概要
幼児に対する2次元姿勢推定モデルFiDIPを提案している論文を読んだので紹介してみます。
長期間にわたる用事の動きの観察は、発達の問題や病気を早期に発見するための重要な手掛かりになることが知られています。本研究は、そのような観察を実現するための幼児向け姿勢推定モデルと、それを訓練するためのデータセットを提案しています。
深層学習ベースの姿勢推定モデルは様々なものが提案されていますが、幼児に対してこのようなモデルを適用しようとすると、あまり良い性能が得られなかった、ということが本研究の動機となっています。
以下の図は、真のポーズ(一番左の列)に対して、DarkPose(ResNet50ベース)、Faster R-CNN、Pose-ResNet、DarkPose(HRNet-W48ベース)、本手法(一番右)の推定結果がどうなっているかを表しています。一番上のような真正面からとらえた比較的おとなしいポーズの画像であればどの手法も正確な姿勢推定ができていますが、一番下のような幼児特有の変なポーズの画像に対しては、どの手法もあまりよい推定結果が得られていません。本手法の推定結果は、もちろん完璧とまでは言えませんが、既存の手法に比べると極端な推定結果の間違いが少なくなっており、精度指標上も最も良い結果が得られいます。

幼児の姿勢推定を難しくしている要因は、以下のようなものが挙げられます。
- 幼児は、大人とは体のパーツのバランスが異なる
- 幼児は、取ることができるポーズの多様性が高い
要するに、通常の姿勢推定モデルの訓練に使用するデータセットは大人に偏りすぎているというわけです。
この問題を解決するために、本研究では、700枚の実画像と1000枚の合成画像からなるデータセットSyRIP(synthetic and real infant pose)と、それを用いたファインチューニングによって訓練されるモデルFiDIP(fine-tuned domain-adapted infant pose)を提案しています。
本稿では、FiDIPのネットワーク構造と訓練手順、およびSyRIPの構築方法について紹介します。
書誌情報
- Huang, X. et al. “Invariant Representation Learning for Infant Pose Estimation with Small Data.” (2020).
- https://arxiv.org/abs/2010.06100
- 公式実装(PyTorch)
ネットワーク構造と訓練手順
FiDIPは、基本的には学習済みの姿勢推定モデルのファインチューニングによって構築されます。しかし、幼児のデータは量が少ないため、それなりの量を用意できる合成データも併せて訓練を行いたいわけですが、合成データに特有の特徴を利用して訓練してしまうことを避けるために、敵対的学習を使用します。こうすることで、実画像と合成画像に共通する、姿勢推定に本質的な特徴のみを用いた姿勢推定モデルが訓練できるように促します。
ネットワーク構造
以下にFiDIPのネットワーク構造を示します。
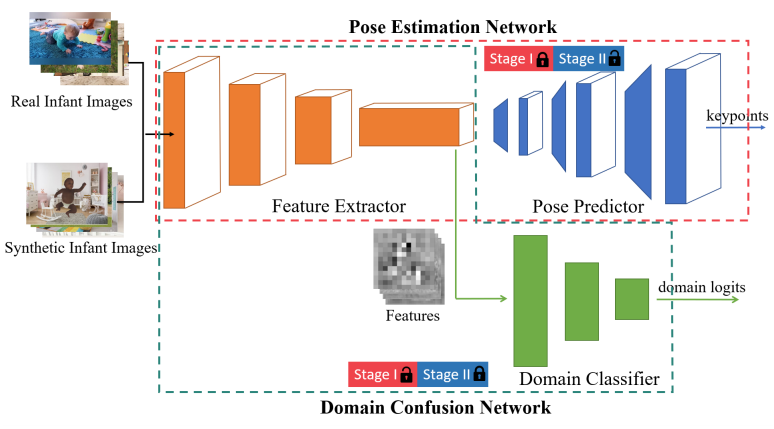
姿勢推定モデルのベースとなっているのはPose-ResNet1で、特徴抽出に使用するFeature Extractor、キーポイントの位置を表すヒートマップを推定するPose Predictorから構成されています。前者はResNet-50で、後者は3つのDeconv層から成っています。
これ加えて、Domain ClassifierがFeature Extractorの下流に接続されています。Domain Classifierは、入力された画像が実画像か合成画像かを推定するのに使用されます。Domain Classifierを通じた敵対的学習によって、Feature Extractorが抽出する特徴が洗練されていくことが期待されます。
