概要
最近公開されたEasyOCRというOCRライブラリのソースコードを読んでみると、テキスト領域の抽出にCRAFTという手法が使われていたので、元論文を読んでみました。
CRAFTはテキスト領域の検出手法です。本手法では、一般的な物体検出手法によってテキスト領域を検出するのではなく、一文字一文字の領域とそれらをつなぎ合わせる領域とを推定することで、文字領域からテキスト領域を推定するというボトムアップなアプローチを採っています。
以下は公式リポジトリに掲載されているGIF動画です。何らかのテキストが映っている画像に対して、文字単位でのヒートマップ、文字間のヒートマップ、テキスト領域(単語単位)の矩形領域が順番に表示されています。

この分野のデータセットの多くは単語単位での矩形領域のアノテーションがなされているものがほとんどで、文字単位で真の領域がアノテーションされているデータセットはあまりないそうです。このような弱教師ありのシナリオでどのように文字単位での推定が可能なモデルの訓練を行うのかが見所です。また、推定した文字単位のヒートマップと文字間のヒートマップをどのように組み合わせて最終的な出力にするのかという後処理のもポイントとなります。
本論文はCVPRE2019採択論文です。
書誌情報
- Baek, Youngmin, et al. "Character region awareness for text detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- https://arxiv.org/abs/1904.01941
- 公式実装(PyTorch)
ネットワーク構造
まず、簡単にネットワーク構造を確認します。
以下に示すように、RGB画像を入力すると2枚のヒートマップを出力する、U-Net状の構造になっています。文字単位のヒートマップはRegion score、文字間のヒートマップはAffinity scoreと表記されていて、入力画像の半分の解像度であることがわかります。

弱教師あり学習
つづけて、弱教師あり学習のやり方を見ていきます。基本的な流れは、以下の通りです。
まず、文字単位のアノテーションがなされている合成データセットを構築し、これを利用してある程度のモデルを訓練します。次に、そのモデルを使ってデータセット内の画像に対する文字単位のヒートマップを得ます。このヒートマップを疑似ラベルとして、さらにモデルを訓練していきます。
疑似ラベルは当然間違っていることもあるので、素直にこれを使ってモデルを訓練するのはやや問題です。そこで、疑似ラベルに対して信頼度を付与し、信頼度が低い領域では損失を小さくしてあげる必要があります。データセットには文字単位でのアノテーションは付与されていませんが、単語単位でのアノテーションはあるため、ある単語領域に何個の文字が存在しているのかはわかっています。そこで、疑似ラベルから得られる単語の文字数が真の文字数とどの程度一致しているのかを確認することで、その疑似ラベルがどの程度信頼できるのかを推定できます。
下図がこの流れの全体像となります。
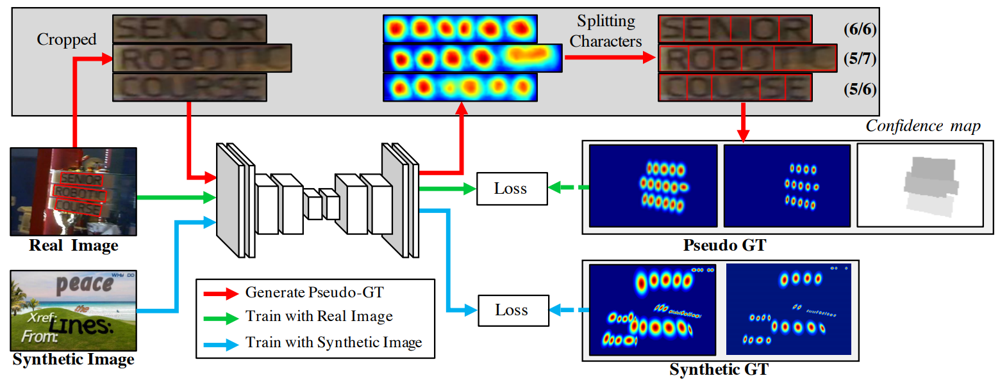
以下、各工程を詳しく見ていきます。
合成データセットのGround Truth
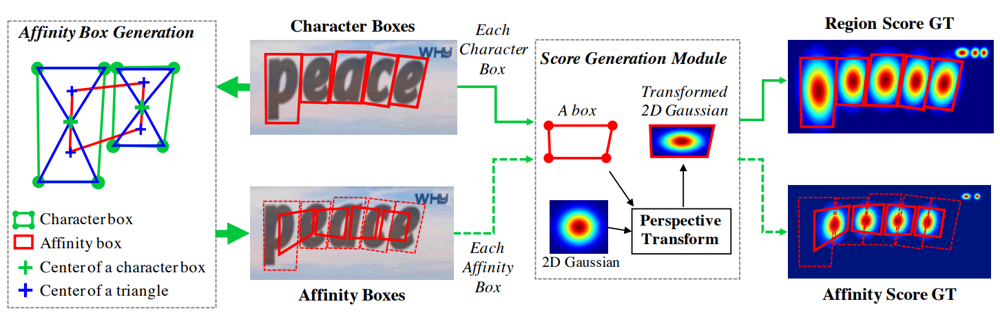
