はじめに
本稿は2020年度の映像メディア学の課題として出題されたものです.
課題は2016~2020年の間にCVPR等のトップ会議・ジャーナルに投稿された内容を自力で実装せよ,さらにオンライン上のブログにて説明を行えというものでした.
今回私はDenseNetを選びgithubに実装を,ここに説明を公開します.
DenseNetとは
DenseNetは2016年にCVPRに投稿されたDensely Connected Convolutional Networks内で提案された画像のクラス分類問題を解くCNN(Convolutional Neural Networks)です.
ベンチマークサイトによれば,外部データを用いないCIFAR-10データセットの分類精度において2016後半にSOTA(state-of-the-art)になりました.
当時はより深くより深層にすることが性能向上の鍵という風潮が強い一方,勾配消失問題への対策を求められている時期であったと記憶しています.その勾配消失問題への解決案として有名なのは,CNNにおいてはResNet,RNN(Recurent Neural Network)においてはLSTM,もっと基礎で言ったら非線型関数はleakyReLUでPoolingはmeanPoolingといったところでしょう.
しかしながら解決案はそれだけではなく,本稿で説明するDenseNetや他にもPyramidNet,HighwayNetなどがあります.では実際にどのように勾配消失を解決していったのかを解説していきます.
ResNetにおける解決策
深層化による勾配消失をResNetでは以下の式のように畳み込み処理をスキップするパスを持つResidual Blockを導入することで解決しています.
x_{l+1} = x_{l} + f_l(x_l)
$x_l$は第$l$層目の入力で,$f_l$がl層目の処理です.
ネットワークはResidualな$f_l$の部分を学習し,スキップするパスで勾配を伝搬する経路を確保します.
このResidual Blockにより100層重ねても学習ができる大規模ネットワークが作れるようになりました.
DenseNetにおける解決策
一方DenseNetは以下の式のようなDense Blockを使用した戦略をとります.
x_{l+1} = f_l(x_0,\cdots,x_l)
先ほどと同じように$x_l$は第$l$層目の入力で,$f_l$がl層目の処理です.
任意の層の入力同士が直通のパスを持っていることがわかります.
特に入力から出力までの直通のパスを用意することで勾配の伝搬する経路を確保しています.
なお,実装上は$x_0,\cdots,x_l$の部分はチャンネル方向に結合して生成しています.
↓論文中より引用したDense Blockの図
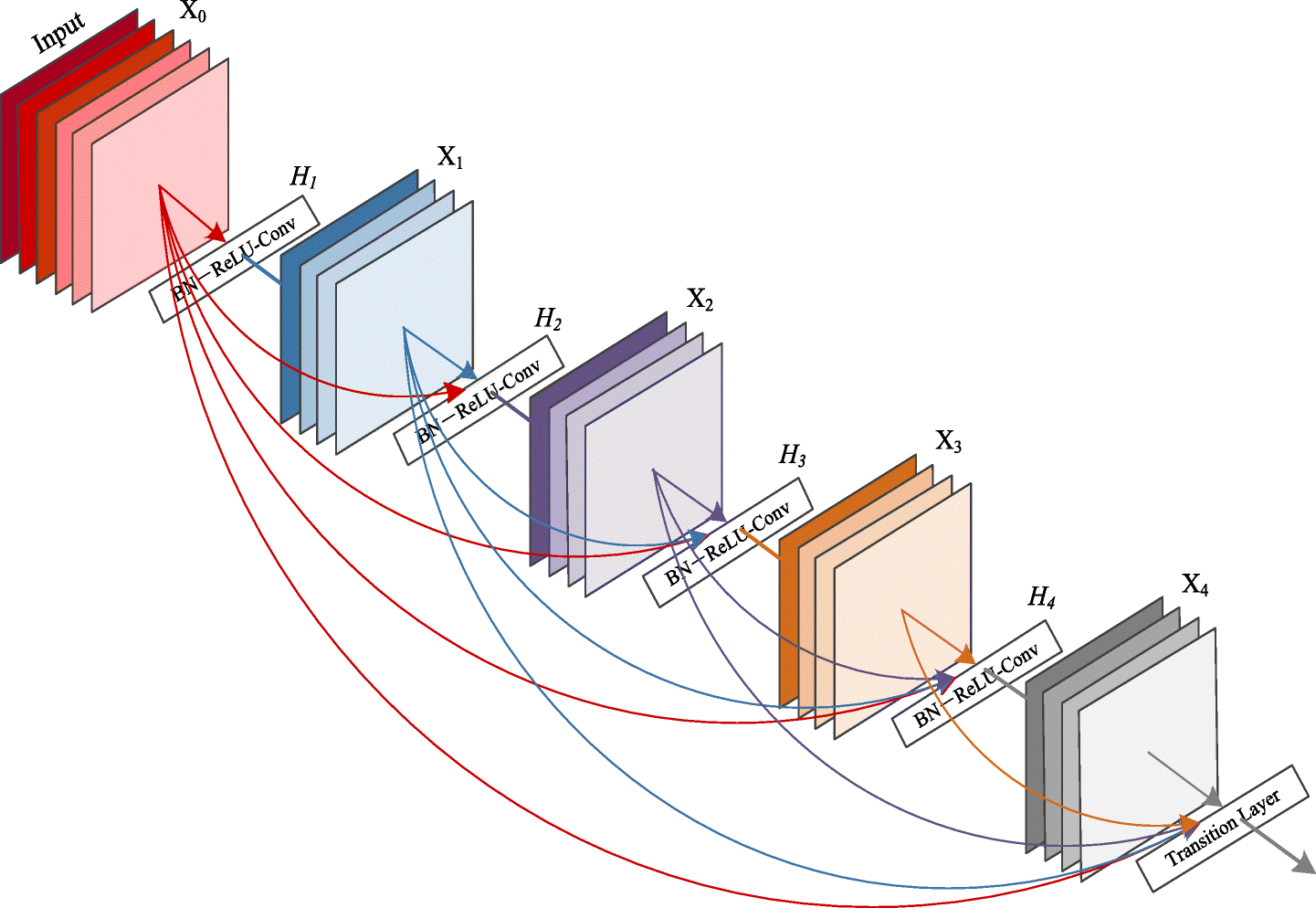
Dense Blockの詳細な説明
Transition層
VGGなどの多くのモデルは入力チャンネルサイズは層が深くなるにつれ大きくなっていきますが,同時に画像サイズ自体が小さくなっているので計算的に大きな問題にはなりません.
