概要

本当の意味での教師なしImage2Imageのモデルを提案している論文"Rethinking the Truly Unsupervised Image-to-Image Translation"を読んだので簡単に紹介します。
Image2Imageは、pix2pix1に代表されるような画像のドメインを変換するモデルです。今回提案されているモデルであるTUNIT(truly unsupervised image-to-image translation)は「本当の意味で」教師なしの画像変換モデルであると主張しています。
下図は本手法が想定するデータセットの状況を示したものです。(a)は変換元と変換先の画像が完全に用意されている教師ありのデータセットを表しています。(b)は、変換先の画像が用意されているわけではありませんが、少なくとも各画像がどのようなドメインに属しているのかがわかっている状況を表しています。このような状況で別ドメインへの画像変換を実現できる手法として、例えばFUNIT2が挙げられます。(c)が本手法が想定するデータセットで、いかなるレベルでの教師信号も存在しないという状況です。ここで挙げられている顔画像の場合は、どのような基準でドメインを分けるのかを決めるのが困難ですし、画像が大量にあればアノテーション作業自体も困難です。

以下、このような問題設定でどのような手法が提案されているのかを見ていきます。
書誌情報
- Baek, Kyungjune, et al. "Rethinking the Truly Unsupervised Image-to-Image Translation." arXiv preprint arXiv:2006.06500 (2020).
- https://arxiv.org/abs/2006.06500
- 公式実装(PyTorch)
FUNITとの比較
本手法の新規性の話に入る前に、既存手法であるFUNITとの比較を簡単に行います。
本手法を構成しているのは3つのモジュールです。1つ目が(Style)Encoderで、変換先のドメインを表すReference画像からStyle codeを抽出します。残りの2つは、Source画像とEncoderによって抽出されたStyle codeを元に画像変換を行うGenerator、Generatorによって生成された画像の真偽を判定するDiscriminatorです。Discriminatorは、MultiTaskDiscriminatorになっており、与えらえた画像が特定のドメインの画像として真であるか偽であるかを判定します。
このような構成は、論文で比較されている手法であるFUNITと同じ構成になっています。違いは、変換先のドメインを指定するReference画像に対して、そのドメインが何であるかを示すラベルの有無のみです。
これを踏まえて、3つのモジュールがどのように訓練されるのかを表した下図を見ていきます。
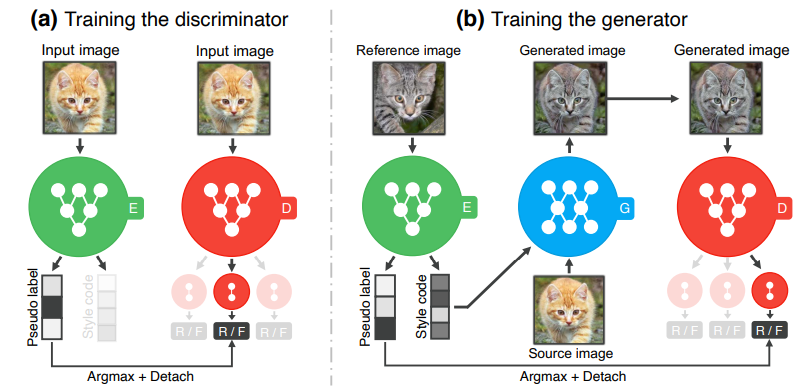
まず、Encoderは、2つのブランチに分かれており、Pseudo labelとStyle codeを出力しています。Style CodeがGeneratorに使われる一方で、Pseudo labelは、MultiTaskDiscriminatorに使われていることがわかります。FUNITではドメインに関する情報がわかっているので、そのクラス数は固定ですが、TUNITにおけるクラス数$K$は疑似的なものであり、ハイパーパラメータです。
FUNITとのネットワーク構造の違いは、以下の2点です。
- EncoderにPseudo labelを出力するブランチであるguiding networkが付いていること
- MultiTaskDiscriminatorに与えられるクラスは真のドメインについてのラベルではなく、Pseudo labelであること
そのため、本手法ではいかにしてEncoderを訓練するのか、ということが関心の中心になります。
Encoderの訓練
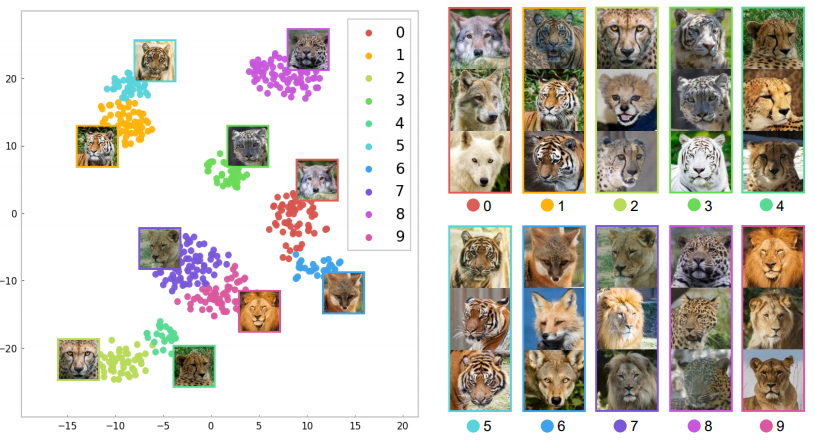