訓練手順
訓練の手順は大きく2つのステップからなります。
1つ目のステップでは、全体の事前学習が行われます。
姿勢推定モデル部分は、COCOデータセットで訓練します。また、Domain ClassifierはCOCOデータセットと、合成データセットであるSURREALデータセット2を使用して訓練します。いずれのデータセットも、主に大人データセットになっており、幼児はほとんど含まれていません。Domain Classifierは、実画像なのか合成画像なのかを分類できるように訓練されます。
2つ目のステップでは、以下の2つの処理を繰り返すことで、幼児用の姿勢推定モデルを訓練していきます。
Stage 1では、Feature Extractorを固定し、Domain Classifierを幼児むけにファインチューニングします。つまり、SyRIPデータセットに含まれる現実の画像と合成画像を見分けられるように訓練します。
Stage 2では、Domain Classifierを固定し、Feature ExtractorとPosePredictorを訓練します。Domain ClassifierはGradientReversalLayerによって接続され、敵対的学習に使用されます。これにより、現実の画像と合成画像を見分けるのに必要な特徴の抽出を抑制し、姿勢推定に本質的な特徴を抽出できるようにFeature Extractorの訓練します。また、Feature Extractorの低次レイヤーのパラメータは固定し、高次レイヤーのみを効率的に訓練します。
Domain Classifierは単純な分類モデルなので、クラスエントロピー損失が使用されます。Pose Estimatorの出力には推定されたヒートマップの平均二乗誤差を使用します。
データセットの構築
幼児の姿勢推定のための既存のデータセットとして、MINI-RGBD3というデータセットがあります。このデータセットは、RGBDという名称から明らかなように、深度もデータとして与えられており、これを利用した先行研究がいくつか存在します。しかし、このデータセットは12の合成幼児モデルに対してポーズのシーケンスが付与されおり、現実の幼児の取りうるポーズとしては、多様性が欠けていると指摘されています。MINI-RGBDのポーズの多様性を表す図で、首から股のキーポイントを固定したときに、その他の関節がどのように分布しているのかを表したものです。

これに比べて、本論文で提案しているSyRIPデータセットでは、この分布は以下のようになっています。上段は実画像中のポーズの分布を、下段は合成画像のポーズの分布を表しています。先ほどのMINI-RGBDと比べると、SyRIPではある程度複雑なポーズが合成画像にも含まれるように注意して構築されていることがわかります。

SyRIPは、700枚の幼児画像とそれに対するアノテーション、および1000枚の合成画像から構成されています。実画像のうち訓練に使用するのは200枚で、残りの500枚は評価のために残されます。これらの実画像は、Google検索とYoutubeから抽出され、COCOスタイルのキーポイントをアノテーションしています。
合成画像の作成には、幼児に特化した3次元線形モデルであるSMIL4を使用しています。SMILはSMPL5をもとに構築された$K=23$個の関節からなる、幼児の3次元形状を6890個の頂点で表現するモデルです。下図は、SMILを提案している論文中の図を引用したものですが、Kinectを用いて実際の幼児の動きを撮影し、それに対してSMPLをフィットさせ、PCAによるパラメータの潜在的な表現を分析することで、少数のパラメータで幼児のポーズや体型を表現できるようにしているものです。SMILは、ポーズを表す係数$\theta \in \mathbb{R}^{3(K+1)}$と体型を表す$\beta \in \mathbb{R}^{20}$で制御されます。

