概要
物体検出手法において必須ともいえるNon-Maximum suppression(NMS)を使用しないことを目指した手法DeFCNを提案している論文を読んだので紹介します。
NMSを使用しないことを目指す理由とは何でしょうか?
以下の表は、本手法を含む物体検出手法の、CrowdHumanデータセット1における各種精度の比較です。データセット名からもわかるように、このデータセットには人が密集した画像が多く含まれています。
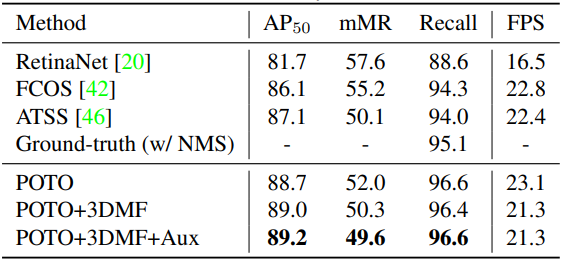
Ground-truth(w/NMS)という行の、Recallが95.1になっていることに注目しましょう。Ground-truthという名前からRecallが100%であることが期待されますが、NMSを適用してしまうと近い位置に存在する人物領域同士がマージされてしまい、4.9%もの領域が消えてしまうということを表しています。このRecallは、NMSを使う場合はこれが限界です、という数値と言えます。
もちろん、単にRecallを上げたいだけならばNMSによる重複検出の除去を使用しなければよいですが、それぶん誤検出が多くなってしまい、Precisionが大幅に下がってしまうことは明らかです。
一方、本論文で提案している手法を表している下3行の結果を見てみると、$\mathrm{AP}_{50}$やmMRは既存手法と並ぶか上回る精度を実現しているうえ、Recallも96.6%となっており、NMSを使用しないことによるRecallの向上とPrecisionの低下の防止を両立させています。
DeFCNでは、NMSフリーな物体検出手法のための2つの工夫を提案しています。いずれも、重複検出を抑えることで、NMSを適用する必要がないようにしたい、というのが目的です。
1つ目は、POTO(Prediction-aware One-To-One)と呼ばれる工夫で、通常の物体検出手法において、真の領域に対して複数のアンカーや特徴マップ上の複数のセルが対応づけられてしまう(one-to-many)ことを回避し、単一のセルに対応づける(one-to-one)ことを目的としています。これによって、隣接するセルによる重複検出を抑制します。POTOでは、事前にone-to-oneの対応付け方法を定義するのではなく、予測された結果をもとに動的にone-to-one対応を決定するという方法を採用しています。
2つ目は3DMF(3D Max Filtering)と呼ばれる工夫で、FeaturePyramidNetworkベースの物体検出において生じやすい、異なるスケールでの予測が重複検出につながることを抑制することを目的としています。
本稿では、上記2つの工夫を中心に、DeFCNを成立させている技術を確認していきます。
書誌情報
- Jianfeng Wang, Song Lin, et al. "End-to-End Object Detection with Fully Convolutional Network." arXiv preprint arXiv:2012.03544 (2020).
- 公式実装
モデルの全体像
ベース手法FOC
まずは、モデルの全体像を確認しておきます。以下の図は、本手法のベースとなっている物体検出手法FOC2の構造です。FOCはアンカーフリーの物体検出手法で、Feature Pyramidの各スケールごとにHeadが付いており、その中で特徴マップの各セルについて、カテゴリ分類と矩形領域に関する回帰が行われています。本手法も基本的にはこの構造を受け継ぎますが、Center-nessに関するブランチは不要です。
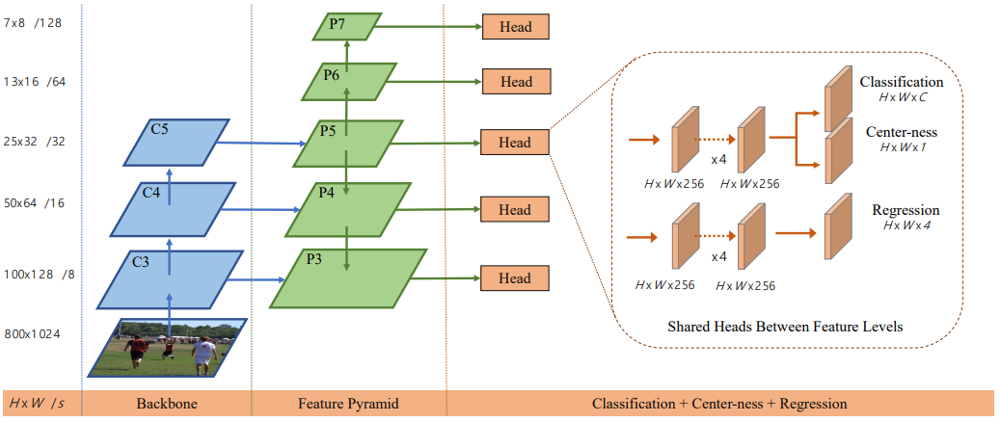
DeFCNの全体像
続けて、以下の図が本手法の全体像を表す図となっています。
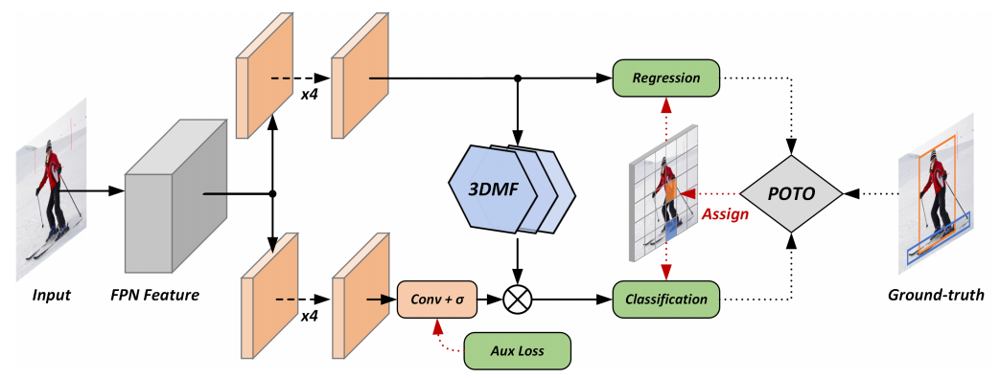
まず、入力画像からFeature Pyramid Networkによって特徴ピラミッド(FPN Feature)が得られます。特徴ピラミッドは複数のスケールの特徴マップから構成されています。各スケールの特徴マップは、カテゴリを予測するための分類ブランチと矩形領域を予測するための回帰ブランチへと入力されます。回帰ブランチの途中にある$\sigma$は、シグモイド関数を表しています。
