Reference
Data
train = pd.read_csv('/content/sales_train_v2.csv')
test = pd.read_csv('/content/test.csv')
submission = pd.read_csv('/content/sample_submission.csv')
items = pd.read_csv('/content/items.csv')
item_cats = pd.read_csv('/content/item_categories.csv')
shops = pd.read_csv('/content/shops.csv')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
#matplotlib inline
Sample Code 1
d = train.groupby('date_block_num', as_index = False)['item_cnt_day'].sum()
ts = d.rename(columns = {'item_cnt_day' : 'item_cnt_month'})
ts.plot.line(x = 'date_block_num', y = 'item_cnt_month', figsize = (5, 3))
plt.title('Total Sales')
plt.show()

import statsmodels.api as sm
x = ts['item_cnt_month'].values
res = sm.tsa.seasonal_decompose(x, freq = 12, model = "additive")
fig = res.plot()
#plt.show()

fig = plt.figure(figsize = (7, 10))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(x, lags = 24, ax = ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(x, lags = 24, ax = ax2)

order_select = sm.tsa.arma_order_select_ic(x, ic = 'aic', trend = 'nc')
print (order_select)
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(x, order = (1, 0, 1))
results = model.fit(trend = 'nc')
print (results.summary())
residuals = results.resid
fig = plt.figure(figsize = (12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(residuals, lags = 24, ax = ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(residuals, lags = 24, ax = ax2)


prediction = results.predict(1, 35)
#plt.plot(x, label = 'true')
#plt.plot(prediction, 'r', label = 'prediction')
#plt.legend(loc = 'upper right')
#plt.show()
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(111)
ax.plot(x, label = 'true')
ax.plot(prediction, 'r', label = 'prediction')
ax.legend(loc = 'upper right')
plt.show()

Sample Code 2
def eda(data):
print('----------Top-5- Record----------')
print(data.head(5))
print('-----------Information-----------')
print(data.info())
print('-----------Data Types-----------')
print(data.dtypes)
print('----------Missing value-----------')
print(data.isnull().sum())
print('----------Null value-----------')
print(data.isna().sum())
print('----------Shape of Data----------')
print(data.shape)
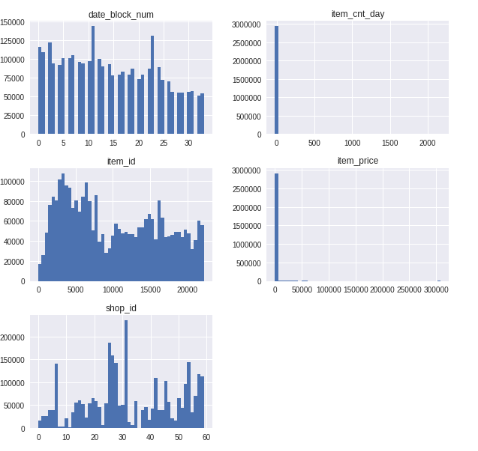
def graph_insight(data):
df_num = data.select_dtypes(include = ['float64', 'int64'])
df_num.hist(figsize = (10, 10), bins=50)
eda(train)
graph_insight(train)
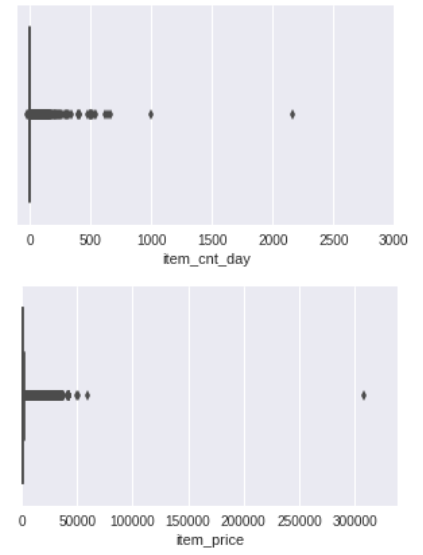
plt.figure(figsize = (5, 3))
plt.xlim(-100, 3000)
sns.boxplot(x = train.item_cnt_day)
plt.show()
plt.figure(figsize = (5, 3))
plt.xlim(train.item_price.min(), train.item_price.max()*1.1)
sns.boxplot(x = train.item_price)
plt.show()
# drop duplicates
print(train.duplicated().value_counts())
print ()
subset = ['date','date_block_num','shop_id','item_id','item_cnt_day']
print(train.duplicated(subset = subset).value_counts())
print ()
temp = train.drop_duplicates(subset = subset)
print (len(train.item_id))
print (len(temp.item_id))
check = train[train.item_id.isin(test.item_id.unique())]
print ('# of item_id of test:', len(test.item_id.unique()))
print ('# of item_id of train in test: ', len(check.item_id.unique()))
print ()
check = train[train.shop_id.isin(test.shop_id.unique())]
print ('# of shop_id of test:', len(test.shop_id.unique()))
print ('# of shop_id of train in test: ', len(check.shop_id.unique()))
print ()
print('train:', train.shape)
print ('temp: ', temp.shape)
# drop shops&items not in test data
test_shops = test.shop_id.unique()
temp = temp[temp.shop_id.isin(test_shops)]
print ('temp: ', temp.shape)
test_items = test.item_id.unique()
temp = temp[temp.item_id.isin(test_items)]
print ('temp: ', temp.shape)