はじめに
最近、シングルステージの物体検出であるYOLOの名を冠する手法が、立て続けに公開されました。
まず、YOLOv4が2020年4月公開されました。v3までの著者であるJoseph Redmon氏のDarknetリポジトリに組み込まれていることからわかるように、「公式の最新バージョンのYOLO」といえます。
次に、YOLOv5がわずか2ヶ月後の2020年6月に公開されました。v4に比べると論文も公開されておらず、新規性が薄いことや、お墨付きのない状態でv5を名乗っていることについては否定的な意見もあるようです。しかし、公式リポジトリにあるように、現実のデータセットにYOLOv3を適用した際に得られた経験知を取りこんで公開してくれているというのは評価すべき点かと思います。
この記事では、2020年7月に公開された、さらに別のYOLOであるPP-YOLOについて紹介します。
PP-YOLOの「PP」とはBaidu製深層学習ライブラリであるPaddlePaddleの頭文字です。PP-YOLOはYOLOv3をベースにし、バックボーンのアーキテクチャをDarknetからResNetに変更したということ以外は、既存のトリックの組み合わせを模索して精度向上を目指した、というものになっています。その結果、EfficientDetやYOLOv4のパフォーマンスを上回る結果が得られた、と主張しています。
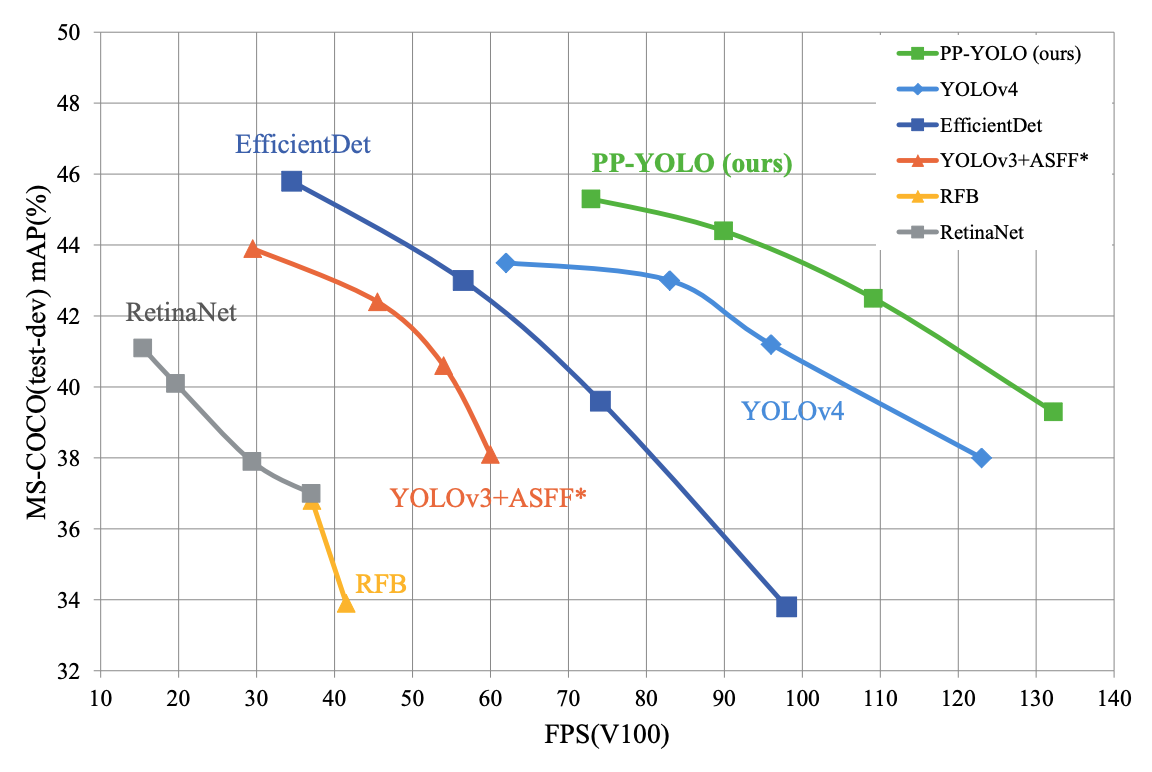
論文中でもはっきりと書かれているように、本論文は何か新規性を主張するものではありません。しかし、物体検出の様々なトリックを学ぶのには良いかもと思い読んでみました。
書誌情報
- Long, Xiang, et al. "PP-YOLO: An Effective and Efficient Implementation of Object Detector." arXiv preprint arXiv:2007.12099 (2020).