このような基本的な流れに対して、上述の2つの工夫は以下のように使われています。
- POTOは上図の右端にあります。Ground-truthの情報及び、Regressionの予測とClassificationの予測を考慮して、どのような監督を行って損失を計算するかを調整します。
- 3DMFは、Regression側のブランチの計算結果をもとに、Classification側の予測結果の一部を抑制するのに使用されます。
損失関数
また、3種類の損失が計算されます。
- 分類損失は、FocalLossが使用されます。
- 回帰損失は、IOU lossが使用されます。
- Aux Lossは、POTOによる監督の弱さを補うための補助となる損失関数です。詳細については後述します。
POTOによるone-to-oneの監督
one-to-manyとone-to-one
一般的に、物体検出の手法では1つの物体領域に対して、複数の予測結果が割り当てられ、それらすべてに損失が計算されます。例えば、アンカーベースの手法であれば、真の物体領域とアンカーとのIoUが一定値以上であるアンカーに対して、分類ラベルや矩形領域の補正値というターゲットが与えられます。このようなone-to-manyの対応関係は、特徴マップ上の近隣セルが同一の物体領域に関するターゲットを持つこととなり、必然的に重複検出を誘発します。これは、NMSフリーな手法を目指す場合は好ましくありません。
一方で、いくつかの手法では、ont-to-manyの対応関係ではなく、one-to-oneの対応関係を採用しています。例えば、アンカーベースの手法であれば、真の物体領域と最もIoUが大きいアンカーのみにターゲットを設定する、という例があります。また、アンカーフリーの手法であれば、物体領域の大きさによって一意に所属させるピラミッドのスケールが決められ、物体領域の中心が属しているセルにのみターゲットを設定する、といったやりかたがあります。
著者らの観察では、このような事前に定義されたone-to-oneの対応関係は、重複検出を著しく低減させる一方で、検出精度を劣化させてしまうということです。
動的なone-to-one
そこで、本研究では、one-to-oneの対応関係を事前に定義せずに、実際に訓練中のモデルから得られた予測結果を通じてone-to-oneの対応関係を動的に決定するPOTOを提案しています。この対応付けは、真の物体領域$i (1, 2, ..., G)$と、予測された検出候補$j (1, 2, ..., N)$を結びつける関数$\pi(i) = j$で表現できます。検出候補のほうがはるかに真の物体領域よりも多いので、$G \ll N$とします。
対応関係$\pi(i)$を求めるために、POTOでは以下のような各物体領域と検出候補間の対応の良さを表すQuality関数を定義します。
Q_{i, \pi(i)}=
\underbrace{\mathbb{1}\left[\pi(i) \in \Omega_{i}\right]}_{\text {spatial prior }} \cdot \underbrace{\left(\hat{p}_{\pi(i)}\left(c_{i}\right)\right)^{1-\alpha}}_{\text {classification }} \cdot \underbrace{\left(\operatorname{IoU}\left(b_{i}, \hat{b}_{\pi(i)}\right)\right)^{\alpha}}_{\text {regression }}
Spatial Priorは、真の物体領域が存在する領域($\Omega_i$)に特徴マップのセルが含まれていれば1、そうでなければ0となる項です。ClassificationとRegressionは、それぞれ検出候補の分類結果と真のカテゴリがどの程度一致しているのか、検出候補と真の領域がどの程度一致しているのかを表します。$\alpha=0.8$とすることで良い性能が得られると実験で確かめられています。
