本記事の目的
- Subword segmentaion の考え方について理解する。
- Subword segmentation の新手法 (SentencePeiece) のロジックを理解する。
- 参照論文の第2章、第3章にある式の展開を追う。
参照論文

参照論文の構成
- Introduction
- Neural Machine Translation with multiple subword segmentations
- NMT training with on-the-fly subword sampling
- Decoding
- Subword segmentations with language model
- Byte-Pair-Encoding (BPE)
- Unigram language model
- Subword sampling
- BPE vs. Unigram language model
- Related Work
- Experiments
- Setting
- Main Results
- Results with out-of-domain corpus
- Comparison with other segmentation algorithms
- Impact of sampling hyperparameters
- Conclusions
第1章について
文章を区切るとはどういうことでしょうか? 参照論文のテーブル1には、"Hello World" を区切る例(5パターン)があります。
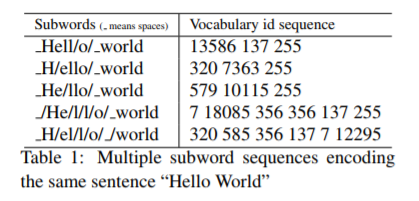
単純に「Hello」と「World」で区切ればよいのでは? と思うのですが、ゆっくり考えてみます。例えば、次の文章はどうでしょうか?
「はなこさんじゅうごさい。」
はなこさんは何歳でしょうか?
15歳と回答した人は、
「はなこさん、じゅうごさい。」
と読んだと思います。一方、35歳と回答した人は、
「はなこ、さんじゅうごさい。」
と読んだのではないでしょうか? では、次の文章はどうでしょうか?
「ここではきものをぬいでください。」
脱いでほしいのは、はきもの(履物)でしょうか、きもの(着物)でしょうか?
私たちは、前後の文脈を手がかりに複数ある読み方(区切り方)の候補から適切なものを選択しています。そもそも、「はなこ」は1単語なのか「はな」と「こ」の2単語なのかは自明ではありません。
(おまけです。「あのひとじなんだよ。」)
日本語の文章に関して機械(深層)学習をする時、形態素解析(分かち書き)をすることが多いと思います。その時ひと通りのやり方で区切った文章で学習させています。一方、複数の区切りの可能性を考え、(さいころを振って話すトピックを決めるように)確率的に区切りを決めるという発想をしてみましょう、というのが参照論文のアイデアです。そして、それは画像系のタスクにおける Augmentaion に対応すると述べられています。1枚の画像データを水平反転させたり、傾けたり、色合いを変えたりすることで複数の入力データとし、モデルの頑健性を向上させる(過学習を抑える)のは常套手段です。同様に、一つの文章を異なる位置で区切ることで、複数の入力データを作成することが可能となります。
以下、参照論文の「6. Conclusions」からの抜粋です。
The central idea is to virtually augment trading data with on-the-fly subword sampling, which helps to improve the accuracy as well as robustness of NMT models.
文章の区切り方を「サブワードによるセグメンテーション」と呼び(画像タスクのセマンティック・セグメンテーションとのアナロジーを考えるとしっくりきます)、「第2章について」で再考します。
すでに「目から鱗」の論文ですが、さらにセグメンテーションの新方法が提案されています。以下は、同じく「6. Conclusions」からの抜粋です。「第3章について」でロジックの理解を試みます。
In addition, for better subword sampling we propose a new subword segmentation algorithm based on the unigram language model.
第2章について
参照論文の式(1)~(4)について考えます。
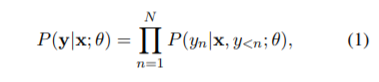
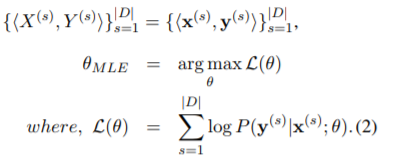
式(1)、(2)で翻訳タスクを定式化しています。
'Hello World' の翻訳を考え、X = 'Hello World'、Y = 「こんにちは世界」が与えられたとします。では、(セグメンテーションされた)X と「こんにちは」を知っているとき、次の単語が「世界」である(条件付き)確率は? というのが(1)式のイメージです。さらに、対数を取って最大化することでモデルのパラメータを求めましょう(最尤法)というのが(2)式です。
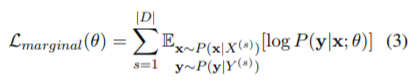
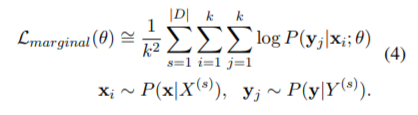
次に(3)式以降ですが、いったん(3)式をわかったとします。(4)式は(3)式中の期待値を(モンテカルロ法のように)サンプル平均で近似しています。さらに k=1 でも十分良い近似である、という展開は、GAN や VAE でも同様にされます。論文中では、