- https://arxiv.org/abs/2007.12099
- 公式実装(PaddlePaddle)
ベースラインモデル
まずはベースラインモデルについて確認していきます。基本的なアーキテクチャはYOLOv3を受け継いでいます。
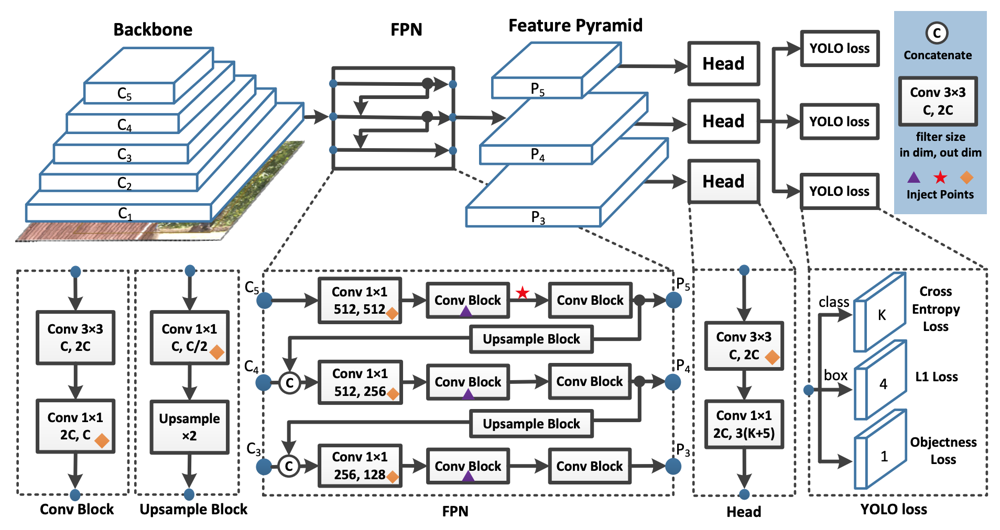
- BackboneとなるCNNから得られた画像特徴量をもとにFPNを通じてFeaturePyramidを構成する。
- 各FeaturePyramidごとにHeadが続き、特徴量を得る。
- 事前に定義された3種類のアンカーごとに、分類/Box回帰/Objectness Scoreを推定する。
Bacobone
YOLOv3との最も大きな違いはBackboneをDarkNet-53からResNet50-vd-dcnに変更したという点にあります。DarkNetはYOLO専用というイメージがあり、あまり広範に研究されていないという問題があります。それに比べると、ResNetは様々なトリックが研究されているアーキテクチャであるため採用した、とのことです。
ところで、ResNet50-vd-dcnのvdやdcnとはなんでしょうか?
まず、vdについては、公式リポジトリの参照先をみてみると、"Bag of Tricks for Image Classification with Convolutional Neural Networks"1という論文の手法で訓練されたResNetのことを指しています。この論文では、ResNetを効果的に訓練するための様々なトリックが検証されており、ResNet派生のいくつかのアーキテクチャよりも、元々のResNetに対する訓練方法を工夫した方が精度が良くなったという驚きの結果を示しています。
次に、dcnは、Deformable Convolution Network2を意味します。DarkNetからResNet-vdに変更しただけでは精度が悪くなってしまったそうで、いくつかのConv層をDCNに置換することで精度の劣化を防いだ、とのことです。
DCNは、FLOPsやパラメータ数的には通常のConv層とそこまで違いはありませんが、推論時間にはそれなりに悪影響を及ぼします。そのため、ResNet40-vd-dcnでは、最終ステージ(おそらくは、ResNetにおけるconv5_xブロックのこと)の3x3Conv層のみをDCNに置換することで、推論速度とパフォーマンスのバランスをとっています。
Box回帰
YOLOでは、特徴マップの各セルごとに事前に定義されたアンカーを元に、実際の物体領域がそこからどれだけズレるのかというBox回帰モデルを訓練します。
この部分はYOLOv3と同じですが、後のトリックに関わる部分なので確認しておきます。
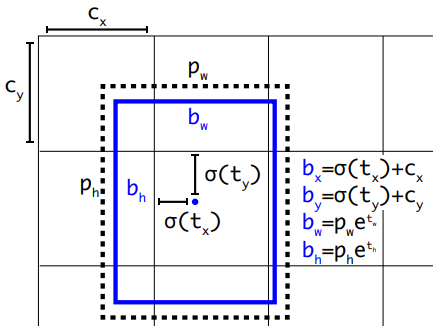
