概要
複雑なレイアウトを持つドキュメントからの情報抽出を目的とした手法を提案している論文を読んだので紹介します。本手法が対象とするのは、例えば以下のようなドキュメントです。丸カッコの中は、各ドキュメントから抽出したいエンティティです。

- 医療請求書(医療保険種別,資本総額,請求書番号,社会保障番号,氏名,病院名)
- 電車の切符(チケット番号,始発駅,電車番号,終着駅,日付,チケット料金,座席種別,名称)
- レシート(企業名,住所,日付,総額)
いずれもエンティティがドキュメントの様々な場所に散らばっており、そのレイアウトが異なる場合もあります。こういったドキュメントから情報を抽出するような深層学習モデルを構築することが、この論文の目標となっています。
本論文の提案している手法PICKでは、事前に文字領域のセグメンテーションとそれらの領域に対するOCR(テキストの抽出)はできている、という前提を置きます。各セグメントから得られるテキスト特徴や画像特徴をもとにセグメントをノードとするグラフ表現を推定し、そのグラフに対する畳み込み操作を通じて最終的にはセグメント内の文字レベルでのNER風のタグを予測します。
本論文はICPR2020採択論文です。
書誌情報
- Yu, Wenwen, et al. "PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks." arXiv preprint arXiv:2004.07464 (2020).
- https://arxiv.org/abs/2004.07464
- 公式実装(PyTorch)
モデルの構造
まずはモデルの全体像を確認します。

モデルは3つのモジュールから成り立っており、ドキュメント内のセグメントから特徴量を抽出するEncoder、セグメントの特徴量をもとにグラフ表現を推定して特徴量を洗練させるGraph Module、EncoderとGraph Moduleの結果を組み合わせて全セグメントの文字レベルのNER風のタグを推定するDecoder、という構成になっています。
以下一つ一つ細かく見ていきます。
Encoder
Encoderでは、ドキュメント中の$N$個のセグメントに含まれるテキストをもとにしたテキスト特徴量と、画像としてみたときの画像特徴量を抽出して組み合わせることで、セグメントごとの特徴量を得ます。
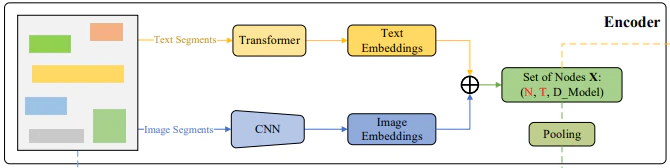
テキスト特徴は、文字レベルのTransformer Encoderによって抽出されます。一方で、画像特徴は、ResNetを通じて抽出されます。各セグメントのテキスト特徴のサイズは$T \times D_{model}$で、画像特徴のサイズは$H \times W \times D_{model}$です。面白いことに、入力画像サイズ調整して画像特徴のサイズを強引にテキスト長と等しくする($T = W \times H$)ことでテキスト特徴と画像特徴のサイズを同じにします。
このようにして得られたテキスト特徴と画像特徴は要素レベルで足し合わされ、$T \times D_{model}$の特徴量$\mathbf{X}$が得られます。このセグメントに対する特徴量は、一方ではそのままDecoderの入力に使われますが、他方ではGraph Moduleの入力に使われます。Graph Moduleに使用するセグメントごとの特徴量$\mathbf{X_0}$は、テキスト長に依存しないように$T$の方向にプーリングされ、$D_{model}$次元になります。
Graph Module
Encoderによってセグメントごとの特徴量が得られました。セグメントはグラフにおいてはノードとして扱われ、その特徴量は$\mathbf{V}$と表記されます。ノードの初期特徴量$\mathbf{V^0}$はEncoderによって得られたセグメントの特徴量$\mathbf{X_0}$に等しいです。
Greaph Moduleは、大きく2つのパーツに分かれています。ひとつは、グラフの構造(ノード間の接続がどのようになっているか)をノードの特徴量をもとに推定するGraph Learning。もうひとつは、ドキュメントにおけるセグメントのレイアウト情報も取り込んでノードの特徴量を洗練させるGraph Convolutionです。
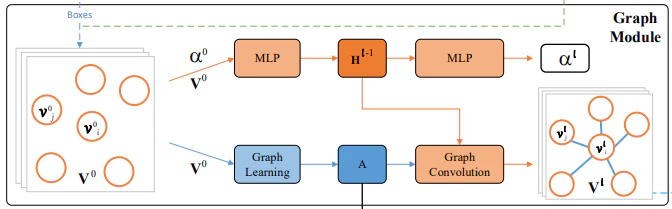
Graph Learning
Graph Learning1は、グラフ構造そのものを推定するためのモジュールです。具体的には、ノードの特徴量をもとに、グラフの構造を表す(ソフトな)隣接行列$\mathbf{A}$を推定します。隣接行列は$N \times N$の行列で、すべての要素が正で、各行を足し合わせると1となる行列です。
Graph Learningモジュールでは、2つのノード間の特徴量の差異をもとに、エッジの強さ$\mathbf{e}_{ij}$を算出し、それをsoftmaxによって正規化します。LeakyReluの部分はReLUでもよさそうですが、勾配消失を避けるために使われているそうです。
\left\{\begin{array}{l}
\left.\mathbf{e}_{i j}=\operatorname{LeakRelu}\left(\mathbf{w}_{i}^{T}\left|\boldsymbol{v}_{i}-\boldsymbol{v}_{j}\right|\right)\right) \\
\mathbf{A}_{i}=\operatorname{softmax}\left(\mathbf{e}_{i}\right), \quad i=1, \ldots, N, \quad j=1, \ldots, N
\end{array}\right.
