スタンバイアドベントカレンダー2日目です!
スタンバイの求人検索機能は検索エンジンとしてVespaを採用しています。
Vespaには検索エンジンの開発運用のための機能が多く用意されており、本記事ではParent-Childという機能について紹介します。
Vespa導入についてはStanby Tech Blogをご参照ください↓
 正規化と検索エンジン
正規化と検索エンジン
カテゴリとニュース記事の関係のような階層関係を持つエンティティをデータストアに格納するケースです。
従来のRelational Databaseではテーブル同士を外部キーで紐付けて正規化を行います。
テーブル結合することで必要なデータを参照する事ができます。
これでアプリケーションの要件を満たせるならば、シンプルな解決策です。
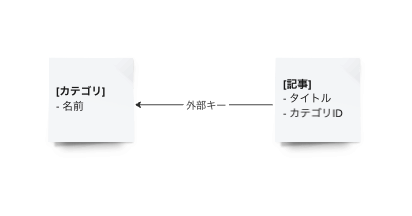
一方、複数ノード構成の検索エンジンに格納する場合はどうでしょうか?
複数のノード間でデータ同士の依存があると、スケールアウト・インの度にデータの入れ替えを行う必要があります。
データの入れ替えを避けるためには冗長なデータ構成をドキュメントに持つ必要があります。

冗長なデータ構成を持った場合、データ更新時(feed)のパフォーマンスが課題になります。
依存先のデータが更新されると、関連するドキュメントを全てを走査して更新するため時間がかかってしまいます。
VespaではParent-Childという機能で親子関係にある2種類のドキュメントを関連付けることができます。
親ドキュメントの更新をするだけで子ドキュメントへ変更を反映でき、冗長なデータ構成時の課題を解決しています。
完全な正規化を行っている訳ではないため、Vespaの公式ブログでは A pragmatic middle ground(実用的な妥協案)としてParent-Childを紹介しています。
 どのように実現されているか?
どのように実現されているか?
スキーマ定義で referenceを使うことでドキュメント間の紐づけが可能です。
子ドキュメントは importで親の要素を参照して自身の要素として使うことができます。
## category.sd
schema category {
document category {
field name type string {
indexing: attribute
}
}
}
## news.sd
schema news {
document news {
field category_ref type reference<category> {
indexing: attribute | summary
}
}
import field category_ref.name as category_name {}
}
またrefで指定される親ドキュメントとなるスキーマはglobal として定義する必要があります。
全コンテンツノードに反映されるのでスケールアウト、イン時に個別のデータの依存を考慮する必要がなくなります。

 Parent-Childの特徴
Parent-Childの特徴
-
Cascade削除は行われない
親ドキュメントが削除されても子はそのままです。
importした項目は要素なし扱い※になります。 -
多階層の親子関係が定義可能
親子関係かつ一方向での参照ならば、多階層での定義が可能です。
※検索条件として参照すると必ずfalseになるので注意。
 導入時の注意点
導入時の注意点
-
親子ドキュメント数の差分がある場合に有効
検索時、feed時ともに親ドキュメント数が子に対して十分に少ない場合にパフォーマンスの向上が見込まれます。 逆に件数の差分がないと冗長化した場合と変わらないことがVespaの公式ブログで紹介されています。 -
Globalドキュメントによる制約
Globalドキュメントは全コンテンツノードに格納されるため、メモリ容量を圧迫する可能性があります。
コンテンツノードのスケールアウト時には親ドキュメントが全て同期されるまでクエリが処理を待つことになります。
 ハンズオン
ハンズオン
ローカルでVespa環境を構築して、Parent-Childの機能を試してみましょう!
Vespa公式のチュートリアルを利用して、カテゴリ-ニュース記事を検索してみます。
親ドキュメントの更新が子ドキュメントに反映されるところまでを見てみます。
事前準備
1. vespa-cliのインストール
$ brew install vespa-cli
2. サンプルアプリのClone
$ vespa clone -f news news && cd news
3. DockerのPull&起動
$ docker pull vespaengine/vespa
$ docker run --detach --name vespa --hostname vespa-tutorial \
--publish 8080:8080 --publish 19071:19071 --publish 19092:19092 \
vespaengine/vespa
4. サンプルアプリのデプロイ
$ vespa deploy --wait 300 app-1-getting-started
Waiting up to 5m0s for deployment to converge...