When we have a sufficient number of iterations, subword sampling is executed via the data sampling of online trading, which yields a good approximation of (3) even if k = 1.
です。
では、(3)式はどう解釈すればよいでしょうか? ここが重要なポイントで、文章の分割(サブワード・セグメンテーション)は複数あり、確率的に決まるものだということです。ですから、xは確率変数であり、期待値を計算する意味があるのです。例えば、
「こん|にちは|世界」である確率は 0.3
「こんにち|は|世界」である確率は 0.2
「こんにちは|世界」である確率は 0.4
「こん|にちは|世界」である確率は 0.1
という感じです。ここで注意したいのは、私たちにとって最も自然に見える区切り方が、必ずしもモデル(AI)にとってベストとは限らないのではないか? ということです。人間による特徴抽出をスキップした End-to-end のディープラーニングが高い予測精度を達成していることを念頭に置いています。論文の著者の以下の記事が大変興味深く、勉強になります。
Sentencepiece : ニューラル言語処理向けトークナイザ
第3章について
文章を分割する新手法 (Sentencepiece) について学びます。
- Byte-Pair-Encoding (BPE)
以下のような文字列を考えます。
'aabcaadbc"
a, b, c, d を単位とすると9個の文字が並んでいます。aa->A, bc->B と置き換えると、
'ABAdB'
となり、文字数は5個に減少します。この時、ボキャブラリーが {a, b, c, d} から {a, b, c, d, A, B} に増加したと考えます。
- Unigram language model
BPE はボキャブラリーサイズとトークンの数をバランスさせることができますが、決定的アルゴリズムであるため複数の分割を生成することが困難です。そこで、新手法による分割(サブワード・セグメンテーション)が提案されます。
式(6)、(7)から見ていきます。
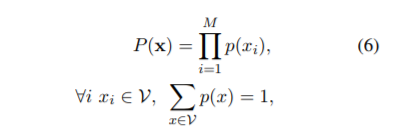
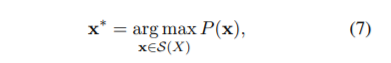
ユニグラムモデルでは各サブワードの生起は独立ですので、分割確率を、(1)式のような条件付き確率を使わず、各サブワードの生起確率の積として表すことができます。(7)式は、全ての分割候補の中から P(x) を最大とする分割列を最適分割列と定義しています。語彙集合νが所与であることに注意してください。
- EM アルゴリズム
最尤推定をするために対数尤度を考えます(次式最初の等式)。2番目の等式は、P(X) を全分割列の分割確率の和に書き換えています。混合(正規)モデルとのアナロジーで、各分割の分布を混合していると考えるとイメージしやすいでしょうか。
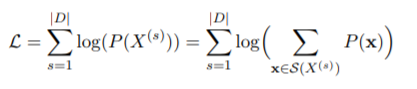
対数尤度Lを最大化したいのですが、最右辺の log の中には Σ があるため解析的に解くことができません。では、EMアルゴリズムで数値的に解きましょう、というのも混合正規分布のパラメータ推定での解法と同様です。
- 全体のアルゴリズム
ここまで語彙集合νを事前に与えてきましたが、実際には未知です。生起確率 p(x) と一緒に求める必要があります。そのために以下のような反復計算を行います。

十分大きな語彙集合から出発し、EMアルゴリズムによる生起確率の推定と語彙の絞り込みを交互に繰り返しています。語彙の絞り込みとは、その語彙を削除した場合の尤度の減少度を計算し、大きいものから(例えば80%を)キープするということです。実際、SentencePiece を学習させる際にはボキャブラリーサイズを引数にとります。
import sentencepiece as spm
spm.SentencePieceTrainer.Train(
'--input=data/wagahaiwa_nekodearu.txt
--model_prefix=wagahai
--vocab_size=3000'
)
SentencePiece の仕様について
以下の論文が取扱説明書となります。

一部繰り返しとなりますが、著者への敬意、感謝も込めて「5 Conclusions」から抜粋します。
SentencePiece not only performs subword tokenizaion, but directly converts the text into an id sequences, which helps to develop a purely end-to-end system without relying on language specific resources.
We hope that SentencePiece will provide a stable and reproducible text processing tool for production use and help the research community to move to more language-agonostic and multilingual architectures.
2番目の引用の考え方が BERT につながります(BERT 論文についての考察は別記事にします)。 また、
に Python wrapper の使用方法の説明があります(感謝)。
以上、subword segmentaion、SentencePiece についての論文に関する考察でした。