この記事は,最近読んだ論文(ICML 2020採択)の紹介&簡単な実装・実験記事です.
タイトルは"Explainable k-Means and k-Medians Clustering"で,arxivはこちらからどうぞ.
本論文は,クラスタリングの手法であるk-meansまたはk-mediansに対して,決定木を用いてクラスタリングのルールを得るというアプローチを提案しています.決定木で説明可能なクラスタリングを得るというのは,先行研究としてはいくつか既にあるのですが,この論文の貢献は,初めて理論的保証付きのk-means/k-mediansを近似するアルゴリズムを提案し,その上界と下界を示しています.この論文の(この記事よりかは)詳しいまとめに関して興味がある方は,是非以下のリンクから概要だけでも読んでみてください.
論文のまとめ
本記事では,この論文では実験などは全くなかったため,提案されたアルゴリズムを簡単にですが実装し,それらを確認してみようと思います(コード).
この論文では,以下の図のように,k-means/k-mediansを決定木で近似します.
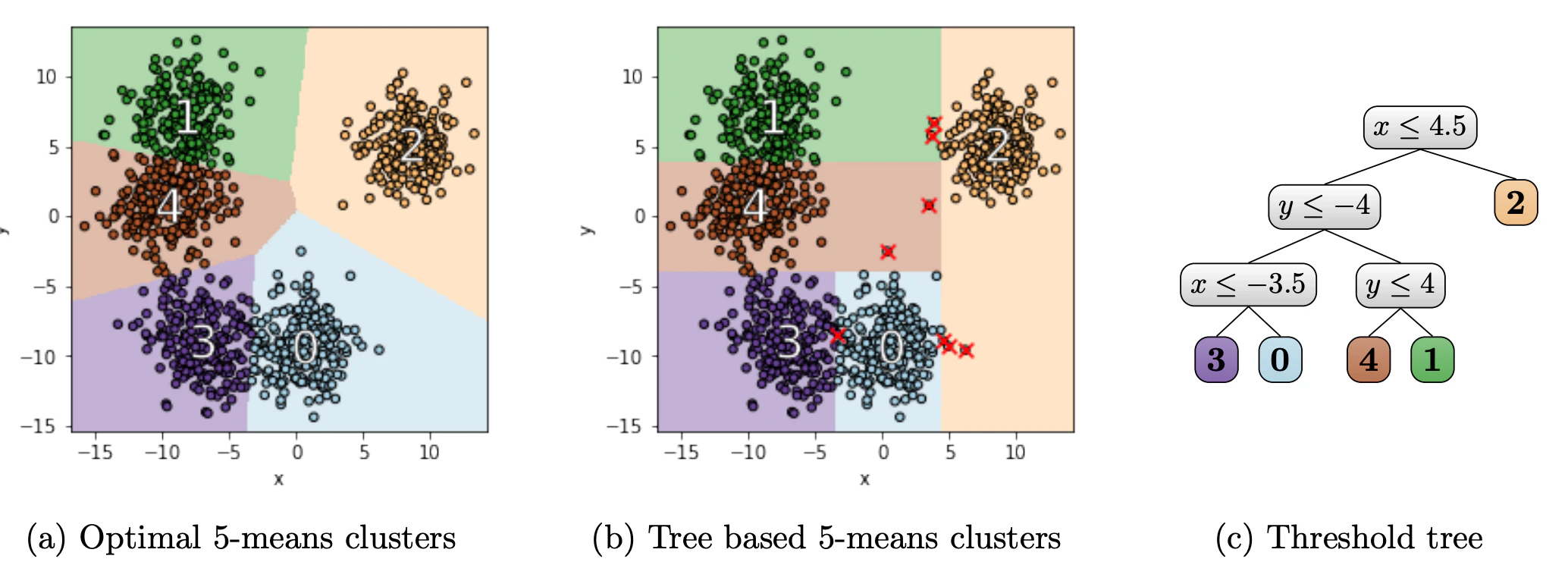
クラスタ数を$k$としたとき,作成される木は葉を$k$個として,それぞれの葉にクラスタが振られるようにします.そうすることで,$k-1$個の中間ノードによる木が作成されるので,ある程度の説明性が担保できます(木が深くなりすぎない).
論文では,$k=2$と$k>2$の2つの場合について,論じています.まず,$k=2$の場合,葉の数2,非終端ノード1(rootノードだけ)なので,1つの分割ルールを得ればいいことになります.これをこの論文では,ソートと動的計画法によって,最適な特徴量の次元$i$と閾値$\theta$を得るアルゴリズムを提案しています.以下のような感じです.ソートと動的計画法によって,効率よく求められると主張されています.詳しくは論文まとめのpdfを見てみてください.