$(b_x, b_y, b_w, b_h)$を特徴マップにおける真の物体矩形の中心のx座標,y座標、幅、高さを表しているとします。$c_x, c_y$をアンカーが定義されている位置、$p_w, p_h$をアンカーの幅と高さとします。Box回帰のターゲットである$t_x, t_y, t_w, t_h$とこれらの値の関係は下式と下図のような関係で表されます。$\sigma$はシグモイド関数です。
\begin{aligned} b_{x} &=\sigma\left(t_{x}\right)+c_{x} \\ b_{y} &=\sigma\left(t_{y}\right)+c_{y} \\ b_{w} &=p_{w} e^{t_{w}} \\ b_{h} &=p_{h} e^{t_{h}} \end{aligned}
下図では、青枠が真の物体領域を表す矩形で、それを囲む点線が、中心位置を移動させたアンカーを表しています。
Objectness Score
こちらもYOLOv3と同じですが、自分の理解が曖昧なところがあったため確認しました。
Objectness Scoreは、各アンカーが物体領域に対応しているかを表すスコアです。ターゲットの作り方が重要で、真の物体領域とのIoUが最も高いアンカーでは1、IoUが0.5未満のアンカーでは0というターゲットが与えられます。なお、IoUが0.5以上でもベストではないアンカーにはターゲットは与えられず、訓練時は無視されます。このようなObjectness Scoreを予測するモデルは、1である確率を予測するロジスティック回帰モデルとして訓練されます。
また、分類/Box回帰に関する損失は、真の物体領域とのIoUが最も高いアンカーでのみで計算されます。
数々のトリック
本論文のメインである、各種のトリックについてみていきましょう。
Large Batch Size
まずはバッチサイズを大きくして安定させようというトリックです。
YOLOv3では64だったのを192にしています。これに伴い、学習率とそのスケジューリングも調整しています。
Exponential Moving Average(EMA)
評価に使用するモデルを、訓練時のモデルの指数移動平均にします。EfficientDet3でも使われている工夫で、訓練時にあっちにいったりこっちに行ったりするパラメータを平滑化し、評価精度を安定させることができます。$\lambda=0.9998$といった値が使われます。
W_{E M A}=\lambda W_{E M A}+(1-\lambda) W
DropBlock
PP-YOLOでは、DropBlock4を適用しています。
DropBlockは、CNNのような空間的な相関が強いオペレーションでは、あるセルをDropOutしても周囲のセルから特徴量が漏れてしまい、うまく機能しないことがあるという弱点を克服するものです。具体的には、領域レベルでDropOutさせるというトリックです。下図の×がDropOutの対象で、(b)が通常のDropOut、(c)がDropBlockになります。
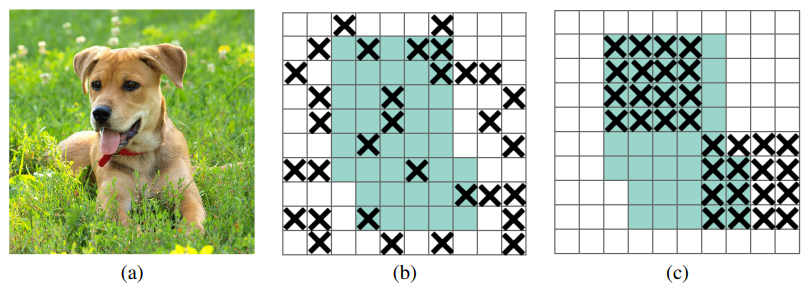
