概要
深層学習ベースの単眼深度推定モデルは、一体何を根拠に推定を行っているのかを実験的に調査した論文「How Do Neural Networks See Depth in Single Images?」を読んだので、解説してみます。
4つの深度推定モデルを比較し、いくつかの実験を行うことで、深度推定モデルがどのような根拠によって深度を求めているのかを特定しています。
比較している手法は、以下の4つです。とはいえ、これらの手法に大きな違いはなく、どれも似たような特性を示した、という実験結果が得られています。
- MonoDepth(Godard et al.)
- SfMLearner(Zhou et al.)
- SemoDepth(Kuznietsov et al.)
- LKVOLearner(Wang et al.)
結論としては、
- 画像における物体の垂直位置を根拠に推定している。
- 物体領域の下部が黒いと適切に推定できる。
ということのようです。
実験の流れ
実験を行いながら、徐々に仮説を立て、次の実験を計画し、また実験する、ということの繰り返しで考察を深めていきます。ざっと流れを要約すると、以下のようになっています。
-
実験1:物体の画像中における位置やサイズは推定結果にどのような影響を与えるかを確認する。
-
結果1:物体の位置によってのみ決まる。このことは、モデルがカメラの姿勢の知識を何らかの形で得ていることを暗示しているが、カメラの姿勢を入力画像から推定しているのか、モデル内部にコンスタントな形で埋め込まれているのかまではわからない。
-
実験2:入力画像の切り抜きによってカメラの姿勢を擬似的に変えたときに、カメラの姿勢に関わり深い要素である地平線を適切に推定できるかを確認する。
-
結果2:通常の入力画像では概ね推定できていた水平線が、擬似的にカメラピッチを変えたり回転させるとあまり認識できなくなる。このことから、入力画像を元にカメラの姿勢を得ているわけではなく、カメラの姿勢情報はコンスタントな形でモデルに埋め込まれている。
-
実験3:教師データに存在しない物体を画像に配置しても適切に深度を推定できるか。
-
結果3:できる。ただし、物体の下部が黒く、陰のようになっていることが求められる。
以降、各実験について、やや詳しめに説明します。
実験1:物体の位置とサイズ
