あるAWS案件でAmazon Managed Streaming for Apache Kafka (以下MSK)とAmazon Managed Service for Apache Flink(以下Managed Flink)で構成されるデータパイプラインにおけるデータ整合性のための設計を支援したことがありました。その中でも特にManaged Flinkについて掘り下げて検討した内容を整理して紹介します。
下図は検討の叩き台としたデータパイプラインの構成です。Managed Flinkは右から二番目にあります。

左端のアプリがRDSのテーブルを更新(レコードをインサート)すると、MSK ConnectがRDSの更新に反応してデータをMSKのトピックにパブリッシュし、MSKのトピックをサブスクライブしているManaged Flinkがデータを受け取って適宜加工し、右端のRDSのテーブルを更新(データをインサート)する流れになっています。
データ整合性の要件は以下の2点でした。
- データは発生順に宛先に到着すること
- 宛先のRDSでデータの欠落や重複がないこと
1.の要件は、データパイプラインを単線にすることで達成できます。可用性や性能面では不利になりますが本件では許容範囲内でした。
2.の要件に関しては、特に障害発生時のFlinkアプリケーションの動作を詳細に検討しました。Apache Flinkにはアプリケーションが直前のチェックポイントの状態を復元してリスタートする機能があり、ManagedFlinkでもサポートしています。この機能を使う上での考慮点が本記事のメインテーマです。
またFlinkアプリケーションのリスタートに関連して、特定のメッセージで繰り返しリスタートが発生するとリスタートの無限ループに陥るケースが考えられ、その問題の回避策も検討しましたので併せて紹介します。
1.チェックポイント
チェックポイント処理はFlinkアプリケーションのステートを定期的にストレージに書き出しておき、Flinkアプリケーションがエラー等で処理を続行できない時に直前のチェックポイントで保存したステートを復元して処理を再開します。本構成のようにMSKからのメッセージをサブスクライブする場合は、ステートには処理済みメッセージのオフセット情報が含まれるので、Flinkアプリケーションは正確なオフセットから処理を再開できます。
チェックポイントには「At most once」「At least once」「Exactly once」の3種類のモードが存在し、データ整合性のレベルが異なります、今回はメッセージの欠落を容認する「At most once」は検討から外し、残りの2つについて検討しました。
At least onceモードの動作
At least onceモードの理解のために、最新のチェックポイントからの再始動した時のデータ処理の推移を描いてみます。

この図は#100のメッセージが処理された時点でチェックポイントが実行され、その後#103を処理中にFlinkアプリケーションがクラッシュしてチェックポイントの時点から処理をリスタートしたというシナリオを表しています。このとき#101、#102のメッセージは二重にSink処理されます。本件の構成ではRDSに対してメッセージを二重にインサートすることになります。
この動作だけを見るとデータの重複になるのですが、UPSERT(SQL文のオプションでレコードがなければINSERT、あればUPDATEする)という方法を使うことによりRDS上での重複は回避でき、「データの欠落や重複がないこと」という要求を満たせます。
Exactly onceモードの動作
こちらも最新のチェックポイントからの再始動した時のデータ処理の推移を図示します。

Exactly onceモードでは2フェーズコミットを使用してチェックポイントとSink処理(宛先の更新処理)を同期します。宛先(ここではRDS)の更新は同期点(次のチェックポイント)まで可視化されず、エラーが発生すると更新が取り消され(ロールバックされ)ます。チェックポイントで保存されたメッセージのオフセットは最後にSink処理が成功した時点のものになるので、チェックポイントからのリスタートで重複が発生することはありません。したがってこのモードでも「データの欠落や重複がないこと」という要求を満たせます。
2.Exactly onceで2フェーズコミットが使われていることへの考慮点
Apache Flinkのドキュメントには以下の記述があり、基本的にExactly onceを推奨しています。
exactly-once vs. at-least-once: You can optionally pass a mode to the enableCheckpointing(n) method to choose between the two guarantee levels. Exactly-once is preferable for most applications. At-least-once may be relevant for certain super-low-latency (consistently few milliseconds) applications.