これをpythonで実装しました.ノートブックはここからどうぞ.2つのデータセットに対して行いましたが,この記事内では1つだけ書きます.まず,データセットを変数Xに入れます.
# First dataset
# 生徒の国語・数学・英語の各得点を配列として与える
X = np.array([
[ 80, 85, 100 ],
[ 96, 100, 100 ],
[ 54, 83, 98 ],
[ 80, 98, 98 ],
[ 90, 92, 91 ],
[ 84, 78, 82 ],
[ 79, 100, 96 ],
[ 88, 92, 92 ],
[ 98, 73, 72 ],
[ 75, 84, 85 ],
[ 92, 100, 96 ],
[ 96, 92, 90 ],
[ 99, 76, 91 ],
[ 75, 82, 88 ],
[ 90, 94, 94 ],
[ 54, 84, 87 ],
[ 92, 89, 62 ],
[ 88, 94, 97 ],
[ 42, 99, 80 ],
[ 70, 98, 70 ],
[ 94, 78, 83 ],
[ 52, 73, 87 ],
[ 94, 88, 72 ],
[ 70, 73, 80 ],
[ 95, 84, 90 ],
[ 95, 88, 84 ],
[ 75, 97, 89 ],
[ 49, 81, 86 ],
[ 83, 72, 80 ],
[ 75, 73, 88 ],
[ 79, 82, 76 ],
[ 100, 77, 89 ],
[ 88, 63, 79 ],
[ 100, 50, 86 ],
[ 55, 96, 84 ],
[ 92, 74, 77 ],
[ 97, 50, 73 ],
])
提案手法でk-meansを近似します(k-mediansはやってません).
# K-meansクラスタリングをおこなう
kmeans_model = KMeans(n_clusters=2, random_state=10).fit(X)
# 分類先となったラベルを取得する
labels = kmeans_model.labels_
# 提案手法による近似アルゴリズムで取得する
bests_split = optimal_threshold_2means(X)
approx_labels = clustering_2means_by_tree(bests_split,X)
print(bests_split)
print(approx_labels)
実行結果

上の結果はつまり,0番目の特徴量で閾値70として分割する決定木が最適だということです.では,この決定木のルールによるクラスタリングはどのくらいk-meansのクラスタリングを近似しているのでしょうか.以下が計算コードです.
approx_score(approx_labels,kmeans_model,X) #近似アルゴリズムのコスト / k-meansのコスト
実行結果

上の結果は,クラスタ数2におけるk-meansと同じクラスタリング結果を,0番目の特徴量が70以下か否かのルールでクラスタリングできていることになります.つまり,この国語,数学,英語のデータセットに対して,ある生徒が,「なぜ僕はクラスタ0になったんですか?」と質問をしてきたとき,「それは君の国語の点が70以下だからだよ」と説明してあげることができます.
この論文の1つの良さは,理論的保証つきの近似アルゴリズムを提案しているところです.著者らはk-means($k=2$)において,以下の式を満たすような最適な1ルールによる決定木近似(分割$\widehat{C}$)が存在することを証明しています.つまり,定数倍の近似精度であるような分割ルールが存在するということです.次元がいくら大きくてもです.この証明は,ホールの定理をうまく使って証明しています.
\operatorname{cost}(\widehat{C}) \leq 4 \cdot \operatorname{cost}(o p t)
この論文では,$k=2$について論じた後,$k>2$について論じています.$k>2$の場合のアルゴリズムは以下になります.これの流れや実験などに興味がございましたら,論文のまとめとコードをみてみてください.

THANK YOU