最近担当したAWS案件で大量の生成AIトークンを扱う要件があり、Bedrockのクオータ超過により発生する例外への対応方法を比較検討しましたので、その事例を紹介します。
1.背景
本件はこれまで人手で行ってきた電子帳票のレビューを機械化したいというニーズが背景にあり、PDFファイルからメタデータや画像等の情報を抽出・加工し、Bedrockの基盤モデルに投入して分析させるワークフローを検討していました。分析のための基盤モデル呼び出しは7パターン、入力プロンプトのトークンサイズは約10,000から160,000に及びました。このワークフローの基盤モデル呼び出し部分を抽出して単純化した構成を下図に示します。
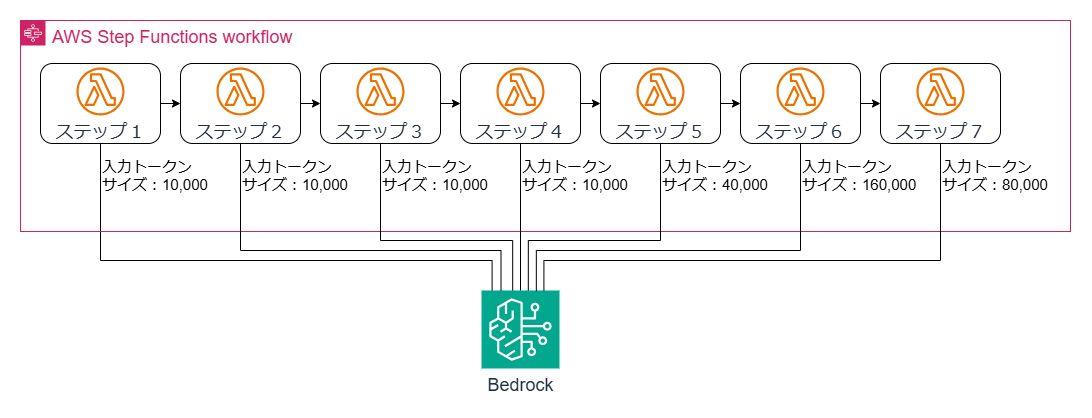
更に、ワークフローを最大で33件同時にスタートして完走できること、国内リージョン内で処理が完結することという非機能要件を満たす必要がありました。
2.Bedrockのサービスクオータの制約
まず基盤モデルの選択ですが、今回はAnthropic Claude 3.5 Sonnet v1を選択しました。検討時点(2025年2月)の東京リージョンでテキストと画像を入力できるモデルは下表の4種類がありましたが、1と3はクロスリージョン推論の処理が国内で完結しないため不採用、4は分析精度面で期待を下回ったため不採用としました。
| # | ベンダー | モデル | 備考 |
|---|---|---|---|
| 1 | Anthropic | Claude 3.5 Sonnet v2 | クロスリージョン推論のみ利用可能 |
| 2 | Anthropic | Claude 3.5 Sonnet | |
| 3 | Anthropic | Claude 3 Sonnet | クロスリージョン推論のみ利用可能 |
| 4 | Anthropic | Claude 3 Haiku |
次に、Claude 3.5 Sonnetモデルのサービスクオータを確認します。ユーザーガイドより本件のワークフローの実行に影響するものを下表に抜粋しました。
参照:https://docs.aws.amazon.com/ja_jp/general/latest/gr/bedrock.html#limits_bedrock
| 名前 | 東京リージョンのサービスクオータ |
|---|---|
| Anthropic Claude 3.5 Sonnet のオンデマンド InvokeModel リクエスト/分 | 20 |
| Anthropic Claude 3.5 Sonnet のオンデマンド InvokeModel トークン/分 | 200,000 |
実際の動作を観察したところ「リクエスト/分」は1分あたりの累計リクエスト数というより同時実行数を制限しているように見えましたが、いずれにしても最大33件同時スタートという要件に対してはキャパシティー不足となります。「トークン/分」の200,000という上限も今回のケースのトークンサイズと並列実行数に対してキャパシティー不足です。例えば160,000トークンのリクエストはほぼ1件/分しか処理できないことになります。
3.サービスクオータ超過時のBedrockの例外応答と対策
サービスクオータの上限を超えてInvokeModelリクエストを投入した時、BedrockはThrottlingException例外を返してリクエストを失敗させます。
参照:https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/troubleshooting-api-error-codes.html#ts-throttling-exception
ThrottlingExceptionを受け取ったときの対策としては、クオータ超過状態が解消した頃にInvokeModelリクエストを再試行する方法が考えられます。今回のワークフローのアーキテクチャはStepFunctionsとLambda関数で構成するので、Lambda関数のタイムアウトの上限の15分以内にクオータ超過状態が解消しない可能性を考慮し、再試行はStepFunctionsの仕組みを利用することにします。そのための設定例を紹介します。
StepFunctions側の設定
Lambda関数を呼び出すステップのステート定義で、RetryフィールドのErrorEqualsにThrottlingExceptionを追加し、リトライ戦略(再試行間隔、最大試行回数など)を定義します。以下に例を示します。