人間は、様々な要素によって物体の深度、つまり三次元的な位置配置を認識していますが、KITTIデータセットのような限られたシチュエーションのデータセットでは、主に物体の位置と大きさがその手がかりとなります。
そこで、まずは、画像中に仮想的な物体を配置した合成画像を作成し、深度推定結果がどうなるかを確認します。
仮想的な物体は、具体的には下図の画面左側にある白い車で、仮想的な深度を変化させながら、画像中における位置と物体の見た目の大きさを変化させています。
最も自然な合成のケースは、Position and sizeで、遠くにあるかのような物体が、小さく見えるようになっています。Position onlyの場合は、物体の見た目の大きさはそのままに遠くにあるかのように配置しています。また、Size onlyでは、見た目のみを、遠くにあるかのように小さくしています。
数式的には、以下の2つの式によって、SizeやPositionを変化させます。擬似的な深度$Z'$を変化させながら、Size onlyはSizeの式のみを適用し、Position onlyはPositionの式のみを適用しています。
Size: $s=\frac{Z}{Z^{\prime}}$
Position: $x^{\prime}=x \frac{Z}{Z^{\prime}}, \quad y^{\prime}=y_{h}+\left(y-y_{h}\right) \frac{Z}{Z^{\prime}}$
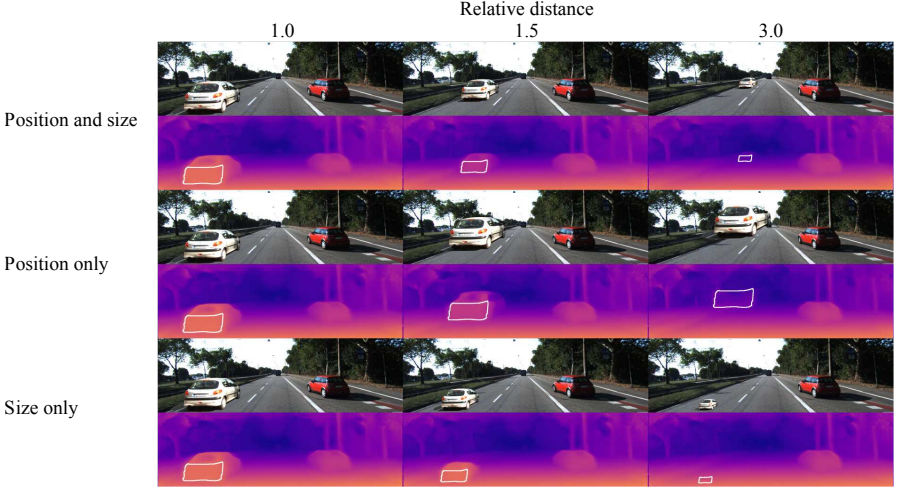
深度推定の結果は以下のようになっています。
横軸がPositionやSizeをいじるときに使用する相対深度($\frac{Z'}{Z}$)、縦軸が推定された相対深度を表しています。
黄色い線はSize onlyの結果ですが、見た目が変化しても、位置が変わらないのであれば、推定深度が一定であるということを示しています。また、赤い線はPosition onlyの結果ですが、青い線のPosition & sizeと似たような推定結果になっています。
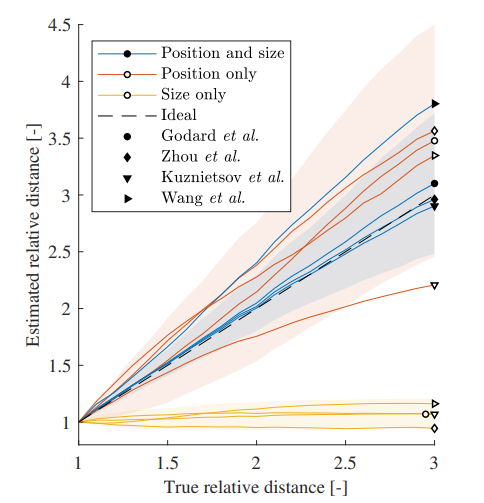
以上のことから、先に示した合成画像について、
- 中段右は、白い車はすごく近くにあるが、道路が変形したりしているために、上の方にある。
- 下段右は、白い車はすごく遠くにあるが、道路が変形したりしているために、下の方にある。
というふうにではなく、
- 中段右は、すごく大きい車が遠くにある
- 下段右は、車道をミニカーが走っている
