目的
Azure Cognitive Searchを使用して、Azure Blob Storage内のJSONファイルにクエリを行う
概要

主な構成要素: データソース、インデクサー、インデックス
データソースに対してインデクサーでクロールを行い、インデックスを生成する
生成されたインデックスに対してクエリを行う

JSONデータの準備
以下のJSONデータをAzure Blob Storageに格納する
[
{
"id": 1,
"category": "category1",
"family": "AndersenFamily",
"lastName": "Andersen",
"address": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"creationDate": 1431620472,
"timestamp": "2021-08-13T09:01:19.443224Z",
"isRegistered": true
},
{
"id": 2,
"category": "category2",
"family": "WakefieldFamily",
"lastName": "Wakefield",
"address": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"creationDate": 1431610472,
"timestamp": "2021-08-11T09:24:20.235524Z",
"isRegistered": false
},
{
"id": 3,
"category": "category1",
"family": "MillerFamily",
"lastName": "Miller",
"address": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"creationDate": 1431600472,
"timestamp": "2021-05-07T12:22:19.123456Z",
"isRegistered": true
}
]
コンテナ: search-source
ディレクトリ: Directory-1
ファイル: test-data.json

データのインポート
データのインポートからデータソース、インデックス、インデクサーの設定を行う

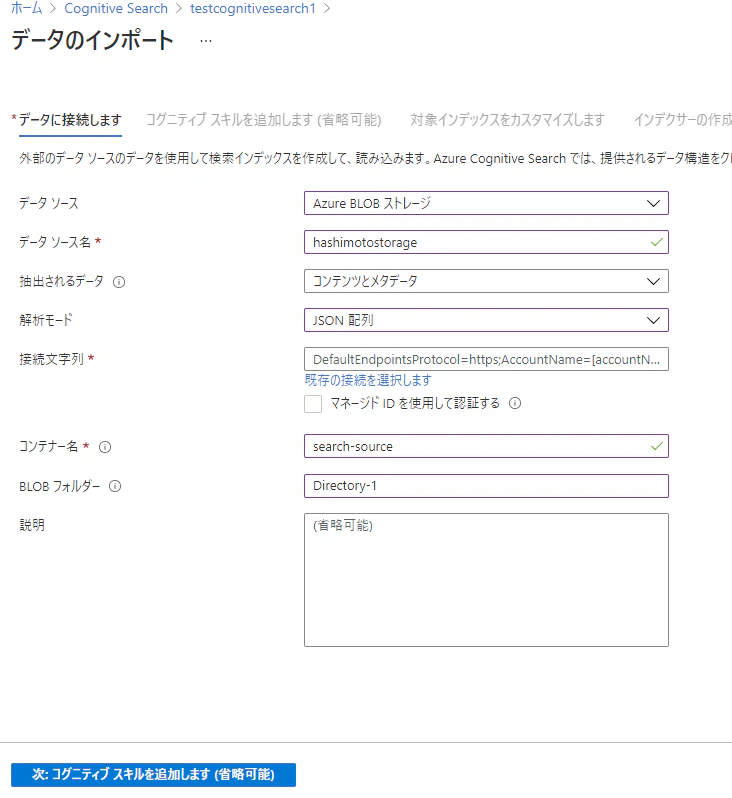
データソース
データのインポート元(Azure Blob Storage)の情報を入力する
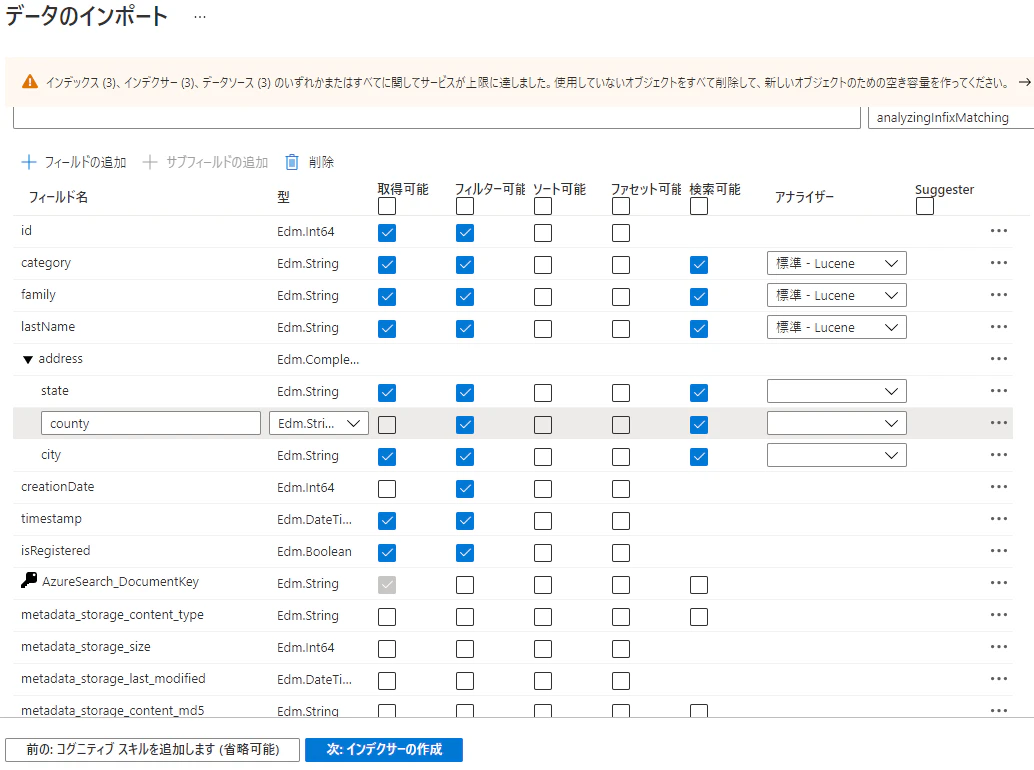
インデックス
データソース内に格納したJSONデータの各フィールドに対して、
検索結果に含めるか、フィルター可能、検索可能等のオプションを設定する
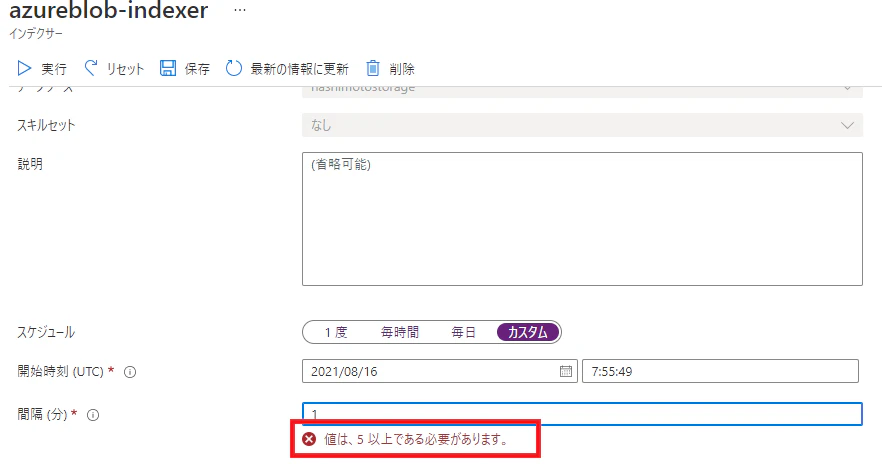
インデクサー
データソースにクロールするスケジュール設定を行う