Encoderは、うまく訓練できればドメインごとに似通ったStyle codeが得られるようになります。以下はその様子を表した図で、Style codeに対してT-SNEを施した時に各疑似ラベルごとにどのような画像が存在しているのかを表しています。同一のカテゴリの画像が別の疑似ラベルに割り振られることもありますが、おおむねカテゴリと疑似ラベルは一致していることがわかります。
このような良いEncoderを構築するために、2つの損失関数を組み合わせて訓練します。一つはIICと呼ばれる表現学習手法、もう一つはContrastive Lossです。それぞれについてどのようなものなのかを確認していきます。
IIC(Invariant Information Clustering)
IIC3は、相互情報量を利用した表現学習手法です。以下はIICの論文の図を引用したものです。TUNITの文脈では、Optional overclusteringの部分は無関係なので無視してください。
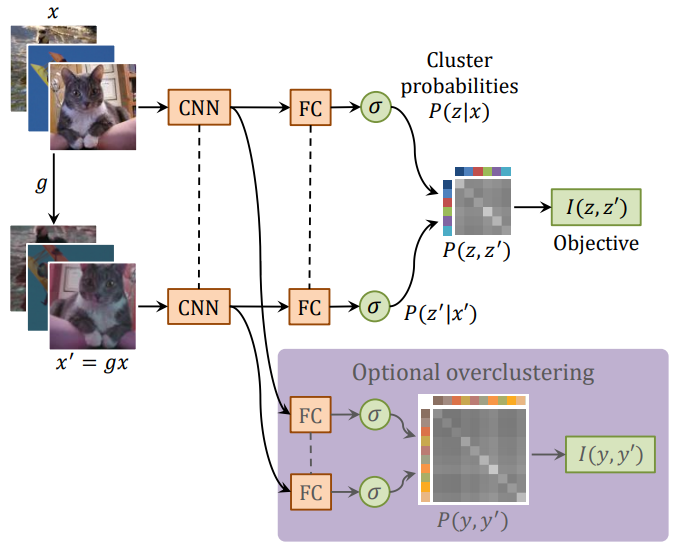
入力画像$x$に対して、簡単なデータ拡張$g$(水平フリップ、ランダムクロップなど)を加えた画像$x'$を用意し、それぞれを同じCNN+FC層であるネットワーク$\Phi$に通すことで、クラスタへの所属確率を推定します。$x, x'$は同一のカテゴリの物体が映っていることは明らかなので、それぞれから得られる確率分布ができるだけ同じになるように$\Phi$を訓練します。
これは、二つの分布の相互情報量の最大化することで実現できます。相互情報量は、具体的には二つの確率分布の同時確率を表す行列$\mathbf{P}$を用いて、以下のように表現されます。
I\left(z, z^{\prime}\right)=I(\mathbf{P})=\sum_{c=1}^{C} \sum_{c^{\prime}=1}^{C} \mathbf{P}_{c c^{\prime}} \cdot \ln \frac{\mathbf{P}_{c c^{\prime}}}{\mathbf{P}_{c} \cdot \mathbf{P}_{c^{\prime}}}
なお、$\mathbf{P}$は、以下のように二つの確率分布をもとに計算されたのち、対称性を持たせるために$\mathbf{P} \leftarrow \left(\mathbf{P}+\mathbf{P}^{\top}\right) / 2$と変換されます。また、$\mathbf{P}_{c},\mathbf{P}_{c^{\prime}}$は、それぞれ$\mathbf{P}$の$c$行目のベクトル、$c'$列目のベクトルを表します。
\mathbf{P}=\frac{1}{n} \sum_{i=1}^{n} \Phi\left(\mathbf{x}_{i}\right) \cdot \Phi\left(\mathbf{x}_{i}^{\prime}\right)^{\top}
以上がIICそのものの説明です。
少し表記は変わりますが、TUNITの文脈に戻すと、IICのための損失関数は以下のように表現されます。実際には、相互情報量は最大化の対象ですので、これにマイナスの係数が付きます。ここで、$\mathbf{p}, \mathbf{p}^{+}$はそれぞれSource画像とそれに単純なデータ拡張を加えた画像からguiding networkを通じて得られる確率分布を表します。また、$\mathbf{P}$は先ほどと同様に、これら二つの分布の同時確率を表す行列です。
\mathcal{L}_{M I}=I\left(\mathbf{p}, \mathbf{p}^{+}\right)=I(\mathbf{P})=\sum_{i=1}^{K} \sum_{j=1}^{K} \mathbf{P}_{i j} \ln \frac{\mathbf{P}_{i j}}{\mathbf{P}_{i} \mathbf{P}_{j}}
Contrastive Loss