DropBlockの論文では、BackboneにもFPNにもDropBlockを適用していますが、本論文では、BackboneにDropBlockを適用すると劣化が生じてしまったために、FPNのみにDropBlockを適用していると述べています。適用しているのは、下図の▲の位置です。
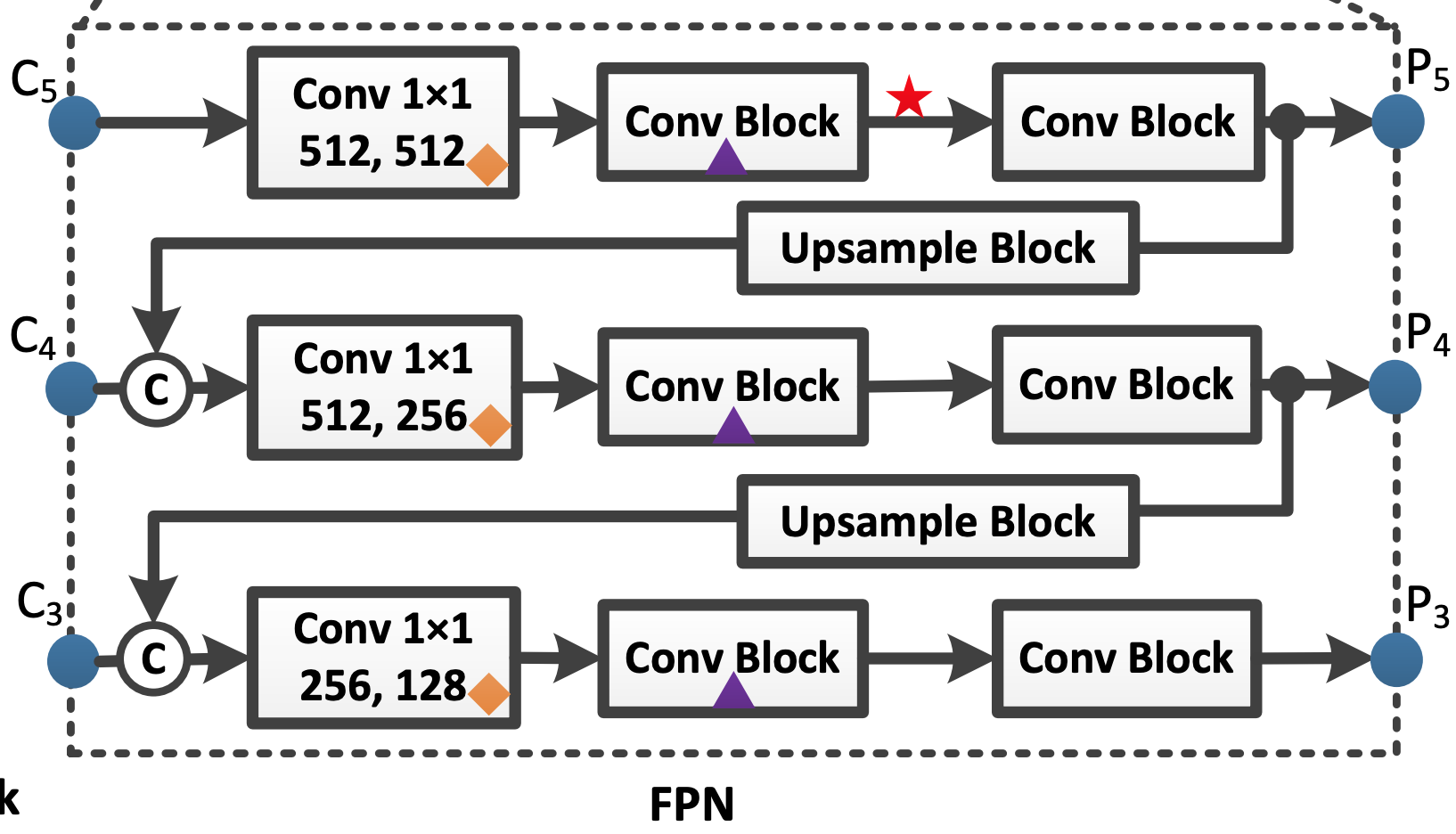
IoU Loss
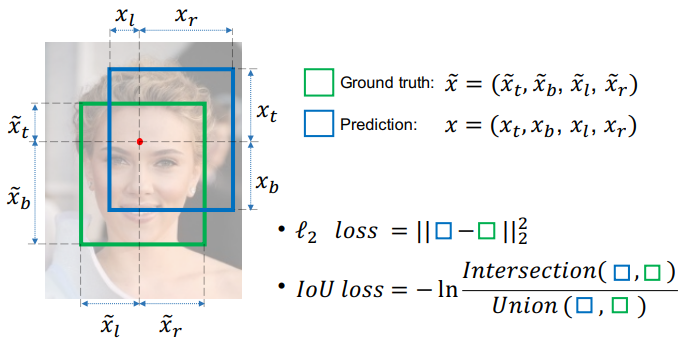
Box回帰に関しては、いくつかの損失関数を考えることができます。YOLOv3のオリジナルでは、$t_x, t_y, t_w, t_w$ に対する二乗誤差損失が使われています。
これに対して、推定した領域と真の領域とのIoUをベースとしたIoU損失というものが考えられます。中には、IoU損失のみを採用し、二乗誤差損失を採用しないという研究もありますが、本論文では、どちらも利用することにしています。
IoU損失にもいくつかのバリエーションがあるみたいですが、本手法では最もベーシックな手法5が使われています。
\mathrm{IoU Loss} = - \ln \mathrm{IoU}
IoU Aware
YOLOv3では、検出結果のスコアは、「分類スコア x Objectness Score」によって計算されます。しかし、このスコアは、最終的な検出位置がどの程度正しいのか(定位精度)を考慮できていません。
そこで、HeadにIoU予測ブランチ6を追加します。IoU予測ブランチは、最終的な検出領域が真の領域とどの程度のIoUにあるのかを推定します。検出結果のスコアは、「IoUスコア x 分類スコア x Objectness Score」となります。
IoU予測ブランチの追加は、0.01%のパラメータ数と0.0001%のFLOPsの追加に止まり、推論速度への影響も無視できる程度に留まります。
Grid Sensitive
Grid Sensitiveとは、真の領域の位置によっては、どのアンカーにも引っ掛かりづらく、推定が難しくなるという問題です。
先に確認した、Box回帰の式を再確認してみましょう。
\begin{aligned} b_{x} &=\sigma\left(t_{x}\right)+c_{x} \\ b_{y} &=\sigma\left(t_{y}\right)+c_{y} \end{aligned}
ここで、$\sigma(t_x), \sigma(t_y)$は0以上1以下の値をとりますが、グリッドの境界にあたる$\sigma(t)=0,1$となるのは、$t=-\inf,\inf$という極点な値です。ここまで極端な値が回帰モデルのターゲットとして与えられると、モデルの訓練が不安定になりますし、推論時にも、このようなグリッドの境界付近の物体を検出しにくいという問題につながります。
以下にPP-YOLOにおけるBox回帰の式を示します。$p_x, p_y$がここまでの議論の$t_x, t_y$に対応します。
\begin{array}{l} x=s \cdot\left(g_{x}+\sigma\left(p_{x}\right)\right) \\ y=s \cdot\left(g_{y}+\sigma\left(p_{y}\right)\right) \end{array}