ちなみにスケジュールの最短周期は5分
クロールが完了するとデータソースに含まれるドキュメント数等が表示される

生成されるインデックスを格納するストレージサイズはエディションによって異なる
Azure Cognitive Search の価格

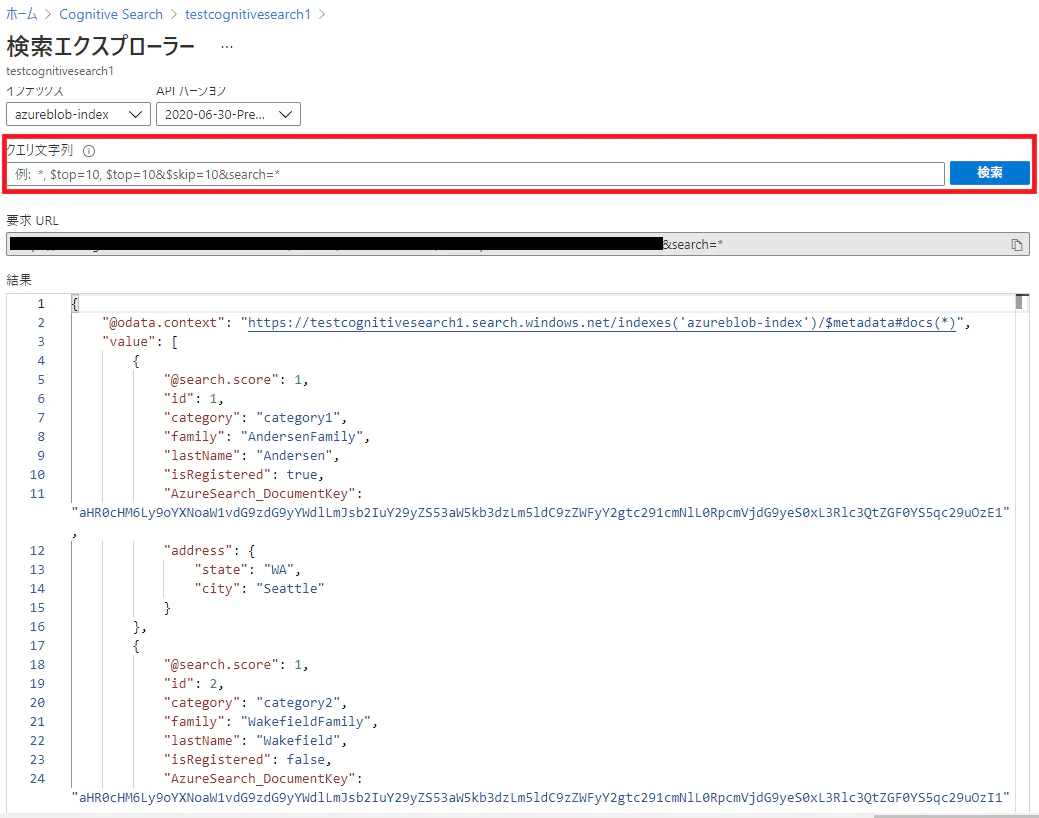
Azure Portalでのクエリ

クエリ文字列を空の状態で検索ボタンをクリックすると結果に全データが返却される
ただし、インデックスの設定時に取得可能にチェックを入れなかったcreationDate等のフィールドは含まれない
文字列検索
クエリ文字列にsearch=category2と入力し検索ボタンをクリックすると結果にcategory2が含まれるドキュメントのみが返却される
ただし、インデックスの設定時に検索可能にチェックを入れたフィールドのみが検索対象