このようなモジュールに対して、以下のような損失関数が設定されています。
\mathcal{L}_{\mathrm{GL}}=\frac{1}{N^{2}} \sum_{i, j=1}^{N} \exp \left(A_{i j}+\eta\left\|\boldsymbol{v}_{i}-\boldsymbol{v}_{j}\right\|_{2}^{2}\right)+\gamma\|\mathbf{A}\|_{F}^{2}
第1項はノード$i, j$間の特徴量の差異が大きいときは$A_{i,j}$が小さくなるように、差異が小さいときは$A_{i,j}$が大きくなるように促します。また、第2項は正則化項で、これによって隣接行列$\mathbf{A}$がスパースになることを促します。
Graph Convolution
Graph Convolutionでは、ノードの特徴量$\mathbf{V}$、隣接行列$\mathbf{A}$、セグメント間のレイアウトに関する特徴を扱うrelation embedding $\boldsymbol{\alpha}$、エッジの特徴量$\mathbf{H}$といった要素を組み合わせて計算を行います。レイアウトに関する$\boldsymbol{\alpha}$、エッジの特徴量$\mathbf{H}$、ノードの特徴量$\mathbf{V}$、レイアウトに関する$\boldsymbol{\alpha}$、…という順番で計算を行います。
relation embedding $\boldsymbol{\alpha}$の初期値は、以下の式によって得られます。
\boldsymbol{\alpha}_{i j}^{0}=\mathbf{W}_{\alpha}^{0}\left[x_{i j}, y_{i j}, \frac{w_{i}}{h_{i}}, \frac{h_{j}}{h_{i}}, \frac{w_{j}}{h_{i}}, \frac{T_{j}}{T_{i}}\right]^{T}
セグメント同士の距離($x_{ij}, y_{ij}$)、セグメント領域の大きさ($ h_i, w_i, h_j, w_j$)、セグメントに含まれるテキスト長($ T_i, T_j$)といったセグメント間のレイアウトに関する情報を組み合わた6次元ベクトルに、$\mathbf{W}_{\alpha}^{0} \in \mathbb{R}^{D_{model} \times 6}$をかけています。
この$\boldsymbol{\alpha}$とノード特徴量$\mathbf{V}$を用いて、エッジの特徴量$\mathbf{H}$は以下のように算出されます。ここで、$\sigma$は非線形活性化関数$\sigma(\cdot)=\max (0, \cdot)$を表しています。
\boldsymbol{h}_{i j}^{l}=\sigma\left(\mathbf{W}_{v_{i} h}^{l} \mathbf{v}_{i}^{l}+\mathbf{W}_{v_{j} h}^{l} \mathbf{v}_{j}^{l}+\boldsymbol{\alpha}_{i j}^{l}+\mathbf{b}^{l}\right)
エッジの特徴量$\mathbf{H}$を用いて、$\boldsymbol{\alpha}, \mathbf{V}$は以下のように更新されます。ノード特徴量の更新には、Graph Learningで推定された隣接行列$\mathbf{A}$が使われています。これによって、関係性が強いノードに対応するエッジ特徴量を重視してノード特徴量を更新することが可能になっています。
\mathbf{v}_{i}^{(l+1)}=\sigma\left(\mathbf{A}_{i} \mathbf{h}_{i}^{l} \mathbf{W}^{l}\right) \\
\boldsymbol{\alpha}_{i j}^{(l+1)}=\sigma\left(\mathbf{W}_{\alpha}^{l} \mathbf{h}_{i j}^{l}\right)
Graph Convolutionは何層か重ねることが可能です。実験の結果、1層か2層が良い、という結果になっており、主な実験では1層とされています。
Decoder
最後に、Decoderを見てみましょう。

Decoderは、Union Layer, BiLSTM, CRFという3つのモジュールから成り立っています。
Union Layerでは、Encoderによって得られたセグメントごとの特徴量とGraph Moduleによって得られたノードごとの(つまりセグメントごとの)特徴量を組み合わせ、シーケンス特徴量にまとめています。Encoderの特徴量は$\mathbb{R}^{T \times D_{model}}$ですが、セグメントごとにテキスト長$T$は異なります。これをpaddingによって同一にし、$N$個のセグメントを合わせて$\mathbb{R}^{N \times T \times D_{model}}$の特徴量とします。ここで、この特徴量を$\mathbb{R}^{(NT) \times D_{model}}$と変形し、無理やり長さ$NL$のシーケンス特徴量に変形します。このように得られたシーケンス特徴量に、Graph Moduleから得られる特徴量が結合され、$\hat{\mathbf{X}}$が得られます。Graph Moduleによって各セグメントの構造情報が得られるので、セグメント間の順序などはあまり考える必要はなく、無理やりシーケンス特徴量に変形しても大丈夫ということのようです。