参照:https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/concepts-error-handling.html
"Retry": [
{
"ErrorEquals": [
"ReadTimeoutError",
"ServiceUnavailableException",
"ThrottlingException",
"TypeError",
"Sandbox.Timedout"
],
"IntervalSeconds": 60,
"MaxAttempts": 100,
"BackoffRate": 1,
"JitterStrategy": "NONE"
}
],
Lambda関数側の設定
Lambda関数側(Pythonで実装)では、BedrockのInvokeModel呼び出しで受け取った例外をそのままLambda関数の外へスロー(Pythonではraise)します。Bedrockの呼び出しにはConverseを使っていますがクオータはInvokeModelと共通です。
from botocore.exceptions import ClientError
:
:
try:
# Converse APIを呼び出し
response = bedrock_client.converse(
modelId=model_id,
messages=messages,
inferenceConfig=inferenceConfig
)
:
:
except ClientError as e:
# ThrottlingExceptionなどの例外をそのままraise
print(f"Bedrock API エラー: {str(e)}")
raise e
4.リトライ戦略の検証
次に本件のワークフローにおけるリトライ戦略の有効性を探ることにしました。
ワークフローは冒頭に示したとおり、7個のステートを一列に連結したStepFunctionsステートマシンで、各ステートでLambda関数を起動し、Lambda関数の中でBedrockのConverse APIを実行します。
ユーザーガイドはThrottlingExceptionの解決策として「エクスポネンシャルバックオフとランダムジッターで再試行」することを推奨しているので、この推奨パターンも含めて下表の3パターンのリトライ戦略を試しました。
| # | IntervalSeconds | BackoffRate | JitterStrategy | リトライ戦略 |
|---|---|---|---|---|
| 1 | 60 | 1 | NONE | 等間隔(60秒)でリトライ |
| 2 | 60 | 2 | NONE | エクスポネンシャルバックオフ |
| 3 | 60 | 2 | FULL | エクスポネンシャルバックオフとランダムジッターを併用 |
上記の設定を実装したワークフロー(StepFunctionsステートマシン)を実際に33個一斉起動し、その結果をワークフローの実行時間と、実行中に発生したリトライの回数の観点で整理してみます。
| # | 平均実行時間[秒] | 最長実行時間[秒] | 最短実行時間[秒] |
|---|---|---|---|
| 1 | 2,284.5 | 3,211.5 | 1,126.6 |
| 2 | 2,155.8 | 4,360.9 | 179.0 |
| 3 | 2,390.3 | 5,087.1 | 661.9 |
| # | 平均リトライ回数[回] | 最多リトライ回数[回] | 最少リトライ回数[回] |
|---|---|---|---|
| 1 | 31.2 | 44 | 15 |
| 2 | 10.8 | 15 | 1 |
| 3 | 11.8 | 16 | 8 |
平均実行時間は3パターンともほぼ同じでしたが、平均リトライ回数はエクスポネンシャルバックオフを使わないパターンが使うパターンの約3倍となっていました。平均値ではエクスポネンシャルバックオフによりスループットを下げずにLambda関数呼び出し回数を1/3に削減できたと言えます。
一方で気になる点が2点あります。エクスポネンシャルバックオフを使用すると等間隔でリトライするパターンよりも最長実行時間が長くなる点と、ランダムジッターを併用するとリトライ回数と実行時間が増加する点です。
これらの点の改善策を探るために、ランダムジッターを併用するパターンで最長実行時間を記録したワークフローの処理時間内訳をみてみましょう。

