概要
最近、「First Order Motion Model for Image Animation」1というアニメーション生成手法に衝撃を受けて、論文を読んでみたのですが、その中で、教師なしのキーポイント検出の手法が当たり前のように使われていました。「First Order ~」の論文中では大した説明がなかったので、元論文に当たることにしました。
「First Order ~」の論文中ではキーポイント検出手法として2本の論文が挙げられていましたので両方読んでみましたが、よりシンプルに高精度を実現している、「Unsupervised learning of object landmarks through conditional image generation」の方を解説してみます。
本手法の基本的な考え方は、「良いキーポイント(論文ではlandmarkと呼称)とは、画像中の物体が運動(人間だったら踊ったりすること)したときでも見つけることができるし、そのキーポイントの位置さえわかっていれば、だいたいその物体がどのように見えるかわかる」というものです。
この直観を上手に訓練するために何をしているのか、以下の図がわかりやすいのでこの図をもとに説明します。
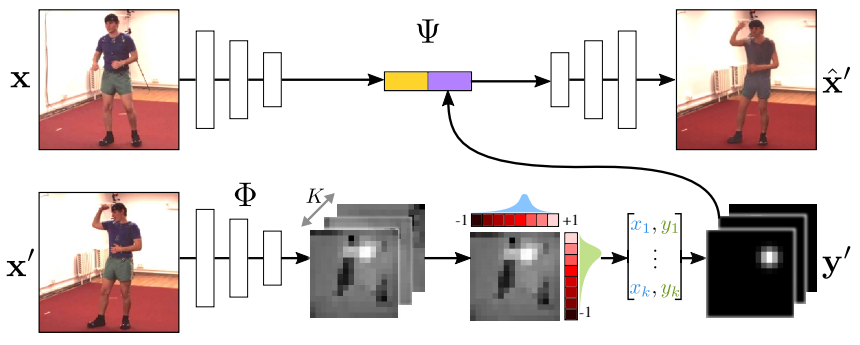
- まず、2枚の画像$\mathbf{x}, \mathbf{x'}$があります。便宜上、前者をソース画像、後者をターゲット画像と呼ぶことにします。
- ターゲット画像からは、キーポイントのヒートマップを抽出します。このヒートマップはいくつかの洗練工程を経た後に、位置が明確なヒートマップ$\mathbf{y'}$に変換されます。
- 一方で、ソース画像からは特徴マップが抽出されます。
- この特徴マップとヒートマップ$\mathbf{y'}$を結合し、Decodeすることで合成画像$\hat{\mathbf{x}}'$が得られます。
本手法の基本的な考え方から、最後に得られる合成画像$\hat{\mathbf{x}}'$が、できるだけターゲット画像$\mathbf{x}'$に似るようにしたいわけです。そういうわけで、ターゲット画像と合成画像の差異を損失として訓練できれば、キーポイント検出器が訓練できる、ということになりそうです。
基本的にはこれだけですが、もう少しだけ詳細に説明してきます。
書誌情報
- Jakab, Tomas, et al. "Unsupervised learning of object landmarks through conditional image generation." Advances in Neural Information Processing Systems. 2018.
- https://papers.nips.cc/paper/7657-unsupervised-learning-of-object-landmarks-through-conditional-image-generation.pdf
- 公式実装(Tensorflow):https://github.com/tomasjakab/imm/
ネットワークアーキテクチャ
訓練に使用するネットワークについて、一つずつ確認していきます。
キーポイント用特徴抽出
まずは画像から特徴マップを抽出するネットワーク$\mathbb{\Phi}$について説明します。
よくあるConvNetで、入力画像に対してConv層を適用し、適当なタイミングでチャネル数を増やしつつ、幅と高さは小さくしていく、というネットワークです。
$\mathbb{\Phi}$は、最初の7x7のConv層以外は、3x3のConv層2つからなるブロックから構成されます。
- 最初の7x7のConv層ではサイズの変更は行わず、チャネル数は32にします。
- 1つ目のブロックではサイズの変更は行わず、チャネル数は倍の64にします。
- 以降のブロックでは最初のConv層でstrideを2にすることでサイズを半分にし、チャネル数は倍にしていきます。
- 入力画像の解像度$2^n \times 2^n$に対して、ブロックは合計$n-3$個適用され、$16 \times 16 \times (32 \cdot 2^{n-3})$のサイズの特徴マップが得られます。
この$\mathbb{\Phi}$は、ターゲット画像側でもソース画像側でも使われます。
キーポイントの求め方
$\mathbb{\Phi}$によって抽出された特徴マップから、キーポイントのヒートマップ$\mathbf{y'}$を得ます。
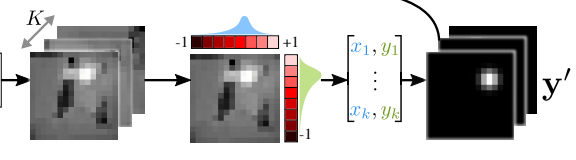
$\mathbb{\Phi}$によって抽出された特徴マップに対して1x1Conv層を適用することで、K枚のヒートマップを得ます。これらのヒートマップを各座標に対する重みと考えて、座標に関する重み付き平均を求めることで、K個の座標が得られます。
数式的には、座標$u$と各座標についてのヒートマップの重み$S_{u}(\mathbf{x} ; k)$と組わせて、以下のように表現されます。
$u_{k}^{*}(\mathbf{x})=\frac{\sum_{u \in \Omega} u e^{S_{u}(\mathbf{x} ; k)}}{\sum_{u \in \Omega} e^{S_{u}(\mathbf{x} ; k)}}$