BiLSTM Layerは普通の双方向LSTMで、シーケンス特徴量を入力し、同じ長さのシーケンスを出力します。$\mathbf{Z} \in \mathbb{R}^{NT \times D_{output}}$で、$D_{output}$は文字単位でつけられるタグのクラス数に対応します。$\mathbf{0}$はBiLSTMの隠れ層の初期値、$\Theta_{\mathrm{lstm}}$はBiLSTMのパラメータを表します。
\mathbf{Z}=\operatorname{BiLSTM}\left(\hat{\mathbf{X}} ; \mathbf{0}, \Theta_{\mathrm{lstm}}\right) \mathbf{W}_{z}
最後のCRF Layerは、出力であるタグの遷移確率行列を取り入れつつ、条件付き確率$p(\mathbf{y} \mid \hat{\mathbf{X}})$を出力します。本モデルの出力となるタグは、IOBフォーマットによって付与されており、シーケンス上の前のステップのタグが次のステップのタグの出力をある程度決定付けるため、遷移確率は事前に設定されます。
条件付確率は、遷移確率行列に対応するスコア行列$\mathbf{T}$と$\mathbf{Z}$から算出されるスコア$s(\hat{\mathbf{X}}, \mathbf{y})$を用いて以下のように表現されます。
s(\hat{\mathbf{X}}, \mathbf{y})=\sum_{i=0}^{N \cdot T} T_{y_{i}, y_{i+1}}+\sum_{i=1}^{N \cdot T} \mathbf{Z}_{i, y_{i}} \\
p(\mathbf{y} \mid \hat{\mathbf{X}})=\frac{e^{s(\hat{\mathbf{X}}, \mathbf{y})}}{\sum_{\tilde{\mathbf{y}} \in \mathcal{Y}(\hat{\mathbf{x}})} e^{s(\hat{\mathbf{x}}, \tilde{\mathbf{y}})}}
損失関数は負の対数尤度が使われ、スコア表現を使うとシンプルな形で表現できます。$Z$は条件付確率の分母の対数を表します。
\left\{\begin{array}{l}
\mathcal{L}_{\text {crf }}=-\log (p(\mathbf{y} \mid \hat{\mathbf{X}}))=-s(\hat{\mathbf{X}}, \mathbf{y})+Z \\
Z=\log \left(\sum_{\overline{\mathbf{y}} \in \mathcal{Y}(\hat{\mathbf{x}})} e^{s(\hat{\mathbf{x}}, \overline{\mathbf{y}})}\right)=\operatorname{logadd}_{\tilde{\mathbf{y}} \in \mathcal{Y}(\hat{\mathbf{x}})} s(\hat{\mathbf{X}}, \widetilde{\mathbf{y}})
\end{array}\right.
推論時は、$p(\widetilde{\mathbf{y}} \mid \hat{\mathbf{X}})$を最大化するように、最適な$\mathbf{y}^{*}$を動的計画法によって選びます。
実験
実験についても簡単に確認しておきます。実験は、論文著者が自分たちで整備した医療請求書データセットと、もともと用意されているデータセットである、電車の切符、レシートで実験しています。
評価指標は、エンティティの検出に対するPrecision/Recall/F1-scoreです。
医療請求書
ベースラインモデルとして、以下のようなモデルを用意して比較しています。
- Encoderでは画像特徴を使用しない
- Encoderにおけるテキスト特徴を2層のBiLSTMによって抽出する
- DecoderはCRFのみ

すべてのエンティティにおいてベースラインを上回る精度で検出できています。
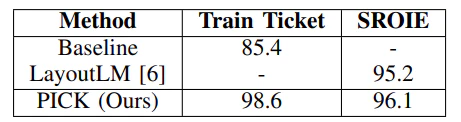
電車の切符/レシート
残りのデータセットでは、F1-scoreで比較しています。ベースラインのほかに大量のドキュメントで事前学習する手法であるLayoutLM2も比較対象にしています。
まず、電車の切符(Train Ticket)は、多少の歪やノイズがあるものの固定レイアウトのデータになっていますが、このようなデータではかなりの精度でエンティティを検出できています。
驚くべきことに、本手法ではレシートデータセット(SROIE)で提供されている教師データのみを使って、多様なドキュメントで事前学習を行っているLayoutLMの同等以上の結果が得られています。
まとめ
ドキュメントからエンティティを抽出する手法であるPICKを提案している論文を紹介しました。
テキスト特徴と画像特徴のサイズを無理やり合わせるところなんかは若干強引なような気もしますが、テキスト、画像、グラフと様々なデータ構造を組み合わせて効果的なモデルを構築できていると思います。
-
参考:https://www.slideshare.net/exwzds/semi-supervised-learning-with-graph-learningconvolutional-networks ↩
-
Xu, Yiheng, et al. "LayoutLM: Pre-training of Text and Layout for Document Image Understanding." arXiv preprint arXiv:1912.13318 (2019). ↩