リトライはステップ2とステップ3で発生していました。WAIT時間を見るとエクスポネンシャルバックオフとランダムジッターが効いていることがわかりますが、ランダムジッターはエクスポネンシャルバックオフのWAIT時間から多少短くなる方向に作用しているようです。このためランダムジッターを使用するとThrottlingExceptionの状況が解消しないうちにリトライする確率が上がり、平均リトライ回数が増えるという結果に表れていると考えられます。WAIT時間はIntervalSecondsの値がベースになるので、これを大きくすることによりThrottlingExceptionの状況が解消するまで待つ確率が上がり、リトライ回数が抑えられるかもしれません。
WAIT時間はステップ3の7回目に3,112秒かかっていて、これだけで実行時間(5,087.1秒)の6割を占めています。エクスポネンシャルバックオフの効果でWAIT時間が指数関数的に増えた結果なのですが、ThrottlingExceptionの状況が短時間では解消しないケースではMaxDelaySecondsパラメータを併用してWAIT時間の上限を設定したほうがよさそうです。もし1,000秒が上限として設定されていたら、実行時間は3,000秒程度(等間隔でリトライするパターンと同等)に抑えられていたかもしれません。
以上の分析を踏まえて、エクスポネンシャルバックオフとランダムジッターを併用するパターンを以下の要領で調整して再実行してみましょう。
- IntervalSecondsを90に変更
- MaxDelaySecondsを追加して1000秒を設定
5.リトライ戦略の追加検証
調整後のリトライ戦略を下表に整理しました。
| # | IntervalSeconds | BackoffRate | JitterStrategy | MaxDelaySeconds | リトライ戦略 |
|---|---|---|---|---|---|
| 4 | 90 | 2 | FULL | 1000 | エクスポネンシャルバックオフとランダムジッターを併用(調整版) |
StepFunctionsの定義は次のように修正しました。
"Retry": [
{
"ErrorEquals": [
"ReadTimeoutError",
"ServiceUnavailableException",
"ThrottlingException",
"TypeError",
"Sandbox.Timedout"
],
"IntervalSeconds": 90,
"MaxAttempts": 10,
"BackoffRate": 2,
"MaxDelaySeconds": 1000,
"JitterStrategy": "FULL"
}
],
実行結果は下表のとおりでした。
| # | 平均実行時間[秒] | 最長実行時間[秒] | 最短実行時間[秒] |
|---|---|---|---|
| 4 | 1,946.7 | 3,642.7 | 422.1 |
| # | 平均リトライ回数[回] | 最多リトライ回数[回] | 最少リトライ回数[回] |
|---|---|---|---|
| 4 | 10.5 | 16 | 6 |
パターン3の結果と比べると、最多リトライ回数は同じでしたが、実行時間短縮とリトライ回数削減の効果が確認できました。平均実行時間と平均リトライ時間はパターン1,2も含めた4パターンの中で最善の結果となりました。最長実行時間は等間隔(60秒)でリトライするパターンに比べるとまだ1割ほど長くかかっていますが、パラメータの更なる微調整によりこの1割の短縮も可能でしょう。
6.まとめ
Amazon Bedrockで、大量の生成AIトークンを伴うInvokeModel呼び出しを多数同時に実行し、ThrottlingExceptionで呼び出しが失敗するケースのリトライ戦略を比較検証しました。
ユーザーガイドが推奨するエクスポネンシャルバックオフとランダムジッターだけでも、等間隔(60秒)でリトライするパターンに比べてリトライ回数を削減する効果があることがわかりました。更にWAIT時間の初期値(IntervalSeconds)と上限値(MaxDelaySeconds)も調整することで、トータルでの処理時間を延ばすことなくリトライ回数を削減(Bedrockへの負荷を軽減)できる見通しを示しました。
補足
今回の検証に使用したワークフローの単体での実行時間は約105秒でした。33倍すると3,465秒になります。つまりワークフローを一時点で1件ずつ逐次実行しても、リトライ戦略を駆使して同時実行した場合と同程度のスループットが期待できます。今回のワークフローのシナリオ特有の結果かもしれませんが、逐次化という戦略も十分有効な選択肢といえるでしょう。