注意:この文書は荒いメモなので、細かい内容に関してはご自身で元論文に当たってください。
概要
物体追跡(Object Tracking)のSiamese Networkベースの手法であるSiamMaskを提案。
単に物体を追跡するだけでは無く、セグメンテーションも同時に実現している。
物体のクラスは不問で、最初のフレームに追跡対象を囲むバウンディングボックスを指定するだけで、以降のフレームは自動的にセグメンテーションしつつトラッキングしてくれる。
精度はSotaに劣るものの、速度は35fps@Titan X GPUと、リアルタイムと呼べる速度が達成されている。
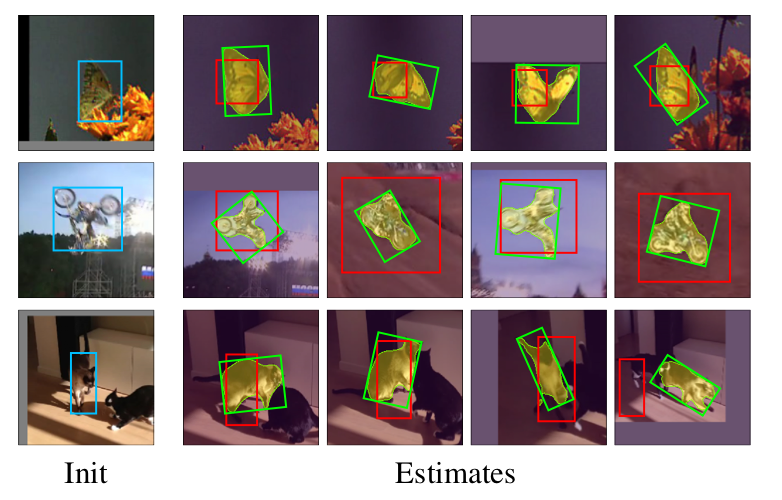
公式ページに動画がある。
手法
既存の手法として、SiamFCとSiamRPNがある。これらの2つの手法はいずれも高速なトラッキング手法であるが、本手法は、これにマスク画像生成のブランチを追加している。
Siameseアプローチとは
Siameseアプローチとは、物体トラッキングにおいてよく用いられるアーキテクチャである。追跡対象の物体を表す局所画像(Exemplar)と探索対象画像(Search Image)を同一のネットワークに通し、それぞれの特徴量マップを得る。その後、Exemplarの特徴量マップをカーネルとした2次元畳み込みを、Search Imageの特徴量マップに対して行う。これによって、Exemplarの特徴量に近いSearch Imageの位置が特定できる、というわけである。この操作は、2つの特徴量マップのCross Correlation(相互相関)を求めることに対応する。
この操作によって、Exemplarに近い特徴をもつ位置が強く反応するヒートマップが得られる。

Siameseアプローチは、物体のクラスによらない一般的な物体追跡のための特徴量マップを得るための方法を学習することから、一種のメタ学習と捉えることもあるようだ。
Siamese FCとSiamese RPN
2つの既存手法について説明する。FCの方は、単純に相互相関を求めて、最も相関が強い位置に物体があると考えるものである。

RPNの方は、Faster R-CNNでおなじみの、Region Proposal Networkを意味している。すなわち、いくつかの事前に定義されている各アンカーが物体を表しているか否かを分類するscoreブランチと、各アンカーの位置補正のための回帰モデルを担うboxブランチからなる。FCよりもRPNの方が、より正確なバウンディングボックスが得られる。

本手法と既存手法との差異
Siam Maskでは、大きく以下の2点で既存手法とは異なっている。
- Siam Maskにはマスク領域の推定ブランチが追加されていること
- Siam Maskでは、相互相関は各チャネルごとに計算されること(depth-wise cross-correlation)
マスク領域推定のブランチでは、最終的に$h \times w \times (63 * 63)$というマップを出力する。マスク領域に対応する1マスのみを取り出すと、その形状は$1 \times 1 \times (63 * 63)$となるが、チャネル方向の特徴を正方形に直して、$63 \times 63$のマスク画像が得られる。

また、より高精度なマスクの生成のための補正手法も記載されている(補正と言いつつ、実際には上記の$63 \times 63$のマスク画像は使用していないことに注意)。
これによって、$127 \times 127$のマスク画像を生成できる。