しかしながらDense Blockは画像サイズはそのままであるのに入力チャンネルサイズが層が深くなるにつれ大きくなってしまい計算量が増える問題があります.
そこでDenseNetではDense Blockをそのまま重ねていくだけではなく,Transition層という画像サイズと入力チャンネルサイズ両方を小さくする処理を間に挟みます.
Transition層ではチャンネル方向をpixel-width convolutionで,画像サイズをaverage poolingで半分のサイズにまで小さくします.
Transition層によって入力テンソルのサイズを小さくし,計算量を減らすことができます.
Bottleneck層
全体として多くの畳み込みを行うDenseNetではTransition層を導入しても計算量やパラメータ数を減らす工夫が必要となります.(正直ResNetとパラメータ数競争したいだけだと思う.)
そのためDense Block内で利用する畳み込み計算をdepthwise separable convolutionのように2つの畳み込みに分解して計算を行います.一つ目の畳み込みはpixel-width convolutionで最終出力チャンネル数の4倍のチャンネル数にまで小さくし,その後に通常の畳み込みを用います.
全体の説明
DenseNetは下図にあるような形状をしており,Dense Blockを3または4層間にTransition層を挟みながら重ねていきます.(下図中において,Transition層はDense Blockの間のConvolutionとPoolingに相当.)
Dense Blockを通った後にGlobal Average Poolingを行った上で一層の線形層とsoftmaxをかけモデル全体となります.Dense BlockとTransition層を理解すればかなり単純な見た目をしています.
↓論文中より引用したDenseNetの概略図

DenseNetの追実験
筆者のgithubに0から自分で実装したコードがあります.今回の追実験はこのコードを利用して行いました.
今回はGPUの容量の都合もあり,CIFAR-10の画像分類問題をモデルに学習させました.
ハイパーパラメータ等として,$k(growth\ rate) = 12,L(depth)=100$でdata augumentaionありで学習を行い,その他は論文に準拠しました.
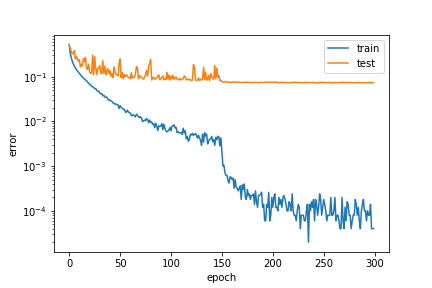
実験結果がこちらです.
| 元論文 | 追実験 |
|---|---|
| 95.5% | 92.5% |
結果として,92.5%程度の精度の分類器を得ることができました.
一方論文中では同じ条件で95.5%程度と報告されているので,追実験と開きがあることは確かです.
これは私の実装にバグがある訳ではなく,モデルの初期値や入力データの順番等のランダム性から生じる誤差だと考えられます.悪い見方をすれば,DenseNetはガチャ性があるモデルであり,何度かやり直す必要があることが考えられます.