というふうに深度推定モデルには見えている、ということがわかりました。
要するに、深度推定モデルは、見た目や大きさは考慮せずに、位置によって深度を推定している、と言えます。
実験2:カメラの姿勢
物体の深度が物体の位置から推定されているということは、深度推定モデルは、何らかの形でカメラの姿勢に関する知識を得ていることを意味します。それが、入力された画像をもとに推定しているのか、それとも、モデルの中に暗黙的に組み込まれているコンスタントなものなのか、ということが問題となります。後者の場合は、学習済み深度推定モデルをそのまま別のシチュエーション(例えば、車が大きく、カメラ位置が高いといった場合)に転用できない可能性があります。
ここでは、カメラの姿勢と関わり深い要素である地平線の高さを、深度推定モデルによって推定可能かを実験しています。
実験2-1:地平線の高さの推定
予備的な実験として、推定された深度をもとに道路の地平線の高さを求めることができるかを確認します。論文では、一例としてMonoDepthを用いて実験しています。
手順としては、入力された画像に対して深度推定を行い、画面中央の道路表面の領域からサンプルして、画像の垂直位置$y$から視差$disparity$を求める簡単なモデルをRANSACによって構築します。このとき、視差が0となる、つまり深度が無限大となる$y$を外挿し、これを地平線の高さとします。
KITTIデータセットでは、真の地平線の高さが得られるようなので、このように推定された地平線の高さと比較すると、相関係数0.60とそれなりに推定できているということがわかります(図では相関係数は0.50になっていますが、論文中では0.60とされています)。
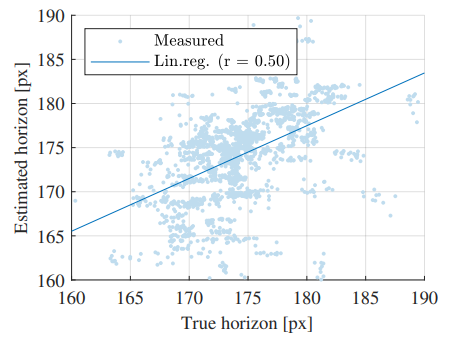
この実験から、深度推定モデルを用いて、地平線の高さの推定ができるということがわかりました。
実験2-2:カメラピッチの擬似的な変化
もしもカメラの姿勢が入力画像を元に推定されているのだとすると、入力画像の上下を切り抜くことは、カメラのピッチを擬似的に変化させたことに対応します。これによって、当然地平線の高さは変化します。
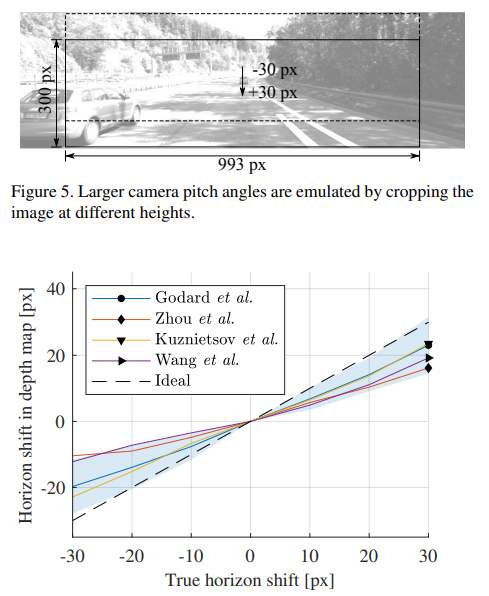
