概要
『天空の城』の名を冠する動画合成に関する論文を読んでみたので、紹介してみます。
この論文で提案している手法は、以下の画像のように、空の領域を別途用意されたテンプレート画像と置き換えることで、あたかも天空の城が現実に出現したかのように合成できるというものです。公式実装のリポジトリ名がSkyARとなっているように、まさに「空のAR」というべき効果が得られています。

本手法が面白いのは、このような合成を、ジャイロセンサーなどの情報を利用せずに、画像情報のみからリアルタイムで動画に対して適用できるという点にあります。公式のプロジェクトページに様々な動画が上がっているので、眺めてみると楽しいと思います。
本手法では、このような合成を3つのプロセスで実現します。深層学習を使っているのは、1のマッティング部分だけで、あとはレガシーなコンピュータビジョンのテクニックが活用されています。
- 空の領域のマッティング
- モーション推定
- 画像合成
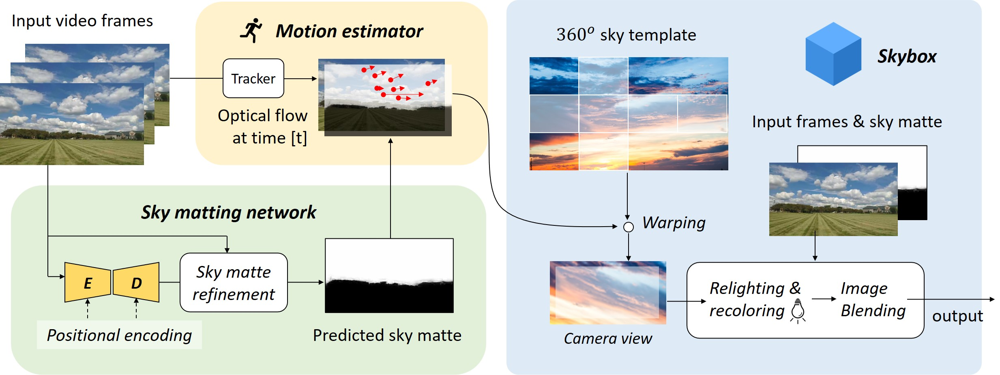
以下、それぞれの処理について確認してきます。
書誌情報
- Zou, Zhengxia. “Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos.” ArXiv abs/2010.11800 (2020): n. pag.
- https://arxiv.org/abs/2010.11800
- 公式実装(PyTorch,OpenCV)
- 公式プロジェクトページ
Sky Matting
動画フレーム中の空の領域のソフトな推定を行うことが、ここでの目標になります。前景と空の領域の境界は、二値でなく0から1の間のソフトな表現として得る必要があります。
まず、U-Net風のEncoder/Decoderによるセグメンテーションネットワークを使用し、空のマスク領域を推定します。
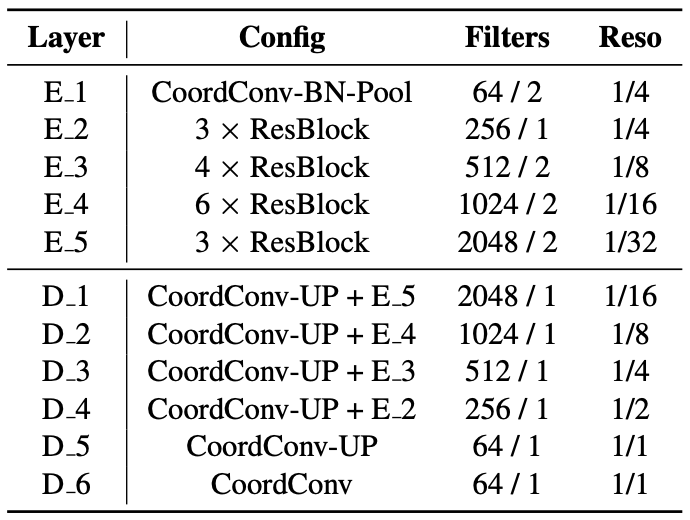
空の領域は、一般的に画像の上の方に集中しています。そこで、このネットワークのいくつかのConv層に対して、CoordConv1を導入しています。これにより、画像中における相対的な位置情報も特徴量に埋め込むことができ、空の領域を効率的に推定することができるようにしています。
また、セグメンテーションはある程度粗い解像度で行い、Guided Filter2による高解像度化を行うという手順を踏んでいます。これにより、わずかなオーバーヘッドが生じますが、鮮明で高精度なマスク画像を得ることができています。
以上の処理によって、あるフレーム$I^{(t)}$に対して、ソフトなマスク画像$A^{(t)}$が得られます。
Motion Estimation
動画フレーム中の空の領域をテンプレート画像と入れ替えるためには、連続するフレームにおけるカメラの動きを推定し、それを仮想的なカメラに反映したうえで、仮想的なカメラが撮影するテンプレート画像をレンダリングする必要があります。
カメラの動きは、アフィン行列$M \in \mathbb{R}^{3\times3}$によってモデル化されます。空の領域とその中の物体(雲、太陽、月など)は無限遠に位置しているという強い仮定を設け、カメラの動きは4自由度(平行移動、回転、スケーリング)とします。1つ目のプロセスで得られた空の領域から特徴点を抽出し、連続するフレーム間のマッチングを行うことで、フレーム間のカメラの動きが推定できます。
ここで問題になるのが、空の領域中の特徴点の品質の悪さと少なさです。