このようなQuality関数によって、真の物体領域と検出候補領域の対応の良さが定量的に得られたら、下式のようなQualityスコアの合計値の最大化する対応付け$\hat{\pi}(i)$は、ハンガリアンアルゴリズムによって高速に得ることができます。
\hat{\pi} =\underset{\pi \in \Pi_{G}^{N}}{\arg \max } \sum_{i}^{G} Q_{i, \pi(i)}
以上のように求めた$\hat{\pi}(i)$をもとに、分類と回帰に関わる損失関数は以下のようにまとめられます。$\hat{\pi}(i)$に含まれないほとんどの検出候補に対しては、すべて背景として分類するような分類ターゲットが与えられています。
\mathcal{L}=\sum_{i}^{G} \mathcal{L}_{f g}\left(\hat{p}_{\hat{\pi}(i)}, \hat{b}_{\hat{\pi}(i)} \mid c_{i}, b_{i}\right)+\sum_{j \in \Psi \backslash \mathcal{R}(\hat{\pi})} \mathcal{L}_{b g}\left(\hat{p}_{j}\right)
以上、このような流れで、動的にone-to-oneの対応関係を作ることができるというのがPOTOです。
3DMFによる異なるスケールでの重複検出の抑止
FPNベースの物体検出では、特徴ピラミッドの各スケールごとに検出候補に対してNMSをかけた場合、全スケールの検出候補を集約したのちにNMSをかけた場合よりも精度が劣化する、ということが論文中の実験で確かめられています。そして、その劣化の原因が、異なるスケールでの重複検出にあるということを発見しています。同一の物体領域を表す検出候補が、ピラミッドの複数のスケールにまたがっていることがあるので、NMSをかける場合は注意する必要がある、という指摘です。
本研究では、NMSフリーな手法の実現のために、特徴ピラミッドのスケール間での重複検出を抑制するための仕組みでありる3DMFを提案しています。
3DMFの実態は以下のようなシンプルなネットワークです。GNはGroup Normalizationを指し、$\sigma$はシグモイド関数を表します。3D Max Filterと書かれている部分の処理も非常にシンプルで、複数のスケールの特徴マップをBilinear補間によってサイズをそろえてスタックし、3次元MaxPoolingを適用するというものです。
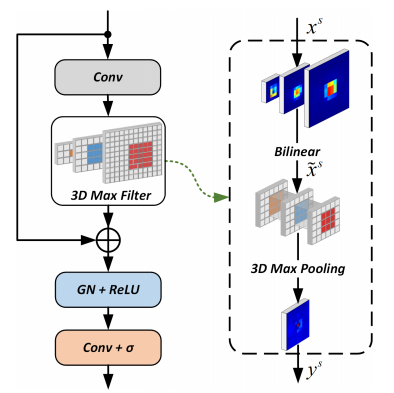
MaxPoolingは、「ランキングによる非線形フィルター」という性質を持っているので、顕著な特徴量のみを抽出し、隣接する似通った特徴をフィルターする役割を果たします。さらに、3DMFの場合は、特徴ピラミッドの複数のスケール間でのフィルタリングも行います。
3D Max Filterの部分を数式で表すと以下のようになります。MaxPoolingのカーネルサイズは$k\times k\times\tau$で、実験の結果、$k=3, \tau=2$が最も良い結果となったとされています。
\tilde{x}^{s}=\left\{\tilde{x}^{s, k}:=\operatorname{Bilinear}_{x^{s}}\left(x^{k}\right) \mid \forall k \in\left[s-\frac{\tau}{2}, s+\frac{\tau}{2}\right]\right\}
y_{i}^{s}=\max_{k \in\left[s-\frac{\tau}{2}, s+\frac{\tau}{2}\right]} \max_{j \in \mathcal{N}_{i}^{\phi \times \phi}} \tilde{x}_{j}^{s, k}