上図の上段の画像のように切り抜きを行うと、推定される地平線の高さは、切り抜いたときの位置と同じだけ変化するはずです。しかし、上図の下の実験結果のグラフを見ると、切り抜いた入力画像から得られる地平線の高さの変化は、理論値よりも小さいということがわかります。つまり、画像の切り抜き位置が変わると、深度推定モデルは地平線の高さを適切に推定できない、ということがわかります。
同様に、得られるdisparityの変化を確認すると、下図のようになります。切り抜きによって単に垂直位置が変わっただけで視差が変わってしまうということは、深度推定モデルが、画像中のy座標によってのみdisparity、すなわち深度を推定しているということを意味しています。
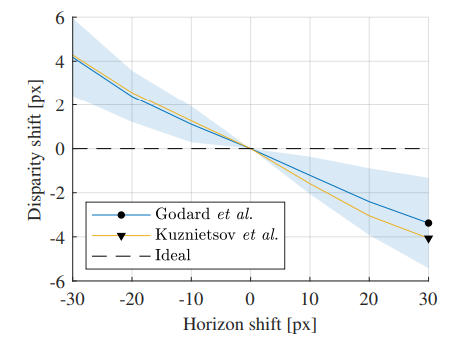
以上から、深度推定モデルは、入力画像からカメラの姿勢を推定しているのではなく、コンスタントな値として持っている、少なくともその影響のほうが大きい、ということがわかります。また、物体の画像中におけるy座標のみが重要であるという結論が得られます。
実験2-2:カメラの擬似的な回転
さらに、画像を以下のように切り抜くことで、カメラを擬似的に回転させてみたとき、地平線もそれに追従して回転するのかを確認します。地平線の傾きは、推定された深度マップに対してハフ変換を適用して直線検出を行い、計算しています。
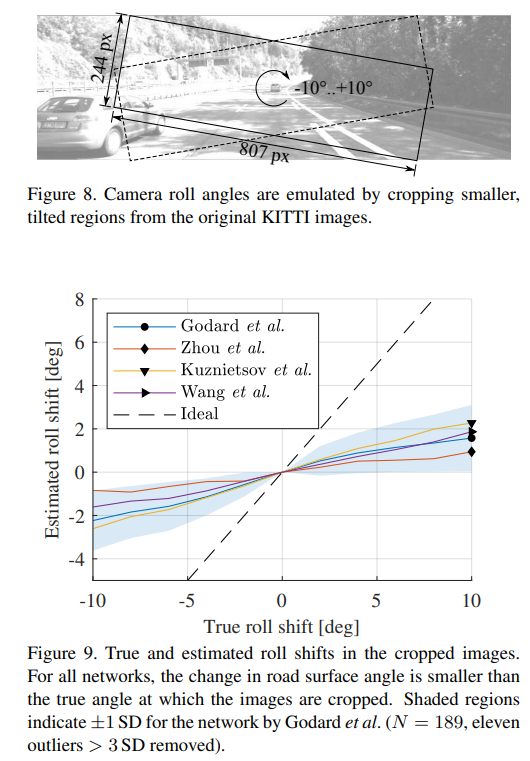
結果としては、傾いていることは認識できているが、傾きの大きさは過小評価されるということがわかります。
この結果も、深度推定モデルが、地平線を認識できない、つまり入力画像からカメラの姿勢を推定できているわけではないという結論を支持しています。
実験3:物体クラスに基づく認識
ここまでの実験から、物体の画像中における垂直位置のみが深度推定に使われていて、カメラの姿勢に関する情報はモデルの中に暗黙的に埋め込まれている、ということがわかりました。
では、物体の内部、つまり色やテクスチャといった要素は深度推定結果にどのような結果を与えるのでしょうか。
以降は、MonoDepthに対して実験を進めていきます。
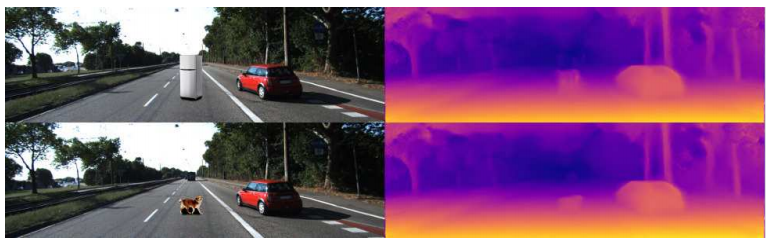
興味深い例を先に示しておきます。下図のように、既存の画像に車や冷蔵庫、犬といった物体を合成した画像を作成します。これらに対する深度推定結果は、下図の右のようになっています。車は適切に深度を推定できていますが、冷蔵庫、犬といった物体は、適切に深度を推定できていません。このことから、KITTIデータセットに含まれていない物体クラスは、適切に深度を推定できない、という仮説が得られます。