IICは低解像度の画像ではうまく働きますが、高解像度の画像ではうまくいかないということが知られているそうです。そこで本手法では、Pseudo labelに対するIICに加えて、Style codeに対するContrastive損失を利用した損失関数も加えることで、よりよい表現学習が実現できるように工夫しています。
Source画像$x$とそれに対して異なるデータ拡張を施した画像$x^+$、Source画像とは異なる画像$x^-$という3つ組を考えます。ここで、対応するStyle code$(\mathbf{s}, \mathbf{s}^{+}, \mathbf{s}^{-})$を用いて、以下のような損失を考えます。これは、$\mathbf{s}$をquery、$\mathbf{s}^{+}, \mathbf{s}^{-}_i(i=1, 2, ..., N)$をkeyとしたときに、与えられたqueryに対応するkeyを見つける$N+1$クラス分類問題を解けるようにしたい、という損失関数になっています。$\tau$は温度パラメータです。
\mathcal{L}_{\text {style }}^{E}=-\log \frac{\exp \left(\mathbf{s} \cdot \mathbf{s}^{+} / \tau\right)}{\sum_{i=0}^{N} \exp \left(\mathbf{s} \cdot \mathbf{s}_{i}^{-} / \tau\right)}
TUNITでは、MoCo4と呼ばれるContrastive Lossのための枠組みを用いています。詳細については省略しますが、負例$\mathbf{s}^{-}_i(i=1, 2, ..., N)$はミニバッチごとに更新されるサイズ$N$のキューに収められており、このすべてを負例のkeyとして使用します。ミニバッチごとにキューには新しいkeyが加えられ、古いkeyから捨てられます。
その他の損失関数
メインのEncoderについての説明は終わったので、残りは簡単に見ていきましょう。
以下はDiscriminator, Generator, Encoderの損失関数です。
\begin{array}{l} \mathcal{L}_{D}=-\mathcal{L}_{a d v} \\ \mathcal{L}_{G}=\mathcal{L}_{a d v}+\lambda_{s t y l e}^{G} \mathcal{L}_{s t y l e}^{G}+\lambda_{r e c} \mathcal{L}_{r e c} \\ \mathcal{L}_{E}=\mathcal{L}_{G}-\lambda_{M I} \mathcal{L}_{M I}+\lambda_{s t y l e}^{E} \mathcal{L}_{s t y l e}^{E} \end{array}
$\mathcal{L}_{a d v}$は一般的なGANにおける敵対的損失です。
\begin{aligned} \mathcal{L}_{a d v} &=\mathbb{E}_{\mathbf{x} \sim p_{\text {data}}(\mathbf{x})}\left[\log D_{y}(\mathbf{x})\right] + \mathbb{E}_{\mathbf{x}, \widetilde{\mathbf{x}} \sim p_{\text {data}}(\mathbf{x})}\left[\log \left(1-D_{\tilde{y}}(G(\mathbf{x}, \widetilde{\mathbf{s}}))\right)\right] \end{aligned}
$\mathcal{L}_{s t y l e}^{G}$は、合成画像$G(\mathbf{x}, \widetilde{\mathbf{s}})$から得られるStyle code$\mathbf{s^{\prime}}$に対するContrastive損失です。