SynthTextは、上図の下段に示されている通り、適当な背景に様々なフォントの文字を張り付けて作成されおり、文字単位でのアノテーションが施されています。
文字単位での矩形領域に対してガウス分布の射影変換を施して対応させ、文字単位のヒートマップであるRegion Scoreマップ(下図右上)を作成します。同様に、文字間のヒートマップであるAffinity Scoreマップも、隣接する文字の矩形領域をもとに作られた矩形領域(下図左の赤線)に対してガウス分布を対応させて作成します。
疑似ラベルと信頼度の作り方
文字単位でのアノテーションが存在しないデータセットに対する疑似ラベルを作成するためには、アノテーションが存在する単語領域を、文字領域に分割する必要があります。この処理は、以下の流れで行います。
- SynthTextデータセットによってモデルをある程度まで訓練する
- 単語単位のアノテーションがなされている画像から、単語ごとの領域を切り出す
- 単語ごとの領域に対して、訓練中のモデルを利用して、文字単位のヒートマップを推定する
- 文字単位のヒートマップに対してWatershedアルゴリズムを適用し、文字ごとの領域を推定する
- 文字ごとの領域を囲む矩形領域を得る
- 文字ごとの矩形領域を、元の画像領域に戻す
下図がこの流れを表しています。
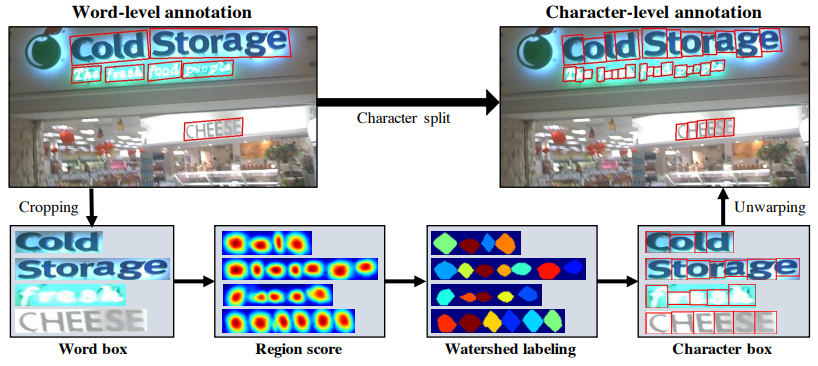
Watershedアルゴリズムはセグメンテーションのための伝統的な手法で、OpenCVでも手軽に使えるアルゴリズムです。
参考:https://qiita.com/ysdyt/items/5972c9520acf6a094d90
このように文字ごとに分割したのち、合成データセットと同様の手順でRegion ScoreマップとAffinity Scoreマップを得ることができます。これが疑似ラベルとなります。
次に、信頼度をの算出方法を見ていきます。
信頼度は単語領域ごとに計算されます。単語$w$に対する信頼度$s_{\text {conf}}(w)$は、真の文字数$l(w)$と推定された文字数$l^{c}(w)$とを比較することで、下式のように得られます。$l(w)=l^{c}(w)$なら信頼度は1.0となります。
s_{\text {conf}}(w)=\frac{l(w)-\min \left(l(w),\left|l(w)-l^{c}(w)\right|\right)}{l(w)}
単語領域の信頼度が十分でない場合、疑似ラベルをそのまま訓練に使用するのには問題が生じます。そのため信頼度が0.5未満の時には、雑ではあるが文字数は確実に合っているという別の疑似ラベルを用意します。作り方は単純で、単語領域を真の文字数で等幅に分割したうえでRegion ScoreマップとAffinity Scoreマップを作成することで得られます。この時の単語領域に対する信頼度は0.5で固定です。
単語領域ごとの信頼度を使い、画像全体の信頼度マップは以下のように得られます。各単語領域の信頼度は上で計算した通りで、それ以外の背景領域の信頼度は1となります。
S_{c}(p)=\left\{\begin{array}{ll}
s_{c o n f}(w) & p \in R(w) \\
1 & \text { otherwise }
\end{array}\right.