super-low-latencyなアプリにはAt-least-onceが向いているとも言っていますが、これはExactly onceで採用している2フェーズコミット処理が複雑で重いからです。
2フェーズコミット処理の複雑さによる不利益には、処理の重さの他に、In-doubt状態での障害回復のデータ整合性保証の難しさという問題があります。
最初に結論を述べておくと、冒頭のパイプライン構成例では、右端のRDSが参加する同期点処理がIn-doubt状態で停止したら、RDSをスナップショットから復元し、スナップショットの時点以降のデータパイプライン処理を再実行して障害発生直前の状態に追いつく手順を用意しておけば、安心してExactly onceモードを採用できます。
下図に2フェーズコミット処理のフローを示しました。タスクマネージャ、ジョブマネージャはManaged Flinkのコンポーネントです。ジョブマネージャのチェックポイント・コーディネータがチェックポイント処理の最後にコミット要求を発行して2フェーズコミット処理を起動します。

2フェーズコミット処理は、二つ以上のリソースにまたがる更新の同期をとる仕組みで、各リソースにコミットの準備を要求するフェーズ1と、更新の確定を要求するフェーズ2で構成されます。
フェーズ1で全リソースから準備完了(Prepared)が返ると、トランザクション・コーディネータはフェーズ2でCommitを要求しますが、ひとつでもPreparedを返さなかった(エラーを返した、タイムアウトした等)場合はフェーズ2でRolebackを要求します。
リソース側からみると、Preparedを返しても次にCommitが来る保証はありませんし、リソース側だけでCommitかRolebackかを判断することもできません。このタイミングでトランザクション・コーディネータに重大障害が発生して処理不能になると、リソース側は先に進むためには判断根拠がないままCommitかRolebackの判断を下さなければなりません。この時本来CommitすべきものをRolebackしてしまうかもしれませんし、その逆もあり得るので、データ整合性は保てないかもしれません。これがIn-doubt状態での障害回復の問題です。
In-doubtの状態は一瞬ですし、そのタイミングでトランザクション・コーディネータの重大障害に遭遇する可能性は極めてゼロに近いと言えますが、ゼロではありません。対策としては代替の回復手段を用意しておけばよくて、データパイプラインではデータを再送する手があります。それが先に述べた結論です。