この算出方法によって、キーポイントの座標を微分可能な形で得ることができます。なお、計算を簡略化するために、軸ごとに重み付き座標を求める方法が採用されています。下式の$i$がx軸とy軸に対応しています。
$u_{i k}^{*}(\mathbf{x})=\frac{\sum_{u_{i} \in \Omega_{i}} u_{i} e^{S_{u_{i}}(\mathbf{x} ; k)}}{\sum_{u_{i} \in \Omega_{i}} e^{S_{u_{i}}(\mathbf{x} ; k)}}, \quad S_{u_{i}}(\mathbf{x} ; k)=\sum_{u_{j} \in \Omega_{j}} S_{\left(u_{1}, u_{2}\right)}(\mathbf{x} ; k)$
以上からK個のキーポイント座標$u_{k}^{*}(\mathbf{x})=(x_k, y_k)$が得られます。この座標をもとに、少しぼかしたヒートマップ$\mathbf{y'}$が得られます。$\mathbf{y'}$の座標$u$における値は下式のようになります。
$\Phi_{u}(\mathbf{x} ; k)=\exp \left(-\frac{1}{2 \sigma^{2}}\left|u-u_{k}^{*}(\mathbf{x})\right|^{2}\right)$
最初に得られたヒートマップと最後に得られたヒートマップを比べると、キーポイントの位置が明確になっているという違いがあります。後者を使うことで、大幅な劣化を避けることができると論文中では記載されています。
合成ネットワーク
最後に、合成ネットワークについて見ていきます。
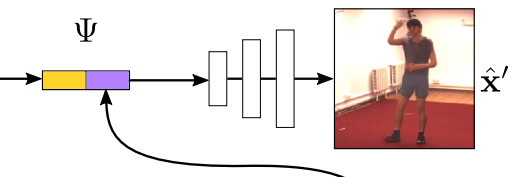
キーポイント用特徴抽出に使用した$\Phi$をソース画像に対して適用し、得られた特徴マップとヒートマップを結合し、Encoder的なネットワークへと入力します。
こちらも、2つの3x3Conv層からなるブロックをメインの構成要素としています。
- 最初のブロックはでは、256チャネルの出力にします。
- 以降のブロックは、出力が32チャンネルになるまで、出力チャネルは半分に減らされ続け、32チャネル以降は減りません。サイズは、bilinear interpolationによって2倍にし、合成画像のサイズと同じになるまでブロックは続きます。
- 最終層は、32チャネルを3チャネルにする3x3Conv層です。
こうして、ソース画像から得られた特徴とキーポイントの位置合成したRGB画像が得られます。
損失関数
本手法の損失関数は1つのみで、ターゲット画像と合成画像の差異を小さくする、というものだけで、以下のように表現されます。
$\mathcal{L}\left(\mathbf{x}^{\prime}, \hat{\mathbf{x}}^{\prime}\right)=\sum_{l} \alpha_{l}\left|\Gamma_{l}\left(\mathbf{x}^{\prime}\right)-\Gamma_{l}\left(\hat{\mathbf{x}}^{\prime}\right)\right|_{2}^{2}$
ここで、$\Gamma_{l}$は、事前学習済みのVGG-19の特定の層の出力を表します。具体的には、
- input
- conv1_2
- conv2_2
- conv3_2
- conv4_2
- conv5_2
の6つの層に対応しています。これらの層における出力を比べたときのL2距離をもとに、$\alpha_l$によって重みを調整された和が損失となります。参照されている論文2によると、$\alpha_l$は、各レイヤー$l$の要素数の逆数によって初期化され、100エポック目以降は各レイヤーでの損失の指数移動平均の逆数が適用されるようです。公式実装のissueを見ればわかりますが、初期値はハードコーディングされていて、各レイヤーごとの$\alpha_l$は、100エポック待たずに指数移動平均の逆数が適用されているようです。
なお、事前学習済みのVGGは、以下の2通りで作成されています。
- モノクロ画像のカラー化を訓練する
- ImageNetの分類モデルを訓練する
前者の場合は、完全な教師なし学習が実現できます。
以下のデータセットの例では、教師なしで得られたキーポイントをもとに補間されたラベルありのキーポイントに対する精度は、優劣がつけがたい結果となっています。selfsupと書いてあるのが、カラー化の訓練によって訓練されたVGGを使った場合です。

データセットの準備
細かい実験結果は示しませんが、訓練するにあたって、ソース画像とターゲット画像がどのように作られるのかを確認しましょう。

CelebAのような静止画像を用いた訓練では、ある特定の静止画に対してランダムなthin-plate-spline変換を施し、ソース画像とターゲット画像を作成します。このとき、画面外の領域が発生するので、この領域では損失が発生しないようにマスクする必要があります。
VoxCelebのような動画を用いた訓練では、もっとシンプルにソース画像とターゲット画像は、同一動画内の別々のフレームから作成します。
まとめ
教師なしでキーポイントを検出する手法について説明しました。教師なしで訓練されたキーポイントなので、当然一つ一つには明確な意味は特に無いわけですが、既存のキーポイントデータセットと組み合わせたり、冒頭に挙げた「First Order ~」のようなアニメーション化のタスクに使用できます。