損失関数
推定された2つのヒートマップ$S_{r}(p), S_{a}(p)$、疑似ラベルを表す2つのヒートマップ$S_{r}^{*}(p), S_{a}^{*}(p)$、疑似ラベルの信頼度を表すヒートマップ$S_{c}(p)$を組み合わせ、最終的には損失関数は以下のように得られます。
L=\sum_{p} S_{c}(p) \cdot\left(\left\|S_{r}(p)-S_{r}^{*}(p)\right\|_{2}^{2}+\left\|S_{a}(p)-S_{a}^{*}(p)\right\|_{2}^{2}\right)
後処理
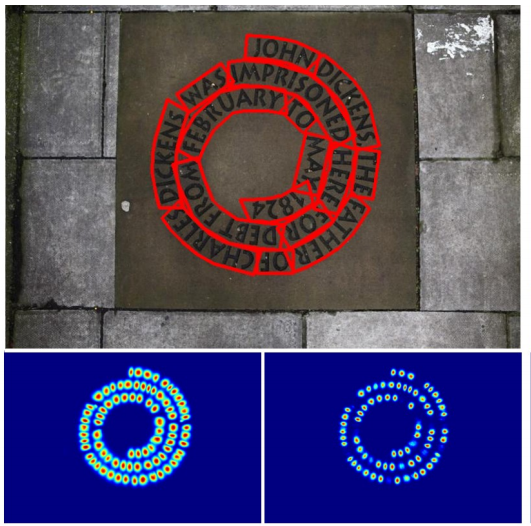
最後に、後処理の流れを確認していきましょう。本手法は単語が直線状に並んでいないような場合にも対応でき、例えば以下のような出力結果を得ることができます。下段に並んでいるヒートマップがそれぞれ推定されたRegion ScoreとAffinity Scoreで、これをもとに後処理を施すことで、上段のような単語領域を表す湾曲した赤い枠線を得ることができます。
後処理の流れは以下の通りです。
- Region Scoreマップ$S_{r}(p)$, Affinity Scoreマップ$S_{a}(p)$に対してそれぞれ閾値$\tau_r, \tau_a$を適用し、得られたマスクのORを採ることで、バイナリ画像$M(p)$を得る
- $M(p)$に対してConnected Component Labeling(CCL)を適用し、ひとまとまりになっている単語領域を推定する
- 得られた単語領域を囲むQuadBoxを推定する
- QuadBox内で、単語領域を囲むPolygonを推定する(詳細は後述)
CCLというのは単純にバイナリマスク画像を連結している部分ごとにラベル付けする処理で、伝統的な手法がOpenCVに実装されています。また、QuadBoxの推定も、OpenCVのminAreaRectといったメソッドで簡単に行えます。
一番複雑なのがPolygonの推定です。下図を見ながらご確認ください。
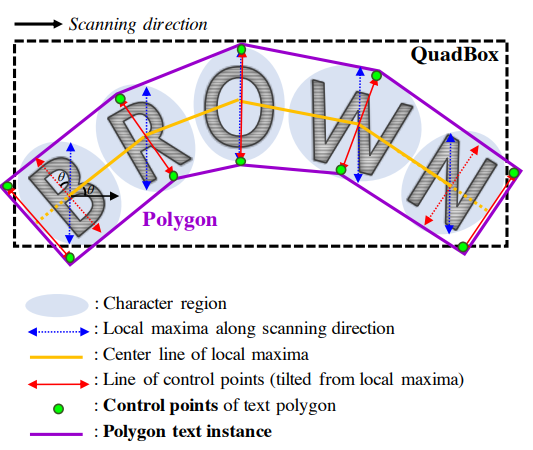
まず、各文字の領域($S_{r}(p) > \tau_r$)で最も長い高さとなっているところ(青い点線)をlocal maxima線として得ます。全文字のうち長さが最大のものを、このPolygon全体の高さとして採用し、全文字のlocal maxima線の長さをこれに統一します。各文字領域のlocal maxima線の中点を隣接する文字同士で結び、Center Line(黄色の実線)を得ます。Center Lineに垂直になるようにlocal maxima線を回転させ(赤い実線)、それ等の両端をPolygonの制御点候補(緑の点)とします。最初の文字と最後の文字に関しては、制御点を左端・右端へと移動させ、最終的なPolygonが得られます。
まとめ
以上ざっくりとですが、CRAFTの中身を確認しました。
文字領域のRegion Scoreだけでなく、文字間を表すヒートマップであるAffinity Scoreを推定するという単純な問題設定ながら、弱教師ありのシナリオに対応するための工夫や、得られたヒートマップに対する丁寧な後処理が面白い手法だと思いました。