一方で、以下のように、車を三角に切り抜いた物体を貼り付けた合成画像であっても、深度マップはその形状にあった形で出力されます。
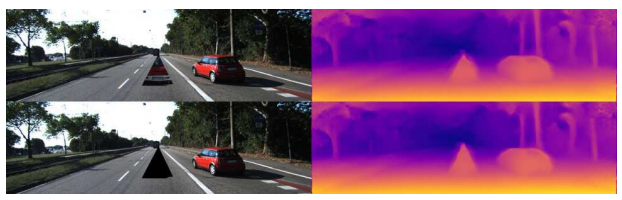
もはや車とは言えないほど変形された物体でも、深度が適切に推定できるということは、先程の仮説と相容れない結果のように考えられます。この原因を実験によって調べていきます。
実験3-1:色とテクスチャ
以下に、色やテクスチャの変化が、深度推定に与える影響を示しています。
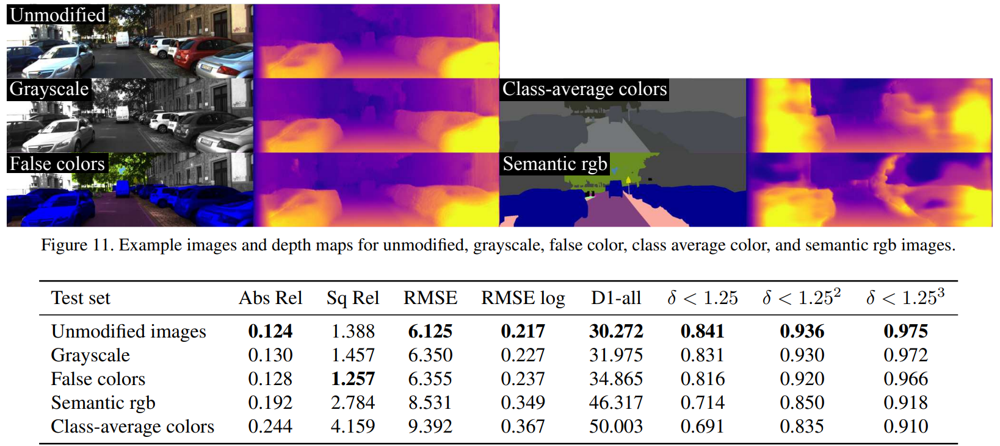
この結果から、色は深度推定結果にほとんど影響を与えていないということがわかります。一方で、物体内部の細かいテクスチャが失われると深度推定結果が崩れるということがわかります。
実験3-2:形状とコントラスト
物体のテクスチャが重要だということはわかりましたが、具体的にはどのような領域のどのようなテクスチャが重要なのでしょうか。
これを調べるために、ややトリッキーな実験を行ってみます。
以下の図に示す通り、合成画像に貼り付ける車の一部を欠損させ(欠損部分は透明になります)、深度推定結果がどのように変化するのかを確認します。
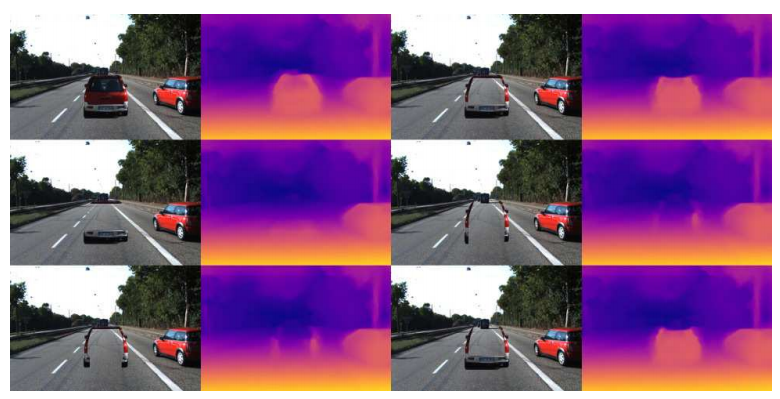
上段右や下段右の結果は、車の内部が欠損しているというケースですが、車の内部が道路表面の見た目になっているのにも関わらず、いずれも元の結果(上段左)から変化が少ないということがわかります。
一方で、下段左や中段右のようなケースでは、車の内部の深度推定結果は道路表面の推定結果に近づいています。
これらの入力画像の違いを見ると、車の下部(道路に接している部分)が欠損していないかしているかの違いであるということがわかります。このことから、地面に接している部位が、深度推定の手がかりになっているのではないかという仮説が立てられます。そして、地面に接している部位と、道路ではない領域によって囲まれた領域が、深度推定の領域として出力されているのだ、ということがわかります。
次に、地面に接している部位に求められる特性を調べます。
まず、地面に接している部位と車の内部が欠損しているアーチ状の物体を合成画像に配置します。そして、地面に接している部分から徐々に特定の模様や色で埋めていったときに、深度推定結果がどのように変化するのかを確認します。