以下は、本手法の全体像の再掲です。これを見ると、3DMFの出力は分類ブランチの出力に掛け算されていることがわかります。3DMFの役割は、複数のスケールをまたぐ矩形領域の候補同士で比較してフィルタリングを行い、重複が起きていそうなセルの分類スコアを下げる役割を果たしていると解釈できます。
Auxiliary損失による分類タスクに関する監督の強化
POTOによるone-to-oneの対応付けは、重複検出を抑制する一方で、one-to-manyと比べると分類に必要な識別的な特徴量をうまく抽出できないという問題が生じます。そのため、本手法では、分類に関するより適切な監督を提供するために、one-to-manyのラベル割り当てに基づく補助損失を導入しています。
まず、ある真の物体領域に対してQualityスコアの値が高いものを、特徴ピラミッドの各スケールで上位9個選びます。これらの候補を用いて、Qualityスコアの平均$\mu$と標準誤差$\sigma$を求め、閾値$\mu+\sigma$を上回る候補を求めます。Qualityスコアが正規分布に従っているのであれば、この候補は上位16%程度に相当します。
このように得られた比較的真の物体領域に近い候補に対しては、one-to-manyの形で分類ターゲットを与え、分類損失を算出します。
このAux損失はPOTOの目標とやや矛盾するようにも思えますが、分類に必要な識別的な特徴抽出を実現するために有用だと示されています。
各工夫による定性的な変化
以下は、ベースとなる手法であるFCOSと比較して、本手法で提案した工夫がどのような変化をもたらすのかを比較したわかりやすい図です。入力画像には3つの物体(人、ネクタイ、桶)が存在しており、3つのスケールの分類出力がどのようになっているかを示したものです。これらのヒートマップは、分類ブランチの出力に対して全クラスでのmaxをとったもので、「何らかの物体がこのセルにありそうだ」というスコアを表しています。

(a)のFCOSでは、高い値が広がりを持って分布していることが読み取れます。物体とヒートマップのピークは1対1には対応しておらず、例えば桶は左側のヒートマップにも真ん中のヒートマップにも表れていますし、ネクタイも同様です。前者は、one-to-manyによって真の物体領域に近い位置にあるセルに広く監督が行われたためであり、後者は、特徴ピラミッドの複数のスケールで同一の物体が検出されている、ということを表しています。このようなヒートマップとなるモデルでは、NMSは必須と言えます。
(b)は(a)とは違い、ヒートマップの広がりが抑えられており、ピーク位置がはっきりと表れるので、POTOによるone-to-oneの監督がうまく効いていると言えます。しかし、異なるスケールで同一の物体を意味する検出候補がある、という点は(a)と一緒です。
(c)は、3DMFを導入することで、検出候補がどのスケールで出てくるのかがきれいに分かれるようになります。ネクタイは一番細かいスケールで、桶は真ん中のスケールで、人は一番粗いスケールでのみ検出されています。また、わずかに残っていた広がりもほとんどなくなっています。3DMFによるフィルタリングが適切に機能していることがわかります。
(d)では、さらにAux損失を導入することで、細かいピークが抑制されています。これは、物体カテゴリごとの分類が洗練されたためと言えます。
まとめ
以上、NMSフリーな物体検出手法DeFCNについてまとめてみました。
POTOによるone-to-oneの監督によって隣接するピクセルでの重複検出を抑え、3DMFによるFPNの異なるスケールでの重複検出を抑えています。
-
Shao, Shuai, et al. "Crowdhuman: A benchmark for detecting human in a crowd." arXiv preprint arXiv:1805.00123 (2018). https://www.crowdhuman.org/ ↩
-
Tian, Zhi, et al. "Fcos: Fully convolutional one-stage object detection." Proceedings of the IEEE international conference on computer vision. 2019. ↩