これをGrid Sensitiveに対処するために、以下のような式に修正します。
\begin{array}{l} x=s \cdot\left(g_{x}+\alpha \cdot \sigma\left(p_{x}\right)-(\alpha-1) / 2\right) \\ y=s \cdot\left(g_{y}+\alpha \cdot \sigma\left(p_{y}\right)-(\alpha-1) / 2\right) \\ \alpha = 1.05 \end{array}
$\alpha$の導入により、グリッド境界に対応する$p_{x}, p_{y}$は$\pm{3.71}$程度となり、ニューラルネットの回帰モデルの出力として妥当な範囲の値に収まってくれるため、訓練の安定性や推論時の検出漏れの低減につなげることができます。
Matrix NMS
多くの物体検出手法の後処理として必要とされるNMSは、それなりの計算コストになります。
Matrix NMS7は、Soft NMSと呼ばれるNMS手法を、並列計算によって高速化することを目的とした手法です。Soft NMSでは、検出候補同士のIoUを求め、2つの候補間のIoUが大きい場合は、スコアが小さい方のスコアを減衰させるという操作をスコアの高い順に繰り返し、閾値を適用して最終的な検出結果を得るという手法です。通常のNMSとは異なり、検出スコアの低い候補を削除するのではなく、スコアを減衰させるというソフトな処理が名前の由来となっています。
Matrix NMSでは、検出候補領域をマスク画像として捉えます。各マスク画像をフラット化して積み上げた行列を作成し、この行列に対する操作を通じて、各候補領域の面積や候補領域間のIntersectionを計算します。ここから各候補間のIoUが計算できます。
IoUは候補間に対して与えられる実数値なので、行列として表されます。IoU行列の上三角行列を元に、行ごとに最大のIoUになっている他の候補を特定し、そのスコアを減衰させるという処理を各行で並列して適用できます。上三角行列を使うことで、もともとのスコアが大きい検出領域のスコアはそのままに、それよりもスコアが低いIoUが大きい候補のスコアのみ減衰させるという処理を実現しています。
Matrix NMSのIoUを元にしたスコアの減衰方法には、GaussianとLinearがありますが、PP-YOLOではGaussianを採用しています。
CoordConv
CoordConv8は、Conv層の入力に対して横方向の座標と縦方向の座標を表す2チャンネルを追加し、その上でConvolutionを行うという手法です。これによって、特徴量に画像における位置という情報が付与されることになります。CoordConvは、Box回帰のような直接的に座標情報が役に立つ時以外にも、様々な画像認識タスクで精度向上に寄与することが知られています。