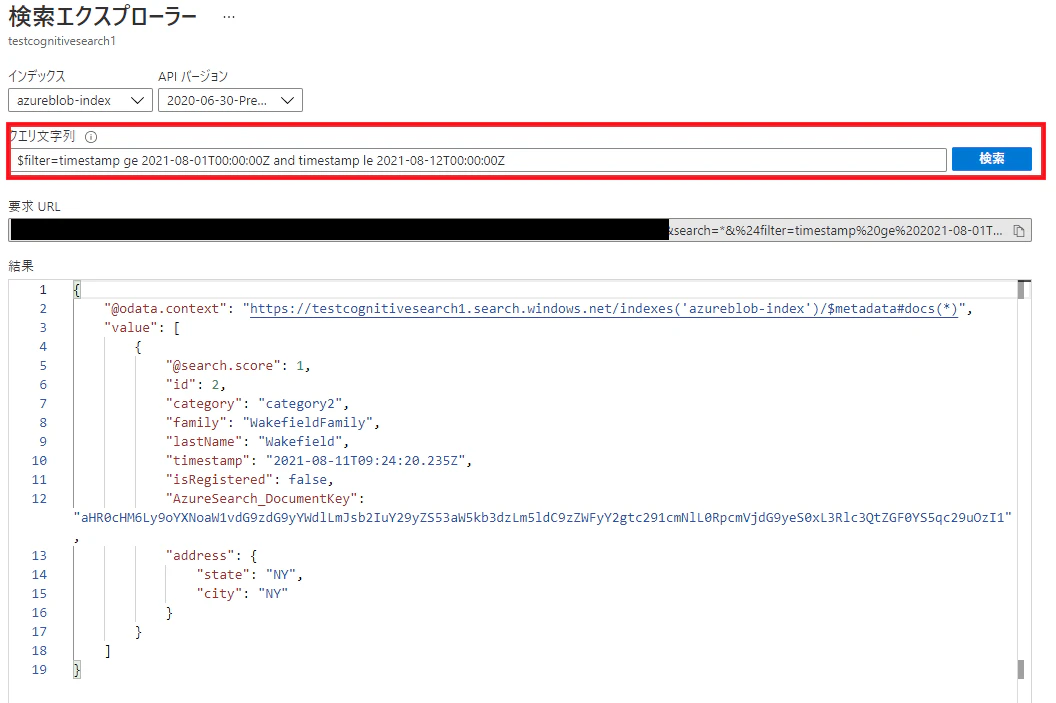
datetimeのフィルター
クエリ文字列に$filter=timestamp ge 2021-08-01T00:00:00Z and timestamp le 2021-08-12T00:00:00Zと入力し検索ボタンをクリックすると結果にtimestampが2021-08-01T00:00:00Z以上2021-08-12T00:00:00Z以下のドキュメントのみが返却される
filter構文については以下参照
Azure Cognitive Search での OData $filter 構文
Azure Cognitive Search の OData 比較演算子 - eq、ne、gt、lt、ge、le
ただし、インデックスの設定時にフィルター可能にチェックを入れたフィールドのみがフィルター対象
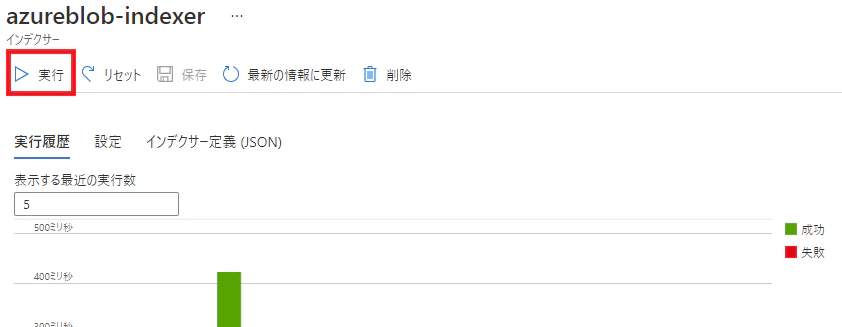
インデクサーの即時実行
データソースに追加されたデータを読み込むためには、インデクサーのスケジュール実行または、手動実行を行う
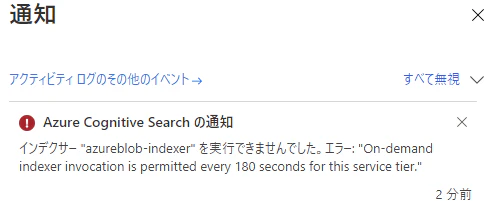
ただし、手動による即時実行は180秒以上間隔をあける必要がある
Azure Functions(Python)でのクエリ
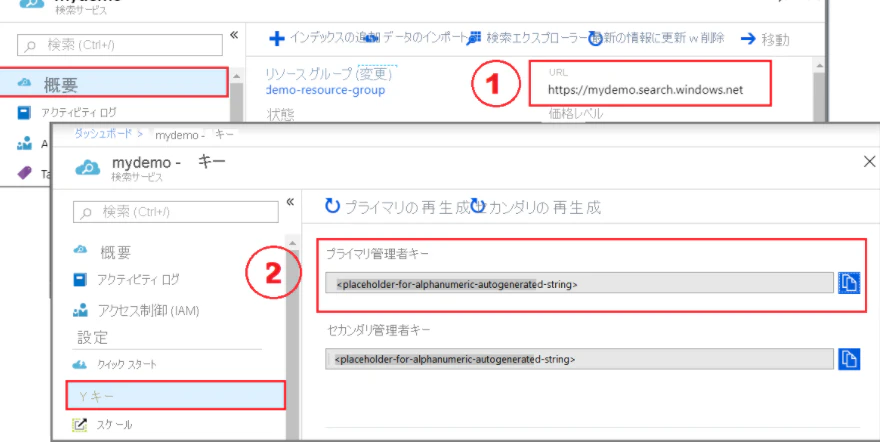
Azure PortalからAzure Cognitive SearchのエンドポイントURLと、キーを取得する
import os
import logging
import azure.functions as func
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
endpoint = os.environ['COGNITIVE_SEARCH_ENDPOINT']
admin_key = os.environ['COGNITIVE_SEARCH_ADMIN_KEY']
index_name = 'azureblob-index'
try:
search_client = SearchClient(endpoint=endpoint,
index_name=index_name,
credential=AzureKeyCredential(admin_key))
except Exception as err:
logging.info(f'Connect Error: {err}')
return func.HttpResponse(status_code=500)
try:
# search=*
logging.info('search=*')
results = search_client.search(search_text='*', include_total_count=True)
logging.info(f'Number of data: {results.get_count()}')
for result in results:
