概要
Weakly Supervised Object Localizationのための、訓練パラメータの存在しないADL(Attention-based Dropout Layer)を提案。分類精度は低下するものの、CUB-200-2011データセットのローカライゼーションタスクにおいてSOTAを達成。
下の画像は、CAMによるローカライゼーションの場合と、提案手法であるADLによるローカライゼーションの比較。CAMでは物体の一部の領域でしか反応していない一方で、ADLでは物体領域を満遍なく覆うように反応できていることがわかる。

注意:この文書はざっくりとしたメモです。細かい内容に関しては元論文や他の解説記事に当たってください。
リンク
手法
モデル訓練時のみに適用するADLを提案している。ADLの仕組みを下図に示す。
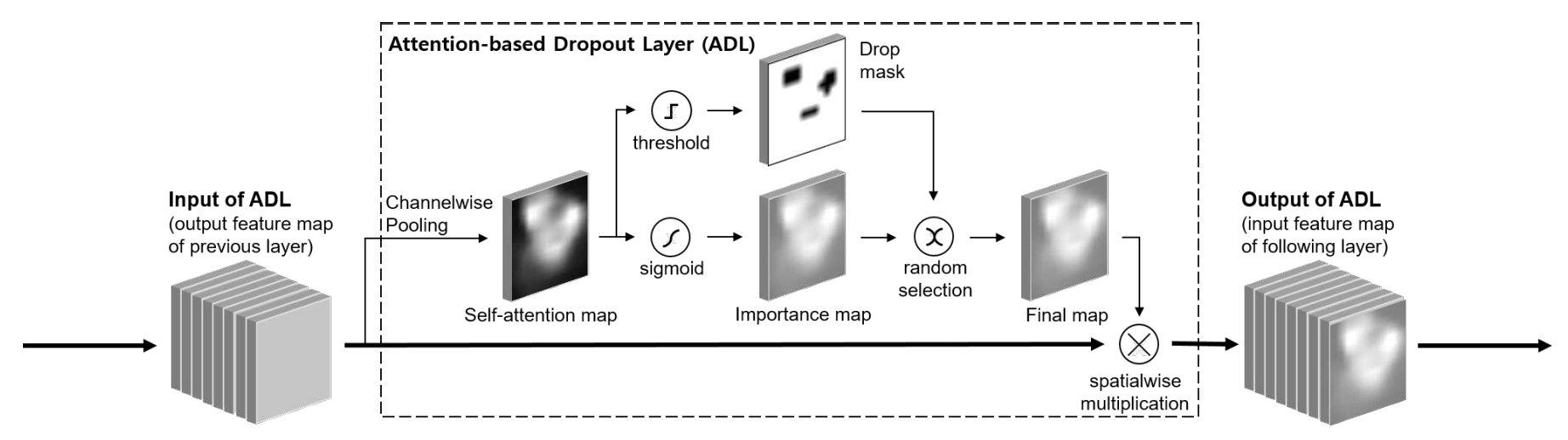
- FeatureMapからAttentionMapを生成する。
- 以下の2種類の処理をランダムに選択し、FinalMapを得る。
- AttentionMapにSigmoid活性化を適用して得られるImportanceMap
- AttentionMapに閾値$\gamma$を適用して得られるDropMask
- FinalMapをFeatureMapに掛け合わせ、出力を得る。
ADLは様々なベースネットワークの、様々な段階に対して適用できる。
以下、AttentionMapの算出と、FinalMapの算出と適用について、詳細を説明する。
AttentionMapの算出
FeatureMapからAttention Mapを算出する。
関連手法として挙げられているBAM(Bottleneck Attention Module)やCBAM(Convolutional Block Attention Module)では、追加のConv層を通すことで、AttentionMapを得ている。
一方で、本手法ではAttentionMapの算出に追加のConv層を必要とせず、チャネル方向のAveragePoolingによって実現している。これにより、追加の訓練パラメータを必要とせずにAttentionMapを算出している点が本手法の大きな特徴である。
FinalMapの算出とその適用
Self-Attentionによって得られたAttentionMapは、FeatureMapに対して適用する空間的な重み付けであり、その重みが大きい領域ほど、分類に重要な特徴含まれると言える。
ここから、AttentionMapの2方向の活用方法を考えることができる。
- ImportanceMap: AttentionMapに素直に従い、FeatureMapに対して重みつけを行う。分類に有用な特徴を強調する、という考え方。
- DropMask: AttentionMapで強く反応している部分の特徴を隠したマスクを作成し、FeatureMapに対して重み付けを行う。分類に有用な部分をあえて隠し、それでも分類可能になるように訓練する、という考え方。
Object Localizationのタスクとして重要なのは、後者のDropMaskの方である。これによって、一部の領域だけにAttentionが集中することを避け、物体領域の広範囲にAttentionが及ぶことを促進することができる。
もちろん、後者ばかりを適用してしまうと分類に有用な特徴を訓練できなくなってしまうため、2つの活用方法を一定の確率でランダムに切り替えながら訓練する。
下図は、VGG-GAPをベースとする訓練済みモデルの各段階で算出されるAttentionMapとそれに対応するDropMaskを示している。