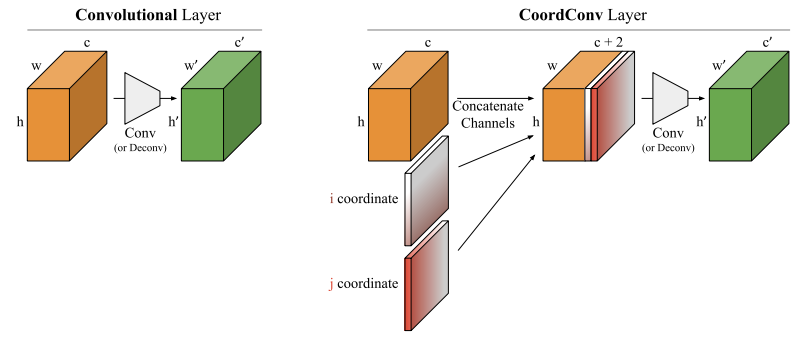
CoordConv層を導入すると、入力チャネルが自動的に2増えるので、若干FLOPsやパラメータ数、推論速度に悪影響がでます。本手法では、下図の◆の位置にある1x1Conv層にのみ適用しています。
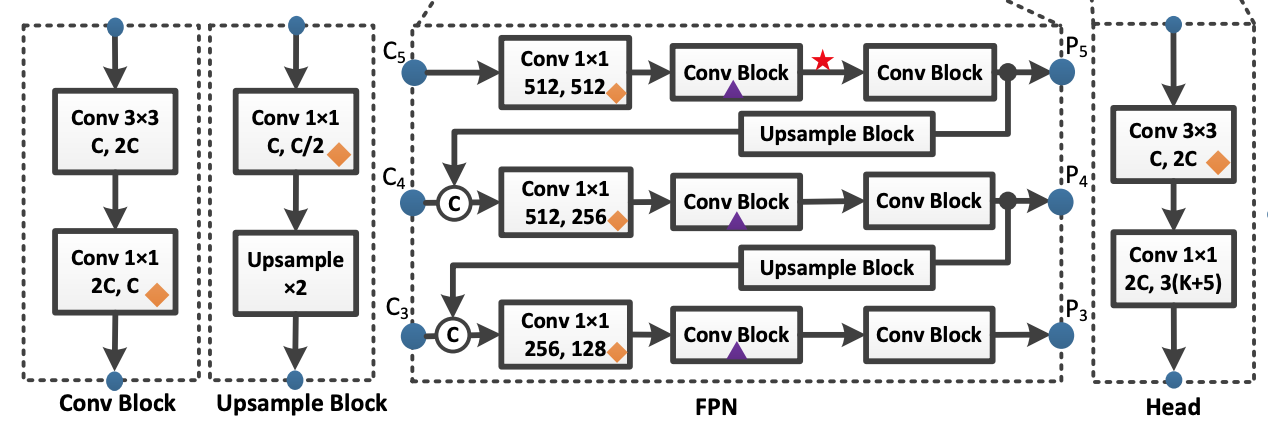
SPP
Spatial Pyramid Pooling9は、1つの特徴マップに対して様々なカーネルサイズのMaxPoolingを適用し、得られた特徴マップをチャネル方向に結合するという処理です。この操作により、特徴マップの各セルには、局所的な特徴量だけでなく、周辺の平均的な特徴量、大域的な平均特徴量が与えられることになります。
PP-YOLOでは、YOLOv4と同様に、カーネルサイズ$k=\{1,5,9,13\}$、ストライド$s=1$というMaxPoolingによって実装しています。
SPPはMaxPoolingと結合操作のみからなるモジュールなので、それ自体はパラメータを持ちませんが、後続のConv層の入力チャネルが増え、それに伴ってパラメータ数が増えます。PP-YOLOでは、挿入する位置を下図に示されるFPNの★の位置に限定し、パラメータ数は2%、FLOPsは1%の増加に留めています。
Better Pretrain Model
より良いBackboneを得るために、Semi-supervised label knowledge distillation(SSLD)という枠組みで、ResNeXt101ベースの教師モデルを蒸留し、ResNet50-vd-dcnのBackboneをチューニングしているようです。
細かい内容が気になる方は以下のURLをご覧ください。
https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/en/advanced_tutorials/distillation/distillation_en.md
まとめ
以上のような様々なトリックを順次加えていった時の精度の推移が以下の表になります。BackboneをDarkNet53からResNet50-vd-dcnに変更しても精度は微増ですが、FPSは80近くまで上がっています。その後はトリックを加えるだけ精度が徐々に上昇し、FPSは徐々に下がっていくというすばらしい結果になっています。
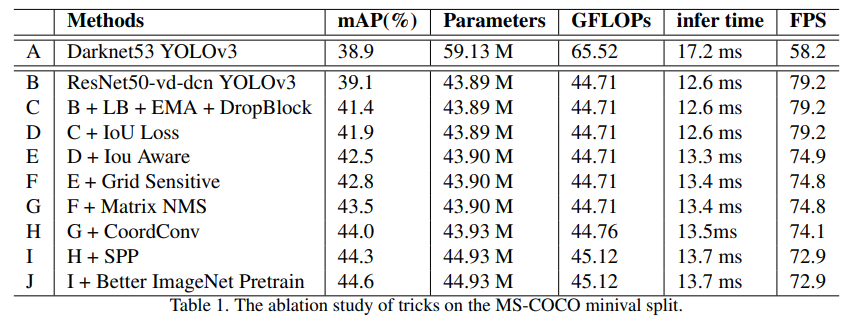
疑問があるとしたら以下の2点くらいです。
- Matrix NMSは精度向上には寄与しているが、FPSの向上には寄与していないように見えるのはなぜか?
- 最初からBetter Pretrain Modelを適用していたらどうなったのか? 実は、Backboneの性能だけでmAP44.6%が達成できたりしないか?
公開されている実装がPaddlePaddleのものなのでなかなか手が出しにくいですが、各種のトリックは取捨選択して自分の物体検出手法に取り入れることができるので、勉強になりました。
-
He, Tong, et al. "Bag of tricks for image classification with convolutional neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019. ↩
-
Zhu, Xizhou, et al. "Deformable convnets v2: More deformable, better results." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019. ↩
-
Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and efficient object detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. ↩
-
Ghiasi, Golnaz, Tsung-Yi Lin, and Quoc V. Le. "Dropblock: A regularization method for convolutional networks." Advances in Neural Information Processing Systems. 2018. ↩
-
Yu, Jiahui, et al. "Unitbox: An advanced object detection network." Proceedings of the 24th ACM international conference on Multimedia. 2016. ↩
-
Wu, Shengkai, Xiaoping Li, and Xinggang Wang. "IoU-aware single-stage object detector for accurate localization." Image and Vision Computing (2020): 103911. ↩
-
X. Wang, R. Zhang, T. Kong, L. Li, and C. Shen. [Solov2: Dynamic, faster and stronger]. arXiv preprint arXiv:2003.10152, 2020. ↩
-
Liu, Rosanne, et al. "An intriguing failing of convolutional neural networks and the coordconv solution." Advances in Neural Information Processing Systems. 2018. ↩
-
He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." IEEE transactions on pattern analysis and machine intelligence 37.9 (2015): 1904-1916. ↩