3.リスタートの無限ループへの対策
特定のメッセージが原因でFlinkアプリケーションがクラッシュし、直前のチェックポイントの状態からリスタートする場合、同じメッセージでまたクラッシュしてリスタートを繰り返す無限ループに陥る可能性が考えられます。
同じメッセージでクラッシュを繰り返す状態を検知して、そのメッセージをスキップできれば無限ループは回避できます。
本件のケースではメッセージが順序番号を持っているので、Flinkアプリケーションの処理の最初でメッセージの順序番号と繰り返し回数を外部のテーブルに保存し、その記録をもとに繰り返しを判定する仕組みを考えたので以下に紹介します。
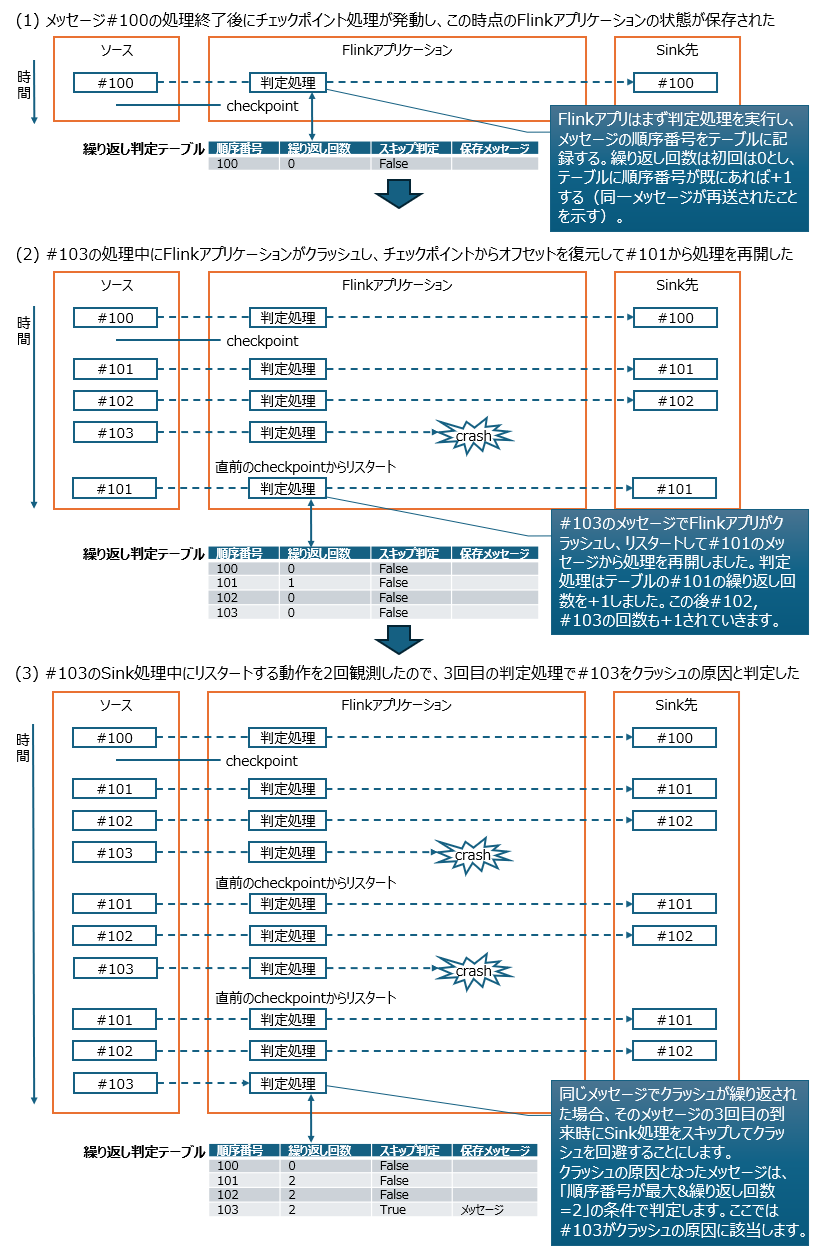
この例では#103のメッセージがクラッシュの原因ですが、その特徴は「チェックポイントからのリスタートにより繰り返し到来するメッセージの中で最後に到来するもの(順序番号が最大のもの)」と定義できます。繰り返し判定テーブルの順序番号が最大値の行が「最後に到来するもの」なので、この行の繰り返し回数の値が閾値に到達したらそのメッセージをスキップする仕掛けにしました。
ちなみに検証では繰り返し判定テーブルをRDSに置いてFlinkアプリケーションからJDBCでアクセスしましたが、Sink処理とはトランザクションスコープが分かれるので、Sink処理がロールバックしても繰り返し判定テーブルの更新は残りました。これはAt least onceモード、Exactly onceモードとも同様の結果でした。
4.まとめ
MSKとManaged Flinkによるデータパイプラインにおいて、データ整合性を確保するための二つの要件(データの発生順到着、欠落・重複の防止)について検討しました。Managed Flinkのチェックポイント機能におけるAt least onceモードとExactly onceモードの両方で要件を満たすことが可能であることを確認し、Exactly onceモードを採用する場合は、2フェーズコミット処理のIn-doubt状態での障害に備えてデータ再送による回復手順を用意することを推奨しました。また、特定メッセージによるクラッシュとリスタートの無限ループを防ぐための対策も紹介しました。