まず、空の領域は非常に遠いということもあり、特徴点としての品質が悪いことが多く、外れ値が生じやすいそうです。そこで、マッチングした特徴点同士のユークリッド距離に関するカーネル密度推定を行い、確率密度の小さい対応関係を除外することで外れ値問題に対処しています。
また、空の領域から十分な数の特徴点が得られなかった場合は、単眼深度推定手法を用いて、2番目に遠い領域を推定し、その領域から代替的な特徴点を抽出することで、特徴点の少なさをカバーしています。
各フレーム間のアフィン変換$M^{(t)}$とテンプレート画像に対する中央切り取りを表す$M^{(c)}$を組み合わせ、下式のようなアフィン変換を得ることができます。
\widetilde{M}^{(t)}=M^{(c)} \left(M^{(t)} M^{(t-1)} \ldots M^{(1)}\right)
空のテンプレート画像$B$に対して、アフィン変換$\widetilde{M}^{(t)}$を適用し、合成に使用する空画像$B^{(t)}$を得ることができます。
Sky Image Blending
以上のように、元動画のフレーム$I^{(t)}$に対して、空の領域を表すマスク$A^{(t)}$と空の画像$B^{(t)}$が得られているので、以下のような合成が可能になります。
Y^{(t)}=\left(1-A^{(t)}\right) I^{(t)}+A^{(t)} B^{(t)}
しかし、このままでは空の色合いが変わっているのに地表の色合いは全く変化がない、という結果になってしまいます。そこで、下式のようなrecoloringとrelightningの処理を事前に行います。ここで、$\mu_{B(A=1)}^{(t)}$は空の領域における$B^{(t)}$の平均値、$\mu_{I(A=0)}^{(t)}$は非空の領域における$I^{(t)}$の平均値を表します。
\begin{array}{l} \widehat{I}^{(t)} \longleftarrow I^{(t)}+\alpha\left(\mu_{B(A=1)}^{(t)}-\mu_{I(A=0)}^{(t)}\right) \\ I^{(t)} \longleftarrow \beta\left(\widehat{I}^{(t)}+\mu_{I}^{(t)}-\widehat{\mu}_{I}^{(t)}\right) \end{array}]
まとめ
簡単にですが、動画中の空の領域を置き換える手法を提案している論文を紹介しました。
Sky Mattingの訓練に使用しているデータセットや処理の流れは、CVPR2020のワークショップで公開されたもののようです。こちらについては未読なので、時間のあるときに読んでみたいと思いました。
-
Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski. An intriguing failing of convolutional neural networks and the coordconv solution. In Advances in Neural Information Processing Systems, pages 9605–9616, 2018. ↩
-
Kaiming He, Jian Sun, and Xiaoou Tang. Guided image filtering. IEEE transactions on pattern analysis and machine intelligence, 35(6):1397–1409, 2012. ↩