合成画像中の幼児のポーズは、実画像中のポーズをベースに構築されます。アノテーション済みの実画像にSMILモデルをフィットさせ、得られた3次元モデルに様々なテクスチャ、背景、カメラ位置、照明を適用することで合成画像を作成します。SMILのフィッティングには、SMPLify-X6というSMPLむけに提案されたフィッティングの手法が使用されます。背景画像は幼児が居てもおかしくないシチュエーションのものがLSUNデータセットから600枚選ばれています。
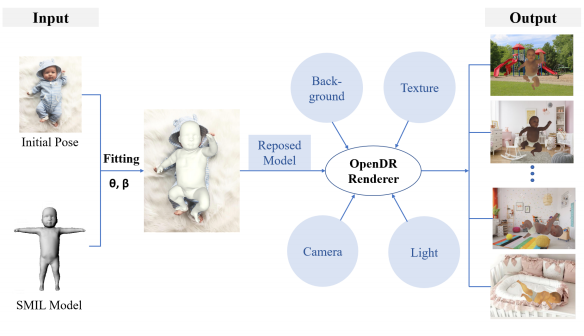
このような方法で作られた合成画像は、実際には質の悪いものも多く、最終的には人手で1000枚選んで使用しています。
実験結果
既存の先端的な姿勢推定モデルとFiDIPを比較するために、3つのデータセットで実験を行っています。ひとつは、COCO2017のValidationセットで、幼児はほとんど含まれていません。次にSyRIPに含まれる700枚の実画像のうち、評価用に取っておいた500枚の画像からなるSyRIP_Test500です。最後が、SyRIP-Test500のうち特に複雑なポーズをとっている画像100枚を集めた、SyRIP-Test100です。
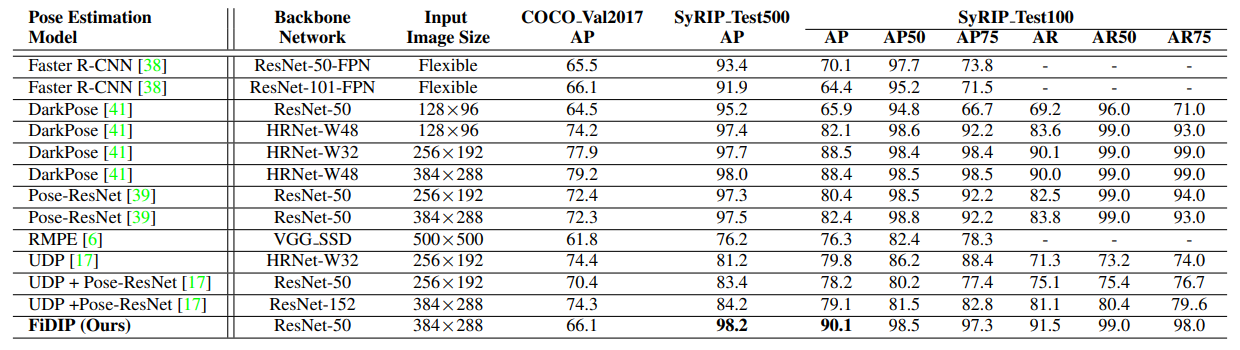
いずれの手法と比べても、FiDIPは幼児に対して高精度な姿勢推定ができているといえます。
まとめ
幼児専用の姿勢推定モデルFiDIPを提案している論文を読みました。
FiDIPの構造や訓練手順はそこまで特殊なものではないですが、データセットであるSyRIPの構築に大きな労力が割かれている研究でした。SMPLは以前から知っていたのですが、まさか幼児専用の3次元モデル表現であるSMILのようなものは想像できていなかったので驚きでした。
-
Kocabas, Muhammed, Salih Karagoz, and Emre Akbas. "Multiposenet: Fast multi-person pose estimation using pose residual network." Proceedings of the European conference on computer vision (ECCV). 2018. ↩
-
Varol, Gul, et al. "Learning from synthetic humans." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. ↩
-
Hesse, Nikolas, et al. "Learning an infant body model from RGB-D data for accurate full body motion analysis." International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2018. ↩
-
Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." ACM transactions on graphics (TOG) 34.6 (2015): 1-16. ↩
-
Pavlakos, Georgios, et al. "Expressive body capture: 3d hands, face, and body from a single image." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019. ↩