Waiting up to 5m0s for cluster discovery...
Waiting up to 5m0s for container default...
5. データfeed&query実行
$ vespa feed -t http://localhost:8080 doc.json
→ OK
$ vespa query -v 'yql=select * from news where true'
→ Hello World!のドキュメントが表示されたら準備完了!
スキーマ定義の変更
news/app-1-getting-started以下のファイルを変更します。
1. service.xmlの修正
content定義にcategoryを追加する
<content id='mind' version='1.0'>
<min-redundancy>2</min-redundancy>
<documents>
<document type='news' mode="index"/>
<--追加-->
<document type='category' mode="index" global="true"/>
<--ここまで-->
</documents>
<nodes>
<node hostalias="node1" distribution-key="0" />
</nodes>
</content>
2. category.sdの追加
schema配下に以下のファイルをcategory.sdという名前で作成する。
schema category {
document category {
field name type string {
indexing: attribute | summary
}
}
}
3. news.sdにrefを追加
category_ref, importを追加する。
直接関係ないですが、更新内容を確認するためにdocument-summaryを追加しておきます。
schema news {
document news {
field title type string {
indexing: index | summary
index: enable-bm25
}
field category_ref type reference<category> {
indexing: attribute | summary
}
}
import field category_ref.name as category_name {}
document-summary news-summary {
summary title {}
summary category_name {}
}
}
4. deploy
deployするとスキーマの変更が反映されます。
$ vespa deploy --wait 300 app-1-getting-started
ドキュメントの追加
更新したスキーマに対してドキュメントを追加します。
子ドキュメントから親ドキュメントの項目が参照できていることを確認します。
1. categoryのfeed
# 以下のjsonファイルを作成
$ cat category_doc.json
{ "put": "id:category:category::1", "fields": { "name": "IT" } }
{ "put": "id:category:category::2", "fields": { "name": "sports" } }
$ vespa feed -t http://localhost:8080 category_doc.json
→ 2件追加されたことを確認
2. newsの新規追加feed
# 以下のjsonファイルを作成
$ cat news_doc.json
{ "put": "id:news:news::1", "fields": { "title": "Vespaのニュース", "category_ref": "id:category:category::1" } }
{ "put": "id:news:news::2", "fields": { "title": "AIのニュース", "category_ref": "id:category:category::1" } }
{ "put": "id:news:news::3", "fields": { "title": "スポーツのニュース", "category_ref": "id:category:category::2" } }
$ vespa feed -t http://localhost:8080 news_doc.json
→ 3件追加されたことを確認
3. 確認
$ vespa query -v "yql=select * from news where category_name contains 'IT' " summary="news-summary"
→ 2件の検索結果が表示
ドキュメントの更新
1. categoryの更新feed
IT -> 情報技術に値を変更します。
# 以下のjsonファイルを作成
$ cat category_doc_changed.json
{ "put": "id:category:category::1", "fields": { "name": "情報技術" } }
$ vespa feed -t http://localhost:8080 category_doc.json
→ 1件更新
2. 確認
子ドキュメントに反映されていることを確認する。
$ vespa query -v "yql=select * from news where category_name contains '情報技術' " summary="news-summary"
→ 2件の検索結果が表示 & category_nameの変更が確認できればOK
ハンズオンは以上となります。
シンプル定義で実現できることがわかります。
 おわりに
おわりに
VespaのParent-Childについての説明およびハンズオンを紹介しました。
スタンバイ社内での活用事例もあるので、今後使ってみてどうだったか?を共有したいです。
まだまだVespaは日本でメジャーになっていないので、これからも発信を続けていきたいと思います!
最後までお読みいただきありがとうございました!
参考