logging.info(result)
# search=category1
logging.info('search=category1')
results = search_client.search(search_text='category1', include_total_count=True)
logging.info(f'Number of data: {results.get_count()}')
for result in results:
logging.info(result)
# $filter=timestamp ge 2021-08-01T00:00:00Z
logging.info('$filter=timestamp ge 2021-08-01T00:00:00Z')
results = search_client.search(search_text='*', filter='timestamp ge 2021-08-01T00:00:00Z', include_total_count=True)
logging.info(f'Number of data: {results.get_count()}')
for result in results:
logging.info(result)
# $filter=timestamp ge 2021-08-01T00:00:00Z and timestamp le 2021-08-12T00:00:00Z
logging.info('$filter=timestamp ge 2021-08-01T00:00:00Z and timestamp le 2021-08-12T00:00:00Z')
results = search_client.search(search_text='*', filter='timestamp ge 2021-08-01T00:00:00Z and timestamp le 2021-08-12T00:00:00Z', include_total_count=True)
logging.info(f'Number of data: {results.get_count()}')
for result in results:
logging.info(result)
except Exception as err:
logging.info(f'Search Error: {err}')
return func.HttpResponse(status_code=500)
return func.HttpResponse(
'This HTTP triggered function executed successfully.',
status_code=200
)
search_textは必須パラメータのため検索が不要な場合でも'*'を指定している
使用クラス:SearchClient.search
SearchIndexerClient.run_indexerを使用してインデクサーの実行が可能だが、
即時クロールが完了するわけではないためクエリ前に実行してもクロール結果は反映されない