andrew Zisserman. "Synthetic data for text localisation in natural images." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
-
公式実装
- masterブランチはpython2でしか動かないので、python3ブランチ推奨
- 各種Forkで様々な言語への対応が行われている模様
手法
SynthTextの手法をわかりやすくまとめているのが以下の画像です。

入力画像
左上は入力される背景画像で、この上にテキストを合成していきます。
本論文では、Google画像検索によって8000枚の背景画像を集めています。背景画像そのものにテキストが含まれているわけにはいかないので、street-signやmenuといった、いかにも画像中にテキストが出現しそうなクエリは使用していません。
最後には人手によるチェックを行っています。
深度画像
上段左から2番目の画像は、深度画像を表します。
深度画像は、単眼の深度推定モデルによって推定されています。本論文は2016年の論文ですので、今となってはもっと手軽で精度の良い単眼深度推定モデルがあるため、別の手法を使っても良いでしょう。この深度画像は、テキストを貼り付ける領域の法線を求めるのに使用しています。こうすることで、合成画像中のテキストが、物体の表面に表示されているように見えるようになります。
セグメント画像
次がgPb-UCM1という階層的なセグメンテーション手法によって得られるセグメント画像です。輪郭を検出し、物体の表面といえそうな領域に分割することが目的です。
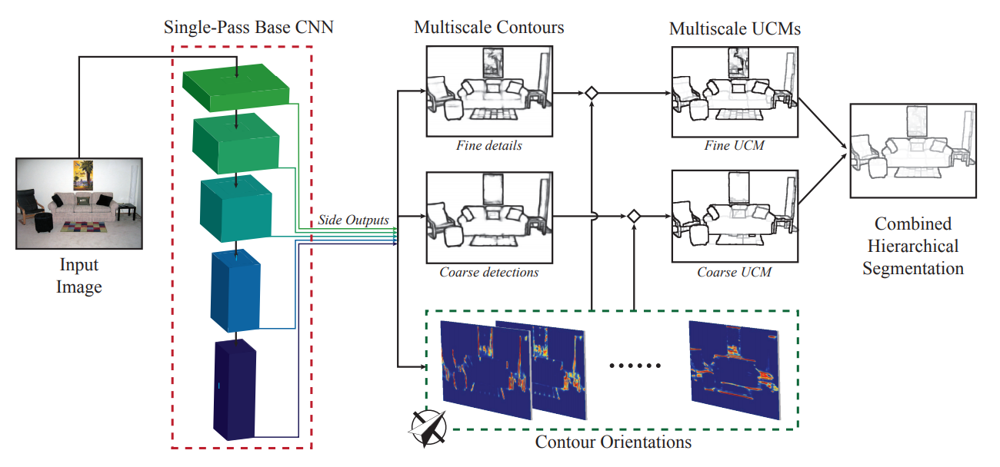
このようなセグメント画像と深度画像を組み合わせると、各セグメント領域がどのような3次元平面になっているのかを推定でき、法線ベクトルが得られます。深度画像はノイズが多いので、RANSACによってロバストな推定を行っています。
テキスト領域
上段右の画像は、テキストを合成する領域の候補となるセグメントを表しています。
まず、あまりにも小さな、極端に細長い、極端な法線ベクトルであるためにテキストを合成したとしても読めないセグメントなどは除外されます。
加えて、あまりにも細かいテクスチャを持つセグメントも除外されます。本手法では、3階微分が大きい領域を除外しています。
テキスト合成
本手法のオリジナルは英語を対象としているので、テキストはNewsgroup20データセットから3種類の方法でサンプルしています。
- 単語
- 文字列(3行まで)
- パラグラフ(7行まで)
このようなテキストを、背景画像のランダムに選ばれたセグメントにたいして合成するわけですが、以下のような流れで行います。
- テキストをランダムなフォント・色によってレンダリングし、テキスト画像を作成する。
- 貼り付け対象のセグメントを真正面から見るように透視投影変換を行う。
- セグメントに対して、テキスト画像をPoisson Image Editing2によって合成する。
- 同一セグメントに複数のテキスト画像を貼り付ける場合は、重ならないように調整しながら行う。
- セグメントを逆変換し、背景画像に戻す。
いくつか補足が必要です。
まず、レンダリングについては、やや細かいことを行っています。
貼り付ける背景領域の色と同じ色でテキストをレンダリングしてしまうと、シーンテキストのデータセットとしては難しすぎる設定になってしまいますし、逆にあまりにも異なる色だと簡単すぎる設定になります。
そこで、本手法では、できるだけ自然なテキスト色・背景色の組み合わせになるように、既存のシーンテキストデータセットであるIIIT5K word dataset3に出現するテキスト色と背景色の組み合わせをLab色空間で分析して、テキスト色・背景色の組み合わせを作成しています。
テキストをレンダリングする際には、まずは貼り付け対象のセグメントの色の平均を求め、上記で求めた組み合わせの背景色に最も近いものを選択し、テキスト色を決めています。
また、20%程度ランダムに、テキストには縁取りを施すといった処理も行っています。
次に、Poisson Image Editingについて簡単に説明します。
Poisson Image Editingはポアソンブレンドとも呼ばれる画像合成手法で、ソース画像を背景画像に貼り付ける際に、背景画像の周囲のテクスチャに馴染むように合成するという手法です。下の図の真ん中では、ソース画像と背景画像の間で大きく色合いが異なっていますが、右の画像ではうまく馴染んでいることがわかります。

ポアソンブレンドはOpenCVでも実装されており、cv2.seamlessCloneという関数で簡単に実現できます。
以上のようにして、レンダリングされたテキスト画像は、物体の表面らしい領域に違和感なく合成される、というわけです。
まとめ
以上、SynthTextについて簡単にまとめてみました。
公式実装では、PythonとMatlabが混じっているため、Matlabが使えない環境にいる人(たとえば、わたくし)は前処理済みのちょっと大きめのデータをダウンロードする必要があります。
また、日本語対応や中国語対応などを行っているForkがいくつかありますので、そちらも有効活用したいところです。
-
Maninis, Kevis-Kokitsi, et al. "Convolutional oriented boundaries: From image segmentation to high-level tasks." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 819-833. ↩
-
Pérez, Patrick, Michel Gangnet, and Andrew Blake. "Poisson image editing." ACM SIGGRAPH 2003 Papers. 2003. 313-318. ↩
-
http://cvit.iiit.ac.in/research/projects/cvit-projects/the-iiit-5k-word-dataset ↩