実験
物体追跡(Visual Object Tracking)と動画セグメンテーション(Video Object Segmentation)の2つの実験を行なっている。
物体追跡
ベンチマークデータセットVOT(2016と2018)を用いている。精度の指標として、AveragePrecision@IOUと、VOTで用いられる公式指標であるEAO/Accuracy/Robustnessが用いられている。
物体追跡手法としては、SiamFCとSiamRPNを大きく上回った精度を得ており、既存のトラッキング手法よりも良い精度が得られている。

動画セグメンテーション
ベンチマークデータセットDAVIS(2016, 2017)を用いている。精度指標として、JaccardIndex(マスク領域の類似度), F-measure(輪郭の精度)を用いている。
なお、データセット中には複数の物体が追跡対象の場合がある。その場合は、複数の物体に関してそれぞれ処理を行なっている。
以下にDAVIS 2017における既存手法との精度比較を示す。なお、下添字のMはMean、OはRecall、Dは時間経過に対する精度劣化を示すようだ。
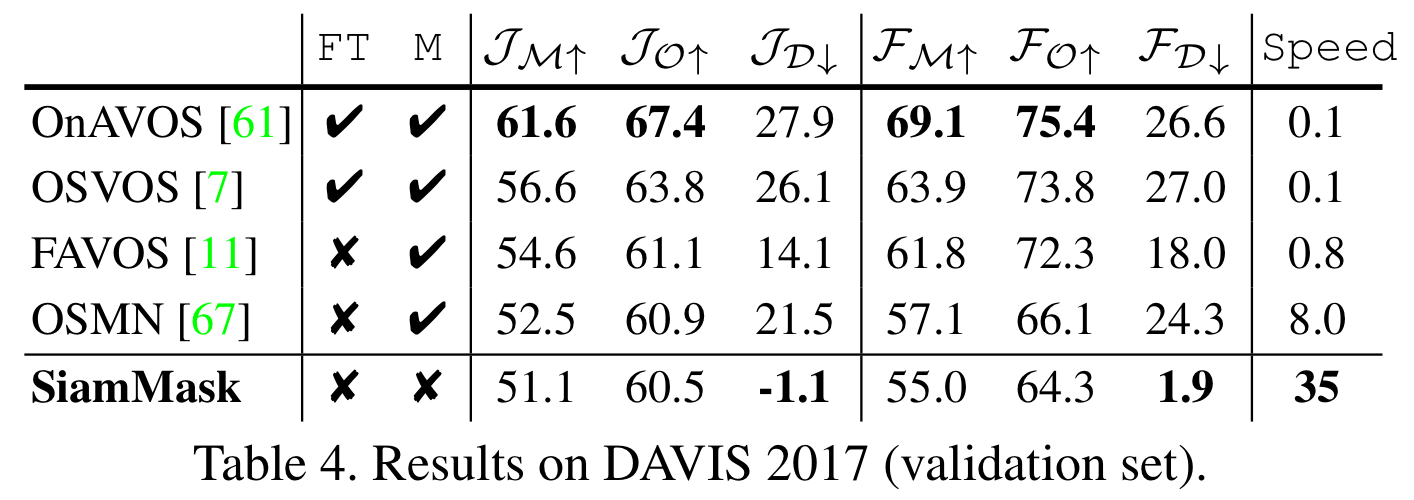
まず、既存手法処理も明らかに高速(35fps)であることが挙げられる。
次に、D関連の指標が極端に良いということが挙げられる。Dは動画中の時間ごとの精度劣化を表しており、本手法が長い動画に対応できる頑健性を備えていることがわかる。
また、本手法は特別なファインチューニングが不要である。さらに、最初のフレームにはマスク画像は不要であり、バウンディングボックスのみを指定すれば良い。
議論
マスク領域推定のブランチがある時とない時で比較し、マスク領域推定のブランチを追加することで、物体追跡部分の精度も向上していると結論づけている。マルチタスク学習の恩恵と言える。
感想
最低限の入力だけで、頑健で高速な物体トラッキングを実現していることが、本手法の素晴らしい点だと思う。
本手法のみでは、オクルージョンやフレームイン/フレームアウトに対応するのは厳しいと思う。
現時点(2019年4月9日)では公式の実装にトレーニング用のコードが無く、学習時に行なっているであろう細かい前処理が見えないのが残念。
ちょこちょこ更新されているようなので、今後もウォッチしていきたい。
公式の実装にトレーニング用のコードが公開されました。