\mathcal{L}_{\text {style}}^{G}=\mathbb{E}_{\mathbf{x}, \widetilde{\mathbf{x}} \sim p_{\text {data}}(\mathbf{x})}\left[-\log \frac{\exp \left(\mathbf{s}^{\prime} \cdot \widetilde{\mathbf{s}}\right)}{\sum_{i=0}^{N} \exp \left(\mathbf{s}^{\prime} \cdot \mathbf{s}_{i}^{-} / \tau\right)}\right]
$\mathcal{L}_{r e c}$は再構成損失です。Source画像とReference画像が同一の時に、出力画像も同一になる、という損失です。
\mathcal{L}_{r e c}=\mathbb{E}_{\mathbf{x} \sim p_{d a t a}(\mathbf{x})}\left[\|\mathbf{x}-G(\mathbf{x}, \mathbf{s})\|_{1}\right]
Joint Training
上記の損失関数をよく見てみると、Encoderの損失関数$\mathcal{L}_{E}$の中にGeneratorの損失関数$\mathcal{L}_{G}$が丸々含まれています。
\mathcal{L}_{E}=\mathcal{L}_{G}-\lambda_{M I} \mathcal{L}_{M I}+\lambda_{s t y l e}^{E} \mathcal{L}_{s t y l e}^{E}
IICとContrastive損失によって強力な表現学習ができるので、Encoderは$\mathcal{L}_{G}$なしでも訓練することもできますが、$\mathcal{L}_{G}$ありの場合のほうが良い結果になるようです。
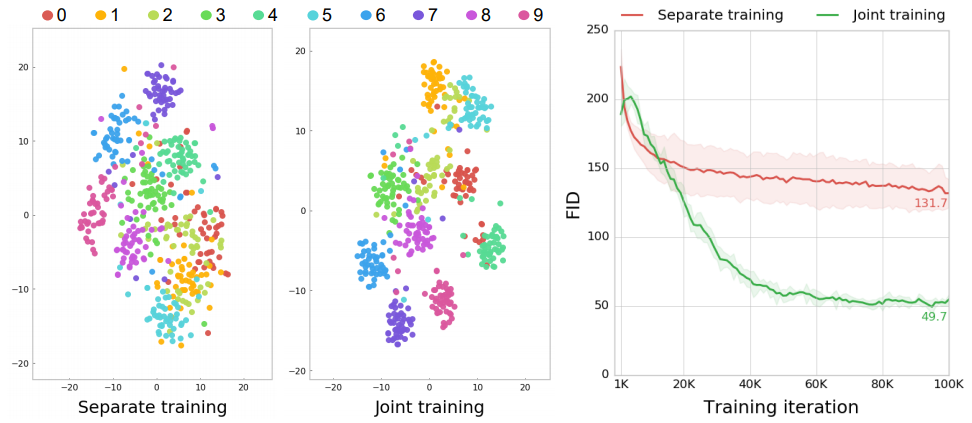
以下に示すのはAnimalFaces-10データセットで$\mathcal{L}_{G}$を$\mathcal{L}_{E}$に入れた場合と入れなかった場合で比較したものです。$\mathcal{L}_{G}$なしでの訓練をSeparate training、$\mathcal{L}_{G}$ありでの訓練をJoint trainingとしています。ここで、左の散布図は真のドメインで色分けしたStyle codeのT-SNEの結果です。Joint trainingのほうがドメインごとに分離できるようなStyle codeを獲得できていますし、右側のグラフから明らかなように生成画像自体の質も良くなっているということがわかります。
まとめ
簡単にですが、ドメインレベルの知識すら必要ないTUNITについて紹介しました。
IICやContrastive Lossまわりの手法について詳しくは知らなかったので、良い勉強になりました。特にMoCoについては近いうちにQiitaにまとめるのもいいなと思いました。
-
Isola, Phillip, et al. "Image-to-image translation with conditional adversarial networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. ↩
-
Liu, Ming-Yu, et al. "Few-shot unsupervised image-to-image translation." Proceedings of the IEEE International Conference on Computer Vision. 2019. ↩
-
Ji, Xu, João F. Henriques, and Andrea Vedaldi. "Invariant information clustering for unsupervised image classification and segmentation." Proceedings of the IEEE International Conference on Computer Vision. 2019. ↩
-
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. ↩