車の内部を埋める模様や色は、特定の色で埋める(下図の上から3段)、元のテクスチャ通りに埋める(下図の最下段)で比較しています。また、どれだけ埋めたかは、埋める領域の高さ(ピクセル数)によって表現できます。下図の左から右に行くほど、埋める領域は大きくなっています。

以下が実験の結果です。横軸が埋める領域の大きさ(ピクセル数)で、縦軸が埋める色(0が黒、1が白)です。また、特殊なケースとして、完全に埋める場合(F)と元のテクスチャで埋める場合(Tex)が示されています。白い色のマスほど、深度推定結果が完全な状態との差が少ない、ということを示しています。当然、元のテクスチャで完全に埋める一番右下のマスは、誤差0です。
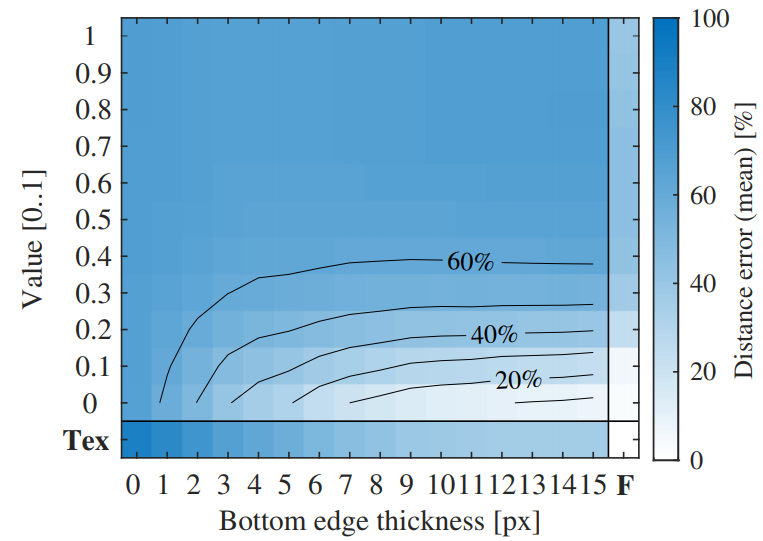
ここから、埋める色は黒がよく、13ピクセル程度あれば、元の推定結果と同じになる、ということがわかります。一方で埋める色が白くなればなるほど、深度推定結果が崩れます。それどころか、真っ黒で埋めたほうが、元のテクスチャで埋めるよりも良い結果が得られていることがわかります。
以上から、深度推定には、地面と接している部分の黒い領域が最も認識に必要であるということがわかりました。
この特性を利用すると、最初に示した犬や冷蔵庫にも、物体下部に黒い領域を足してあげることで深度が適切に推定できます。冷蔵庫は上の引き出し部分が欠けていますが、これは「白」が苦手であるという先程の実験結果から説明できます。
まとめ
深度推定モデルが一体何を根拠に深度を求めているのか、ということを検証した論文について紹介しました。
道路に面している物体下部の暗さが重要、という結論は、屋外道路で太陽光が降り注ぐKITTIデータセットから学習されたモデルでは自然な結論のように思います。
一方で、このような特性を元にした例外的な状況の洗い出しによる、より汎用的なデータセットの構築や、既存モデルに対する攻撃手法なども編み出せそうです。
書誌情報
- Dijk, Tom van, and Guido de Croon. "How Do Neural Networks See Depth in Single Images?." Proceedings of the IEEE International Conference on Computer Vision. 2019.
- ICCV2019のページ