ハイパーパラメータ
ADLには、ハイパーパラメータは2つしかない。
1つ目は、ImportanceMapとDropMaskのどちらを適用するのかをランダムに選択する確率(drop_rate)。2つ目は、DropMaskを作成するさいにAttentionMapに対して適用する閾値($\gamma$)である。
後者の閾値は、公式実装を確認すると、AttentionMapの最大値に対する割合を指定する形になっている。
drop_rateは75%で固定されている。$\gamma$はベースネットワークに応じて異なっており、80%〜95%が使われている。
Localization
最終的なLocalizationはCAMの枠組みで行なっている。
ベースネットワークの各段階で得られるAttentionMapを使っているわけではないことに注意。
実験
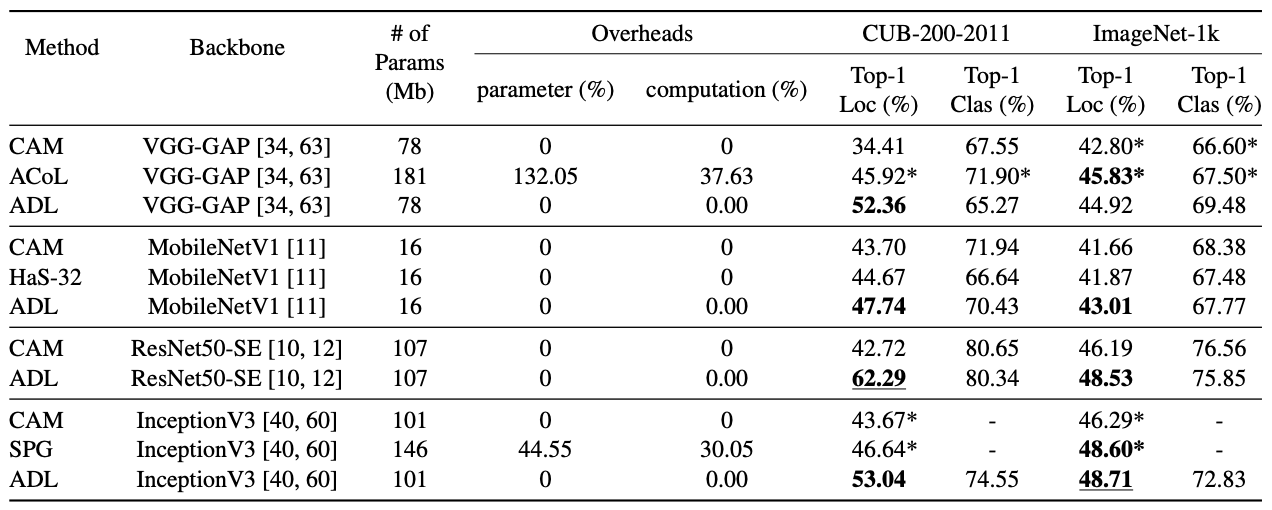
既存手法との比較の表を示す。データセットはCUB-200-2011およびImageNet-1kの場合で比較している。
計算時間はCAMからほとんど増加していない(0.00%!)にも関わらず、高いLocalization精度が得られていることがわかる。一方で、分類精度はCAMなどから低下している場合もあることが確認できる。
議論
Localizationに失敗している例として、以下の画像が示されている。これは、snowmobileにたいするLocalizationの結果である。
CAMは人間にもAttentionが出ており、ADLは人間にはAttentionが出ていない、という点では良いが、ADLはsnowやtreeに相当する部分にもAttentionが及んでおり、適切なLocalizationとは言えない。このような、物体の外部に生じてしまうAttentionへの対処が、今後の課題である。

感想
Weakly Supervised Object Localizationの手法として、とてもシンプルな手法だと思った。訓練に追加のパラメータが不要という点が非常に良い。一方で、AttentionMapが1枚しかないというのは少々心許ない。分類精度の低下への対策として、Attentionをマルチヘッド化する方向性が良いのではないかと思う。
また、物体の外部にAttentionが及んでしまうという現象は、原理的には避けがたいように思える。Convolutionが、「周辺の特徴を集めてきて新しい特徴にする」という操作である以上、「右側にsnowmobileがあることを表現する特徴」すら訓練されてしまう可能性があるためである。
このような問題に対処するには、入力画像の時点でsnowmobileに対応する部分を削除するしか対策がないのではないか、と考えるのだが、どうなのだろうか。